4月22日复盘-开始卷积神经网络
4月24日复盘
一、CNN
视觉处理三大任务:图像分类、目标检测、图像分割
上游:提取特征,CNN
下游:分类、目标、分割等,具体的业务
1. 概述
卷积神经网络是深度学习在计算机视觉领域的突破性成果。在计算机视觉领域, 往往我们输入的图像都很大,使用全连接网络的话,计算的代价较高。另外图像也很难保留原有的特征,导致图像处理的准确率不高。
卷积神经网络(Convolutional Neural Network,CNN)是一种专门用于处理具有网格状结构数据的深度学习模型。最初,CNN主要应用于计算机视觉任务,但它的成功启发了在其他领域应用,如自然语言处理等。
卷积神经网络(Convolutional Neural Network)是含有卷积层的神经网络. 卷积层的作用就是用来自动学习、提取图像的特征。
CNN网络主要有三部分构成:卷积层、池化层和全连接层构成,其中卷积层负责提取图像中的局部特征;池化层用来大幅降低运算量并特征增强;全连接层类似神经网络的部分,用来输出想要的结果。
1.1 使用场景




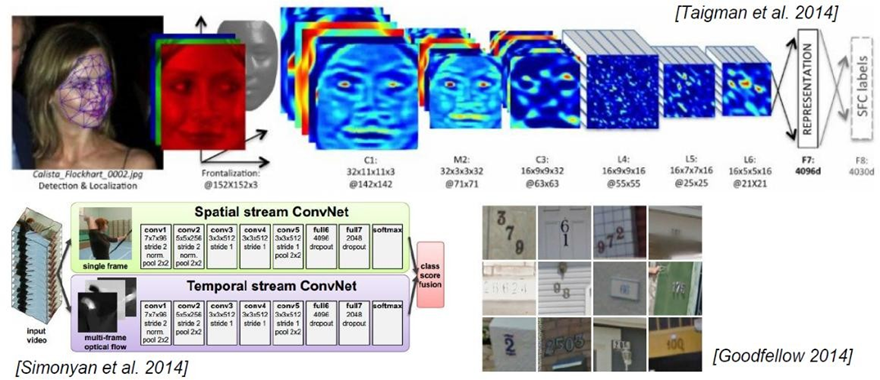
