深入剖析结构体内存对齐
在掌握了结构体的基本用法之后,我们需要深入探讨一个常见且重要的问题:如何计算结构体的大小。这不仅是C语言中的一个核心概念,也是一个常见的考点——结构体内存对齐。
目录
一、对齐规则
1、首成员对齐
2、其他成员对齐
3、结构体总大小
4、嵌套结构体的对齐
二、练习与验证
练习1
内存布局图:
练习2
内存布局图:
练习3
内存布局图:
练习4 - 结构体嵌套
内存布局图:
三、为什么存在内存对齐?
1、平台原因(移植性)
2、性能原因
四、修改默认对齐数
应用场景:
五、offsetof 宏
1、概念
2、语法
3、参数说明
4、返回值
5、示例代码分析
示例1:结构体 S1
示例2:结构体 S2
6、注意事项
7、应用场景
一、对齐规则
要准确计算结构体的大小,必须掌握以下对齐规则:
1、首成员对齐
- 结构体的第一个成员始终对齐到结构体变量起始位置偏移量为0的地址处。
2、其他成员对齐
- 其余每个成员需要对齐到 “对齐数” 的整数倍地址处。
- 对齐数 = 该成员自身的大小 与 编译器默认对齐数 中的较小值。
-
在 Linux 平台使用 gcc 编译时,没有默认对齐数,对齐数即为成员自身的大小。
-
在 Visual Studio 中,默认对齐数为
8。
-
3、结构体总大小
- 整个结构体的总大小必须是所有成员中 最大对齐数 的整数倍。
4、嵌套结构体的对齐
如果结构体中嵌套了另一个结构体,则该嵌套结构体成员要对齐到其内部成员的最大对齐数的整数倍地址处。整个结构体的总大小必须是所有最大对齐数(包括嵌套结构体成员的对齐数)中的最大值的整数倍。
