基于requests_html的python爬虫
前言:今天介绍一个相对性能更高的爬虫库requests_html,会不会感觉和requests有点联系?是的。为什么开始不直接介绍呢?因为我觉得requests是最基本入门的东西,并且在学习过程中也能学到很多东西。我的python老师在介绍这两个库时是直接一起讲的,然后我就很混乱,各自特点以及用法都分不清楚。不是说老师讲得不好啊,老师是高手,是我太菜了~.~
requests_html库也是requests的作者开发的,是对requests、PyQuery、lxml、beautifulsoup4等库的二次封装。它将请求和解析功能集成在一起,使用起来更加方便。此外,requests_html还支持异步请求,能够提高爬虫的效率。但是,在某些复杂场景下,它的使用不如单独使用requests和BeautifulSoup灵活。
首先第一步当然是安装requests_html库啦,前面的文章有介绍,自行查阅
发送请求
from requests_html import HTMLSession #从requests_html模块中导入了HTMLSession类(封装了 requests)
session=HTMLSession() #创建HTMLSession的实例(一个会话对象),用于发送HTTP请求
r=session.get('https://blog.csdn.net/2402_88126487?type=blog') #发起GET请求,r是Response对象(同requests)
if r.status_code!=200:raise Exception('error')
print(r.text) #返回的是响应的原始HTML文本
print(r.html.html) #r.html是requests_html库提供的功能(包含一些额外的处理,比如自动解码)
#r.html是一个HTML对象,对响应的HTML内容进行了解析和封装,r.html.html是将解析后的HTML对象转换为字符串形式,便于查看和操作requests_html为html对象提供了许多方便的属性和方法
r.html.html #返回解析后的HTML内容的字符串形式
r.html.url #返回实际请求的URL,可能与初始请求的URL不同(例如经过重定向后)
r.html.base_url #返回页面的基准URL
r.html.links #返回页面中所有链接的集合
r.html.absolute_links #返回页面中所有绝对链接的集合(完整的URL)
r.html.encoding #查看以及更改页面的编码格式
r.html.render() #渲染页面以执行JavaScript
#如果请求的网页包含动态加载的数据,那么在提取数据之前需调用r.html.render(),确保页面上的JavaScript代码被执行,从而加载所有动态内容
#使用需下载包(前面的文章介绍过了),
r.html.find()
r.html.xpath() #这两个方法将在下面介绍
request-html支持CSS选择器和XPATH两种语法来选取HTML元素
r.html.find(selector,first=False)
使用 CSS 选择器查找页面中的元素,如果 first=True,则只返回第一个匹配的Element对象;否则返回所有匹配的Element对象的列表,使用方法有点类似于soup.find(),但不能直接在 find 方法中指定如class等的参数,selector参数说明如下:
r.html.find('div') #查找所有标签为<div>的元素
r.html.find('div.article-list') #查找所有标签为<div>类名为article-list的元素
r.html.find('div#abc123') #查找id为abc123的<div>标签的元素Element对象是requests_html库中用于表示HTML元素的对象,有如下属性和方法
element.text #获取元素的文本内容
element.attrs['href'] #通过element.attrs字典(包含了元素的所有属性)来访问元素的属性
element.find() #查找当前元素的子元素
element.html #获取元素的HTML内容现在我们来尝试打印主包博客首页每篇文章的标题
from requests_html import HTMLSession
session=HTMLSession()
r=session.get('https://blog.csdn.net/2402_88126487?type=blog')
if r.status_code!=200:raise Exception('error')
titles=r.html.find('article.blog-list-box') #titles是列表,不能继续.find
