大数据开发 hadoop集群 3.Hadoop运行环境搭建
一、配置虚拟机
1.1 下载VMware虚拟机
1.下载地址:VMware Workstation下载_VMware Workstation官方免费下载_2024最新版_华军软件园
1.2 创建虚拟机
简易安装信息
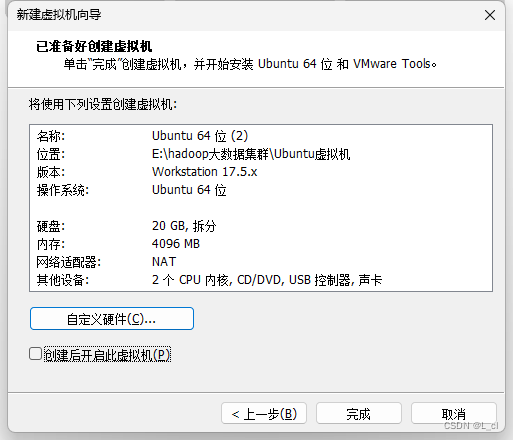
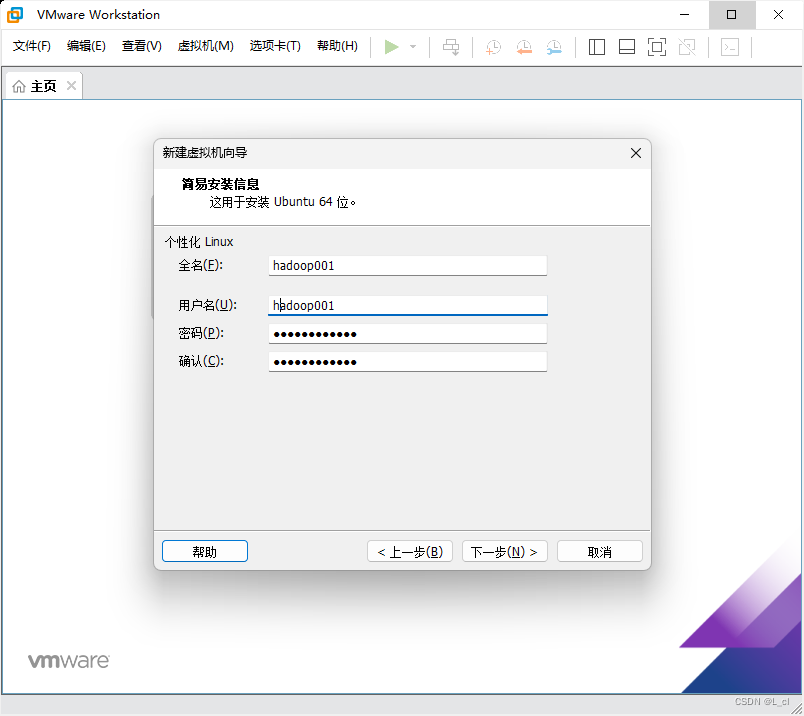 1.3. 命名虚拟机
1.3. 命名虚拟机
标题一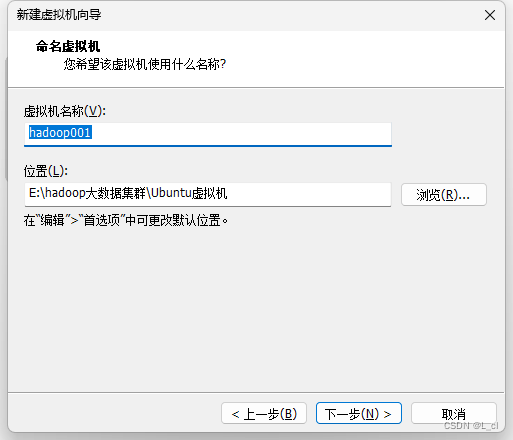
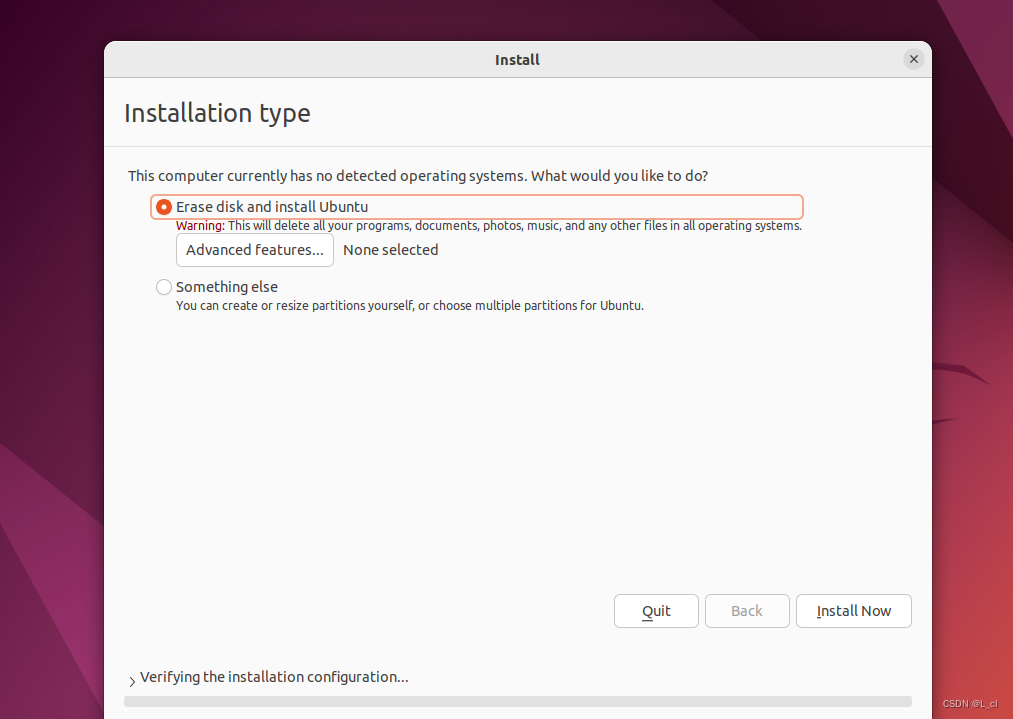
指定磁盘容量大小(推荐大小)
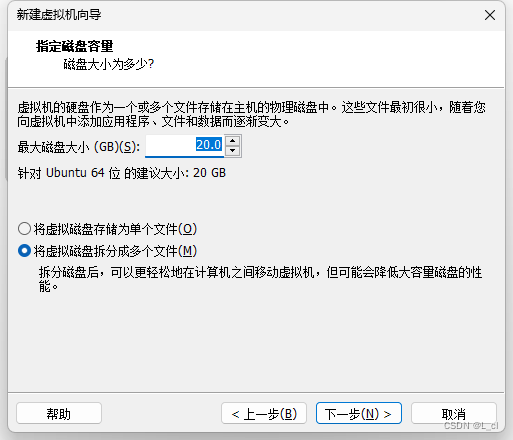
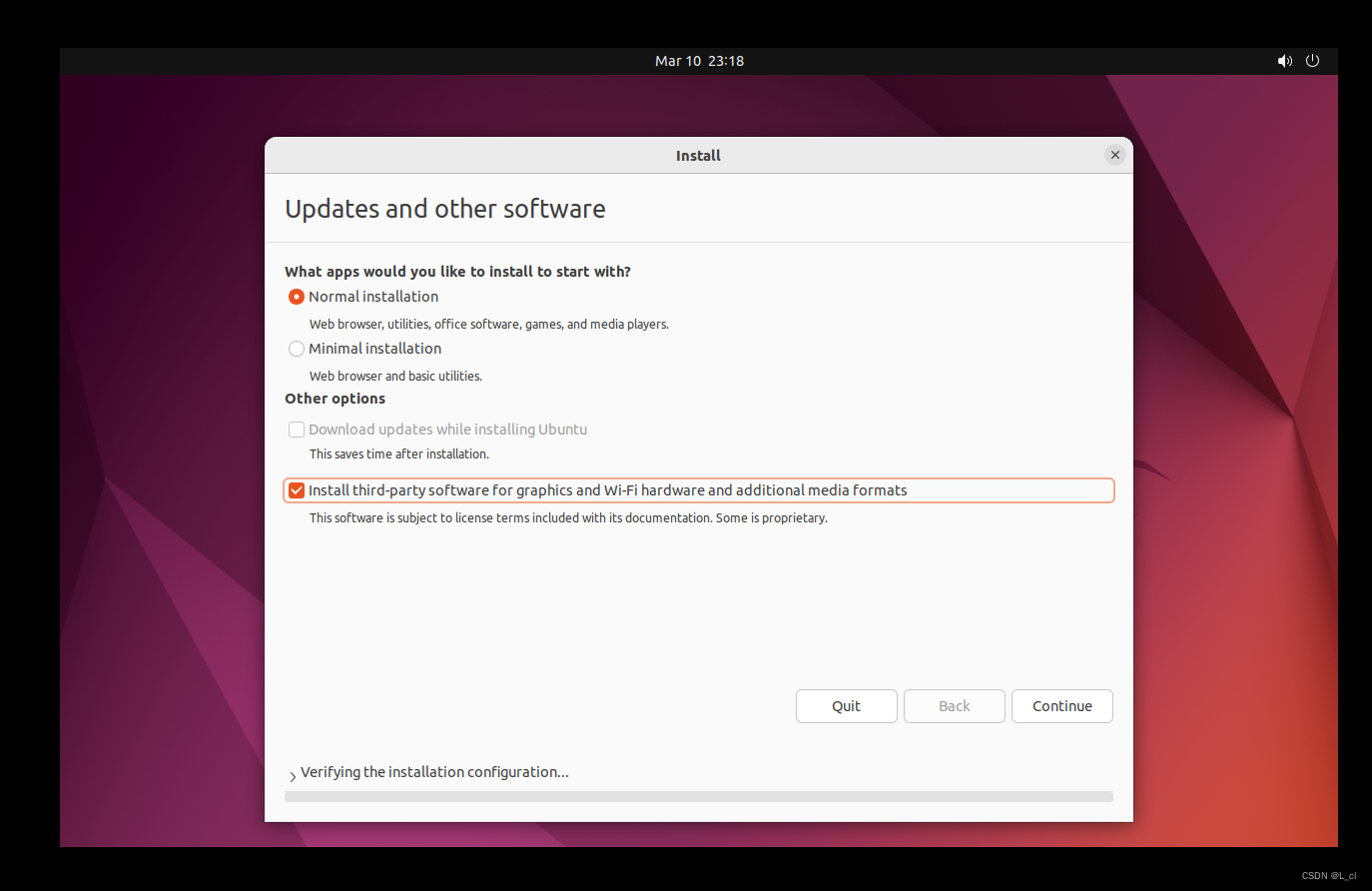
1.4. 语言和时区设置
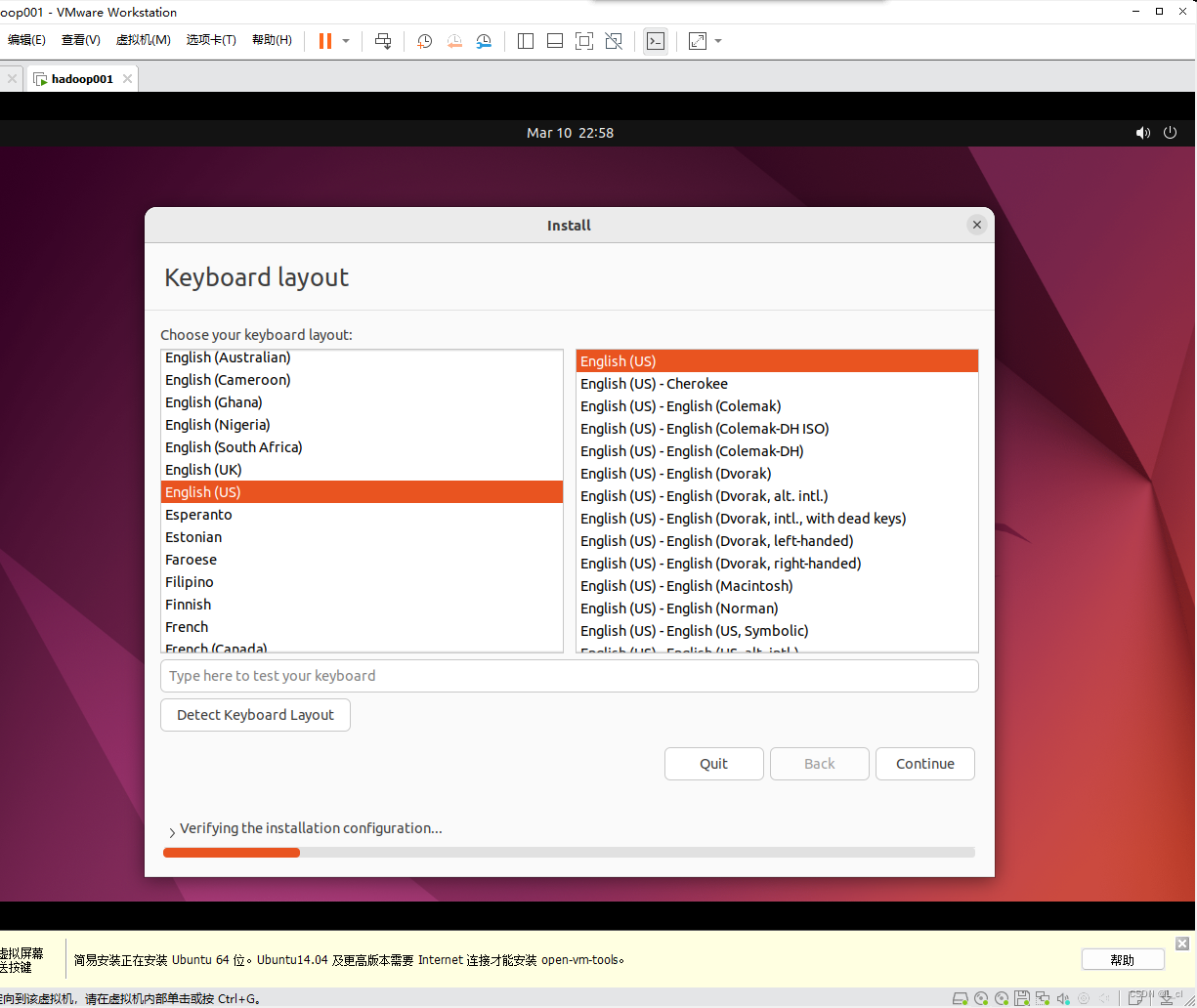