二、练习与验证
以下通过几个例子来验证和理解上述规则(假设在VS环境下,默认对齐数为8):
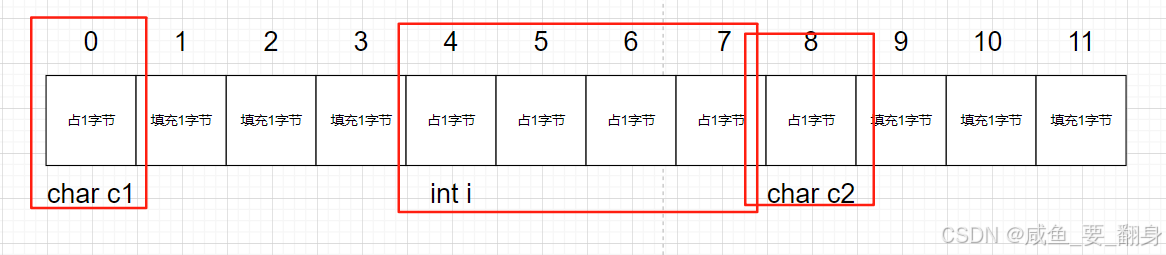
练习1
struct S1 {char c1; // 大小1,对齐数min(1,8)=1int i; // 大小4,对齐数min(4,8)=4 -> 需对齐到4的倍数char c2; // 大小1,对齐数min(1,8)=1
};
// 内存布局示意 (假设起始地址为0):
// 0 [c1]
// 1 [填充3字节]
// 4 [i]
// 8 [c2]
// 9 [填充3字节] -> 总大小需为最大对齐数(4)的整数倍 -> 12
printf("%d\n", sizeof(struct S1)); // 输出:12内存布局图:
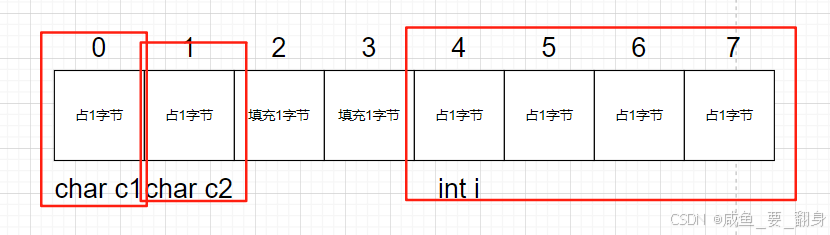
练习2
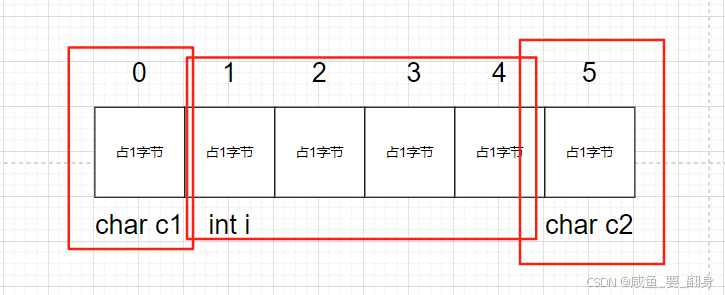
struct S2 {char c1; // 对齐数1char c2; // 对齐数1int i; // 对齐数4 -> 需对齐到4的倍数
};
// 内存布局示意 (地址0):
// 0 [c1]
// 1 [c2]
// 2 [填充2字节]
// 4 [i]
// 8 -> 已是最大对齐数(4)的整数倍 -> 8
