NaVILA: Legged Robot Vision-Language-ActionModel for Navigation
摘要
本文旨在解决基于视觉与语言导航(VLN)在四足机器人上的实现问题。该任务不仅为人类提供了一种灵活的指令方式,还使机器人能够在更具挑战性和杂乱的场景中导航。然而,将人类自然语言指令转换为低层次的腿部关节控制指令并非易事。
为此,作者提出了一个两级架构 NaVILA(Navigation with Vision, Language and Action),将视觉-语言-动作模型(VLA)与行走技能相结合。与直接从VLA预测低层动作的方式不同,NaVILA 首先生成带有空间信息的中层动作,以自然语言形式表示(例如“向前移动75厘米”),然后作为输入,传递给一个视觉驱动的强化学习行走策略执行。
在现有基准测试上,NaVILA 显著优于此前的方法。此外,在作者开发的新基准环境(使用 IsaacLab)中,该方法也表现出一致的优势。新基准涵盖了更真实的场景、更低层的控制和真实机器人实验。
引言
具备视觉-语言导航(VLN)能力已成为现代机器人系统中的关键组件。借助 VLN,机器人无需预先地图,只需依照语言指令,即可在未见过的环境中导航【1–6】。这种方式不仅为人类提供了更自然的交互方式,也通过语言增强了跨场景的泛化能力。
本论文进一步将 VLN 研究扩展至腿式机器人(如四足或类人机器人)。相比轮式移动,使用腿部可以让机器人在更复杂、障碍密集的场景中导航。例如:机器人可以穿越杂乱的实验室狭窄通道、在室内多个房间之间移动,甚至在户外崎岖地形(如石块、洞坑)中前行。
要将语言转化为行动,机器人必须理解语言输入,并进行闭环规划与低层控制。近年来,大型语言模型(LLM)和视觉-语言模型(VLM)的进展使得一些端到端的视觉-语言-动作系统(VLA)成为可能【7–9】。这些系统通常通过大规模机器人操作演示数据微调 VLM,从而直接输出低层动作。尽管这种整合“推理+控制”的方式取得了初步成功,但问题仍在于:**是否有比量化的低层命令更合适的动作表示形式?**毕竟,LLM/VLM 主要还是基于语言训练的,将推理结果转化为精确的非语言动作仍是巨大挑战。
受近期 VLM 在空间位置和距离推理能力提升的启发【10, 11】,我们提出 NaVILA:一个两级框架,专为腿式机器人的 VLN 而设计。其方法是:使用 VLM 输出中层动作(例如“右转30度”),然后使用视觉强化学习训练的低层行走策略执行该指令。该中层动作以语言形式表征方向和距离信息,避免直接预测低层命令。
这一框架带来了三大优势:
-
模块解耦:将VLA与低层控制解耦,使得VLA可适配多种机器人,仅需替换低层策略;
-
泛化增强:用语言表达中层动作,可以借助丰富的真实世界数据(如YouTube视频)进行训练,提升推理能力且避免过拟合;
-
双频运行机制:VLA作为高负载模型低频运行输出导航指令;而低层策略实时运行处理复杂障碍物,增强整体鲁棒性。
我们还展示了如下训练策略:
-
在 VLM 框架下整合历史上下文与当前观测;
-
构建专为导航设计的提示模板(prompt);
-
利用 YouTube 上人类导览视频提升模型在连续环境中的导航能力;
-
提出混合数据集,用于提升模型泛化能力。
这是首次展示直接使用人类视频训练能显著提升 VLN 表现的研究。
在行走控制策略方面,我们采用单阶段的视觉驱动策略训练方式。通过 LiDAR 点云构建高度图,并引入随机扰动以实现模拟到真实的迁移(sim-to-real)。控制器将VLA输出的语言转化为速度指令,并最终转化为关节位置。此端到端流程可训练出稳健、真实可部署的策略,即便在强阳光或透明地面环境下也能正常运行。
实验结果表明:
-
在经典VLN基准上,我们的VLA成功率提高超17%,优于现有方法;
-
单阶段行走策略也显著优于以往基于策略蒸馏的方法;
-
我们提出新基准 VLN-CE-Isaac,基于Isaac Sim,更真实地模拟机器人关节与环境交互;
-
在该新基准中,我们的视觉策略比无视觉策略高出14%成功率;
-
我们还在多种机器人(Unitree Go2、H1、Booster T1)上部署,验证策略通用性;
-
最后在真实世界中部署 NaVILA,在25条指令中达成88%的整体成功率,其中75%为复杂跨场景指令。
方法
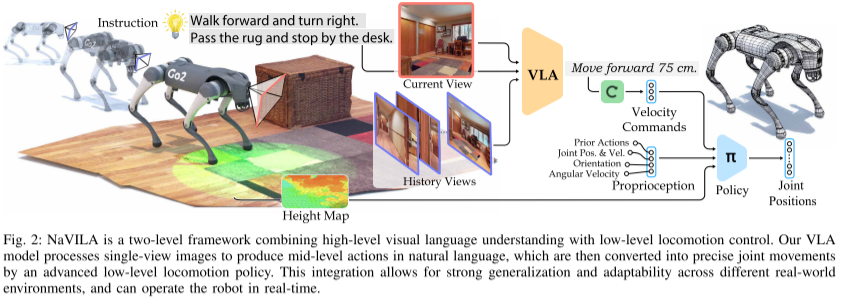
NaVILA 将高层次的视觉-语言理解与低层次的行走控制结合在一起(见图2)。它使用一个视觉-语言模型(VLM)来处理单视角图像,并以自然语言的形式生成路径点指令(waypoint instructions),这些指令随后由行走策略(locomotion policy)翻译为精确的关节运动,从而实现机器人的实时控制。
VLM 的推理能力与行走策略的执行能力之间的协同作用,使得 NaVILA 能够在多样化的环境中实现良好的泛化。
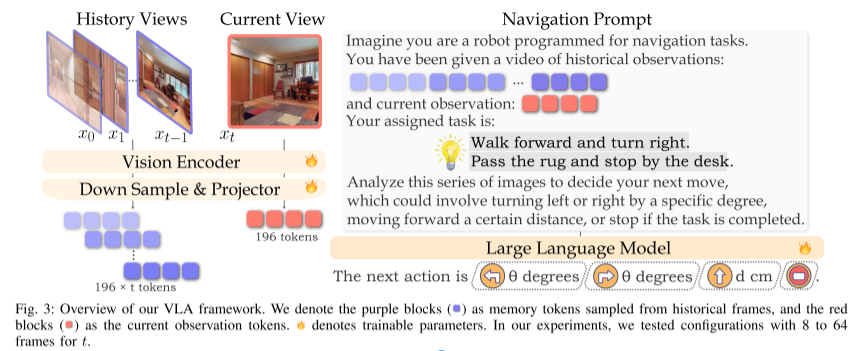
用于视觉语言导航的Taming VLM
视觉-语言导航(VLN)任务需要处理视频输入作为感知信息。处理这类输入的常见方法是采用视频编码器【12】。但目前视觉-语言模型(VLM)的发展,主要得益于图文对数据的广泛可用。尽管也有尝试将这些成功迁移至视频编码器,但由于缺乏大规模、高质量的视频-文本数据集,限制了其预训练能力。
为了解决这个问题,我们选择使用基于图像的视觉-语言模型。相比视频模型,这些模型具备更强的泛化能力和更广的世界知识,更适合应对 VLN 中复杂多样的环境。具体而言,我们采用了 VILA 系列模型【13–19】,它是一类高效的视觉-语言模型,支持理解与生成,尤其擅长多图像之间的推理能力,非常适合 VLN 任务。
VILA简介
导航Prompts

