目标检测任务 - 数据增强
目标检测任务 - DETR : 数据预处理/数据增强 算法源码实例
import datasets.transforms as Tnormalize = T.Compose([T.ToTensor(),T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])scales = [480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800]if image_set == 'train':return T.Compose([T.RandomHorizontalFlip(),T.RandomSelect(T.RandomResize(scales, max_size=1333),T.Compose([T.RandomResize([400, 500, 600]),T.RandomSizeCrop(384, 600),T.RandomResize(scales, max_size=1333),])),normalize,])if image_set == 'val':return T.Compose([T.RandomResize([800], max_size=1333),normalize,])以下为 datasets/transforms.py 文件
# datasets/transforms.py
import randomimport PIL
import torch
import torchvision.transforms as T
import torchvision.transforms.functional as Ffrom util.box_ops import box_xyxy_to_cxcywh
from util.misc import interpolatedef crop(image, target, region):cropped_image = F.crop(image, *region)target = target.copy()i, j, h, w = region# should we do something wrt the original size?target["size"] = torch.tensor([h, w])fields = ["labels", "area", "iscrowd"]if "boxes" in target:boxes = target["boxes"]max_size = torch.as_tensor([w, h], dtype=torch.float32)cropped_boxes = boxes - torch.as_tensor([j, i, j, i])cropped_boxes = torch.min(cropped_boxes.reshape(-1, 2, 2), max_size)cropped_boxes = cropped_boxes.clamp(min=0)area = (cropped_boxes[:, 1, :] - cropped_boxes[:, 0, :]).prod(dim=1)target["boxes"] = cropped_boxes.reshape(-1, 4)target["area"] = areafields.append("boxes")if "masks" in target:# FIXME should we update the area here if there are no boxes?target['masks'] = target['masks'][:, i:i + h, j:j + w]fields.append("masks")# remove elements for which the boxes or masks that have zero areaif "boxes" in target or "masks" in target:# favor boxes selection when defining which elements to keep# this is compatible with previous implementationif "boxes" in target:cropped_boxes = target['boxes'].reshape(-1, 2, 2)keep = torch.all(cropped_boxes[:, 1, :] > cropped_boxes[:, 0, :], dim=1)else:keep = target['masks'].flatten(1).any(1)for field in fields:target[field] = target[field][keep]return cropped_image, targetdef hflip(image, target):flipped_image = F.hflip(image)w, h = image.sizetarget = target.copy()if "boxes" in target:boxes = target["boxes"]boxes = boxes[:, [2, 1, 0, 3]] * torch.as_tensor([-1, 1, -1, 1]) + torch.as_tensor([w, 0, w, 0])target["boxes"] = boxesif "masks" in target:target['masks'] = target['masks'].flip(-1)return flipped_image, targetdef resize(image, target, size, max_size=None):# size can be min_size (scalar) or (w, h) tupledef get_size_with_aspect_ratio(image_size, size, max_size=None):w, h = image_sizeif max_size is not None:min_original_size = float(min((w, h)))max_original_size = float(max((w, h)))if max_original_size / min_original_size * size > max_size:size = int(round(max_size * min_original_size / max_original_size))if (w <= h and w == size) or (h <= w and h == size):return (h, w)if w < h:ow = sizeoh = int(size * h / w)else:oh = sizeow = int(size * w / h)return (oh, ow)def get_size(image_size, size, max_size=None):if isinstance(size, (list, tuple)):return size[::-1]else:return get_size_with_aspect_ratio(image_size, size, max_size)size = get_size(image.size, size, max_size)rescaled_image = F.resize(image, size)if target is None:return rescaled_image, Noneratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(rescaled_image.size, image.size))ratio_width, ratio_height = ratiostarget = target.copy()if "boxes" in target:boxes = target["boxes"]scaled_boxes = boxes * torch.as_tensor([ratio_width, ratio_height, ratio_width, ratio_height])target["boxes"] = scaled_boxesif "area" in target:area = target["area"]scaled_area = area * (ratio_width * ratio_height)target["area"] = scaled_areah, w = sizetarget["size"] = torch.tensor([h, w])if "masks" in target:target['masks'] = interpolate(target['masks'][:, None].float(), size, mode="nearest")[:, 0] > 0.5return rescaled_image, targetdef pad(image, target, padding):# assumes that we only pad on the bottom right cornerspadded_image = F.pad(image, (0, 0, padding[0], padding[1]))if target is None:return padded_image, Nonetarget = target.copy()# should we do something wrt the original size?target["size"] = torch.tensor(padded_image.size[::-1])if "masks" in target:target['masks'] = torch.nn.functional.pad(target['masks'], (0, padding[0], 0, padding[1]))return padded_image, targetclass ResizeDebug(object):def __init__(self, size):self.size = sizedef __call__(self, img, target):return resize(img, target, self.size)class RandomCrop(object):def __init__(self, size):self.size = sizedef __call__(self, img, target):region = T.RandomCrop.get_params(img, self.size)return crop(img, target, region)class RandomSizeCrop(object):def __init__(self, min_size: int, max_size: int):self.min_size = min_sizeself.max_size = max_sizedef __call__(self, img: PIL.Image.Image, target: dict):w = random.randint(self.min_size, min(img.width, self.max_size))h = random.randint(self.min_size, min(img.height, self.max_size))region = T.RandomCrop.get_params(img, [h, w])return crop(img, target, region)class CenterCrop(object):def __init__(self, size):self.size = sizedef __call__(self, img, target):image_width, image_height = img.sizecrop_height, crop_width = self.sizecrop_top = int(round((image_height - crop_height) / 2.))crop_left = int(round((image_width - crop_width) / 2.))return crop(img, target, (crop_top, crop_left, crop_height, crop_width))class RandomHorizontalFlip(object):def __init__(self, p=0.5):self.p = pdef __call__(self, img, target):if random.random() < self.p:return hflip(img, target)return img, targetclass RandomResize(object):def __init__(self, sizes, max_size=None):assert isinstance(sizes, (list, tuple))self.sizes = sizesself.max_size = max_sizedef __call__(self, img, target=None):size = random.choice(self.sizes)return resize(img, target, size, self.max_size)class RandomPad(object):def __init__(self, max_pad):self.max_pad = max_paddef __call__(self, img, target):pad_x = random.randint(0, self.max_pad)pad_y = random.randint(0, self.max_pad)return pad(img, target, (pad_x, pad_y))class RandomSelect(object):"""Randomly selects between transforms1 and transforms2,with probability p for transforms1 and (1 - p) for transforms2"""def __init__(self, transforms1, transforms2, p=0.5):self.transforms1 = transforms1self.transforms2 = transforms2self.p = pdef __call__(self, img, target):if random.random() < self.p:return self.transforms1(img, target)return self.transforms2(img, target)class ToTensor(object):def __call__(self, img, target):return F.to_tensor(img), targetclass RandomErasing(object):def __init__(self, *args, **kwargs):self.eraser = T.RandomErasing(*args, **kwargs)def __call__(self, img, target):return self.eraser(img), targetclass Normalize(object):def __init__(self, mean, std):self.mean = meanself.std = stddef __call__(self, image, target=None):image = F.normalize(image, mean=self.mean, std=self.std)if target is None:return image, Nonetarget = target.copy()h, w = image.shape[-2:]if "boxes" in target:boxes = target["boxes"]boxes = box_xyxy_to_cxcywh(boxes)boxes = boxes / torch.tensor([w, h, w, h], dtype=torch.float32)target["boxes"] = boxesreturn image, targetclass Compose(object):def __init__(self, transforms):self.transforms = transformsdef __call__(self, image, target):for t in self.transforms:image, target = t(image, target)return image, targetdef __repr__(self):format_string = self.__class__.__name__ + "("for t in self.transforms:format_string += "\n"format_string += " {0}".format(t)format_string += "\n)"return format_string1)按概率随机选择做数据增强操作
class RandomSelect(object):"""Randomly selects between transforms1 and transforms2,with probability p for transforms1 and (1 - p) for transforms2"""def __init__(self, transforms1, transforms2, p=0.5):self.transforms1 = transforms1self.transforms2 = transforms2self.p = pdef __call__(self, img, target):if random.random() < self.p:return self.transforms1(img, target)return self.transforms2(img, target)T.RandomSelect( # 按概率随机选择做数据增强操作T.RandomResize(scales, max_size=1333),T.Compose([T.RandomResize([400, 500, 600]),T.RandomSizeCrop(384, 600),T.RandomResize(scales, max_size=1333),])
)代码解读 :
-
指定概率 p=0.5
-
若 p < 0.5,执行
T.RandomResize(scales, max_size=1333) -
若 p > 0.5 ,执行 如下3个 数据增强操作
-
T.Compose([T.RandomResize([400, 500, 600]),T.RandomSizeCrop(384, 600),T.RandomResize(scales, max_size=1333),])
-
2)Compose
class Compose(object):def __init__(self, transforms):self.transforms = transformsdef __call__(self, image, target):for t in self.transforms:image, target = t(image, target)return image, target3)随机水平翻转 RandomHorizontalFlip
boxes 的形式为 (xmin, ymin, xmax, ymax)