printf("%d\n", sizeof(struct S2)); // 输出:8内存布局图:
练习3
struct S3 {double d; // 大小8,对齐数min(8,8)=8char c; // 大小1,对齐数1int i; // 大小4,对齐数min(4,8)=4 -> 需对齐到4的倍数
};
// 内存布局示意 (地址0):
// 0 [d]
// 8 [c]
// 9 [填充3字节]
// 12 [i]
// 16 -> 已是最大对齐数(8)的整数倍 -> 16
printf("%d\n", sizeof(struct S3)); // 输出:16内存布局图:

练习4 - 结构体嵌套
struct S4 {char c1; // 对齐数1struct S3 s3; // S3中最大对齐数为8,故该成员需对齐到8的倍数double d; // 对齐数8
};
// 内存布局示意 (地址0):
// 0 [c1]
// 1 [填充7字节] (使s3对齐到地址8)
// 8 [s3] (s3大小为16字节,布局见上)
// 24 [d]
// 32 -> 所有最大对齐数(8)的整数倍 -> 32
printf("%d\n", sizeof(struct S4)); // 输出:32内存布局图:

三、为什么存在内存对齐?
内存对齐主要是出于以下两个关键原因的考虑:
1、平台原因(移植性)
并非所有的硬件平台都能任意访问所有地址上的数据。某些架构的CPU(例如早期的RISC架构或某些嵌入式处理器)只能从特定倍数地址(如4的倍数、8的倍数)读取特定类型的数据(如4字节的int)。尝试在非对齐地址上进行访问可能会导致硬件异常,导致程序崩溃。
2、性能原因
数据结构(尤其是栈上的)应尽可能地在自然边界上对齐。现代处理器通常以固定大小的块(如64位处理器常以8字节为块)来访问内存。如果数据未对齐,一个本可以一次访问完成的int或double变量可能跨越两个内存块。这迫使处理器执行两次内存访问、进行额外的移位和拼接操作,从而显著降低性能。而对齐的内存访问通常只需一次操作。
总结而言,结构体的内存对齐是一种典型的以空间换取时间(Space-Time Tradeoff)的策略。
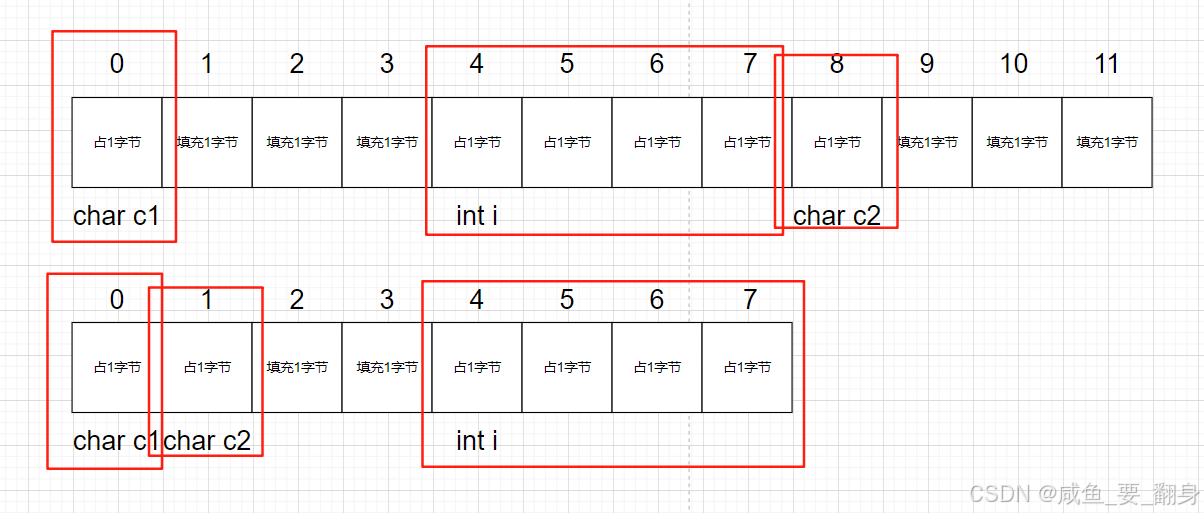
既然对齐会牺牲一些空间,那么在设计结构体时,如何在满足对齐要求的前提下尽可能地节省空间呢?
答案是:将占用空间小的成员尽量集中声明在一起。这可以最大限度地减少成员之间因对齐需求而插入的“填充字节”(Padding)。
// 低效布局:空间浪费较多
struct S1 {char c1; // 1字节// 编译器插入3字节填充以满足后续int的对齐int i; // 4字节char c2; // 1字节// 末尾再填充3字节使结构体总大小为最大对齐数(4)的倍数
}; // sizeof(struct S1) = 12// 优化布局:节省空间
struct S2 {char c1; // 1字节char c2; // 1字节// 仅需插入2字节填充即可满足后续int的对齐int i; // 4字节