从人类视频中学习
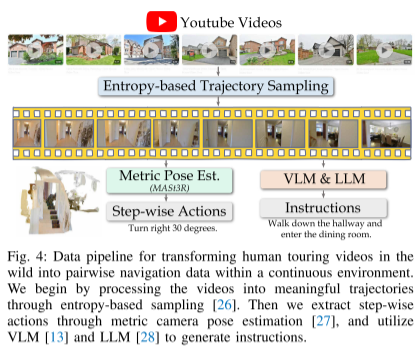
近期研究【24–26】表明,从人类视频中收集“轨迹-指令”对能够增强机器人的导航能力。然而,以往的方法仅限于离散导航场景,主要使用真实视频作为预训练数据来缩小领域差异或提升地标识别能力,而不是直接用于训练导航模型。
将该方法推广到连续导航场景面临重大挑战,主要是因为获取连续的动作标签非常困难。不过,近年来野外环境中的相机位姿估计(metric-pose estimation)技术取得突破,使得我们可以从人类视频中提取空间理解信息,从而直接训练导航模型。
我们设计的数据处理流程(如图4所示)如下:
-
首先收集了来自 YouTube 的 2000 条第一视角导览视频,这些视频提供了丰富的真实世界数据,有助于机器人从人类行为中学习导航。
-
我们通过基于熵的采样方法【26】将这些视频处理为 2 万条具有代表性且多样化的轨迹。
-
然后使用 MASt3R 算法【27】估计相机位姿,从而提取出逐步的动作信息;
-
接着,使用 基于视觉语言模型(VLM)的描述生成器【13】,为每条轨迹生成自然语言指令,并通过 大语言模型(LLM)【28】进一步改写,使语言表达更自然。
这一流程使我们能够有效利用人类演示数据来进行连续导航训练,这是此前很难实现的能力。
监督微调数据混合策略
要训练出一个强健的视觉-语言-动作模型,有效的监督微调(SFT)数据至关重要。该模型既要专注于具身智能任务,又要避免过拟合具体动作;同时应具备良好的现实泛化能力,并保留对世界的广泛认知。
依托 NaVILA 模块化框架的高可扩展性与灵活性,我们可以轻松将各种数据源整合进训练流程,从而显著提升模型的导航泛化能力。我们构建的 SFT 数据混合集基于以下四类来源:
-
来自真实视频的导航数据
-
来自仿真的导航数据
-
辅助导航数据(Auxiliary)
-
通用视觉问答(VQA)数据集
仿真导航数据:
-
连续环境下的 VLN 数据集有限,只有 R2R-CE [29] 和 RxR-CE [30] 可用,它们是从离散版本转换而来的稀疏路径点数据。
-
我们在 Habitat 模拟器 中使用这两个数据集,并利用**最短路径跟随器(Shortest Path Follower)**生成沿测地路径的动作序列。
-
得到的数据形式是:(t+1) 帧视频 + t 时刻的动作标签。
-
为了训练 LLM 生成连续数值标签(如距离、角度),我们将多个连续动作合并(如两个 25cm 前进合成一个 50cm 前进),最多合并三步。
-
这样可以:
-
减小数据体积,提高处理效率;
-
丰富动作多样性,减缓过拟合。
-
-
-
为缓解 标签不均衡问题(如 stop 动作不足),我们采用了重采样技术进行再平衡。
-
所有导航类数据都按照前述帧提取策略处理,并配以任务提示语。
辅助导航数据:
-
R2R-CE 和 RxR-CE 的指令有限,为提升语义理解,我们引入额外导航数据:
-
使用 EnvDrop [31] 的增强指令(augmented instructions);
-
引入轨迹总结任务:给定一个轨迹视频,保留首帧和若干历史帧,并用指令作为标签,要求 LLM 生成对轨迹的语言总结。
-
-
引入 ScanQA [32] 数据集以增强空间理解能力,该数据集基于真实 3D 扫描对象,提供人工编辑的问答对。
-
我们从原始扫描中提取多视角 RGB 图像支持该任务训练。
-
通用视觉问答数据:
-
为保持模型的广泛能力,我们还加入了多个通用 VQA 数据集【23, 33, 34】。
这一整合策略确保了 NaVILA 模型在面对新场景和真实世界环境时仍具备强泛化能力。

