CAU人工智能class3 优化器
优化算法框架

优化思路
随机梯度下降

随机梯度下降到缺点:
SGD 每一次迭代计算 mini-batch 的梯度,然后对参数进行更新,每次迭代更新使用的梯度都只与本次迭代的样本有关。
- 因为每个批次的数据含有抽样误差,每次更新可能并不会
按照正确的方向进行,因此可能带来优化波动(扰动) - SGD 最大的缺点是下降速度慢,而且可能会在沟壑的两
边持续震荡,停留在一个局部最优点
弥补方法
动量(SGD with Momentum)

当到达左边的最低点时,会在这个低谷来回震荡而无法继续优化函数。
如果增加一个动量就能帮助函数越过低谷继续优化。
原理:
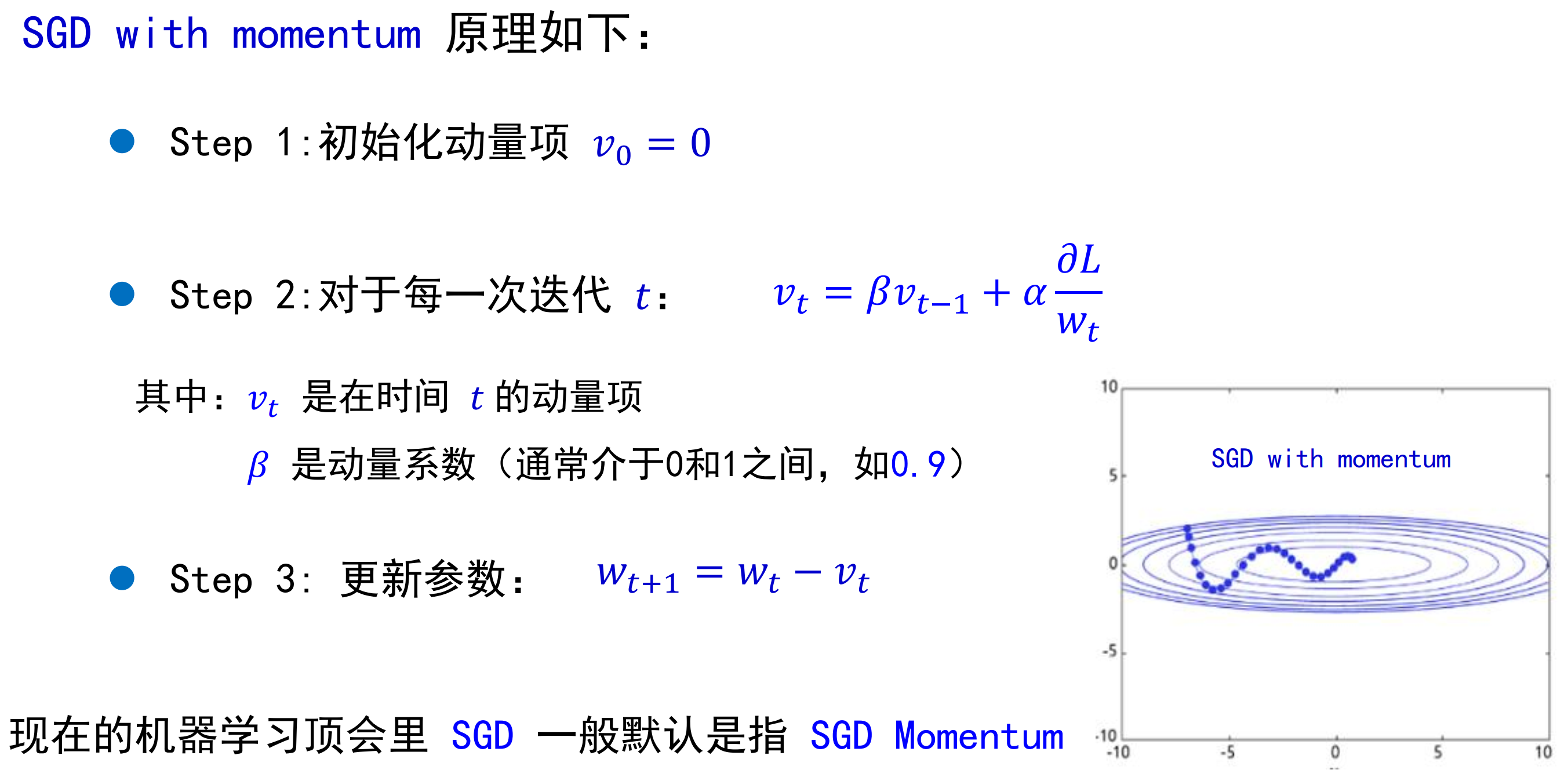
这使得参数更新的更加平缓,不会有突然发生巨变的情况,有助于避免震荡。
自适应梯度下降(AdaGrad: Adaptive Gradient)
这是一种利用概率统计的方法动态调整学习率大小从而避免优化时来回震荡的方法。
当距离最优解较远时,期望参数更新的步长(学习率 𝛼 )大一些,以便更快收敛到最优解。反之步长减小。
自适应运动(矩)估计(Adam: adaptive moment estimation)
Adam: 融合 Momentum 和 AdaGrad 的思想优化算法,广泛用于深度学习应用中,尤其是计算机视觉和自然语言处理等任务。
Adam 涉及一阶矩和二阶矩
- 一阶矩:一阶矩 𝑚𝑡 是梯度的指数移动平均,即对过去梯度的加权平均,类似于Momentum方法
公式如下:𝑚𝑡 = 𝛽1 ∙ 𝑚𝑡−1 + (1 − 𝛽) ∙ 𝑔𝑡
其中 𝛽1 是一阶矩的平滑因子(通常设置为 0.9 ), 𝑔𝑡 在第 𝑡 次迭代时计算得到的梯度向量 - 二阶矩 (梯度平方的均值):即历史梯度平方与当前梯度平方的加权平均,类似AdaGrad 方法,体现了环境感知能力,为不同参数产生自适应的学习速率
公式如下:𝑣𝑡 = 𝛽2 ∙ 𝑣𝑡−1 + (1 − 𝛽2) ∙ 𝑔𝑡
其中 𝛽2 是二阶矩的平滑因子(通常设置为 0.999 ), 𝑔𝑡 在第 𝑡 次迭代时计算
得到的梯度向量,二阶矩在这里的作用是捕捉梯度的波动情况,用于自适应地调整学习率。
修正偏差:

参数更新

这几种方法均可以在模型中直接调用使用,具体不展开。