优化算法 - intro
优化问题
- 一般形式
- minimize f ( x ) f(\mathbf{x}) f(x) subject to x ∈ C \mathbf{x} \in C x∈C
- 目标函数 f : R n → R f: \mathbb{R}^n \rightarrow \mathbb{R} f:Rn→R
- 限制集合例子
- C = { x ∣ h 1 ( x ) = 0 , . . . , h m ( x ) = 0 , g 1 ( x ) ≤ 0 , . . . , g r ( x ) ≤ 0 } C = \{\mathbf{x} | h_1(\mathbf{x}) = 0, ..., h_m(\mathbf{x}) = 0, g_1(\mathbf{x}) \leq 0, ..., g_r(\mathbf{x}) \leq 0\} C={x∣h1(x)=0,...,hm(x)=0,g1(x)≤0,...,gr(x)≤0}
- 如果 C = R n C = \mathbb{R}^n C=Rn 那就是不受限
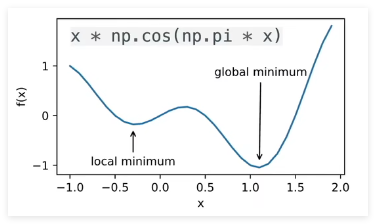
局部最小 vs 全局最小
- 全局最小 x ∗ \mathbf{x}^* x∗: f ( x ∗ ) ≤ f ( x ) f(\mathbf{x}^*) \leq f(\mathbf{x}) f(x∗)≤f(x) ∀ x ∈ C \mathbf{x} \in C x∈C
- 局部最小 x ∗ \mathbf{x}^* x∗: 存在 ε \varepsilon ε, 使得 f ( x ∗ ) ≤ f ( x ) f(\mathbf{x}^*) \leq f(\mathbf{x}) f(x∗)≤f(x) ∀ x : ∥ x − x ∗ ∥ ≤ ε \mathbf{x}: \|\mathbf{x} - \mathbf{x}^*\| \leq \varepsilon x:∥x−x∗∥≤ε
- 使用迭代优化算法来求解,一般只能保证找到局部最小值
凸集
-
一个 R n \mathbb{R}^n Rn 的子集 C C C 是凸当且仅当
α x + ( 1 − α ) y ∈ C \alpha \mathbf{x} + (1 - \alpha) \mathbf{y} \in C αx+(1−α)y∈C
∀ α ∈ [ 0 , 1 ] ∀ x , y ∈ C \forall \alpha \in [0,1] \; \forall \mathbf{x}, \mathbf{y} \in C ∀α∈[0,1]∀x,y∈C
凸函数
-
函数 f : C → R f: C \rightarrow \mathbb{R} f:C→R 是凸当且仅当
f ( α x + ( 1 − α ) y ) f(\alpha \mathbf{x} + (1 - \alpha) \mathbf{y}) f(αx+(1−α)y)
≤ α f ( x ) + ( 1 − α ) f ( y ) \leq \alpha f(\mathbf{x}) + (1 - \alpha) f(\mathbf{y}) ≤αf(x)+(1−α)f(y)
∀ α ∈ [ 0 , 1 ] ∀ x , y ∈ C \forall \alpha \in [0,1] \; \forall \mathbf{x}, \mathbf{y} \in C ∀α∈[0,1]∀x,y∈C
-
如果 x ≠ y , α ∈ ( 0 , 1 ) \mathbf{x} \neq \mathbf{y}, \alpha \in (0,1) x=y,α∈(0,1) 时不等式严格成立,那么叫严格凸函数
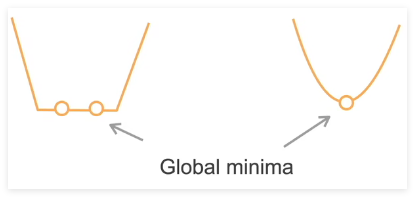
凸函数优化
- 如果代价函数 f f f 是凸的,且限制集合 C C C 是凸的,那么就是凸优化问题,那么局部最小一定是全局最小
- 严格凸优化问题有唯一的全局最小
凸和非凸例子
- 凸
- 线性回归 f ( x ) = ∥ W x − b ∥ 2 2 f(\mathbf{x}) = \|\mathbf{Wx} - \mathbf{b}\|_2^2 f(x)=∥Wx−b∥22
- Softmax 回归
- 非凸:其他
- MLP, CNN, RNN, attention, …
梯度下降
- 最简单的迭代求解算法
- 选取开始点 x 0 \mathbf{x}_0 x0
- 对 t = 1 , … , T t = 1, \ldots, T t=1,…,T
- x t = x t − 1 − η ∇ f ( x t − 1 ) \mathbf{x}_t = \mathbf{x}_{t-1} - \eta \nabla f(\mathbf{x}_{t-1}) xt=xt−1−η∇f(xt−1)
- η \eta η 叫做学习率
随机梯度下降
-
有 n n n 个样本时,计算
f ( x ) = 1 n ∑ i = 0 n ℓ i ( x ) f(\mathbf{x}) = \frac{1}{n} \sum_{i=0}^{n} \ell_i(\mathbf{x}) f(x)=n1∑i=0nℓi(x) 的导数太贵
-
随机梯度下降在时间 t t t 随机选项样本 t i t_i ti 来近似 f ( x ) f(x) f(x)(求导是线性可加的 )
x t = x t − 1 − η t ∇ ℓ t i ( x t − 1 ) \mathbf{x}_t = \mathbf{x}_{t-1} - \eta_t \nabla \ell_{t_i}(\mathbf{x}_{t-1}) xt=xt−1−ηt∇ℓti(xt−1)
E [ ∇ ℓ t i ( x ) ] = E [ ∇ f ( x ) ] \mathbb{E}\left[\nabla \ell_{t_i}(\mathbf{x})\right] = \mathbb{E}[\nabla f(\mathbf{x})] E[∇ℓti(x)]=E[∇f(x)]