}; // sizeof(struct S2) = 8S1和S2的成员完全相同,但通过调整顺序,S2比S1节省了1/3的空间。
四、修改默认对齐数
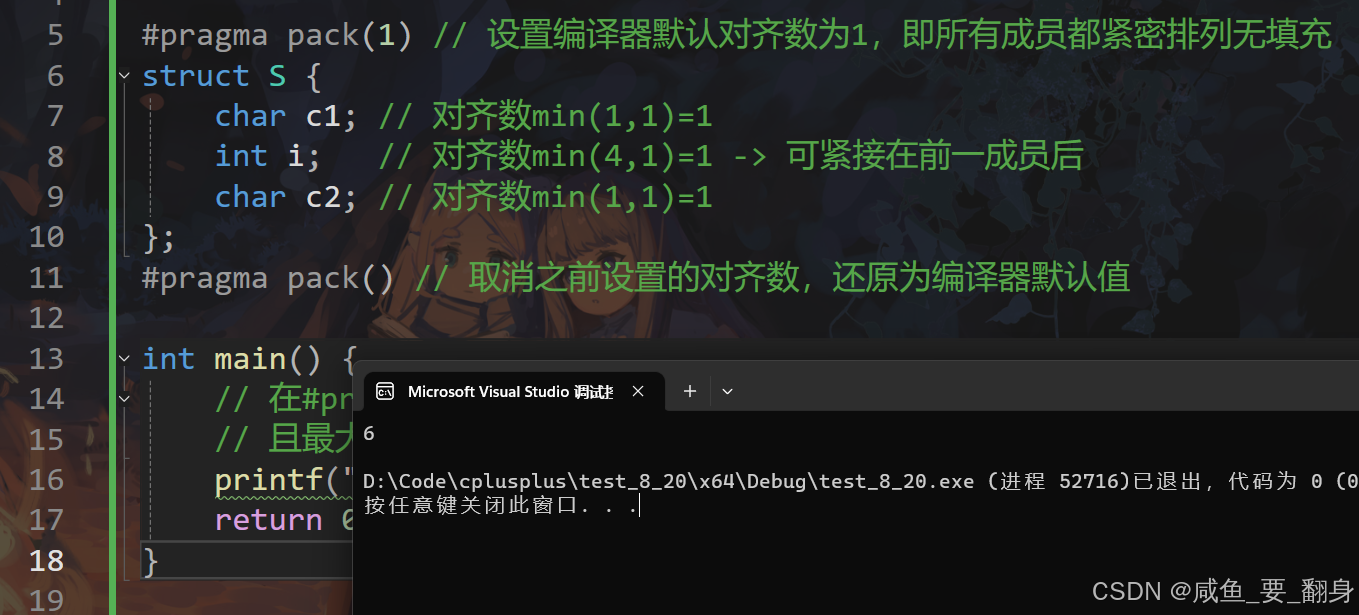
使用预处理指令 #pragma pack(n) 可以改变编译器的默认对齐数,其中 n 通常为 1, 2, 4, 8, 16。
#include <stdio.h>#pragma pack(1) // 设置编译器默认对齐数为1,即所有成员都紧密排列无填充
struct S {char c1; // 对齐数min(1,1)=1int i; // 对齐数min(4,1)=1 -> 可紧接在前一成员后char c2; // 对齐数min(1,1)=1
};
#pragma pack() // 取消之前设置的对齐数,还原为编译器默认值int main() {// 在#pragma pack(1)下,所有成员间无填充,总大小即为1+4+1=6// 且最大对齐数为1,6是1的整数倍。printf("%d\n", sizeof(struct S)); // 输出:6return 0;
}
应用场景:
当结构体需要与其他硬件、网络协议或文件格式进行精确的二进制交互(例如网络封包、读取BMP文件头)时,通常需要禁用或修改对齐以保证布局的精确性,防止因编译器插入不可控的填充字节而导致数据错位。在这种情况下,可以使用 #pragma pack(1) 来确保结构体是“紧凑”(Packed)的。