训练和推理范式
我们的训练过程从 VILA 的第二阶段模型开始,该模型已经完成了图文混合语料的预训练。在此基础上,我们使用前述的 SFT 数据混合集对整个视觉语言模型(VLM)进行训练,仅训练一个 epoch,遵循标准训练流程。
在这一训练阶段,我们解冻模型的三个核心模块:
-
视觉编码器(Vision Encoder)
-
连接器(Connector)
-
大语言模型(LLM)
在 推理阶段,我们设计并实现了一个 正则表达式解析器【35】,用于从 LLM 的输出中提取:
-
动作类型(如 forward,turn left)
-
对应参数(如具体距离或角度)
我们在模拟和真实环境中验证了该方法的有效性,实验证明:在所有任务中,所有动作均被成功解析与匹配,且能正确转换为控制命令。
视觉运动策略
简要介绍实验所用平台 Go2 机器人犬,随后描述我们开发的端到端视觉控制策略,该策略能够将 VLM 输出的高层语言导航命令转化为精确的关节动作指令。该控制策略在 Isaac Sim 仿真环境中通过 Isaac Lab [36] 训练,并可直接部署至现实机器人平台。
Go2机器人简介
如图5所示,Go2 机器人配备一个安装在头部基座上的 LiDAR 激光雷达,以 15Hz 的频率广播点云。机器人总共具备 18 个自由度(DoF):
-
其中 6 DoF 属于底座(base),
-
每条腿具有 3 DoF,共 4 条腿。
在策略训练过程中,底座的 6 个自由度不受控制,策略仅控制 12 个腿部关节电机。

语言指令——》控制信号转换

底层动作与观测空间

训练策略:单阶段强化学习
与常见的两阶段“教师-学生”训练范式【38–41】不同,我们采用了单阶段训练方式:
-
更高效:无需进行策略蒸馏;
-
更灵活:策略直接与环境交互,有机会学习新策略;
-
借助 Isaac Lab 中的光线投射(Ray-casting)能力,在 RTX 4090 GPU 上可达 每秒6万帧(60K FPS) 的仿真速度,极大提升训练效率。