1.2 与传统网络的区别
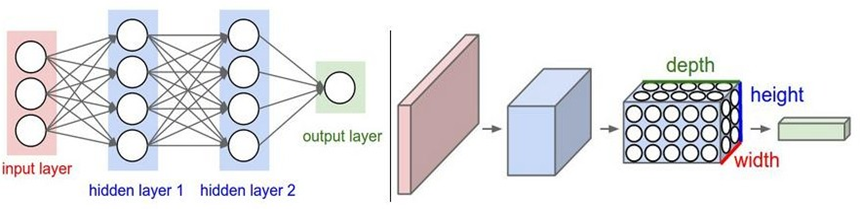
1.3 全连接的局限性
全连接神经网络并不太适合处理图像数据…
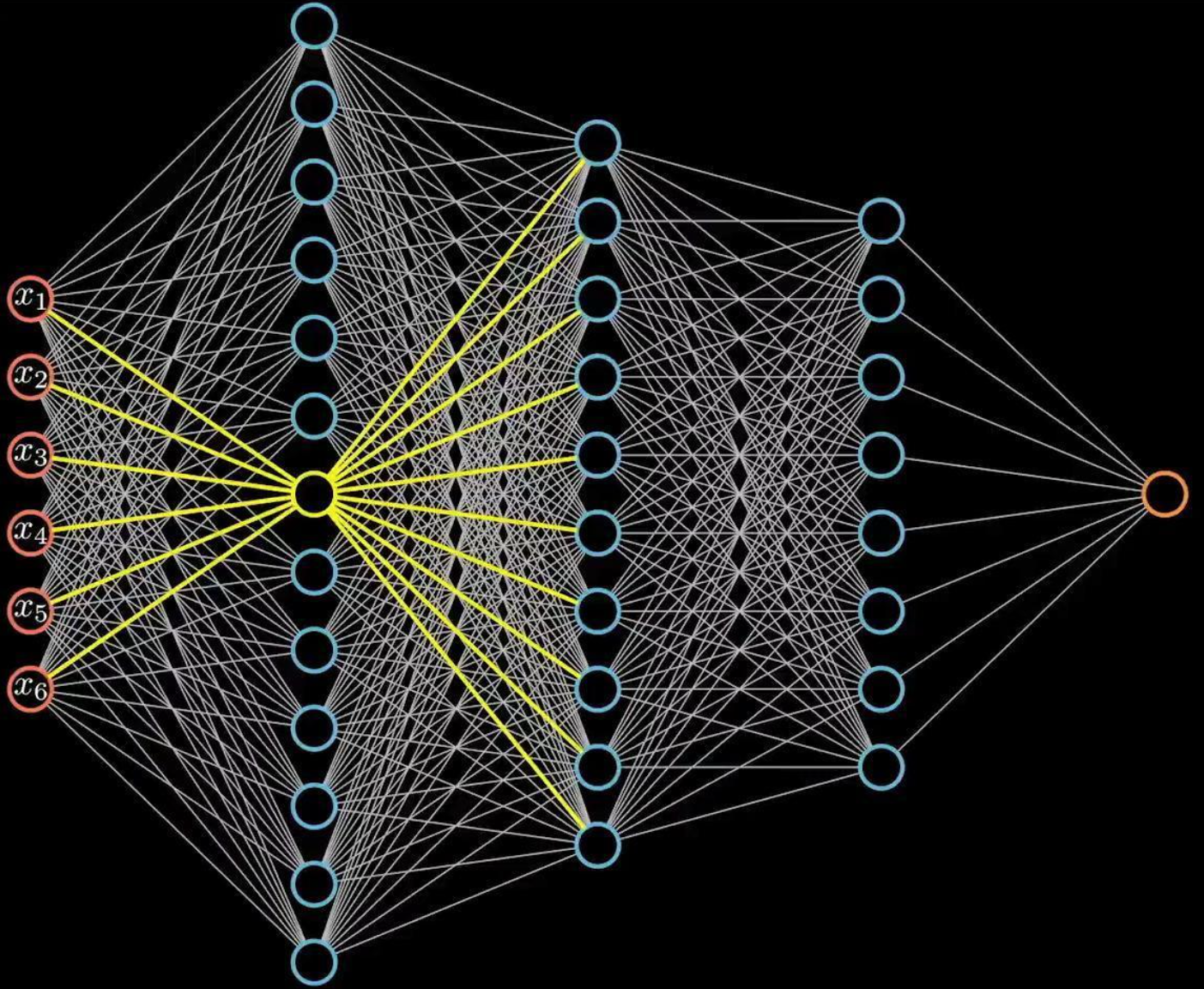
1.3.1 参数量巨大
y = x × W T + b y = x \times W^T + b y=x×WT+b
全连接结构计算量非常大,假设我们有1000×1000的输入,如果隐藏层也是1000×1000大小的神经元,由于神经元和图像每一个像素连接,则参数量会达到惊人的1000×1000×1000×1000,仅仅一层网络就已经有 1 0 12 10^{12} 1012个参数。
1.3.2 表达能力太有限
全连接神经网络的角色只是一个分类器,如果将整个图片直接输入网络,不仅参数量大,也没有利用好图片中像素的空间特性,增加了学习难度,降低了学习效果。
1.4 卷积思想
卷:从左往右,从上往下
积:乘积,求和
1.4.1 概念
Convolution,输入信息与卷积核(滤波器,Filter)的乘积。