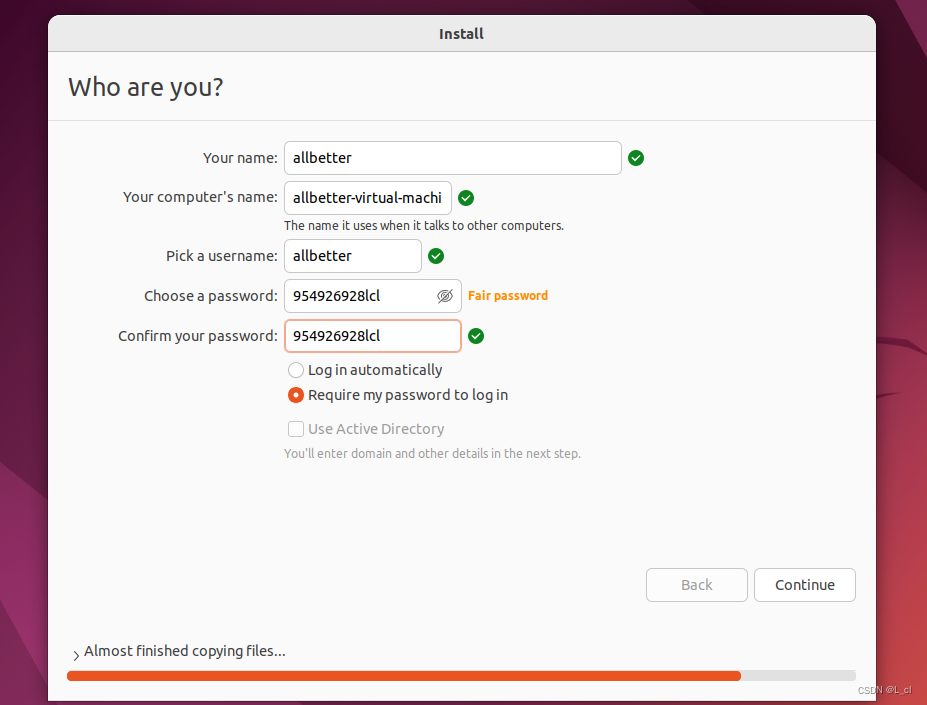
1.5. 设置虚拟机名字、密码
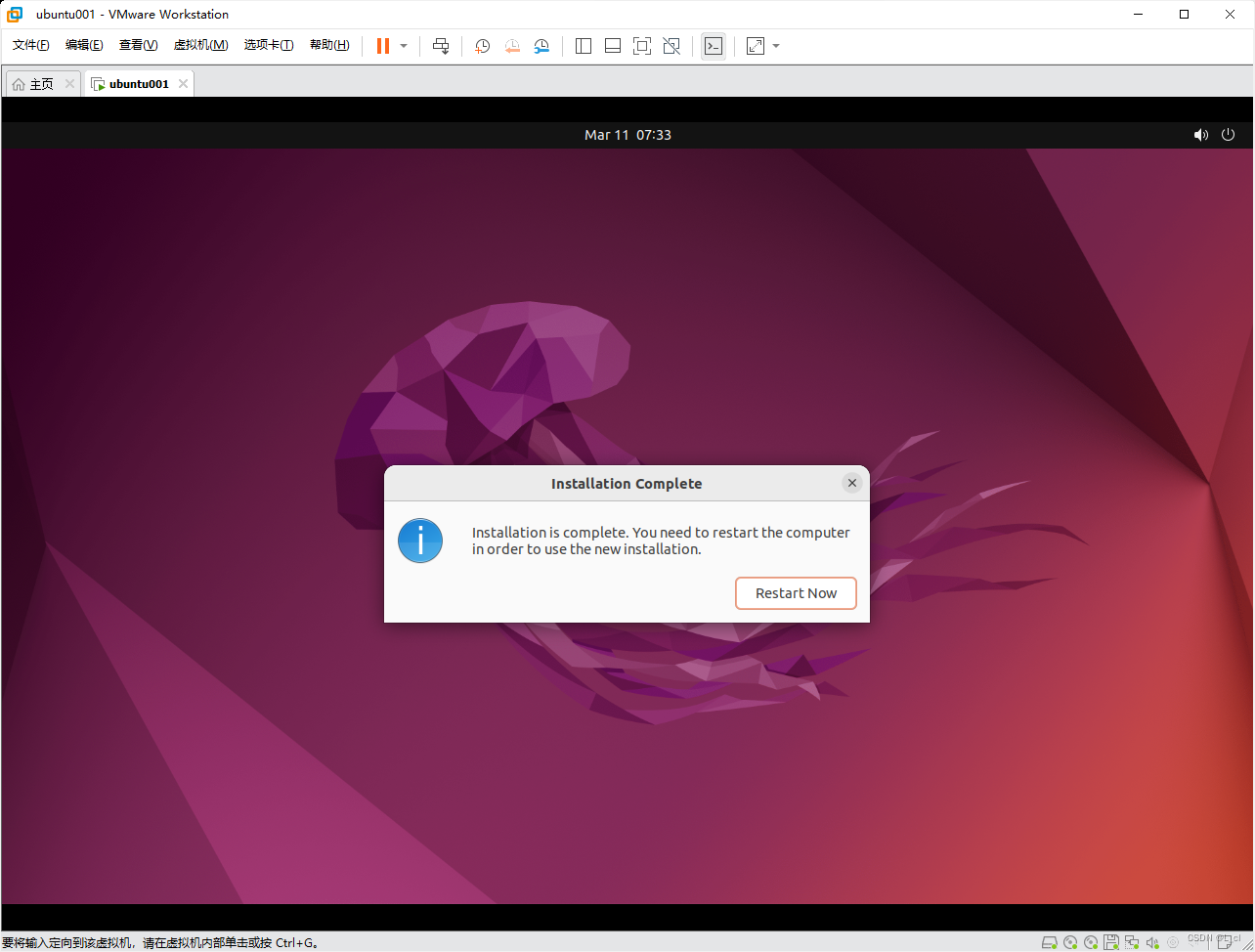
1.6*.更改网络设置,给虚拟机联网
打开设置找到网络(network)
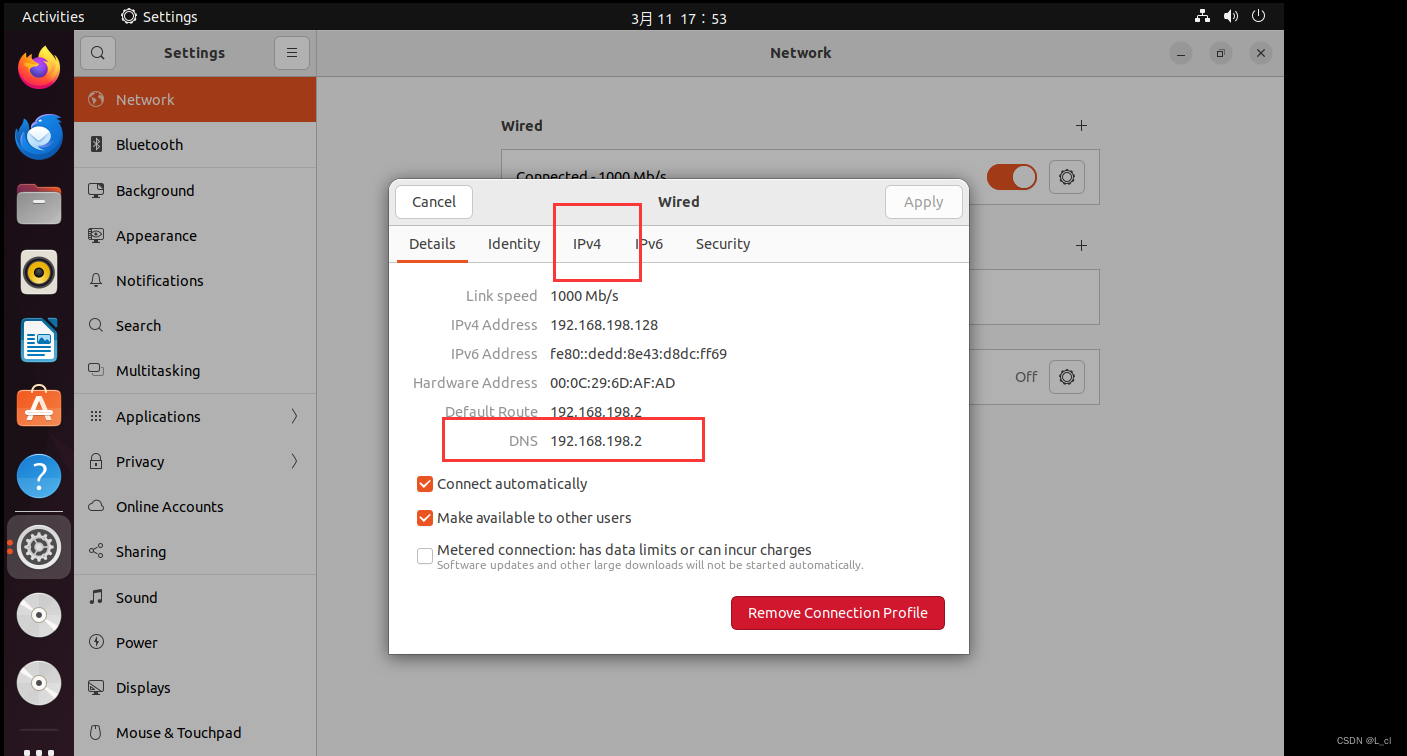
填入上面的DNS
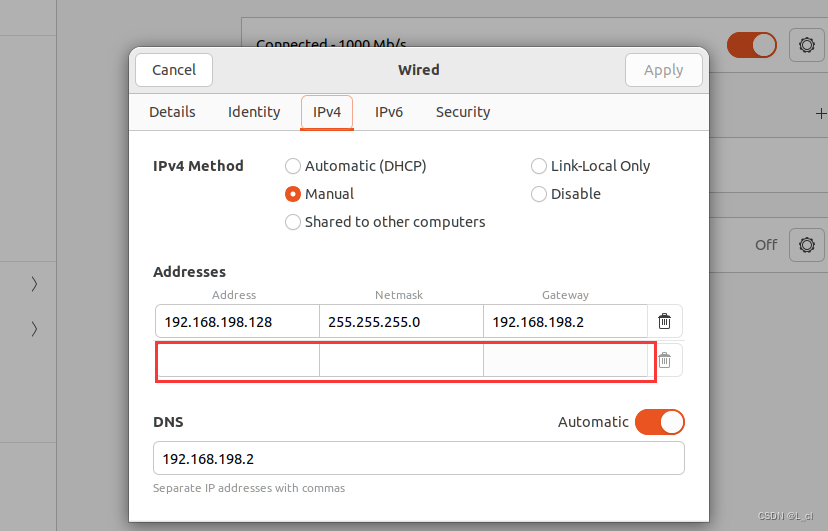
点击修改
1.7*.配置无密码登录
安装SSH

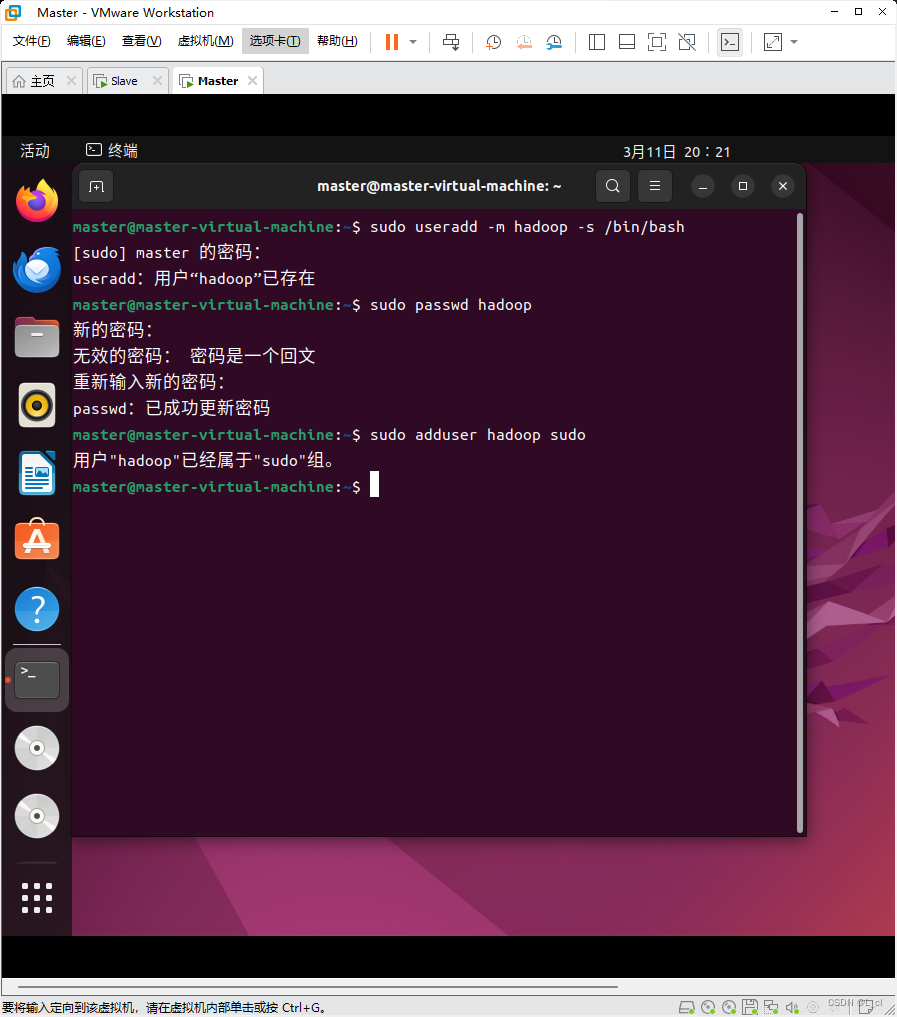
将hadoop用户设置sudo权限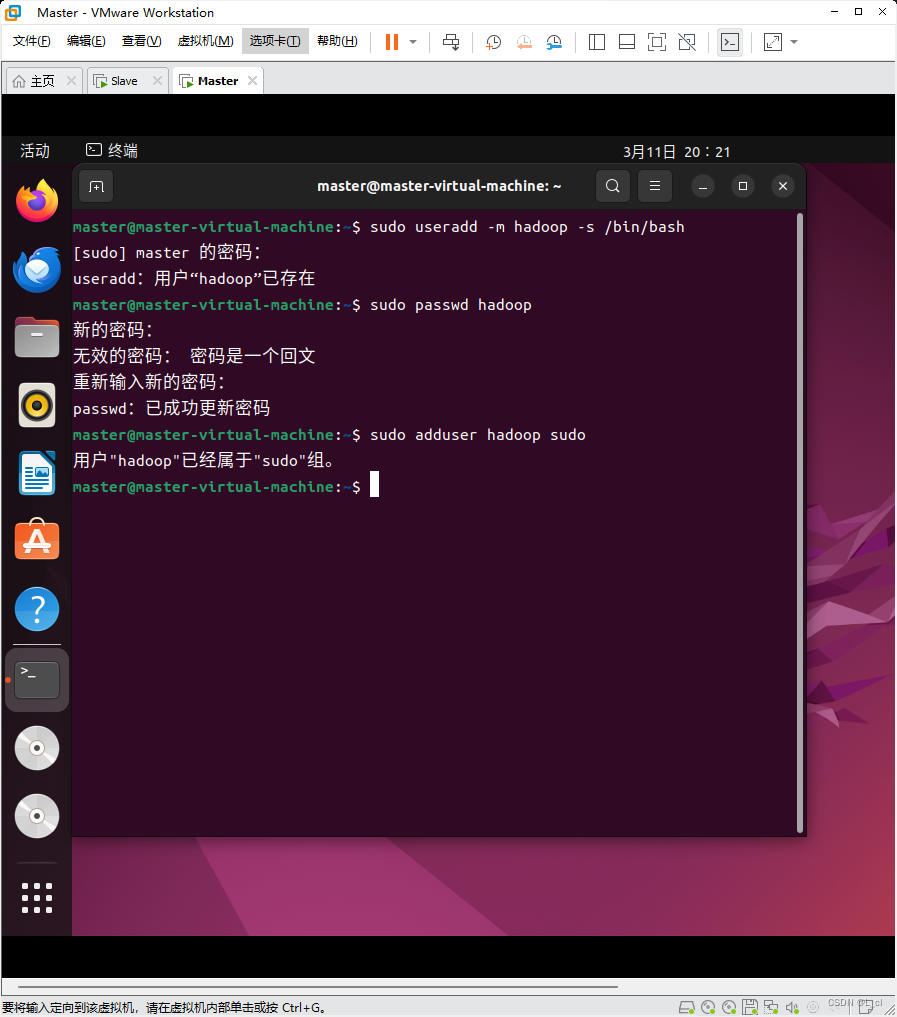
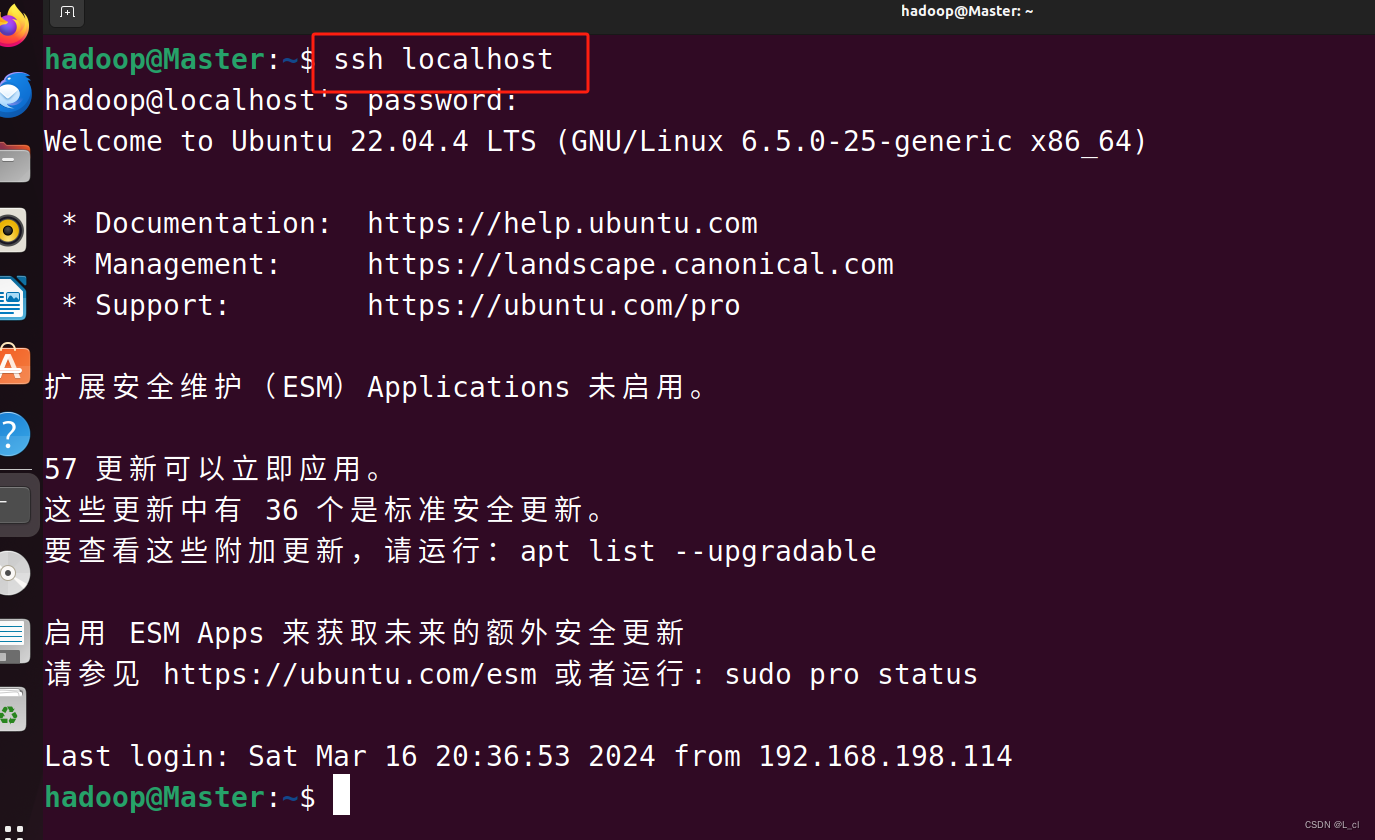
注销 更换用户登录

安装后,可以使用ssh localhost登陆环境
二、更新apt和设置无密码登录
