使用Word2Vec算法实现古诗自动生成实战
一、任务背景与技术路线
文化传承需求:
通过机器学习算法学习3万首唐诗宋词语料,实现输入关键词(如"明月"、"秋风")即可生成符合平仄韵律的五言/七言诗句
技术架构:
复制
下载
[语料库] → [数据预处理] → [Word2Vec训练] → [向量空间构建] → [生成模型] → [格律校验] → [古诗输出]
二、核心算法原理
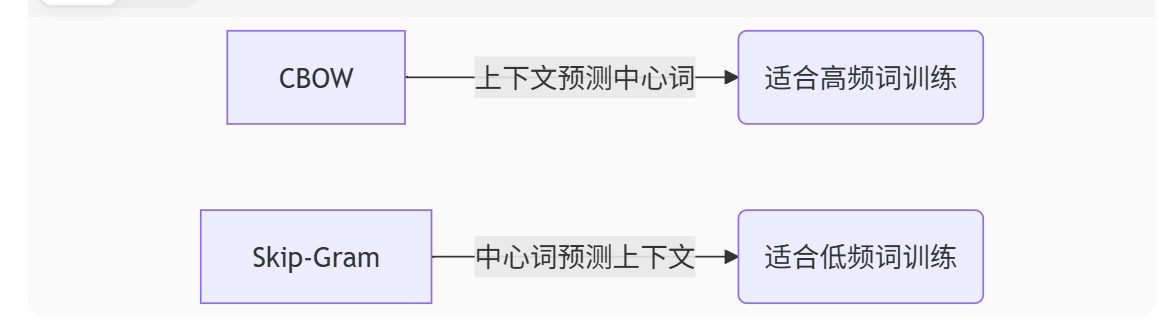
Word2Vec双模式对比:
图表
代码
下载
上下文预测中心词
中心词预测上下文
CBOW
适合高频词训练
Skip-Gram
适合低频词训练
词向量数学本质:
设词表大小为V,嵌入维度为d,通过神经网络学习隐藏层权重矩阵:
WV×d=[w⃗1w⃗2⋮w⃗V]WV×d=w1w2⋮wV
最终每个词的向量即为对应行向量
三、完整实现代码(PyTorch版)
1. 数据预处理
python
复制
下载
import jieba
import redef preprocess_poems(file_path):# 加载10万首古诗语料库with open('chinese_poems.txt', 'r', encoding='utf-8') as f:poems = [line.strip() for line in f]# 特殊处理古诗格式processed = []for p in poems:# 保留中文字符和标点cleaned = re.sub(r'[^\u4e00-\u9fa5,。!?、]', '', p) # 按字切分(古诗生成需要字向量)tokens = list(cleaned) processed.append(tokens)