检索增强生成(RAG):大模型的‘外挂知识库

🎏:你只管努力,剩下的交给时间
🏠 :小破站
检索增强生成(RAG):大模型的‘外挂知识库
- 前言
- 什么是RAG
- 工作原理
- 1. 检索(Retrieval)
- (1)输入处理
- (2)检索相关文档
- 2. 生成(Generation)
- (1)输入整合
- (2)生成响应
- 3. 输出(Output)
- 关键技术与细节
- (1)检索模型
- (2)生成模型
- (3)知识库
- 优缺点
- 优点
- 1. 准确性高
- 2. 可解释性强
- 3. 灵活性高
- 4. 知识覆盖广
- 5. 减少训练成本
- 缺点
- 1. 检索效率问题
- 2. 知识库依赖性强
- 3. 检索与生成的协同问题
- 4. 复杂性问题
- 5. 知识库规模限制
- **总结**
前言
想象一下,你正在参加一场考试,但这次考试允许你“开卷”。你不仅可以从书本中找到答案,还能灵活运用这些知识来回答问题。这就是RAG技术的魅力所在!传统的生成式AI(如ChatGPT)只能依赖“脑子里存的东西”(训练好的模型参数),而RAG则像一位“开卷小天才”,既能查资料,又能灵活作答。它结合了信息检索与生成式大模型的双重优势,让AI的回答更精准、更实时。那么,RAG究竟是如何工作的?它又能为我们的生活带来哪些改变?让我们一探究竟!