2.1 更新apt
sudo apt 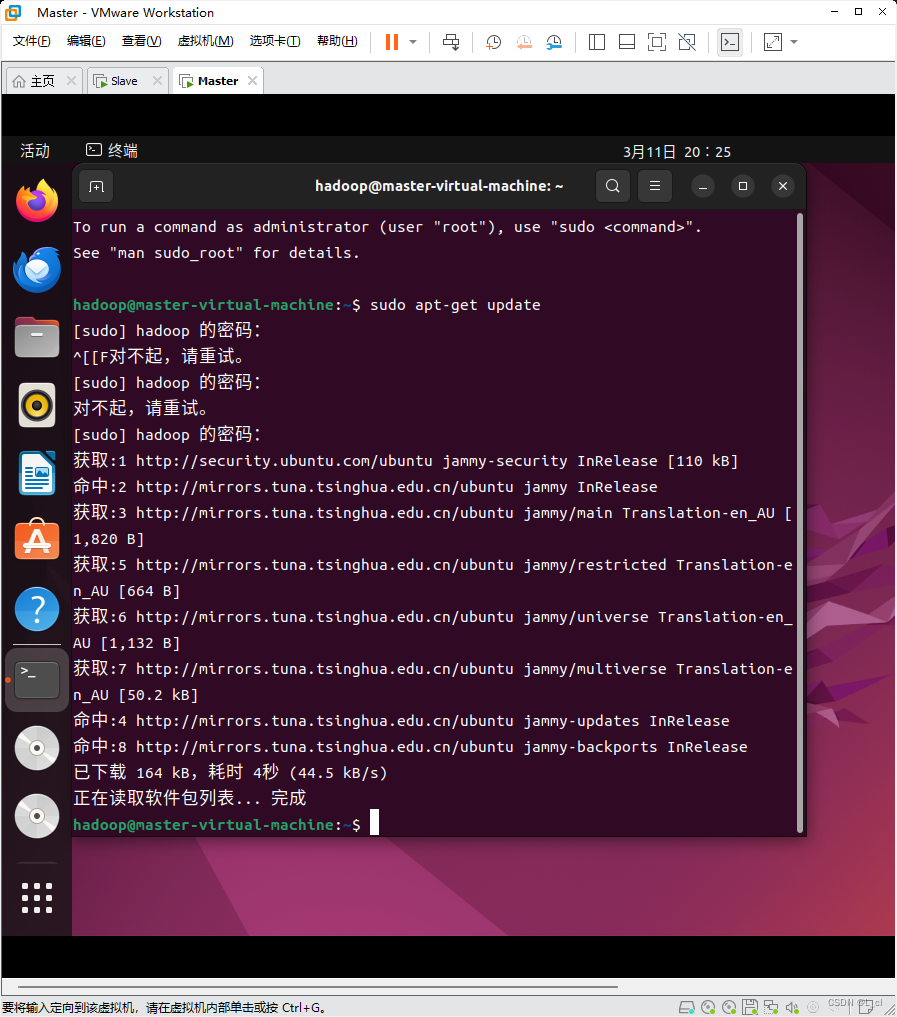
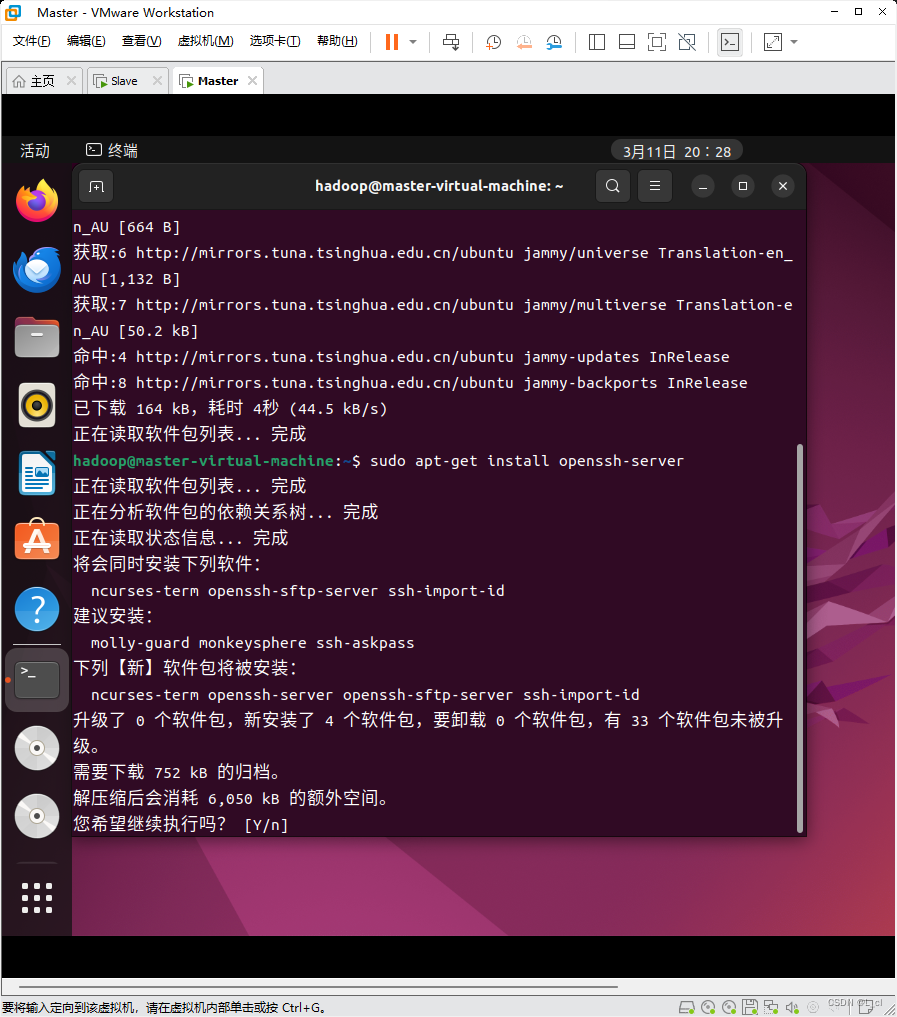
2.2 将ssh连接到本地
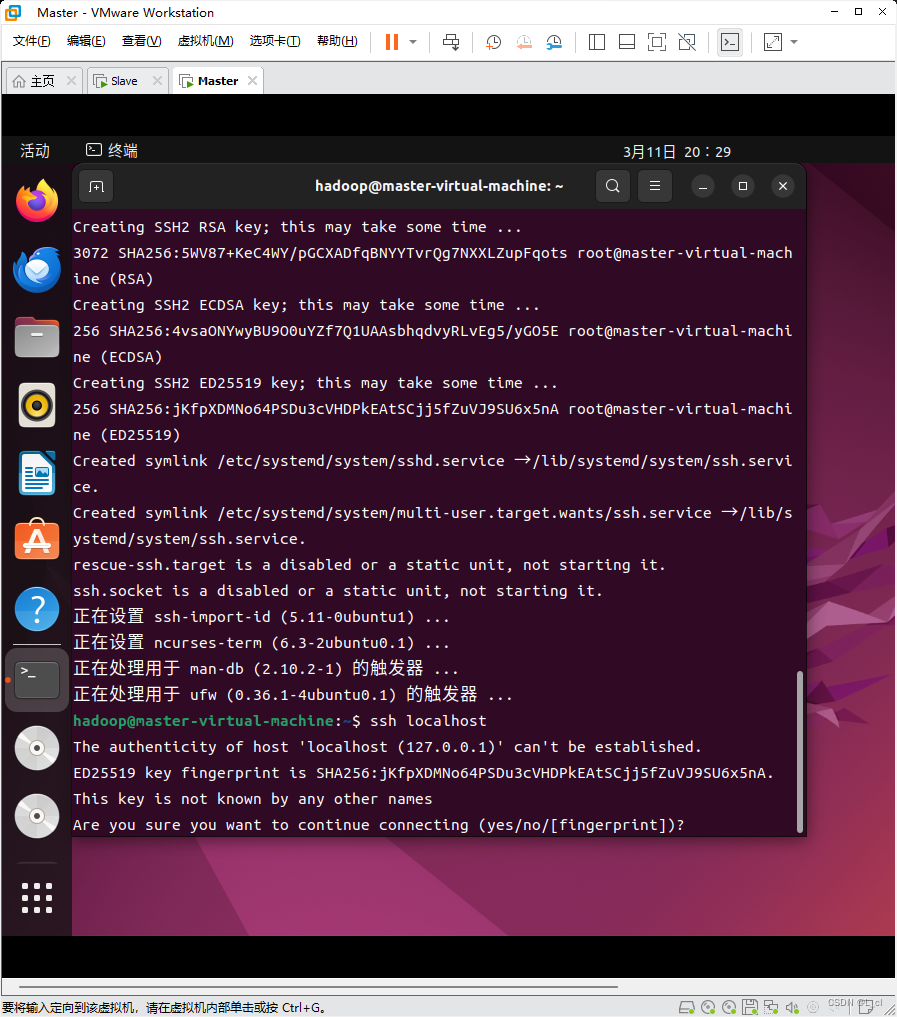
2.3* 配置无密码登录
ssh-keygen -t rsa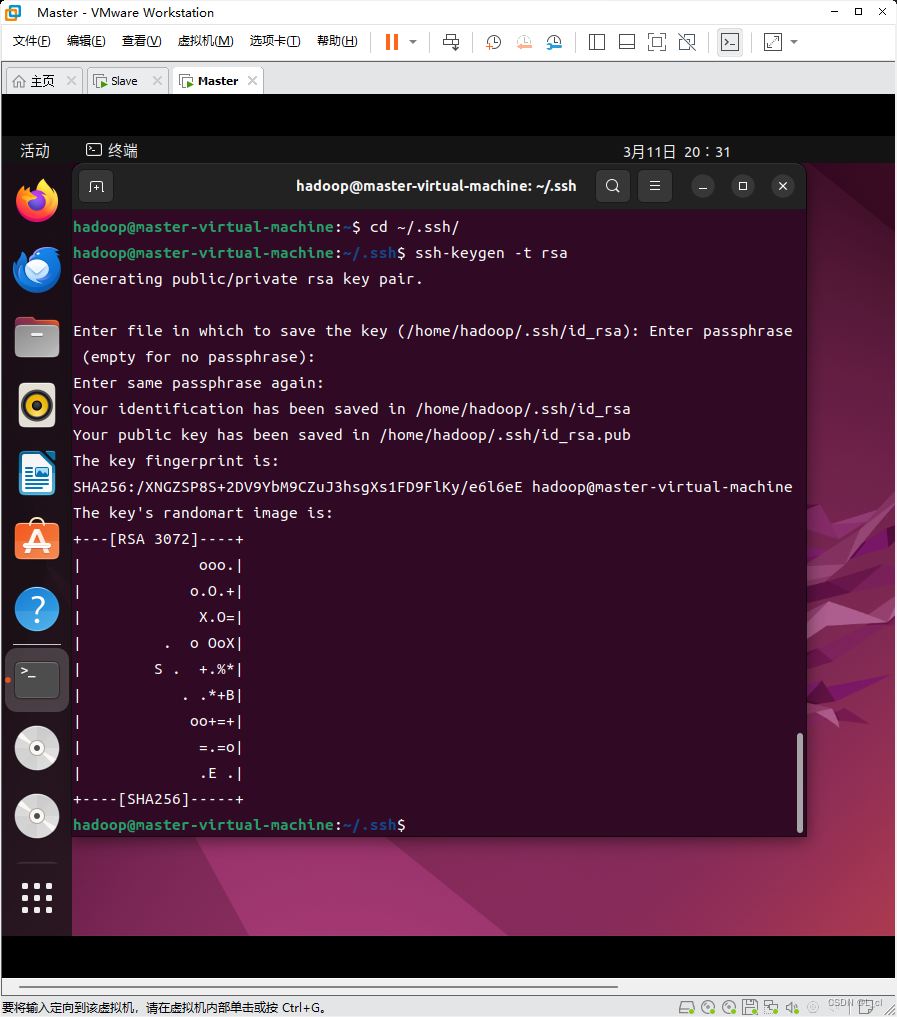
三、安装Java环境
3.1 我们安装java环境,首先cd返回主目录
cd ~3.2 安装jdk-8
JDK文件解压缩以后,可以执行如下命令到/usr/lib/jvm目录查看一下:
ls
sudo apt-get install openjdk-8-jdk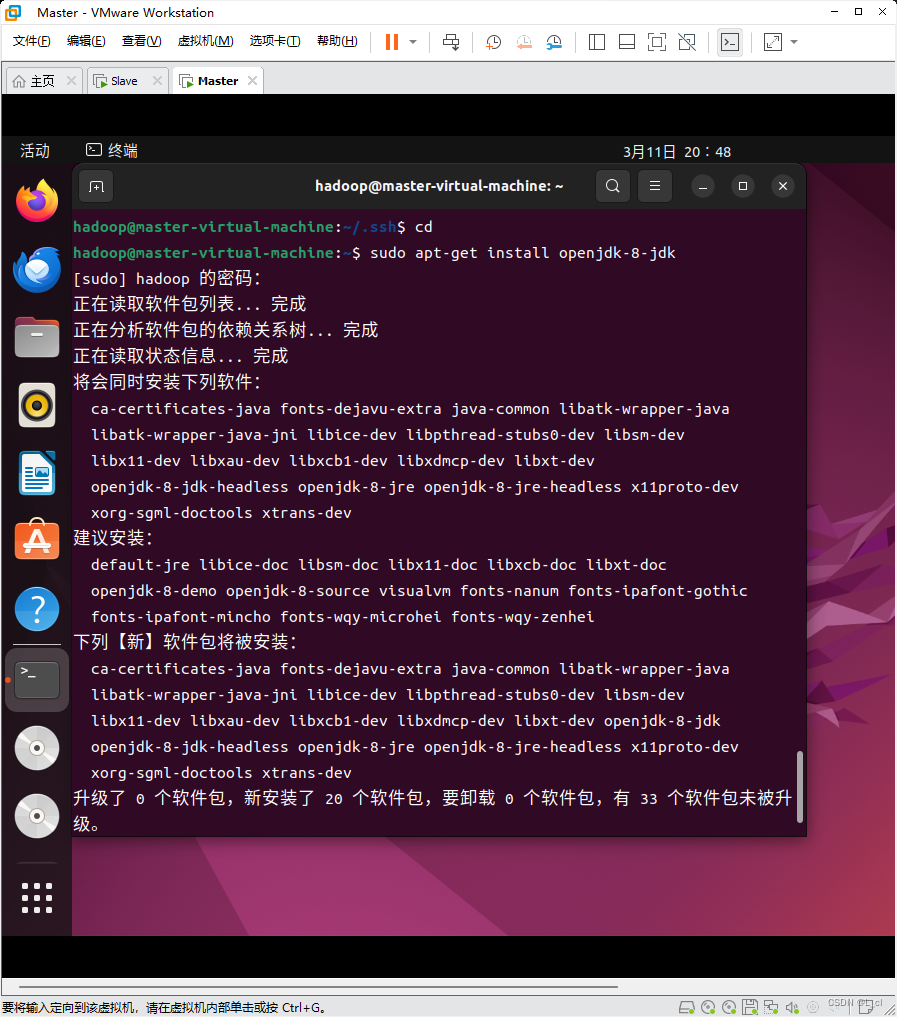
3.3 查看Java版本
java -version
3.4 配置java环境