五、offsetof 宏
1、概念
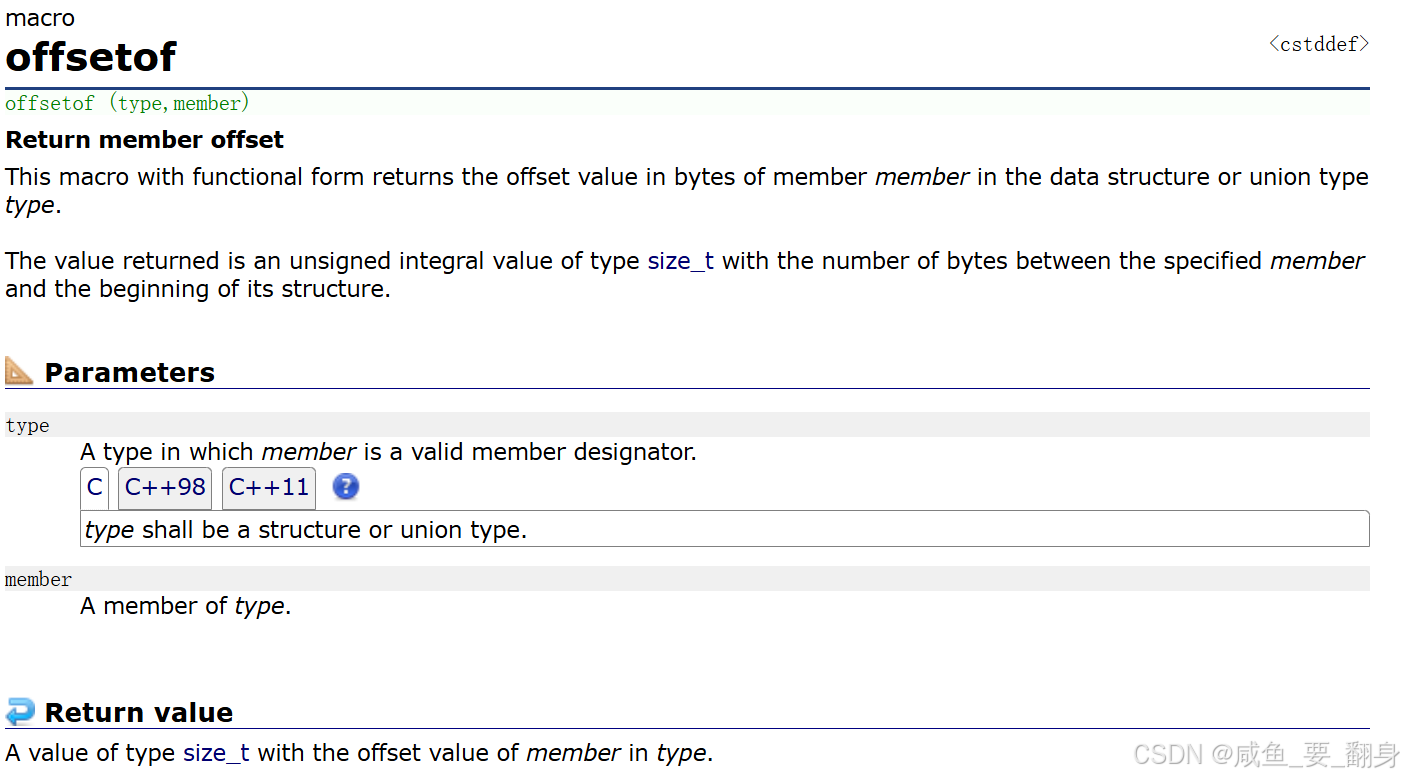
offsetof 是一个标准库宏,用于计算结构体(或联合体)中某个成员相对于结构体起始位置的偏移量(以字节为单位)。
2、语法
使用 offsetof 宏需要包含以下头文件之一:
#include <stddef.h> // 需要包含此头文件offsetof(type, member)3、参数说明
-
type:结构体或联合体类型 -
member:结构体或联合体中的成员名称
4、返回值
返回一个 size_t 类型的无符号整数值,表示指定成员从结构体起始位置开始的字节偏移量。
5、示例代码分析
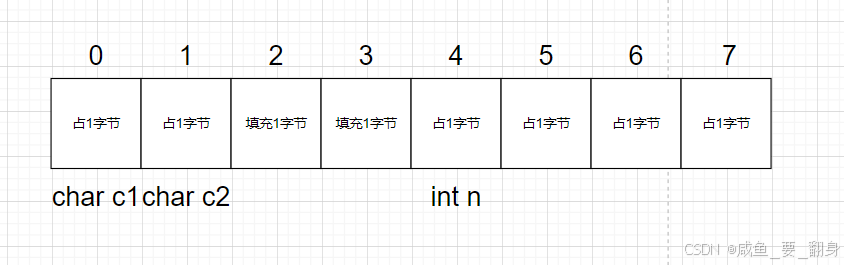
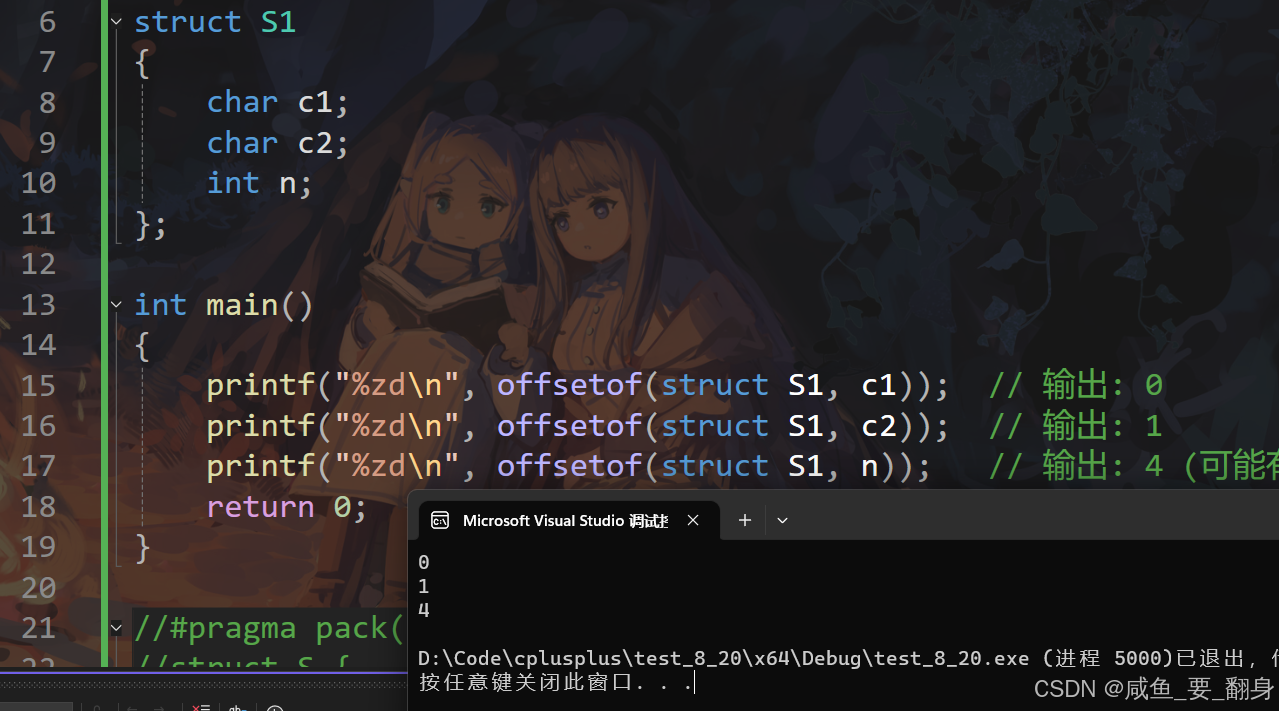
示例1:结构体 S1
#include <stdio.h>
#include <stddef.h> // 需要包含此头文件struct S1
{char c1;char c2;int n;
};int main()
{printf("%zd\n", offsetof(struct S1, c1)); // 输出: 0printf("%zd\n", offsetof(struct S1, c2)); // 输出: 1printf("%zd\n", offsetof(struct S1, n)); // 输出: 4 (可能有对齐填充)return 0;