什么是RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索技术与生成式大模型(LLM)的AI框架。它通过从外部知识库中检索相关信息,并将其作为提示(Prompt)输入给大模型,从而增强模型处理知识密集型任务的能力,如问答、文本摘要、内容生成等。
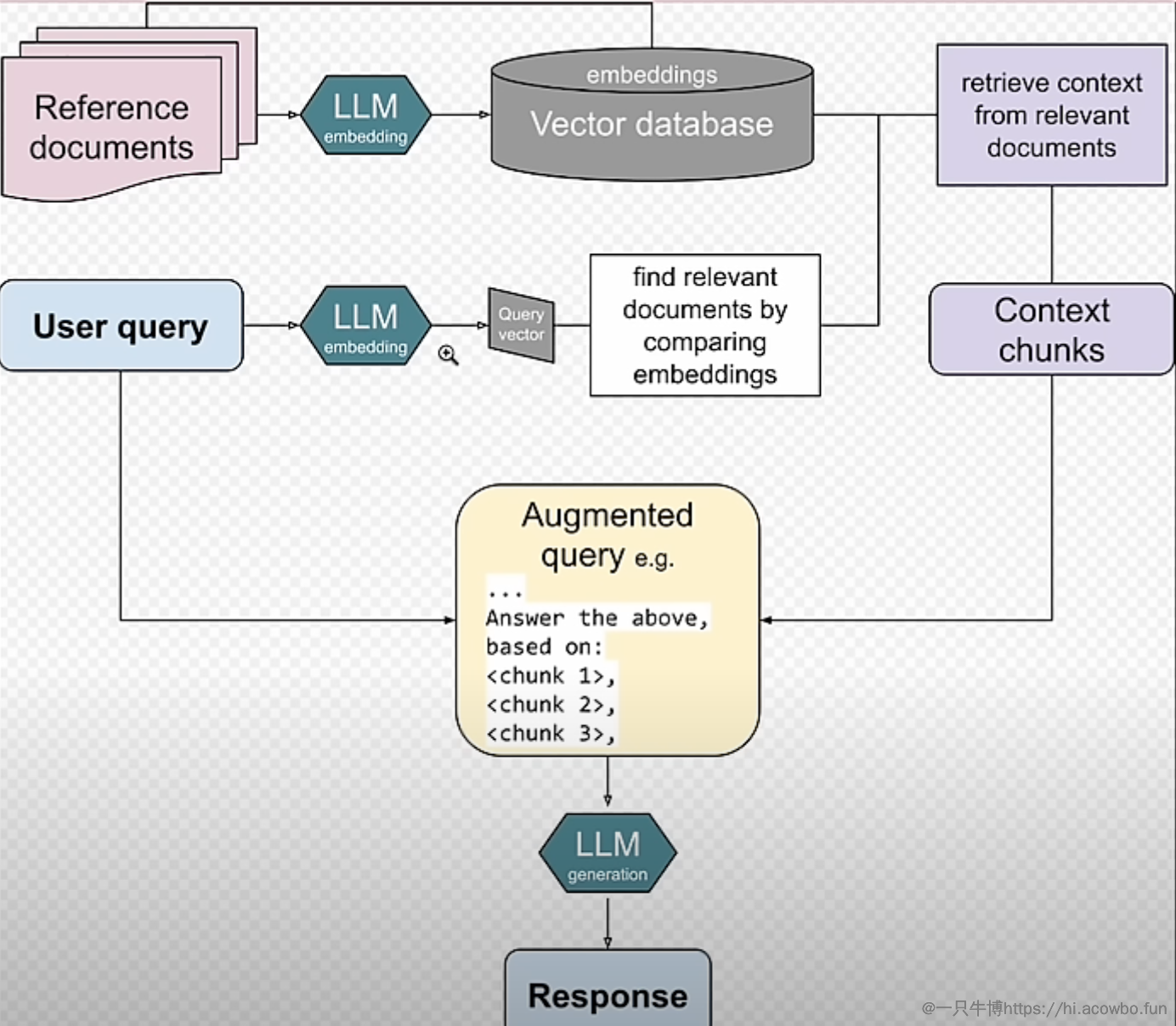
工作原理
1. 检索(Retrieval)
(1)输入处理
- 用户输入一个问题或指令(例如:“量子计算的基本原理是什么?”)。
- 系统对输入进行预处理,包括:
- 分词:将输入文本拆分为单词或子词。
- 编码:将文本转换为向量表示(例如,使用BERT等预训练语言模型)。
- 语义理解:提取输入的语义信息,以便后续检索。
(2)检索相关文档
- 系统使用检索模型从外部知识库中查找与输入最相关的文档或段落。
- 检索模型:常用的检索模型包括:
- 稀疏检索模型:如BM25,基于关键词匹配。
- 稠密检索模型:如DPR(Dense Passage Retriever),基于语义相似度。
- 知识库:可以是维基百科、专业数据库或其他结构化/非结构化文档集合。
- 检索过程:
- 将用户输入的向量表示与知识库中的文档向量进行相似度计算。
- 根据相似度排序,返回最相关的若干文档或段落(例如,Top-K个结果)。
- 检索模型:常用的检索模型包括:
2. 生成(Generation)
(1)输入整合
-
将用户输入和检索到的文档整合为一个增强的输入。
-
例如:
- 用户输入:“量子计算的基本原理是什么?”