1.4.2 局部连接
- 局部连接可以更好地利用图像中的结构信息,空间距离越相近的像素其相互影响越大。
- 根据局部特征完成目标的可辨识性。
1.4.3 权重共享
-
图像从一个局部区域学习到的信息应用到其他区域。
-
减少参数,降低学习难度。
2. 卷积层
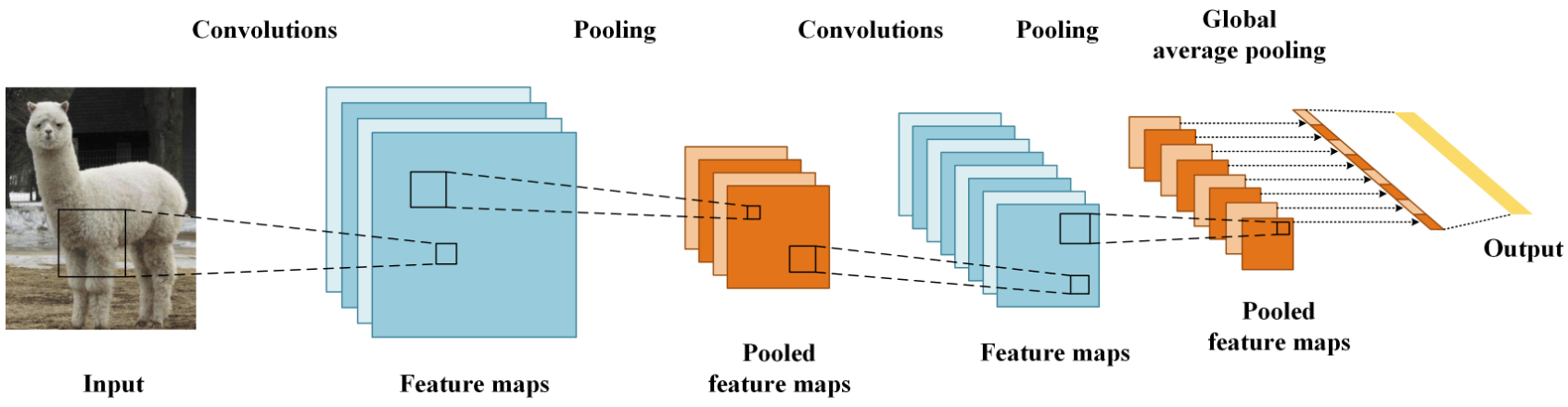
接下来,我们开始学习卷积核的计算过程, 即: 卷积核是如何提取特征的。
2.1 卷积核
卷积核是卷积运算过程中必不可少的一个“工具”,在卷积神经网络中,卷积核是非常重要的,它们被用来提取图像中的特征。
卷积核其实是一个小矩阵,在定义时需要考虑以下几方面的内容:
- 卷积核的个数:卷积核(过滤器)的个数决定了其输出特征矩阵的通道数。
- 卷积核的值:卷积核的值是初始化好的,后续进行更新。
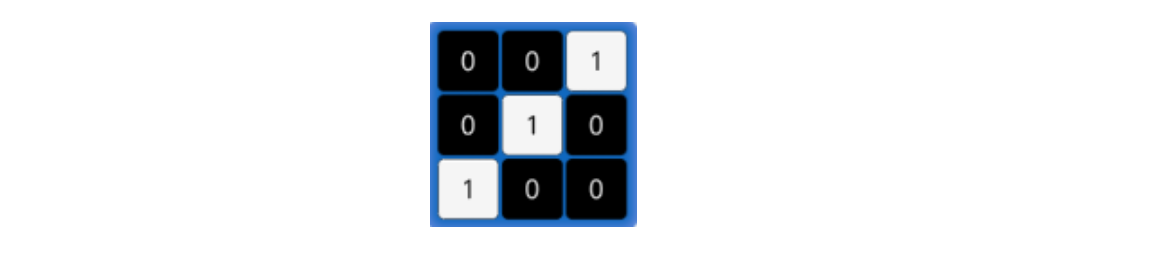
- 卷积核的大小:常见的卷积核有1×1、3×3、5×5等,一般都是奇数 × 奇数。
下图就是一个3×3的卷积核:
2.2 卷积计算
2.2.1 卷积计算过程
