人工智能数学基础(九)—— 信息论
信息论是一门研究信息的度量、存储、传输和处理的学科,它在人工智能领域尤其是机器学习、自然语言处理和计算机视觉等方面有着广泛的应用。今天,我将带大家深入浅出地探索信息论的核心概念,并结合 Python 实例,让大家能够直观地理解和应用这些知识。
9.1 概述
9.1.1 信息论的形成和发展
信息论由克劳德·香农在 1948 年创立,最初用于解决通信中的信息传输问题。随着时间的推移,信息论的应用范围不断扩大,逐渐渗透到人工智能、数据科学、生物信息学等多个领域。
9.1.2 信息论对人工智能的影响
在人工智能中,信息论提供了度量数据信息量、评估模型复杂度、优化算法性能的工具。例如,在机器学习中,信息增益是决策树分裂节点的重要依据;在自然语言处理中,语言模型的训练离不开对文本信息量的度量。
9.1.3 信息的基本概念
信息是用来消除不确定性的东西,信息的基本单位是比特(bit)。信息量的大小与事件发生的概率密切相关:越不可能发生的事件,一旦发生,提供的信息量越大。
9.1.4 通信系统模型
一个基本的通信系统包括信源、编码器、信道、解码器和信宿。信源产生信息,编码器将信息转换为适合传输的形式,信道是信息传输的媒介,解码器将接收到的信号还原为信息,信宿是信息的最终接收者。
9.2 信息的度量
9.2.1 自信息量
自信息量衡量一个事件发生时所提供的信息量,其公式为: I(xi)=−log2P(xi) 其中,P(xi) 是事件 xi 发生的概率。
9.2.2 条件自信息量
条件自信息量衡量在已知另一个事件发生的情况下,某一事件发生所提供的信息量,其公式为: I(xi∣yj)=−log2P(xi∣yj)
9.2.3 联合自信息量
联合自信息量衡量两个事件同时发生所提供的信息量,其公式为: I(xi,yj)=−log2P(xi,yj)
9.2.4 互信息量与条件互信息量
互信息量衡量两个事件之间的相关性,其公式为: I(xi;yj)=I(xi)+I(yj)−I(xi,yj) 条件互信息量则是在已知第三个事件的情况下,两个事件之间的互信息量。
9.2.5 互信息量的性质
互信息量具有非负性、对称性等性质。它反映了两个随机变量之间的依赖程度:互信息量越大,变量之间的相关性越强。
9.3 信源与信息熵
9.3.1 平均自信息量(熵)
熵是衡量信源输出不确定性的一个指标,其公式为: H(X)=−∑i=1nP(xi)log2P(xi) 熵越大,信源的不确定性越高。
9.3.2 平均条件自信息量(条件熵)
条件熵衡量在已知另一个随机变量的情况下,某一随机变量的不确定性,其公式为: H(X∣Y)=−∑i=1n∑j=1mP(xi,yj)log2P(xi∣yj)
9.3.3 联合熵
联合熵衡量两个随机变量共同的不确定性,其公式为: H(X,Y)=−∑i=1n∑j=1mP(xi,yj)log2P(xi,yj)
9.3.4 相对熵