import torchvision.transforms.functional as Fclass RandomHorizontalFlip(object):def __init__(self, p=0.5):self.p = pdef __call__(self, img, target):if random.random() < self.p:return hflip(img, target)return img, targetdef hflip(image, target):flipped_image = F.hflip(image)w, h = image.sizetarget = target.copy()if "boxes" in target:boxes = target["boxes"]boxes = boxes[:, [2, 1, 0, 3]] * torch.as_tensor([-1, 1, -1, 1]) + torch.as_tensor([w, 0, w, 0])target["boxes"] = boxesreturn flipped_image, targetimg, target = RandomHorizontalFlip()(img, target)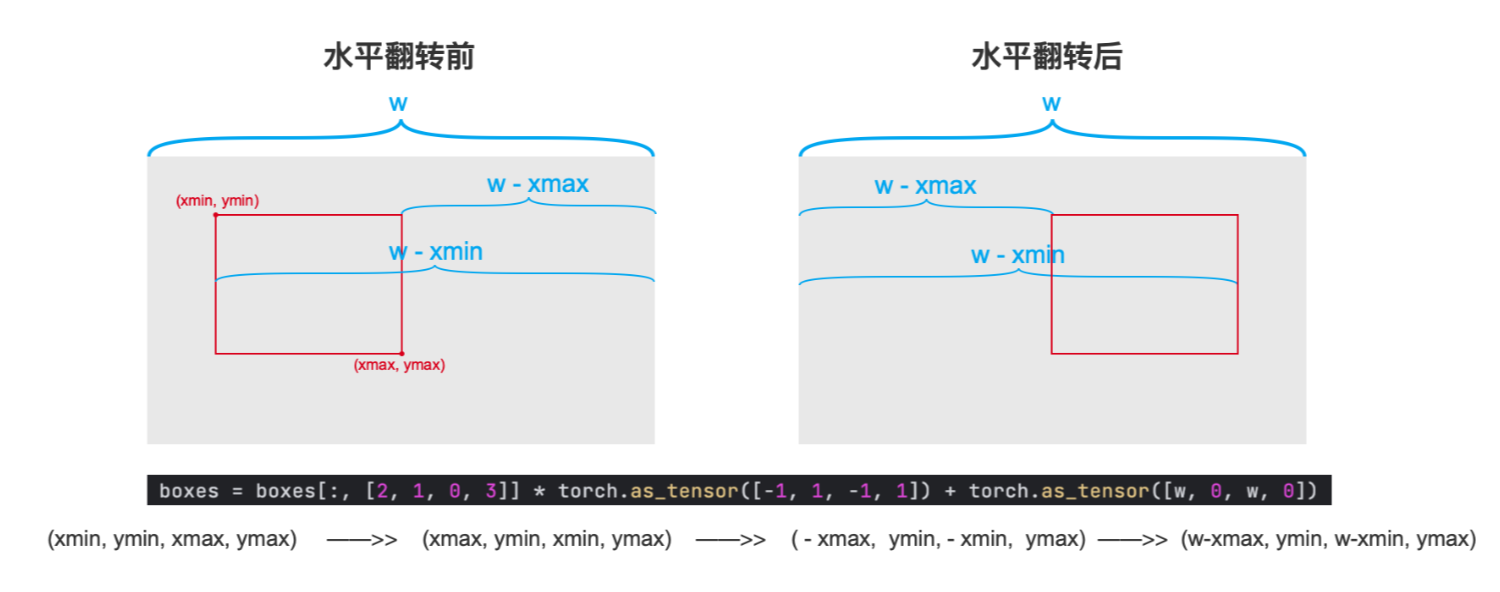
4)随机缩放 RandomResize
boxes 的形式为 (xmin, ymin, xmax, ymax)
class RandomResize(object):def __init__(self, sizes, max_size=None):assert isinstance(sizes, (list, tuple))self.sizes = sizesself.max_size = max_sizedef __call__(self, img, target=None):size = random.choice(self.sizes)return resize(img, target, size, self.max_size)def resize(image, target, size, max_size=None):# 获取缩放后的图像尺寸size = get_size(image.size, size, max_size)# 对图像进行缩放rescaled_image = F.resize(image, size)if target is None:return rescaled_image, None# 计算 高的缩放比例 和 宽的缩放比例ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(rescaled_image.size, image.size))ratio_width, ratio_height = ratiostarget = target.copy()if "boxes" in target:boxes = target["boxes"]# 将 bbox 的高宽分别按照 高的缩放比例 和 宽的缩放比例 进行调整scaled_boxes = boxes * torch.as_tensor([ratio_width, ratio_height, ratio_width, ratio_height])target["boxes"] = scaled_boxes# 重新计算 bbox 的面积if "area" in target:area = target["area"]scaled_area = area * (ratio_width * ratio_height)target["area"] = scaled_area# 保存缩放后的高和宽h, w = sizetarget["size"] = torch.tensor([h, w])if "masks" in target:target['masks'] = interpolate(target['masks'][:, None].float(), size, mode="nearest")[:, 0] > 0.5return rescaled_image, targetdef get_size(image_size, size, max_size=None):if isinstance(size, (list, tuple)):return size[::-1]else:return get_size_with_aspect_ratio(image_size, size, max_size)def get_size_with_aspect_ratio(image_size, size, max_size=None):w, h = image_sizeif max_size is not None:# 将size定为较短边长度,按照原始图像的长短比例(高宽比/宽高比),缩放图像较长边# 若缩放后图像的较长边大于最大尺寸 max_size, 则将较长边的长度定为 max_size,将# 较短边按照按照原始图像的比例进行调整min_original_size = float(min((w, h)))max_original_size = float(max((w, h)))if max_original_size / min_original_size * size > max_size:size = int(round(max_size * min_original_size / max_original_size))if (w <= h and w == size) or (h <= w and h == size):return (h, w)# 计算缩放后的图像高宽尺寸if w < h:ow = sizeoh = int(size * h / w)else:oh = sizeow = int(size * w / h)return (oh, ow)scales = [480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800]
img, target = RandomResize(scales, max_size=1333)(img, target)5)随机尺寸裁剪 RandomSizeCrop
boxes 的形式为 (xmin, ymin, xmax, ymax)