11.可以看到,在/usr/lib/jvm目录下有个jdk1.8.0_162目录。
下面继续执行如下命令,设置环境变量:
gedit ~/.bashrc在文件最前面添加
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64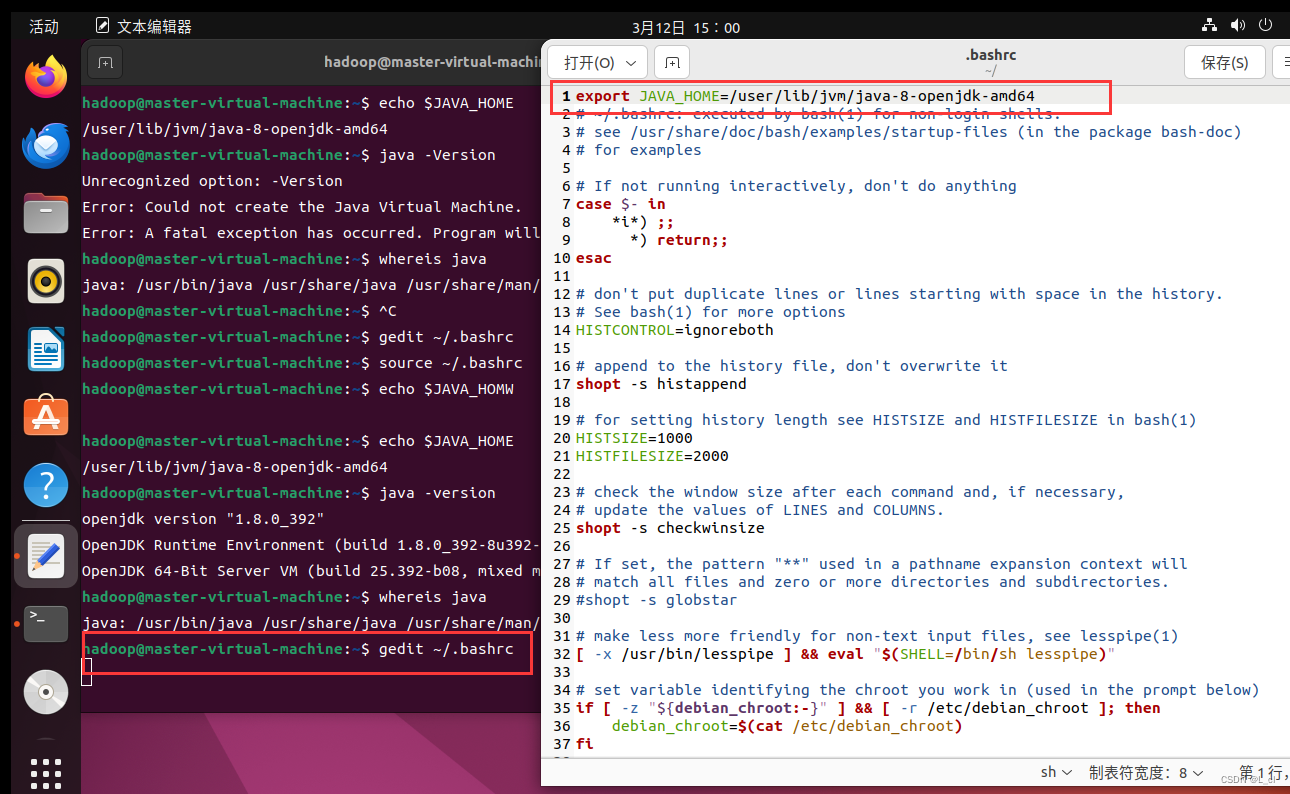
使环境变量生效
source ~/. bashrc![]()
查看设置的环境变量是否生效
echo $JAVA_HOME查看是否是自己安装的java路径和版本
java -versionwhereis java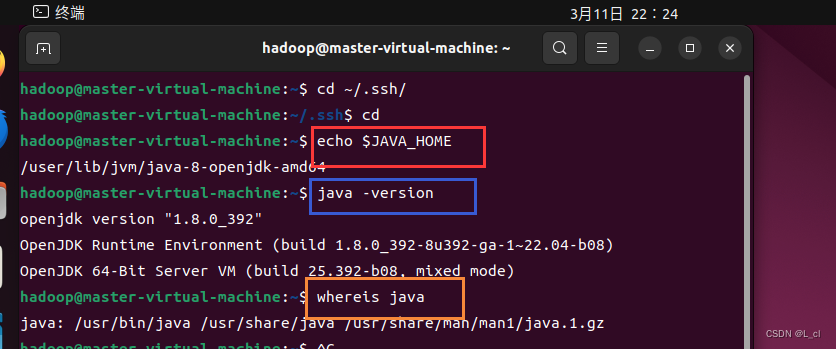
以上环境安装和配置好后,就可以安装Hadoop了
四、配置Hadoop环境
4.2 下载Hadoop
方案一:
hadoop的安装包从Ubuntu自带的火狐浏览器直接下载
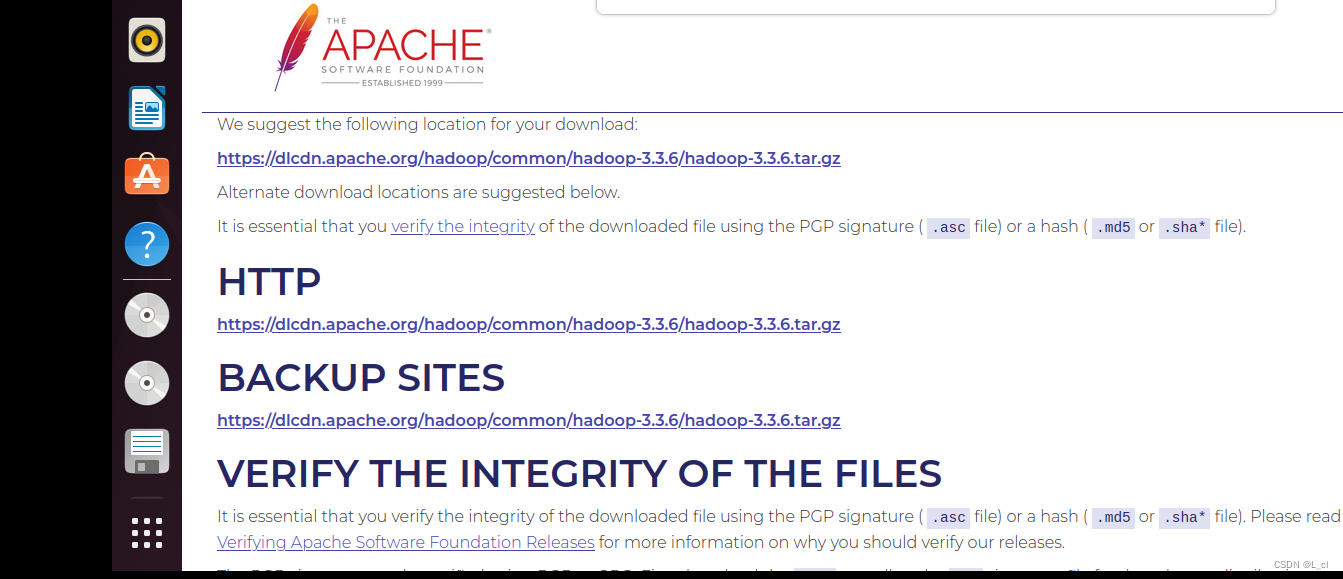
链接:
https://hadoop.apache.org/releases.html
直接复制粘贴在浏览器打开,勾选合适的选项进行下载
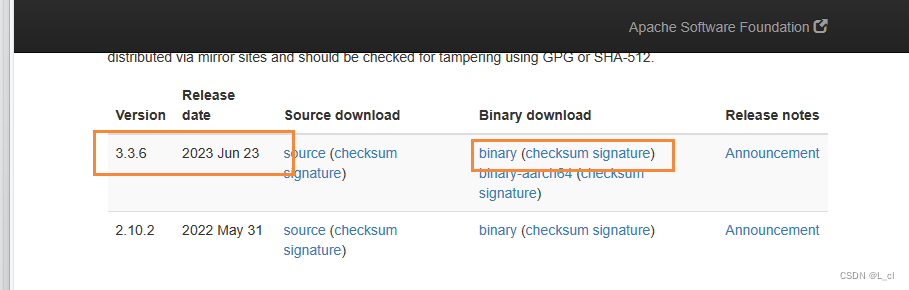
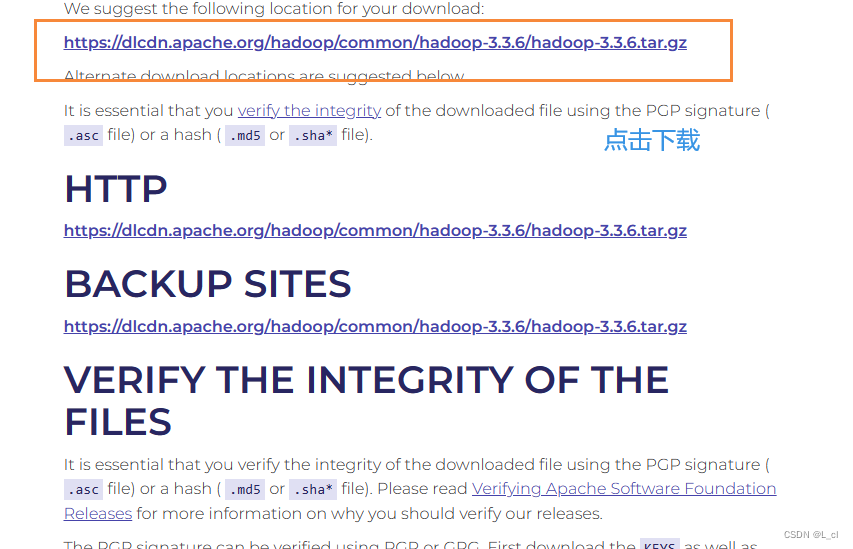
方案二:共享文件夹下载
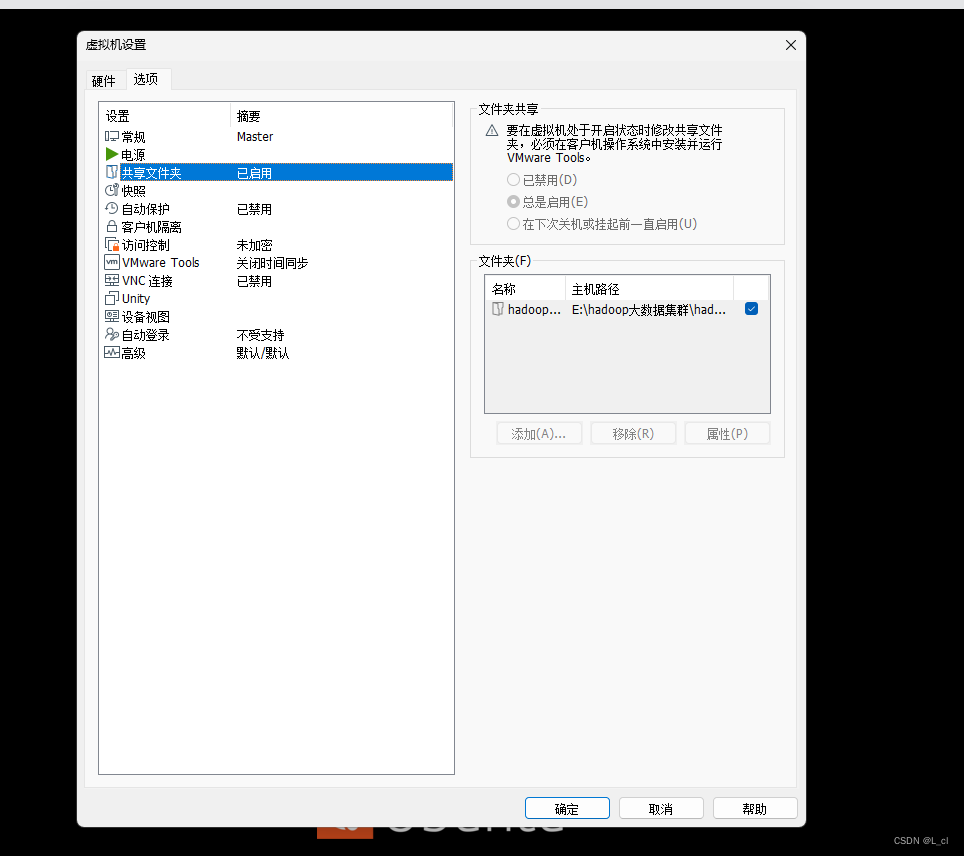
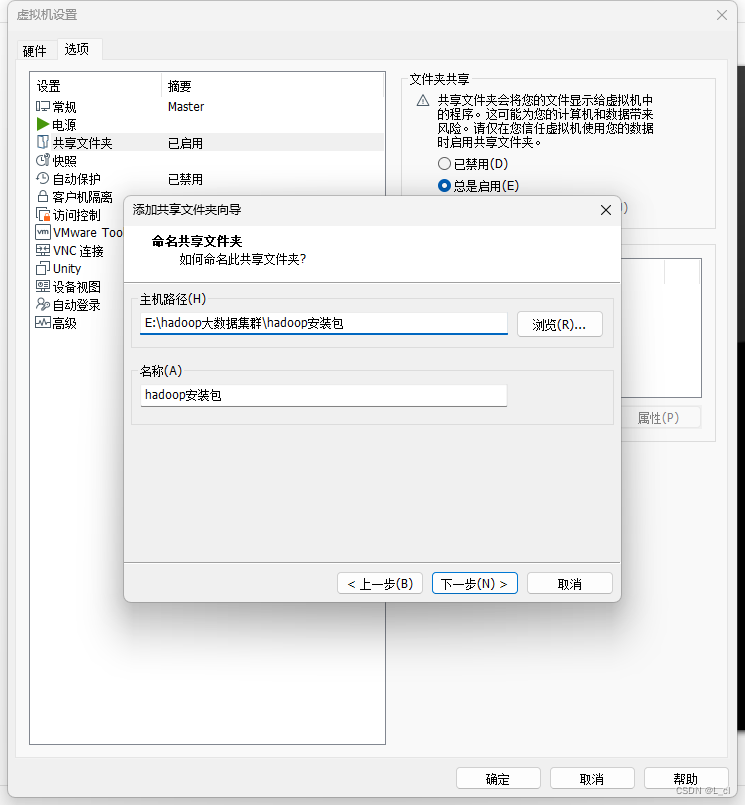
方案三
用国内的镜像下载(Ubuntu自带的火狐浏览器)
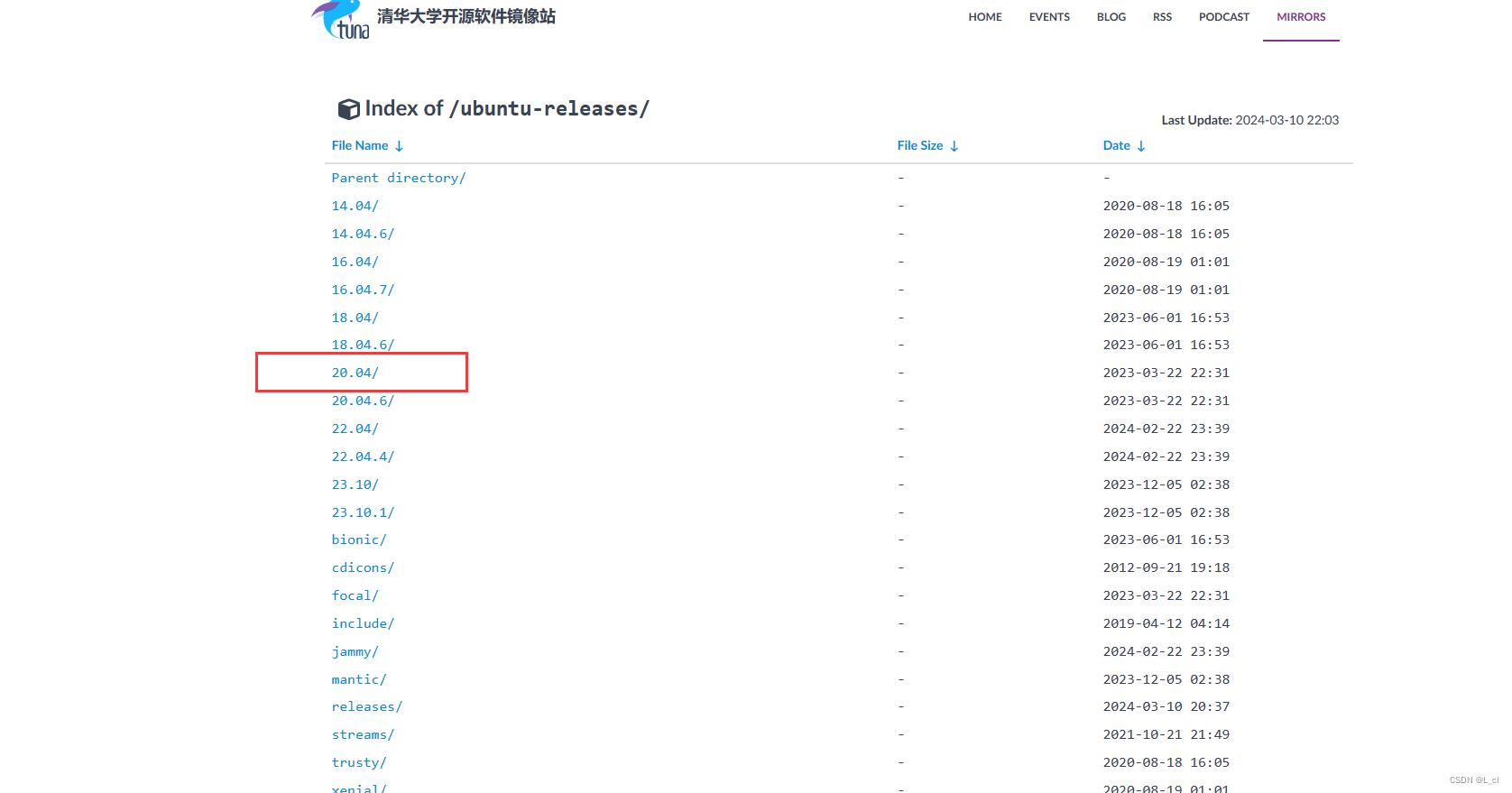
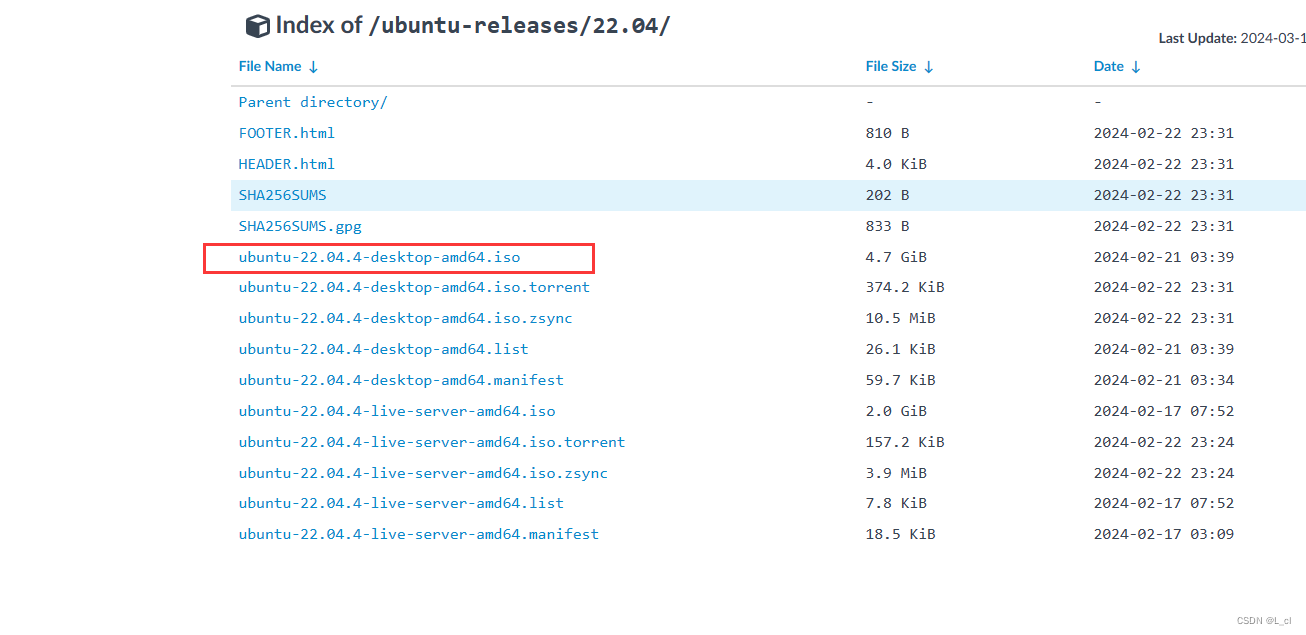
镜像地址:
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/
下载好了以后使用如下命令解压到/usr/local:
sudo tar -zxf /home/hadoop/下载/hadoop-3.3.5.tar.gz -C /usr/local
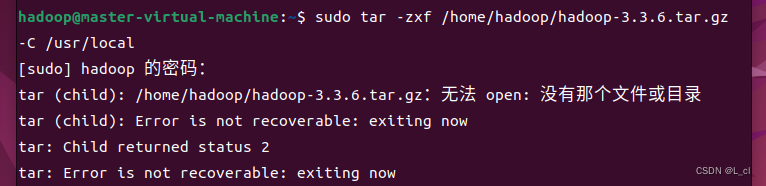
修改权限:
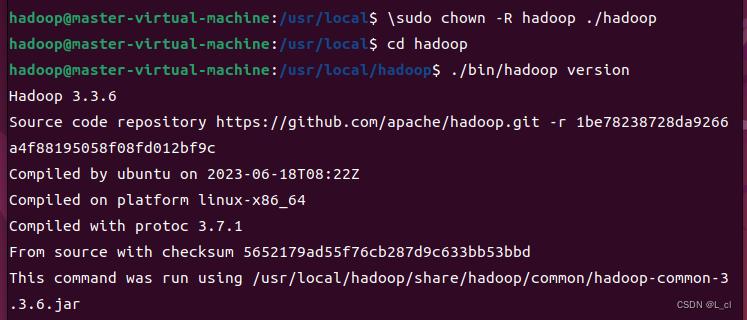
sudo chown -R hadoop ./hadoop
![]()
查看刚才解压的Hadoop是否可用:
cd /usr/local/hadoop
./bin/hadoop version
Hadoop伪分布式配置
接下来是Hadoop伪分布式配置需要修改两个配置文件:
①修改core-site.xml文件:
cd /usr/local/hadoop
gedit ./etc/hadoop/core-site.xml
在configration里添加如下内容:
<property><name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value><description>Abase for other
