LeRobot 项目部署运行逻辑(一)——综述
LeRobot 是由 Hugging Face 推出的开源项目:项目地址
首先用一句话简单介绍一下是什么以及为什么:lerobot 可以理解为一套集成了多个知名算法的开源通用架构,因为它将多个算法统一为了一套流程,所以部署起来很方便,并且它还包含仿真环境、预训练模型和数据集,教程极其详细,所以可以节省不少开发时间
如果各位小伙伴之前用源码部署过 ACT/DP/UMI/DEXCAP/IDP3/PI0......那就知道这套架构用起来真的很舒服
LeRobot 为机器人研究和开发提供了一个统一、模块化且可扩展的框架,这样我们只需专注于算法和策略的开发,而无需过多关注底层实现细节
在最新版 Lerobot 的代码库中,配置管理使用了 dataclasses 和 pydantic 替换了 Hydra 的 omegaconf,整体更加简洁和轻量化
老规矩,首先对通用的安装部署流程记个笔记
目录
1 LeRobot:面向真实场景的尖端机器人AI技术
2 安装
3 项目目录
4 数据集可视化
5 LeRobotDataset 格式
6 评估预训练策略
7 训练自定义策略
8 贡献指南
1 LeRobot:面向真实场景的尖端机器人AI技术
🤗 LeRobot旨在提供PyTorch实现的真实世界机器人模型、数据集和工具。其目标是降低机器人技术门槛,让每个人都能通过共享数据集和预训练模型参与其中并获益
🤗 LeRobot包含经实践验证的尖端算法,重点聚焦模仿学习与强化学习领域
🤗 LeRobot现已提供多组预训练模型、人类演示数据集及即用型仿真环境,无需组装实体机器人即可开始实践。未来数周将持续增加对高性价比实体机器人的支持
🤗 LeRobot预训练模型与数据集托管于Hugging Face社区页面:huggingface.co/lerobot
2 安装
下载源代码:
git clone https://github.com/huggingface/lerobot.git
cd lerobot创建 Python 3.10 虚拟环境(以miniconda为例):
conda create -y -n lerobot python=3.10
conda activate lerobot使用miniconda时若缺少ffmpeg:
conda install ffmpeg安装🤗 LeRobot:
pip install --no-binary=av -e .PS:开发 Python 库或应用时,经常需要反复修改代码进行测试。使用 pip install -e . 可以保证每次运行的都是最新的源代码,无需重复安装
NOTE:如遇 build errors,可能需要安装额外依赖(cmake、build-essential 和 ffmpeg 库)。Linux系统请运行:sudo apt-get install cmake build-essential python-dev pkg-config libavformat-dev libavcodec-dev libavdevice-dev libavutil-dev libswscale-dev libswresample-dev libavfilter-dev pkg-config。其他系统参考:Compiling PyAV
对于仿真环境,支持通过附加组件安装:
- aloha
- xarm
- pusht
例如,安装含 aloha 和 pusht 的组件:
pip install --no-binary=av -e ".[aloha, pusht]"使用 Weights and Biases 进行实验追踪,需登录:
wandb login(note:还需在配置中启用WandB,详见下文)
3 项目目录
.
├── examples # contains demonstration examples, start here to learn about LeRobot
| └── advanced # contains even more examples for those who have mastered the basics
├── lerobot
| ├── configs # contains config classes with all options that you can override in the command line
| ├── common # contains classes and utilities
| | ├── datasets # various datasets of human demonstrations: aloha, pusht, xarm
| | ├── envs # various sim environments: aloha, pusht, xarm
| | ├── policies # various policies: act, diffusion, tdmpc
| | ├── robot_devices # various real devices: dynamixel motors, opencv cameras, koch robots
| | └── utils # various utilities
| └── scripts # contains functions to execute via command line
| ├── eval.py # load policy and evaluate it on an environment
| ├── train.py # train a policy via imitation learning and/or reinforcement learning
| ├── control_robot.py # teleoperate a real robot, record data, run a policy
| ├── push_dataset_to_hub.py # convert your dataset into LeRobot dataset format and upload it to the Hugging Face hub
| └── visualize_dataset.py # load a dataset and render its demonstrations
├── outputs # contains results of scripts execution: logs, videos, model checkpoints
└── tests # contains pytest utilities for continuous integration.