相对熵衡量两个概率分布之间的差异,其公式为: D(P∣∣Q)=∑i=1nP(xi)log2Q(xi)P(xi) 相对熵是非对称的,常用于机器学习中的损失函数。
9.3.5 熵函数的性质
熵函数具有非负性、对称性、极值性等性质。熵函数在均匀分布时取得最大值,在确定性分布时取得最小值。
9.3.6 平均互信息量
平均互信息量衡量两个随机变量之间的相关性,其公式为: I(X;Y)=H(X)−H(X∣Y)=H(Y)−H(Y∣X) 平均互信息量越大,变量之间的相关性越强。
9.3.7 平均互信息量的性质
平均互信息量具有非负性、对称性等性质。它反映了两个随机变量之间的依赖程度。
9.3.8 平均互信息量与熵和条件熵的关系
平均互信息量与熵和条件熵之间有如下关系: I(X;Y)=H(X)−H(X∣Y)=H(Y)−H(Y∣X)
9.3.9 关于平均互信息量的两条定理
-
数据处理定理 :如果 X→Y→Z 构成一个马尔可夫链,那么 I(X;Y)≥I(X;Z)。
-
充分统计量定理 :如果 T(X) 是 X 的充分统计量,那么 I(T(X);Y)=I(X;Y)。
9.3.10 熵在决策树中的应用
在决策树算法中,熵用于衡量数据集的纯度。信息增益是决策树分裂节点的重要依据,其公式为: Information Gain=H(D)−H(D∣A) 其中,H(D) 是数据集 D 的熵,H(D∣A) 是在属性 A 下的数据集 D 的条件熵。
9.4 信道与信道容量
9.4.1 信道的分类
信道可以分为有线信道和无线信道、离散信道和连续信道等。不同的信道具有不同的特性和容量。
9.4.2 离散无记忆信道容量
离散无记忆信道容量是信道在单位时间内能够传输的最大信息量,其公式为: C=maxP(x)I(X;Y) 其中,P(x) 是输入信号的概率分布。
9.4.3 连续信道容量
连续信道容量是连续信道在单位时间内能够传输的最大信息量,其公式为: C=maxf(x)I(X;Y) 其中,f(x) 是输入信号的概率密度函数。
9.5 信道编码
9.5.1 信道编码的基本概念
信道编码是在信源编码的基础上,为提高信号在信道中的传输可靠性而进行的编码。它通过增加冗余信息,使接收端能够检测和纠正传输过程中产生的错误。
9.5.2 信道译码规则
信道译码规则是指接收端根据接收到的信号,估计发送端发送的原始信号的规则。常见的译码规则有最大似然译码、最小距离译码等。
9.5.3 信道编码定理
信道编码定理指出,对于任意信道,只要编码速率小于信道容量,就存在一种编码方案,使得在足够长的编码块长下,译码错误概率可以任意小。
9.5.4 信道编码逆定理
信道编码逆定理指出,如果编码速率大于信道容量,那么无论采用何种编码方案,译码错误概率都不能任意小。
9.6 网络信息安全及密码
9.6.1 网络信息安全概述
网络信息安全旨在保护网络中的数据、信息和资源不受威胁和攻击。它包括信息的机密性、完整性、可用性和不可否认性等方面。
9.6.2 密码技术