temporary directories.</description></property><property><name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value></property>
修改完以后保存退出。
②修改hdfs-site.xml文件:
gedit ./etc/hadoop/hdfs-site.xml
在configration里添加如下内容:
<property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property>
修改完保存退出。
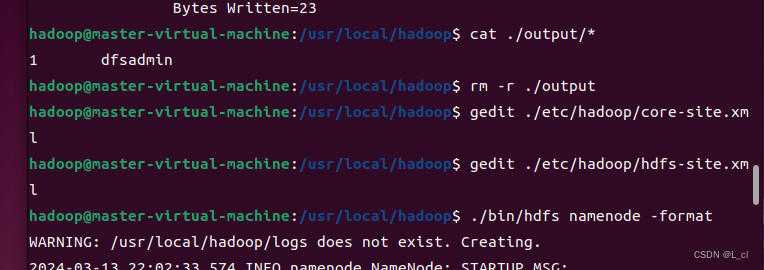
执行namenode的格式化,如果有提示输入Y/N时一定要输入大写的Y:
./bin/hdfs namenode -format
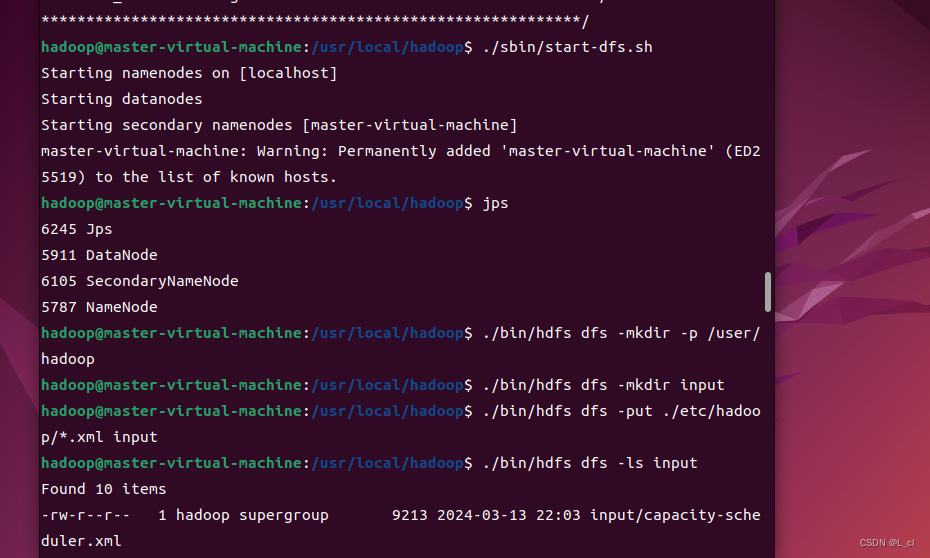