for title in titles:title=title.find('h4', first=True)print(title.text)r.html.xpath(xpath,first=False)
使用 XPath 表达式查找页面中的元素,如果 first=True,则只返回第一个匹配的元素;否则返回所有匹配的元素(element对象),xpath参数说明如下
r.html.xpath('//div') #查找所有标签为<div>的元素
r.html.xpath("//div[@class='example']") #查找所有<div>的class="example"的元素
r.html.xpath("//a[@href='https://example.com']")查找所有href=https://example.com的<a>元素给大家分享一下如何快速得到xpath
找到要提取的元素,右键,点击“复制”,点击“复制完整的XPath”
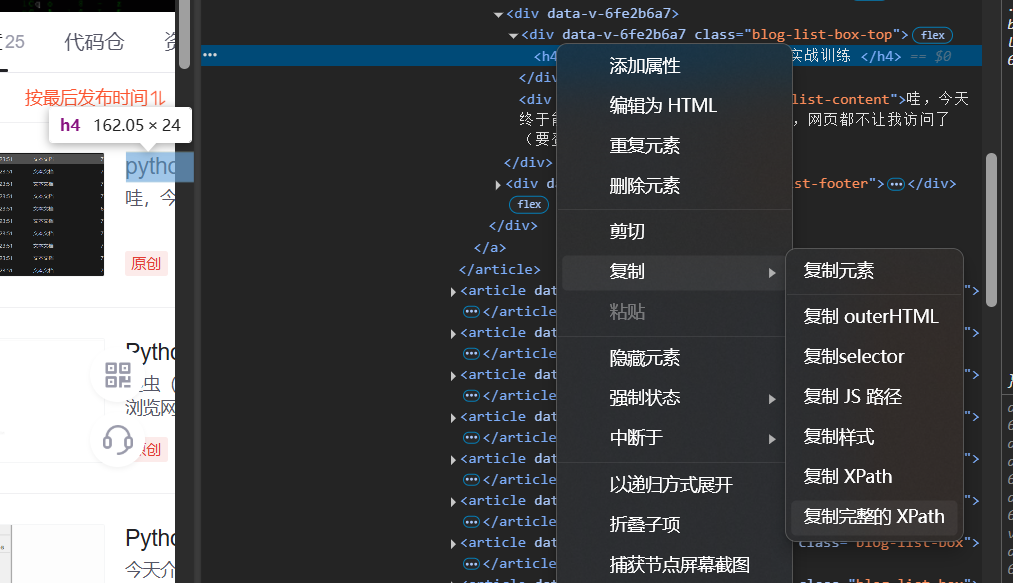
我们复制前两篇文章标题的xpath,如下,可以发现除了article后面的数字,其它都完全相同,并且数字代表篇数,那么我们可以通过改变数字获取所有标题的h4标签(为什么会想到这个呢?因为可以发现标题的存储都十分有规律)
/html/body/div[2]/div/div[1]/div/div/div/div/div/div[2]/div/div[2]/div[1]/div[2]/div/article[1]/a/div[2]/div[1]/div[1]/h4
/html/body/div[2]/div/div[1]/div/div/div/div/div/div[2]/div/div[2]/div[1]/div[2]/div/article[2]/a/div[2]/div[1]/div[1]/h4再写代码之前还要补充下:从浏览器开发者工具中复制的 XPath 是基于当前页面的完整结构生成的绝对路径。若网页中的某些内容是通过 JavaScript 动态生成的,这个XPath就会失效。解决方法是调用r.html.render()来渲染动态内容。博客首页开始有些地方是没有展示的,当我们在底部继续往下拉后才显示出来,但是url没有改变,说明这个网页是动态加载的
代码如下
from requests_html import HTMLSession
session=HTMLSession()
r=session.get('https://blog.csdn.net/2402_88126487?type=blog')
if r.status_code!=200:raise Exception('error')
r.html.render()
for n in range(1,11):title=r.html.xpath(f'/html/body/div[2]/div/div[1]/div/div/div/div/div/div[2]/div/div[2]/div[1]/div[2]/div/article[{n}]/a/div[2]/div[1]/div[1]/h4')if title==[]:continueprint(title[0].text)展示如下,不知道为什么STL那篇没法显示,但我单独查找article[7]是可以搜索到的,可能是页面加载时间过长了吧

关闭会话
完成请求后,建议关闭会话对象,释放资源(虽然不关不会报错,但这可以避免潜在的资源泄漏)
session.close()爬取百度
现在,我们来解决一下之前遗留的问题(入门那一篇),当然用上一篇的抓包动态加载也可以,但requests_html支持JavaScript真的方便很多哦
代码如下
from requests_html import HTMLSession
url='https://www.baidu.com/'
session=HTMLSession()
r=session.get(url)
r.html.render()
titles=r.html.find('ul#hotsearch-content-wrapper',first=True).find('li')
for title in titles:data=title.find('span')print(title.find('a',first=True).attrs['href'],data[0].text,data[1].text)展示如下

至此,一代新星即将升起,你已经“出师”了
最后,再给大家分享个网站——博客园,主包之前查信息有看到过这个网站,不过没去细看,最近发现里面真的有好多好棒的IT(Information Technology)专业信息文章,并且网页都是渲染过的,视觉体验好棒