密码技术是网络信息安全的核心,它通过加密和解密算法,保护数据的机密性和完整性。常见的密码技术有对称加密、非对称加密、哈希函数等。
9.6.3 密码技术在信息安全中的应用
密码技术在网络信息安全中有着广泛的应用,如 SSL/TLS 协议保护网络通信安全、数字签名保证信息的完整性和不可否认性、加密存储保护数据的机密性等。
9.7 实验一:绘制二进制熵函数曲线
9.7.1 实验目的
通过绘制二进制熵函数曲线,加深对熵概念的理解,掌握信息熵随概率变化的趋势。
9.7.2 实验要求
绘制二进制熵函数 H(p)=−plog2p−(1−p)log2(1−p) 的曲线,其中 p 是事件发生的概率,取值范围为 [0, 1]。
9.7.3 实验原理
二进制熵函数衡量了二元事件的不确定性。当 p=0 或 p=1 时,熵为 0,表示事件完全确定;当 p=0.5 时,熵达到最大值 1,表示事件最不确定。
9.7.4 实验步骤
-
导入必要的 Python 库,如 NumPy 和 Matplotlib。
-
定义二进制熵函数。
-
生成 p 的取值范围。
-
计算对应的熵值。
-
绘制二进制熵函数曲线。
9.7.5 实验结果
import numpy as np
import matplotlib.pyplot as plt# 定义二进制熵函数
def binary_entropy(p):return -p * np.log2(p) - (1 - p) * np.log2(1 - p)# 生成 p 的取值范围
p = np.linspace(0.01, 0.99, 100)# 计算对应的熵值
h = binary_entropy(p)# 绘制二进制熵函数曲线
plt.figure(figsize=(8, 6))
plt.plot(p, h, 'b-', linewidth=2)
plt.xlabel('Probability p', fontsize=12)
plt.ylabel('Entropy H(p)', fontsize=12)
plt.title('Binary Entropy Function', fontsize=14)
plt.grid(True)
plt.show()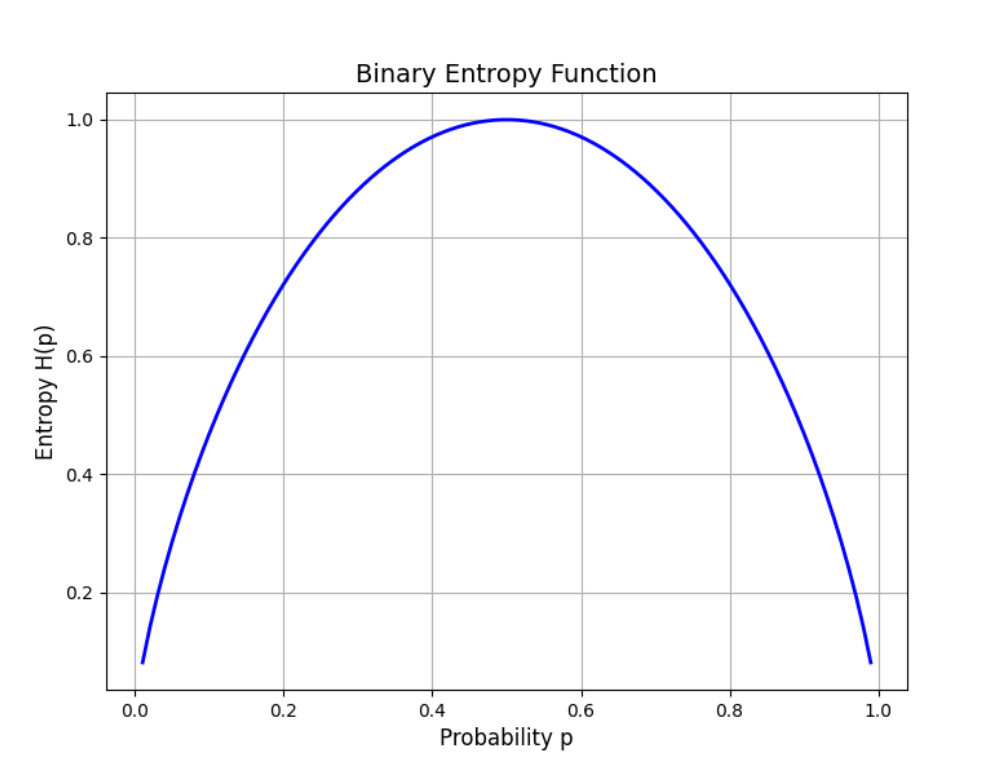
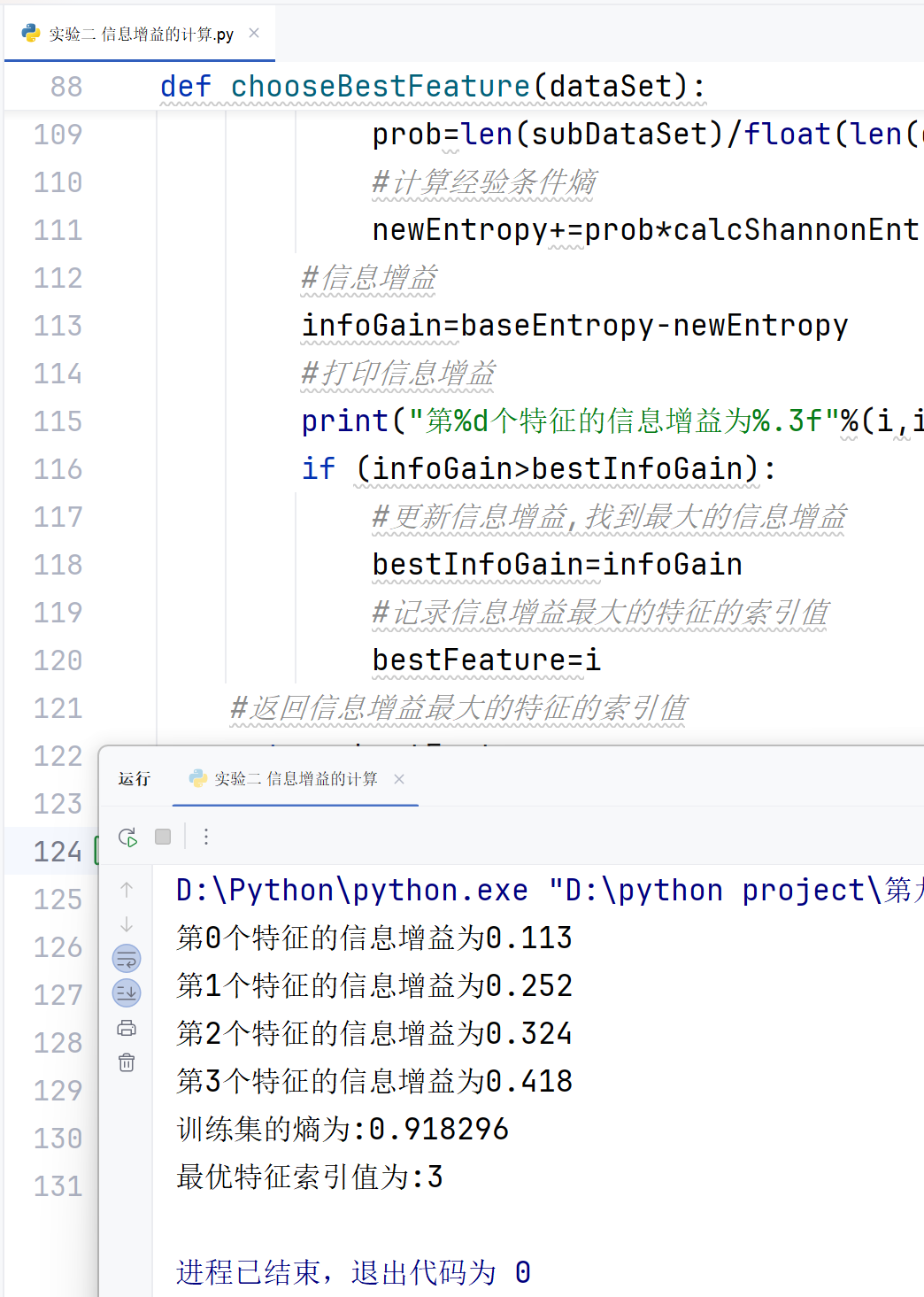
9.8 实验二:信息增益的计算
9.8.1 实验目的
通过计算信息增益,了解如何在决策树中选择最优的分裂属性。
9.8.2 实验要求
给定一个数据集,计算某个属性的信息增益。
9.8.3 实验原理
信息增益是决策树分裂节点的重要依据,其公式为: Information Gain=H(D)−H(D∣A) 其中,H(D) 是数据集 D 的熵,H(D∣A) 是在属性 A 下的数据集 D 的条件熵。
9.8.4 实验步骤
-