}
示例2:结构体 S2
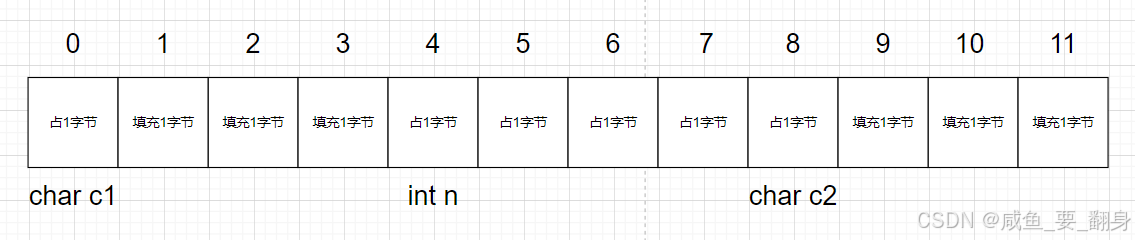
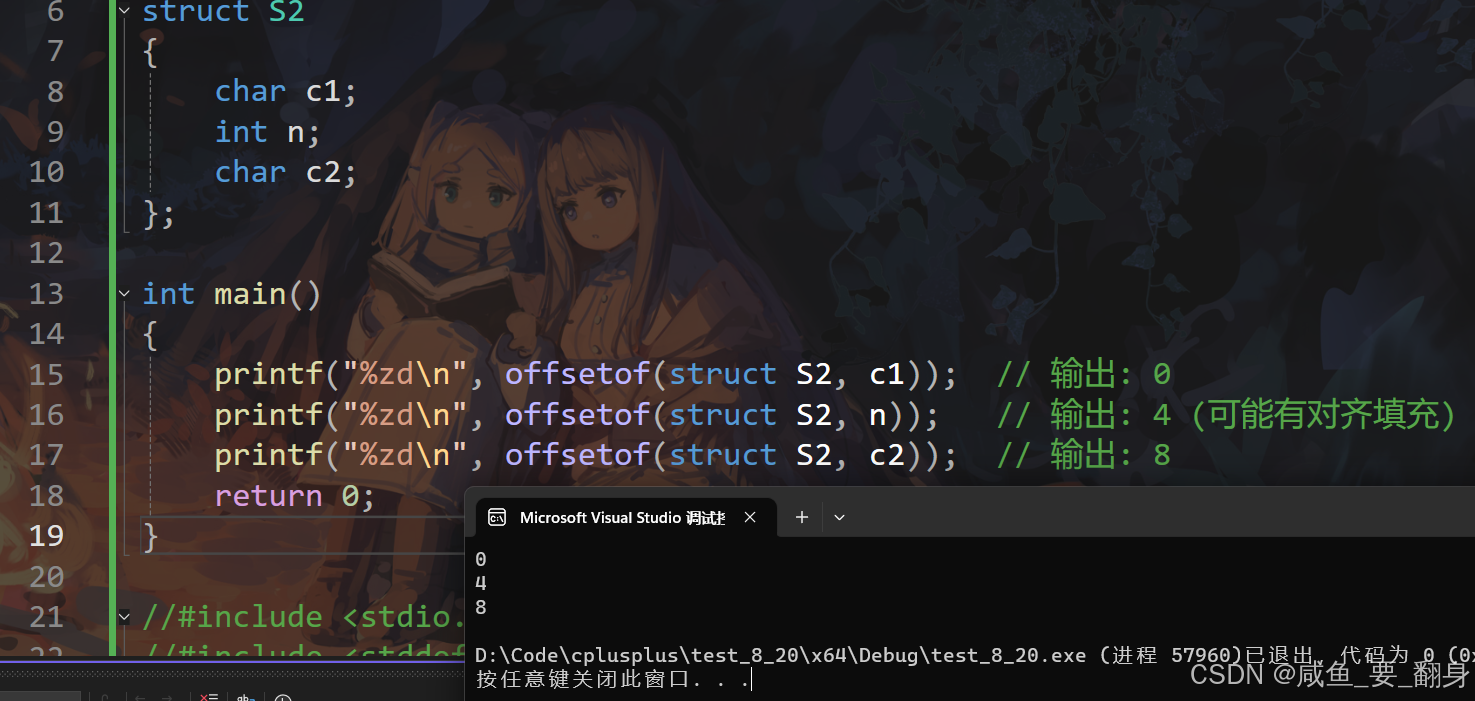
#include <stdio.h>
#include <stddef.h> // 需要包含此头文件struct S2
{char c1;int n;char c2;
};int main()
{printf("%zd\n", offsetof(struct S2, c1)); // 输出: 0printf("%zd\n", offsetof(struct S2, n)); // 输出: 4 (可能有对齐填充)printf("%zd\n", offsetof(struct S2, c2)); // 输出: 8return 0;
}
6、注意事项
-
offsetof是一个编译时计算的宏,不是运行时的函数 -
由于结构体内存对齐的原因,成员的偏移量可能与成员大小之和不同
-
在C++中,
offsetof只能用于POD(普通旧数据类型)类型 -
使用前需要包含
<stddef.h>(C语言)或<cstddef>(C++)
7、应用场景
-
序列化和反序列化数据
-
访问特定硬件寄存器
-
实现自定义内存管理
-
调试和诊断工具开发
这个宏在底层编程和系统开发中非常有用,特别是在需要直接操作内存布局的情况下。