ViT- an image is worth 16x16 words- transformers for image recognition at scale
Google ICLR 2021
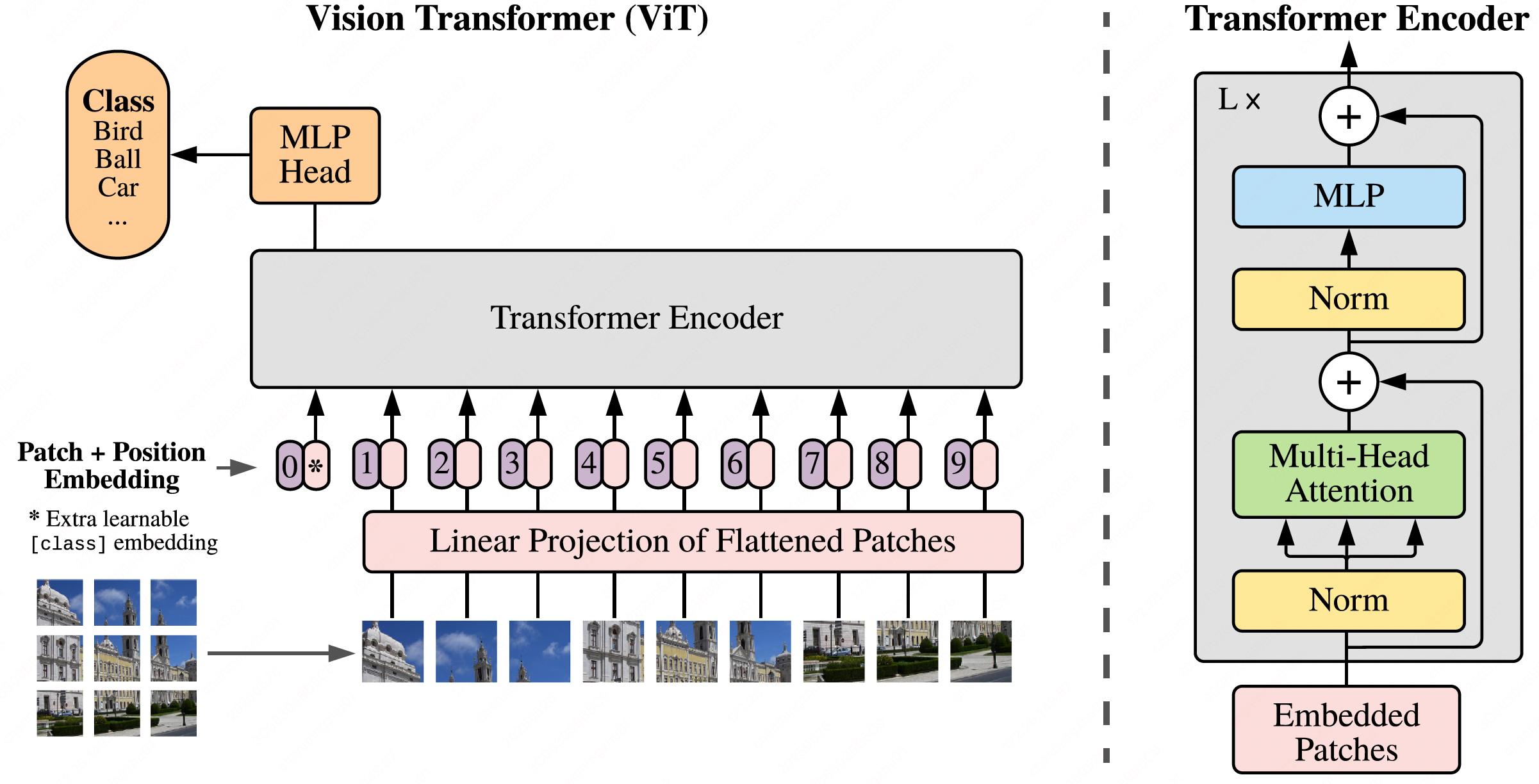
输入:图像
网络结构:
- 图像拆patch (bs, num_patch, dim) to_patch_embedding
- Rearrange 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width
- norm
- Linear
- norm
- 拼接类别token (bs, num_patch+1, dim)
- 加位置embedding(矩阵点加)
- transformer网络
- 堆叠att和ffn
- att:
- norm- selfAtt- Linear- dropout
- ffn:norm- Linear- act- dropout- Linear- dropout
- norm:LayerNorm
- act:GELU
- att:
- 堆叠att和ffn