卷积的过程是将卷积核在图像上进行滑动计算,每次滑动到一个新的位置时,卷积核和图像进行点对点的计算,并将其求和得到一个新的值,然后将这个新的值加入到特征图中,最终得到一个新的特征图。
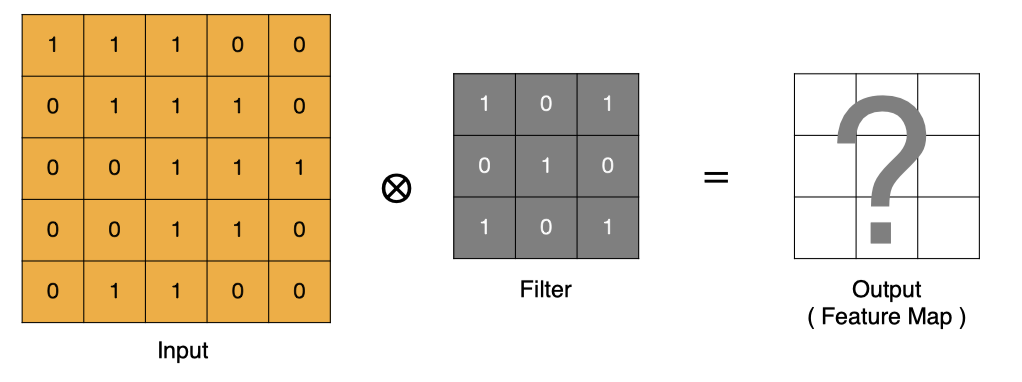
- input 表示输入的图像
- filter 表示卷积核, 也叫做滤波器
- input 经过 filter 的得到输出为最右侧的图像,该图叫做特征图
那么, 它是如何进行计算的呢?卷积运算本质上就是在滤波器和输入数据的局部区域间做点积。
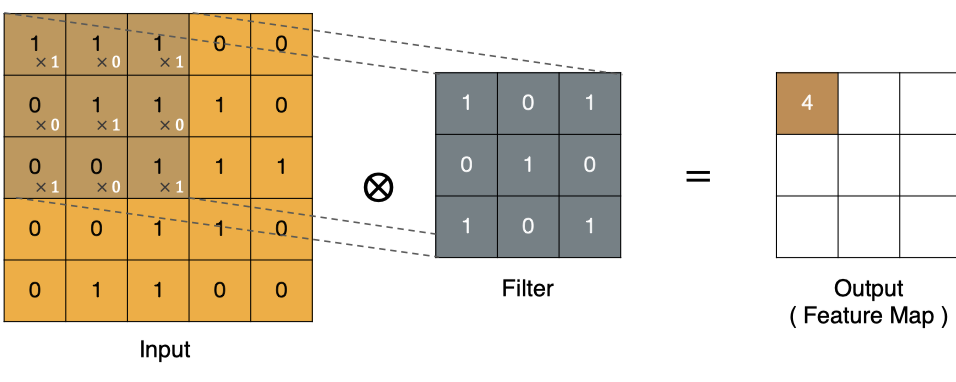
左上角的点计算方法:
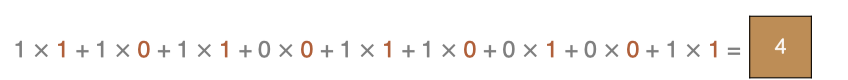
按照上面的计算方法可以得到最终的特征图为:
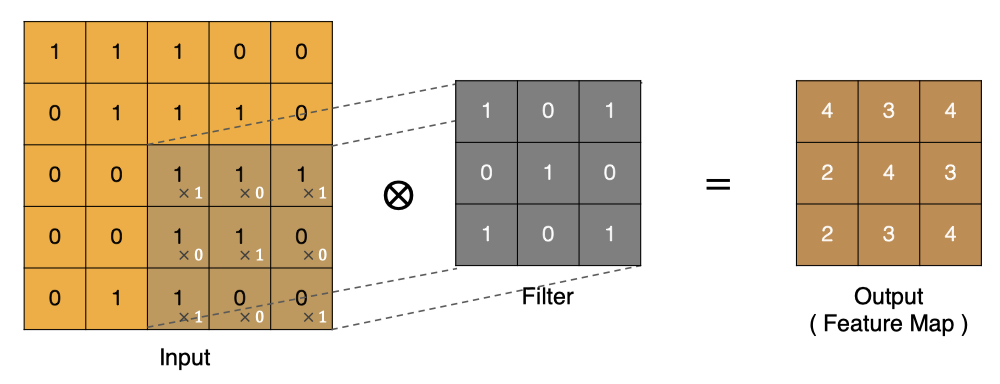
卷积的重要性在于它可以将图像中的特征与卷积核进行卷积操作,从而提取出图像中的特征。
可以通过不断调整卷积核的大小、卷积核的值和卷积操作的步长,可以提取出不同尺度和位置的特征。
