倒排索引(Inverted Index)详解
倒排索引(Inverted Index)详解
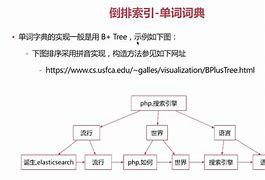
1. 倒排索引的定义
倒排索引是一种用于快速查找的索引方法,广泛应用于信息检索系统和搜索引擎中。与正排索引(将文档ID映射到其内容)不同,倒排索引将每个词项(Term)映射到包含该词项的所有文档列表(称为倒排记录表或Posting List)。
2. 倒排索引的原理
倒排索引的核心思想是构建一个“词-文档”关系表,具体步骤如下:
- 文本预处理:对原始文档进行分词、去除停用词等操作。
- 构建词典:收集所有文档中的词项,形成词典(Dictionary)。
- 生成倒排记录表:为每个词项建立一个倒排记录表,记录该词项在哪些文档中出现及其位置信息。
3. 倒排索引的处理过程
3.1 文本预处理
假设我们有以下三个文档:
- Doc1: “The quick brown fox”
- Doc2: “The lazy dog”
- Doc3: “The quick brown dog”
经过分词和去除停用词(如 “The”),得到:
- Doc1: [“quick”, “brown”, “fox”]
- Doc2: [“lazy”, “dog”]
- Doc3: [“quick”, “brown”, “dog”]
3.2 构建词典
收集所有词项,形成词典:
- 词典:[“quick”, “brown”, “fox”, “lazy”, “dog”]
3.3 生成倒排记录表
为每个词项建立倒排记录表:
- “quick”: [Doc1, Doc3]
- “brown”: [Doc1, Doc3]
- “fox”: [Doc1]
- “lazy”: [Doc2]
- “dog”: [Doc2, Doc3]
更详细的倒排记录表(包含词项在文档中的位置):
- “quick”: [(Doc1, 1), (Doc3, 1)]
- “brown”: [(Doc1, 2), (Doc3, 2)]
- “fox”: [(Doc1, 3)]
- “lazy”: [(Doc2, 1)]
- “dog”: [(Doc2, 2), (Doc3, 3)]
4. 倒排索引的代码案例
以下是一个简单的 Python 实现示例:
class InvertedIndex:def __init__(self):self.index = {}def add(self, doc_id, terms):for term in terms:if term not in self.index:self.index[term] = []self.index[term].append(doc_id)def search(self, term):return self.index.get(term, [])# 示例文档
documents = {1: "The quick brown fox",2: "The lazy dog",3: "The quick brown dog"
}# 创建倒排索引
index = InvertedIndex()# 添加文档到索引
for doc_id, text in documents.items():terms = text.lower().split() # 简单分词index.add(doc_id, terms)# 搜索词项
print(index.search("quick")) # 输出: [1, 3]
print(index.search("dog")) # 输出: [2, 3]
5. 与其他索引方法的对比
5.1 正排索引(Forward Index)
正排索引将每个文档ID映射到其内容,结构简单但查询效率低。
- 优点:结构简单,易于理解和实现。
- 缺点:查询时需要遍历大量数据,效率低下。
5.2 倒排索引(Inverted Index)
倒排索引将每个词项映射到包含该词项的文档列表,查询效率高。
- 优点:查询速度快,适合大规模数据检索。
- 缺点:构建和维护成本较高,存储空间需求大。
5.3 全文索引(Full-text Index)
全文索引结合了正排索引和倒排索引的特点,支持全文检索。
- 优点:功能强大,支持复杂查询。
- 缺点:实现复杂,资源消耗大。
6. 表格总结
| 索引方法 | 定义 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 正排索引 | 将每个文档ID映射到其内容 | 结构简单,易于实现 | 查询效率低,需遍历大量数据 | 小规模数据,简单查询 |
| 倒排索引 | 将每个词项映射到包含该词项的文档列表 | 查询速度快,适合大规模数据检索 | 构建和维护成本高,存储空间需求大 | 大规模数据检索,如搜索引擎 |
| 全文索引 | 结合正排索引和倒排索引,支持全文检索 | 功能强大,支持复杂查询 | 实现复杂,资源消耗大 | 需要全文检索的场景,如数据库全文搜索 |
总结
倒排索引是一种高效的信息检索技术,通过将词项映射到包含该词项的文档列表,实现了快速查询。相比正排索引和全文索引,倒排索引在大规模数据检索场景下具有显著优势,但构建和维护成本相对较高。理解倒排索引的原理和实现方式,有助于在实际应用中选择合适的技术方案,提升系统的性能和用户体验。