├── examples # 演示案例目录,从这里开始学习LeRobot
| └── advanced # 进阶案例├── lerobot
| ├── configs # 包含可通过命令行覆盖的配置类
| ├── common # 核心工具类
| | ├── datasets # 人类演示数据集:aloha, pusht, xarm
| | ├── envs # 仿真环境:aloha, pusht, xarm
| | ├── policies # 策略实现:act, diffusion, tdmpc
| | ├── robot_devices # 实体设备支持:Dynamixel舵机、OpenCV相机、Koch机器人
| | └── utils # 工具函数
| └── scripts # 命令行执行脚本
| ├── eval.py # 加载策略并评估环境表现
| ├── train.py # 通过模仿/强化学习训练策略
| ├── control_robot.py # 实体机器人操控、数据记录、策略运行
| ├── push_dataset_to_hub.py # 转换数据集为LeRobot格式并上传至Hugging Face hub
| └── visualize_dataset.py # 加载数据集并渲染演示
├── outputs # 脚本输出:日志/视频/模型检查点
└── tests # 持续集成测试工具
4 数据集可视化
参考 example 1 了解如何使用自动从 Hugging Face hub 下载数据的数据集类
也可通过命令行脚本可视化 hub 中的数据集片段:
python lerobot/scripts/visualize_dataset.py \--repo-id lerobot/pusht \--episode-index 0或使用 root 选项和 --local-files-only 可视化本地数据集(数据将搜索 ./my_local_data_dir/lerobot/pusht 路径):
python lerobot/scripts/visualize_dataset.py \--repo-id lerobot/pusht \--root ./my_local_data_dir \--local-files-only 1 \--episode-index 0脚本将启动 rerun.io 展示相机流、机器人状态与动作,效果如下:

该脚本也支持远程服务器数据集可视化。更多指令见 python lerobot/scripts/visualize_dataset.py --help
5 LeRobotDataset 格式
LeRobotDataset 格式简单易用
从 Hugging Face hub 或本地文件夹加载,如:dataset = LeRobotDataset("lerobot/aloha_static_coffee") 后,可像常规 Hugging Face/PyTorch 数据集一样索引访问。例如 dataset[0] 将返回包含观察值和动作的 PyTorch 张量帧
LeRobotDataset 的一个特殊之处在于,它不仅仅是通过一个索引来检索单个帧,而是可以基于与该索引帧在时间上的关系,检索出多个帧。这是通过将 delta_timestamps 参数设置为相对于索引帧的相对时间列表来实现的。例如,若设置 delta_timestamps 为
{"observation.image": [-1, -0.5, -0.2, 0]},那么对于任意给定的索引,可以检索出 4 帧:
-
3 帧分别是比索引帧提前 1 秒、0.5 秒和 0.2 秒的 “前一帧”
-
以及索引帧本身(对应 0 的那一项)
更多关于 delta_timestamps 的细节,请参见示例 1_load_lerobot_dataset.py
在底层实现中,LeRobotDataset 格式采用了多种数据序列化方法。如果想更深入地使用这种格式,了解这些序列化方式会非常有帮助。LeRobotDataset 致力于构建一种既灵活又简单的数据集格式,该格式能够覆盖强化学习和机器人技术中大部分特性和特殊性,既适用于仿真也适用于真实世界的场景。该设计主要关注摄像头数据和机器人状态,但只要其他类型的传感器输入能够表示为张量,也可以轻松扩展到它们上
下面给出了一个典型 LeRobotDataset 的重要细节和内部结构组织说明
以 dataset = LeRobotDataset("lerobot/aloha_static_coffee 实例化的数据集为例。不同数据集的具体特征可能会有所不同,但主要的组织结构和概念保持一致:
dataset attributes:├ hf_dataset: a Hugging Face dataset (backed by Arrow/parquet). Typical features example:│ ├ observation.images.cam_high (VideoFrame):│ │ VideoFrame = {'path': path to a mp4 video, 'timestamp' (float32): timestamp in the video}│ ├ observation.state (list of float32): position of an arm joints (for instance)│ ... (more observations)│ ├ action (list of float32): goal position of an arm joints (for instance)│ ├ episode_index (int64): index of the episode for this sample│ ├ frame_index (int64): index of the frame for this sample in the episode ; starts at 0 for each episode│ ├ timestamp (float32): timestamp in the episode│ ├ next.done (bool): indicates the end of en episode ; True for the last frame in each episode│ └ index (int64): general index in the whole dataset├ episode_data_index: contains 2 tensors with the start and end indices of each episode│ ├ from (1D int64 tensor): first frame index for each episode — shape (num episodes,) starts with 0│ └ to: (1D int64 tensor): last frame index for each episode — shape (num episodes,)├ stats: a dictionary of statistics (max, mean, min, std) for each feature in the dataset, for instance│ ├ observation.images.cam_high: {'max': tensor with same number of dimensions (e.g. `(c, 1, 1)` for images, `(c,)` for states), etc.}│ ...├ info: a dictionary of metadata on the dataset│ ├ codebase_version (str): this is to keep track of the codebase version the dataset was created with│ ├ fps (float): frame per second the dataset is recorded/synchronized to│ ├ video (bool): indicates if frames are encoded in mp4 video files to save space or stored as png files│ └ encoding (dict): if video, this documents the main options that were used with ffmpeg to encode the videos├ videos_dir (Path): where the mp4 videos or png images are stored/accessed└ camera_keys (list of string): the keys to access camera features in the item returned by the dataset (e.g. `["observation.images.cam_high", ...]`)dataset attributes:
├ hf_dataset: 一个基于 Hugging Face 数据集(由 Arrow/parquet 支持)的数据集。典型的特征示例如下:
│ ├ observation.images.cam_high (VideoFrame):
│ │ VideoFrame = {'path': 指向 mp4 视频的路径, 'timestamp' (float32): 视频中的时间戳}
│ ├ observation.state (float32 列表): 比如描述机器臂各关节位置的信息
│ ... (更多的观测信息)
│ ├ action (float32 列表): 例如描述机器臂各关节目标位置的信息
│ ├ episode_index (int64): 当前样本所属 episode 的索引
│ ├ frame_index (int64): 当前样本在该 episode 中的帧索引;每个 episode 的帧索引均从 0 开始
│ ├ timestamp (float32): 当前 episode 中的时间戳
│ ├ next.done (bool): 指示是否为该 episode 的结束帧;每个 episode 的最后一帧对应 True
│ └ index (int64): 数据集中全局样本的索引
├ episode_data_index: 包含两个张量,记录每个 episode 的起始和结束帧索引
│ ├ from (一维 int64 张量): 每个 episode 的第一帧索引 — 形状为 (episode 数量,), 从 0 开始
│ └ to (一维 int64 张量): 每个 episode 的最后一帧索引 — 形状为 (episode 数量,)
├ stats: 一个字典,用于保存数据集中各特征的统计信息(例如最大值、均值、最小值、标准差),例如:
│ ├ observation.images.cam_high: {'max': 与实际数据维度相同的张量(例如对图像为 (c, 1, 1),对状态为 (c,)),等等。}
│ ...
├ info: 一个包含数据集元数据的字典,其中包括:
│ ├ codebase_version (字符串): 用于记录生成该数据集时使用的代码库版本
│ ├ fps (浮点数): 数据集记录或同步时的帧率
│ ├ video (布尔值): 表示是否将帧以 mp4 视频文件形式编码以节省空间,或者直接存储为 png 图像文件
│ └ encoding (字典): 如果视频以 mp4 格式存储,这里记录了使用 ffmpeg 进行编码时所采用的主要选项
├ videos_dir (Path): 指向存储/访问 mp4 视频或 png 图像的目录
└ camera_keys (字符串列表): 用于访问返回样本中摄像头特征的键(例如 ["observation.images.cam_high", ...])