导入必要的 Python 库,如 Pandas 和 Math。
-
创建一个示例数据集。
-
计算数据集的熵。
-
计算在某个属性下的条件熵。
-
计算信息增益。
9.8.5 实验结果
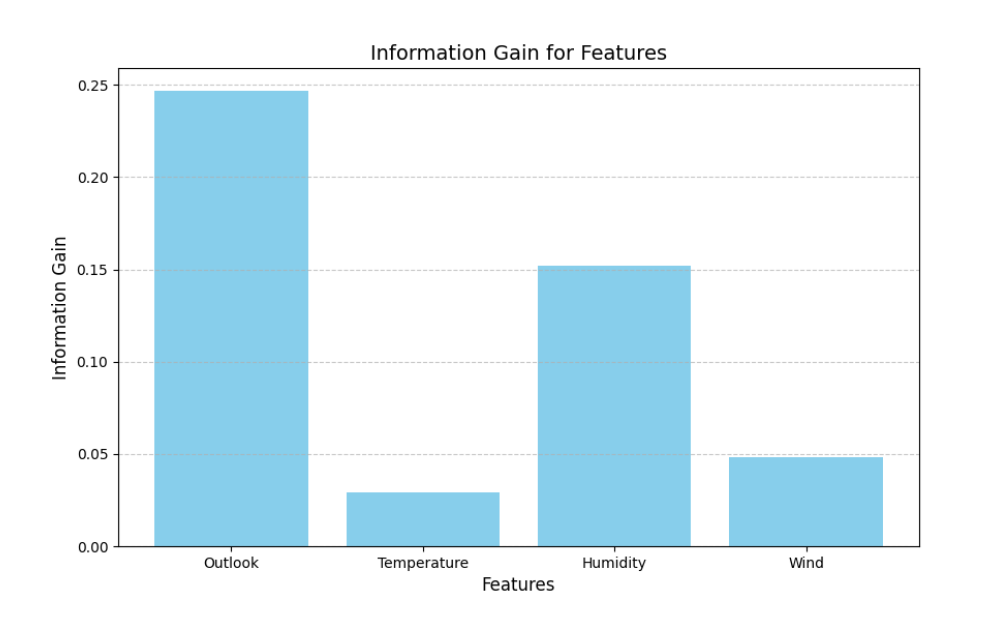
import matplotlib.pyplot as plt
import pandas as pd
import math# 创建示例数据集
data = {'Outlook': ['Sunny', 'Sunny', 'Overcast', 'Rain', 'Rain', 'Rain', 'Overcast', 'Sunny', 'Sunny', 'Rain', 'Sunny', 'Overcast', 'Overcast', 'Rain'],'Temperature': ['Hot', 'Hot', 'Hot', 'Mild', 'Cool', 'Cool', 'Cool', 'Mild', 'Cool', 'Mild', 'Mild', 'Mild', 'Hot', 'Mild'],'Humidity': ['High', 'High', 'High', 'High', 'Normal', 'Normal', 'Normal', 'High', 'Normal', 'Normal', 'Normal', 'High', 'Normal', 'High'],'Wind': ['Weak', 'Strong', 'Weak', 'Weak', 'Weak', 'Strong', 'Strong', 'Weak', 'Weak', 'Weak', 'Strong', 'Strong', 'Weak', 'Strong'],'Play': ['No', 'No', 'Yes', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes', 'Yes', 'Yes', 'Yes', 'Yes', 'No']}
df = pd.DataFrame(data)# 计算数据集的熵
def calculate_entropy(column):counts = column.value_counts()probabilities = counts / len(column)entropy = -sum(probabilities * [math.log2(p) for p in probabilities])return entropy# 计算信息增益