class RandomSizeCrop(object):def __init__(self, min_size: int, max_size: int):self.min_size = min_sizeself.max_size = max_sizedef __call__(self, img: PIL.Image.Image, target: dict):# 在指定范围内,分别随机出 高/宽尺寸,用于裁剪w = random.randint(self.min_size, min(img.width, self.max_size))h = random.randint(self.min_size, min(img.height, self.max_size))# 返回的region为裁剪的尺寸,形为:(top, left, height, width)region = T.RandomCrop.get_params(img, [h, w])return crop(img, target, region)def crop(image, target, region):# 将图像按照region 指定的尺寸进行裁剪cropped_image = F.crop(image, *region)target = target.copy()i, j, h, w = region# 保存裁剪后的尺寸target["size"] = torch.tensor([h, w])# 保存字段名,方便后面用于检查fields = ["labels", "area", "iscrowd"]if "boxes" in target:boxes = target["boxes"]# 将裁剪后的图像宽高转换为 tensormax_size = torch.as_tensor([w, h], dtype=torch.float32)# 调整bbox的坐标,将bbox的(xmin, ymin, xmax, ymax) 分别减去(left, top, left, top)cropped_boxes = boxes - torch.as_tensor([j, i, j, i])# 处理边界情况,若bbox的坐标落在裁剪区域外,则将bbox的坐标进行截断cropped_boxes = torch.min(cropped_boxes.reshape(-1, 2, 2), max_size) # 处理bbox的xmax和ymaxcropped_boxes = cropped_boxes.clamp(min=0) # 处理bbox的xmin和ymin# 求出裁剪后的图像面积,代码等价于 :area =(xmax - xmin)*(ymax - ymin)area = (cropped_boxes[:, 1, :] - cropped_boxes[:, 0, :]).prod(dim=1) target["boxes"] = cropped_boxes.reshape(-1, 4)target["area"] = areafields.append("boxes")if "masks" in target:# FIXME should we update the area here if there are no boxes?target['masks'] = target['masks'][:, i:i + h, j:j + w]fields.append("masks")if "boxes" in target or "masks" in target:# 删除落在裁剪区域外的bbox,这部分bbox经过上面的处理之后: xmin=xmax, ymin=ymaxif "boxes" in target:cropped_boxes = target['boxes'].reshape(-1, 2, 2)keep = torch.all(cropped_boxes[:, 1, :] > cropped_boxes[:, 0, :], dim=1)else:keep = target['masks'].flatten(1).any(1)# 删除无效的bboxfor field in fields:target[field] = target[field][keep]return cropped_image, targettorchvision.RandomCrop.get_params 用法:
region = torchvision.RandomCrop.get_params(img, output_size)参数:
-
img: 要裁剪的图像,可以是 PIL Image 或 Tensor 对象。 -
output_size: 裁剪区域的大小,必须是元组,包含两个元素,表示裁剪区域的高度和宽度 [h, w] 。
返回值:
-
一个元组,包含四个元素:
-
top: 裁剪区域的顶部坐标。 -
left: 裁剪区域的左侧坐标。 -
height: 裁剪区域的高度。 -
width: 裁剪区域的宽度。
-
6)ToTensor
class ToTensor(object):def __call__(self, img, target):return F.to_tensor(img), targetimg, target = ToTensor()(img, target)7)Normalize
class Normalize(object):def __init__(self, mean, std):self.mean = meanself.std = stddef __call__(self, image, target=None):image = F.normalize(image, mean=self.mean, std=self.std)if target is None:return image, Nonetarget = target.copy()h, w = image.shape[-2:]if "boxes" in target:boxes = target["boxes"]boxes = box_xyxy_to_cxcywh(boxes)boxes = boxes / torch.tensor([w, h, w, h], dtype=torch.float32)target["boxes"] = boxesreturn image, targetdef box_xyxy_to_cxcywh(x):x0, y0, x1, y1 = x.unbind(-1)b = [(x0 + x1) / 2, (y0 + y1) / 2,(x1 - x0), (y1 - y0)]return torch.stack(b, dim=-1)img, target = Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])(img, target)代码解读 :
-
将图像的像素值进行归一化
-
将 bbox 坐标由 (xmin, ymin, xmax, ymax) 转换为 (cx, cy, w, h)的形式
-
将 (cx, cy, w, h)的取值分别除以 w, h, w, h,将坐标值都归一化到 0 ~1 之间,
即,相对于 图像尺寸的 相对坐标