LeRobotDataset 利用多种广泛使用的文件格式对各个部分进行序列化,具体如下:
-
hf_dataset:使用 Hugging Face datasets 库进行序列化,保存为 parquet 格式
-
视频:以 mp4 格式存储,以达到节省存储空间的目的
-
元数据:以普通的 json 或 jsonl 文件形式存储
此外,数据集可以无缝地上传到或从 HuggingFace Hub 下载。如果需要在本地使用数据集,可以通过指定 root 参数来设置数据集的位置(如果它不在默认的 ~/.cache/huggingface/lerobot 路径下)。
6 评估预训练策略
参考 example 2 ,该示例展示了如何从 Hugging Face Hub 下载预训练的策略(policy),并在与该策略对应的环境中运行评估
此外还提供了一个更强大的脚本,可以在一次 rollout 中对多个环境进行并行评估。以下是一个使用托管在 lerobot/diffusion_pusht 上的预训练模型的示例命令:
python lerobot/scripts/eval.py \--policy.path=lerobot/diffusion_pusht \--env.type=pusht \--eval.batch_size=10 \--eval.n_episodes=10 \--policy.use_amp=false \--policy.device=cudaNote:训练完成后可通过以下命令重新评估检查点:
python lerobot/scripts/eval.py --policy.path={OUTPUT_DIR}/checkpoints/last/pretrained_model更多指令见 python lerobot/scripts/eval.py --help
7 训练自定义策略
参考 example 3 了解如何使用核心 Python 库训练模型,同时 example 4 如何从命令行调用训练脚本
使用 wandb 记录训练曲线前需执行 wandb login 确保完成登录。训练时通过 --wandb.enable=true 启用日志功能
终端将显示黄色日志链接。浏览器查看效果示例如下,指标说明参见 here
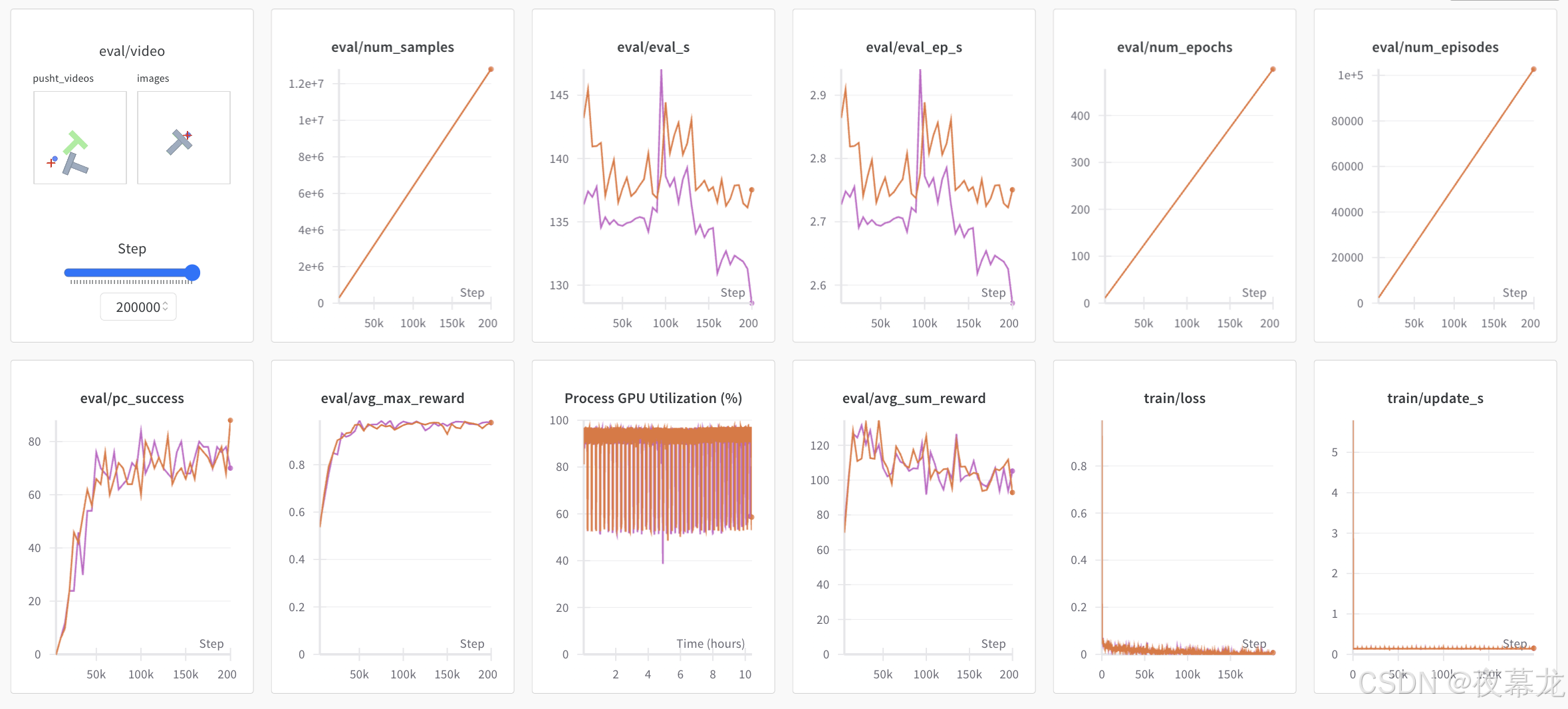
Note:出于效率考虑,在训练过程中,每个检查点(checkpoint)通常只会在较少的 episode 上进行评估。可以使用 --eval.n_episodes=500 来比默认值评估更多的 episode;或者在训练结束后,如果希望对表现最佳的 checkpoints 使用更多的 episode 或调整其他评估设置进行重新评估。更多设置选项请参见 python lerobot/scripts/eval.py --help