def calculate_information_gain(data, feature_column, target_column):total_entropy = calculate_entropy(data[target_column])feature_entropy = 0.0for value in data[feature_column].unique():subset = data[data[feature_column] == value]subset_entropy = calculate_entropy(subset[target_column])feature_entropy += (len(subset) / len(data)) * subset_entropyinformation_gain = total_entropy - feature_entropyreturn information_gain# 计算 "Outlook" 属性的信息增益
gain_outlook = calculate_information_gain(df, 'Outlook', 'Play')
print(f"Information Gain for Outlook: {gain_outlook:.4f}")# 绘制信息增益的柱状图
features = ['Outlook', 'Temperature', 'Humidity', 'Wind']
gains = [calculate_information_gain(df, feature, 'Play') for feature in features]plt.figure(figsize=(10, 6))
plt.bar(features, gains, color='skyblue')
plt.xlabel('Features', fontsize=12)
plt.ylabel('Information Gain', fontsize=12)
plt.title('Information Gain for Features', fontsize=14)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.show()
9.9 信息论知识总结
| 概念 | 定义与说明 | 相关公式 | ||
|---|---|---|---|---|
| 自信息量 | 衡量一个事件发生时所提供的信息量 | I(xi)=−log2P(xi) | ||
| 信息熵 | 衡量信源输出不确定性的指标 | H(X)=−∑i=1nP(xi)log2P(xi) | ||
| 互信息量 | 衡量两个随机变量之间的相关性 | ( I(X;Y) = H(X) - H(X | Y) ) | |
| 信道容量 | 信道在单位时间内能够传输的最大信息量 | C=maxP(x)I(X;Y) | ||
| 相对熵 | 衡量两个概率分布之间的差异 | ( D(P | Q) = \sum_{i=1}^n P(x_i)\log_2 \frac{P(x_i)}{Q(x_i)} ) |
以上就是本期关于信息论的全部内容啦!如果你在学习过程中有任何疑问或者想法,欢迎在评论区留言,大家一起交流探讨呀!资源绑定附上完整资源供读者参考学习!