- 检索到的文档:“量子计算利用量子比特(qubit)和量子叠加、纠缠等原理进行计算。”
-
整合后的输入可能形式:
用户问题:量子计算的基本原理是什么? 相关文档:量子计算利用量子比特(qubit)和量子叠加、纠缠等原理进行计算。
-
(2)生成响应
-
使用生成模型(如GPT、T5等)基于整合后的输入生成最终响应。
-
生成模型的任务:
- 理解用户问题和检索到的文档。
- 结合文档内容生成准确、连贯的回答。
-
生成过程:
- 模型通过自回归方式逐词生成答案。
- 在生成过程中,模型会参考检索到的文档内容,确保回答的准确性和相关性。
-
示例生成结果:
量子计算的基本原理是利用量子比特(qubit)进行信息处理。与传统计算机的二进制比特不同,量子比特可以同时处于多个状态的叠加,并且通过量子纠缠实现高效的信息传递和计算。
-
3. 输出(Output)
- 将生成的响应返回给用户。
- 系统会对生成的文本进行后处理,例如:
- 去除重复内容。
- 检查语法和流畅性。
- 最终将回答呈现给用户。
- 系统会对生成的文本进行后处理,例如:
关键技术与细节
(1)检索模型
- 稀疏检索:基于关键词匹配,速度快但语义理解能力有限。
- 稠密检索:基于语义相似度,能够捕捉更深层次的语义关系。
- 混合检索:结合稀疏检索和稠密检索的优点,提高检索效果。
(2)生成模型
- 预训练语言模型:如GPT、T5、BART等,具有较强的文本生成能力。
- 上下文理解:生成模型需要理解用户问题和检索到的文档之间的关联。
- 多任务学习:生成模型可以同时处理问答、摘要、对话等多种任务。
(3)知识库
- 规模:知识库越大,检索到的相关文档可能越多,但计算成本也会增加。
- 质量:知识库的内容质量直接影响生成结果的可信度。
- 动态更新:知识库需要定期更新,以保持信息的时效性。
优缺点
优点
1. 准确性高
- 检索增强:通过从外部知识库中检索相关文档,生成模型能够基于真实、可靠的信息生成回答,显著提高准确性。
- 减少幻觉:相比纯生成模型(如GPT),RAG减少了生成虚假或无关内容的可能性。
2. 可解释性强
- 基于文档生成:RAG的回答通常基于检索到的文档,用户可以追溯生成结果的来源,增强可信度。
- 透明性:检索到的文档可以作为生成过程的依据,使系统更具透明性。
3. 灵活性高
- 多任务适用:RAG可以用于多种任务,如问答、对话生成、文档摘要、内容创作等。
- 动态知识更新:通过更新知识库,RAG可以快速适应新领域或新知识,而无需重新训练生成模型。
4. 知识覆盖广
- 外部知识库:RAG可以利用大规模知识库(如维基百科、专业数据库),覆盖广泛的主题和领域。
- 弥补模型知识局限:生成模型本身的知识受限于训练数据,而RAG通过检索弥补了这一不足。
5. 减少训练成本
- 无需完全重新训练:RAG可以在现有生成模型的基础上,通过引入检索模块提升性能,而无需从头训练。
缺点
1. 检索效率问题
- 计算成本高:检索过程需要对大规模知识库进行搜索和匹配,尤其是稠密检索模型,计算开销较大。
- 延迟较高:检索和生成两个步骤的串联可能导致响应时间较长,不适合实时性要求高的场景。
2. 知识库依赖性强
- 知识库质量决定性能:如果知识库不完整、过时或质量差,检索到的文档可能不准确,从而影响生成结果。
- 知识库更新成本:保持知识库的时效性需要定期更新和维护,增加了系统运营成本。
3. 检索与生成的协同问题
- 检索结果不相关:如果检索模型未能找到与用户输入高度相关的文档,生成模型可能无法生成高质量的回答。
- 生成模型过度依赖检索:生成模型可能过于依赖检索结果,而忽略了自身的语言生成能力,导致回答缺乏创造性。
4. 复杂性问题
- 系统复杂性高:RAG需要同时维护检索模型、生成模型和知识库,系统架构和调试复杂度较高。
- 调试难度大:检索和生成两个模块的协同工作可能导致问题定位和优化更加困难。
5. 知识库规模限制
- 大规模知识库的存储和检索:随着知识库规模的增大,存储和检索的开销也会显著增加,可能影响系统性能。
- 小规模知识库的局限性:如果知识库规模较小,可能无法覆盖用户的所有查询需求。
总结
| 优点 | 缺点 |
|---|---|
| 准确性高,减少幻觉 | 检索效率低,计算成本高 |
| 可解释性强,结果透明 | 知识库依赖性强,更新成本高 |
| 灵活性高,适用于多任务 | 检索与生成协同问题 |
| 知识覆盖广,弥补模型知识局限 | 系统复杂性高,调试难度大 |
| 减少训练成本,无需完全重新训练 | 知识库规模限制 |