开启NameNode和DataNode的守护进程
./sbin/start-dfs.sh
可以通过jps命令查看是否启动成功:
jps
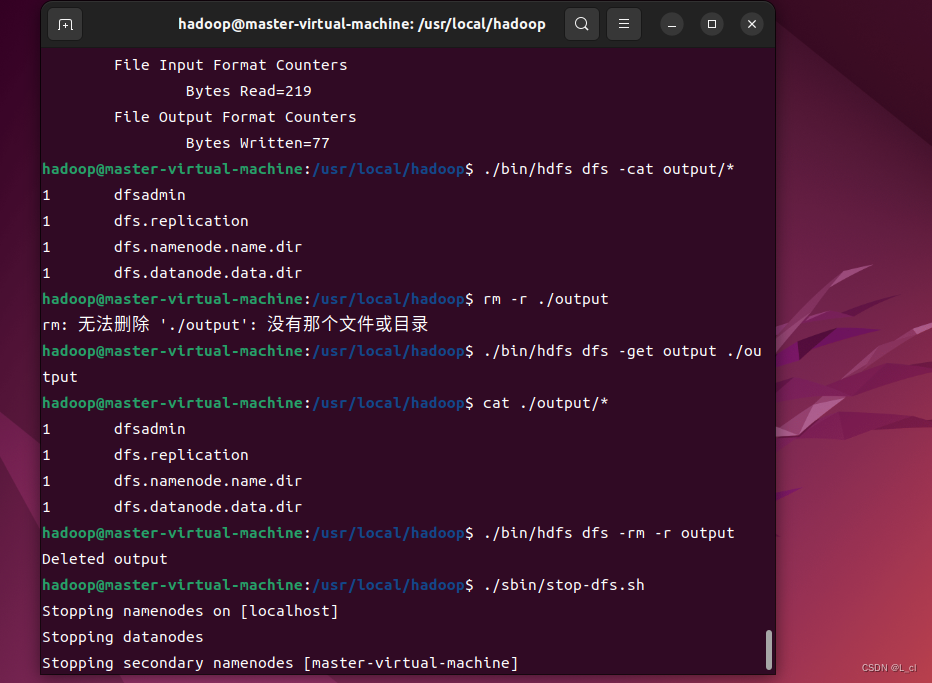
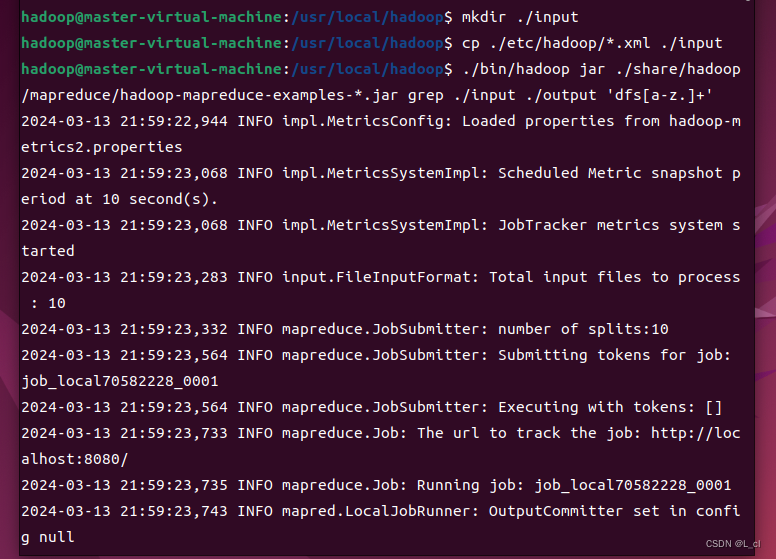
在hdfs上创建一个count目录:
/usr/local/hadoop/bin/hdfs dfs -mkdir /count
显示刚才创建的文件:
usr/local/hadoop/bin/hdfs dfs -ls /
上传一个test3.txt文件到count目录中:
/usr/local/hadoop/bin/hadoop fs -put /home/gufei/test3.txt /count
查看刚才上传的test3.txt文件:
/usr/local/hadoop/bin/hadoop fs -ls /count
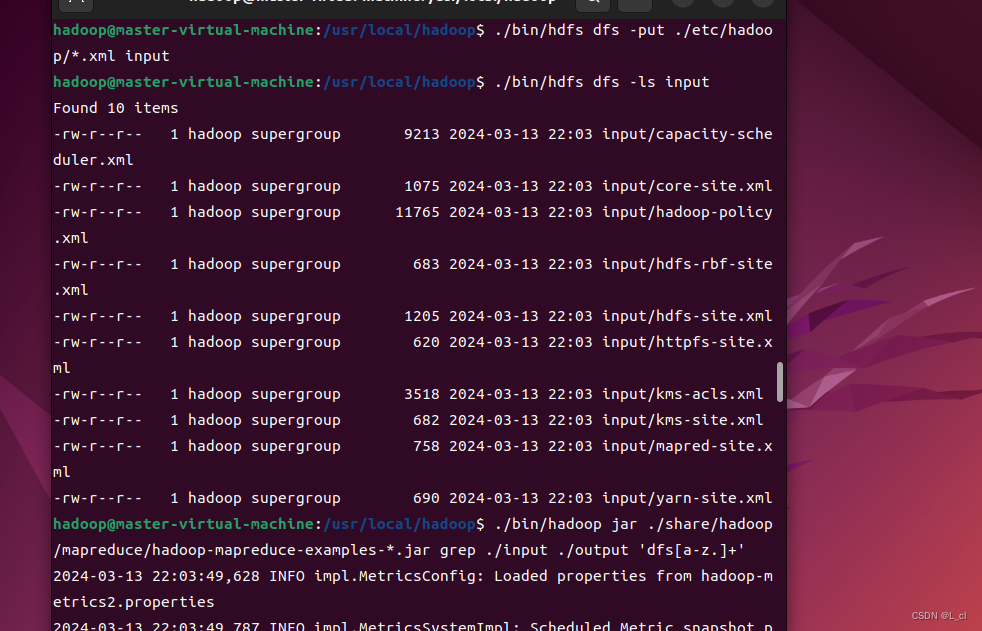
Hadoop伪分布式配置