复现 state-of-the-art (SOTA)
在 hub page 提供多个 SOTA 性能的预训练策略。通过加载原始运行配置即可复现训练,例如:
python lerobot/scripts/train.py --config_path=lerobot/diffusion_pusht将复现 PushT 任务上 Diffusion Policy 的 SOTA 结果
8 贡献指南
欢迎参与🤗 LeRobot开发,请参阅contribution guide
添加预训练策略
当训练完成后,可通过一个像 ${hf_user}/${repo_name} 格式的 hub id(e.g. lerobot/diffusion_pusht)上传至Hugging Face hub
首先,需定位实验目录中的检查点文件夹(e.g. outputs/train/2024-05-05/20-21-12_aloha_act_default/checkpoints/002500),其中 pretrained_model 目录应包含:
-
config.json: 策略配置序列化文件(遵循策略的 dataclass 配置)
-
model.safetensors: 一组 torch.nn.Module 参数,采用 Hugging Face Safetensors 格式保存
-
train_config.json: 完整训练配置(与config.json一致)
上传命令:
huggingface-cli upload ${hf_user}/${repo_name} path/to/pretrained_model他人可通过 eval.py 使用此策略
性能分析工具
以下是一个用于对策略评估过程进行性能分析的代码示例:
from torch.profiler import profile, record_function, ProfilerActivitydef trace_handler(prof):prof.export_chrome_trace(f"tmp/trace_schedule_{prof.step_num}.json")with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],schedule=torch.profiler.schedule(wait=2,warmup=2,active=3,),on_trace_ready=trace_handler
) as prof:with record_function("eval_policy"):for i in range(num_episodes):prof.step()# insert code to profile, potentially whole body of eval_policy function