小批量随机梯度下降
-
计算单样本的梯度难完全利用硬件资源
-
小批量随机梯度下降在时间 t t t 采样一个随机子集 I t ⊂ { 1 , . . . , n } I_t \subset \{1, ..., n\} It⊂{1,...,n} 使得 ∣ I t ∣ = b |I_t| = b ∣It∣=b
x t = x t − 1 − η t b ∑ i ∈ I t ∇ ℓ i ( x t − 1 ) \mathbf{x}_t = \mathbf{x}_{t-1} - \frac{\eta_t}{b} \sum_{i \in I_t} \nabla \ell_i(\mathbf{x}_{t-1}) xt=xt−1−bηt∑i∈It∇ℓi(xt−1)
-
同样,这是一个无偏的近似,但降低了方差
E [ 1 b ∑ i ∈ I t ∇ ℓ i ( x ) ] = ∇ f ( x ) \mathbb{E}\left[\frac{1}{b} \sum_{i \in I_t} \nabla \ell_i(\mathbf{x})\right] = \nabla f(\mathbf{x}) E[b1∑i∈It∇ℓi(x)]=∇f(x)
冲量法
-
冲量法使用平滑过的梯度对权重更新
g t = 1 b ∑ i ∈ I t ∇ ℓ i ( x t − 1 ) \mathbf{g}_t = \frac{1}{b} \sum_{i \in I_t} \nabla \ell_i(\mathbf{x}_{t-1}) gt=b1∑i∈It∇ℓi(xt−1)
v t = β v t − 1 + g t w t = w t − 1 − η v t \mathbf{v}_t = \beta \mathbf{v}_{t-1} + \mathbf{g}_t \quad \mathbf{w}_t = \mathbf{w}_{t-1} - \eta \mathbf{v}_t vt=βvt−1+gtwt=wt−1−ηvt
梯度平滑: v t = g t + β g t − 1 + β 2 g t − 2 + β 3 g t − 3 + . . . \mathbf{v}_t = \mathbf{g}_t + \beta \mathbf{g}_{t-1} + \beta^2 \mathbf{g}_{t-2} + \beta^3 \mathbf{g}_{t-3} + ... vt=gt+βgt−1+β2gt−2+β3gt−3+...
-
β \beta β 常见取值 [0.5, 0.9, 0.95, 0.99]
Adam
-
记录 v t = β 1 v t − 1 + ( 1 − β 1 ) g t \mathbf{v}_t = \beta_1 \mathbf{v}_{t-1} + (1 - \beta_1) \mathbf{g}_t vt=β1vt−1+(1−β1)gt 通常 β 1 = 0.9 \beta_1 = 0.9 β1=0.9
-
展开 v t = ( 1 − β 1 ) ( g t + β 1 g t − 1 + β 1 2 g t − 2 + β 1 3 g t − 3 + . . . ) \mathbf{v}_t = (1 - \beta_1)(\mathbf{g}_t + \beta_1 \mathbf{g}_{t-1} + \beta_1^2 \mathbf{g}_{t-2} + \beta_1^3 \mathbf{g}_{t-3} + ...) vt=(1−β1)(gt+β1gt−1+β12gt−2+β13gt−3+...)
-
因为 ∑ i = 0 ∞ β 1 i = 1 1 − β 1 \sum_{i=0}^{\infty} \beta_1^i = \frac{1}{1 - \beta_1} ∑i=0∞β1i=1−β11,所以权重和为1
-
由于 v 0 = 0 \mathbf{v}_0 = 0 v0=0,且 ∑ i = 0 t β 1 i = 1 − β 1 t 1 − β 1 \sum_{i=0}^{t} \beta_1^i = \frac{1 - \beta_1^t}{1 - \beta_1} ∑i=0tβ1i=1−β11−β1t,
修正 v ^ t = v t 1 − β 1 t \hat{\mathbf{v}}_t = \frac{\mathbf{v}_t}{1 - \beta_1^t} v^t=1−β1tvt -
类似记录 s t = β 2 s t − 1 + ( 1 − β 2 ) g t 2 \mathbf{s}_t = \beta_2 \mathbf{s}_{t-1} + (1 - \beta_2) \mathbf{g}_t^2 st=β2st−1+(1−β2)gt2,通常 β 2 = 0.999 \beta_2 = 0.999 β2=0.999,且修正
s ^ t = s t 1 − β 2 t \hat{\mathbf{s}}_t = \frac{\mathbf{s}_t}{1 - \beta_2^t} s^t=1−β2tst
-
计算重新调整后的梯度 g t ′ = v ^ t s ^ t + ϵ \mathbf{g}'_t = \frac{\hat{\mathbf{v}}_t}{\sqrt{\hat{\mathbf{s}}_t} + \epsilon} gt′=s^t+ϵv^t
-
最后更新 w t = w t − 1 − η g t ′ \mathbf{w}_t = \mathbf{w}_{t-1} - \eta \mathbf{g}'_t wt=wt−1−ηgt′
总结
- 深度学习模型大多是非凸
- 小批量随机梯度下降是最常用的优化算法
- 冲量对梯度做平滑
- Adam对梯度做平滑,且对梯度各个维度值做重新调整