# 面向对象的模块化编程
from matplotlib import pyplot as plt
import os
import torch
import torch.nn as nndef test001():current_path = os.path.dirname(__file__)img_path = os.path.join(current_path, "data", "彩色.png")# 转换为相对路径img_path = os.path.relpath(img_path)# 使用plt读取图片img = plt.imread(img_path)print(img.shape)# 转换为张量:HWC ---> CHW ---> NCHW 链式调用img = torch.tensor(img).permute(2, 0, 1).unsqueeze(0)# 创建卷积核 (501, 500, 4)conv = nn.Conv2d(in_channels=4, # 输入通道out_channels=32, # 输出通道kernel_size=(5, 3), # 卷积核大小stride=1, # 步长padding=0, # 填充bias=True)# 使用卷积核对图像进行卷积操作 [9999] [[[[]]]]out = conv(img)# 输出128个特征图conv2 = nn.Conv2d(in_channels=32, # 输入通道out_channels=128, # 输出通道kernel_size=(5, 5), # 卷积核大小stride=1, # 步长padding=0, # 填充bias=True)out = conv2(out)print(out)# 把图像显示出来print(out.shape)plt.imshow(out[0][10].detach().numpy(), cmap='gray')plt.show()# 作为主模块执行
if __name__ == "__main__":test001()
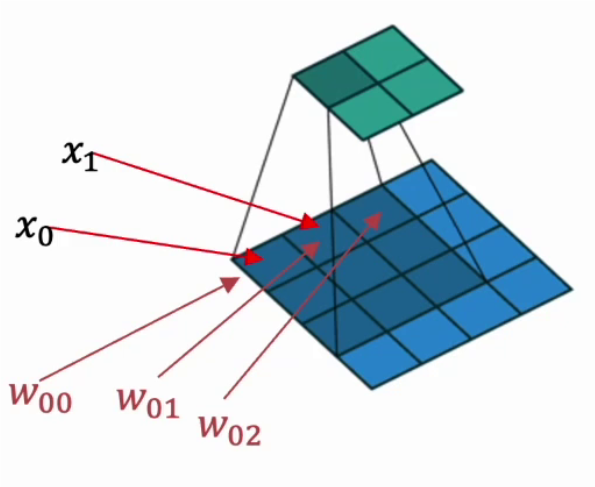
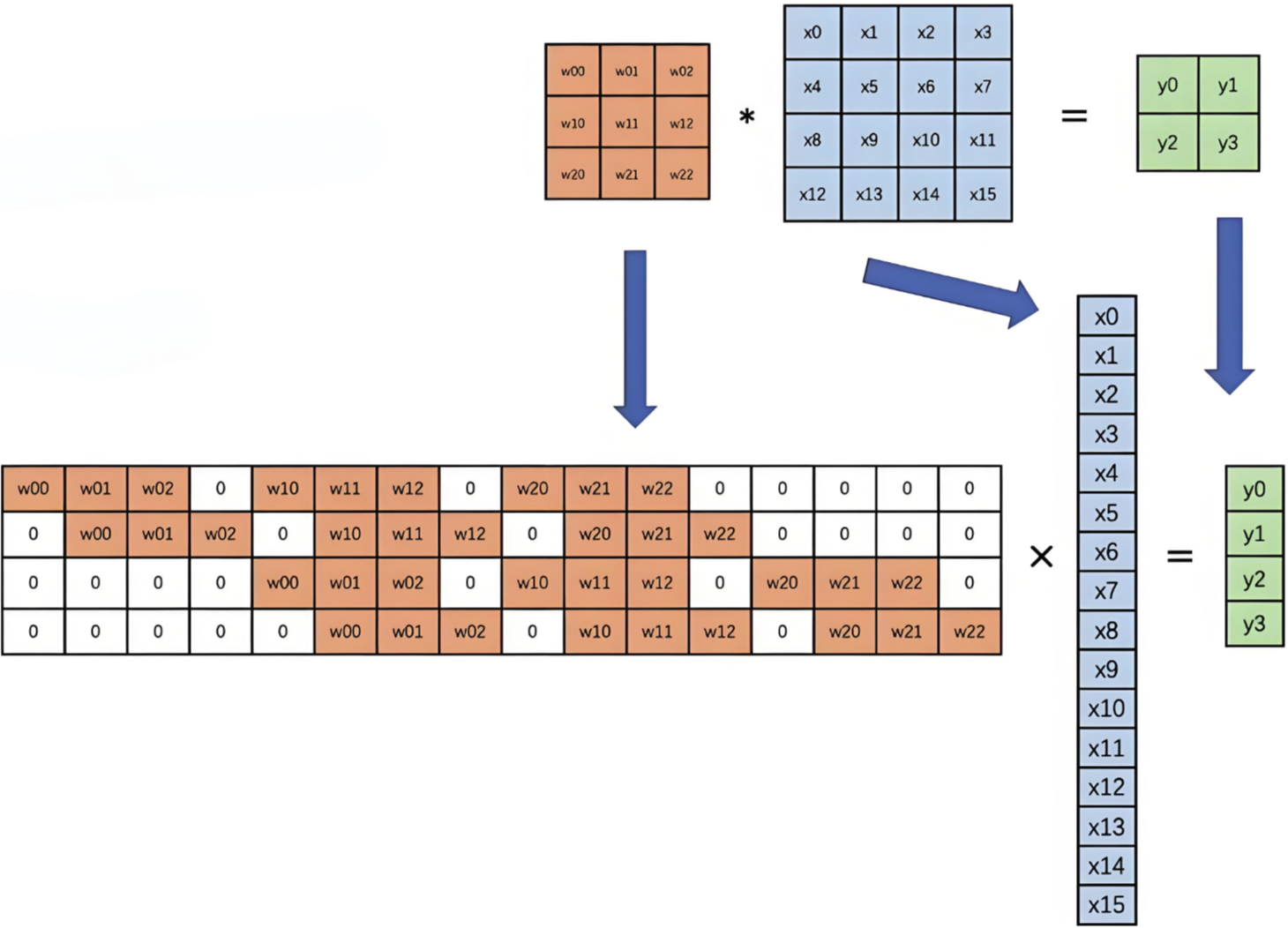
2.2.2 卷积计算底层实现
并不是水平和垂直方向的循环。
下图是卷积的基本运算方式:
卷积真正的计算过程如下图:
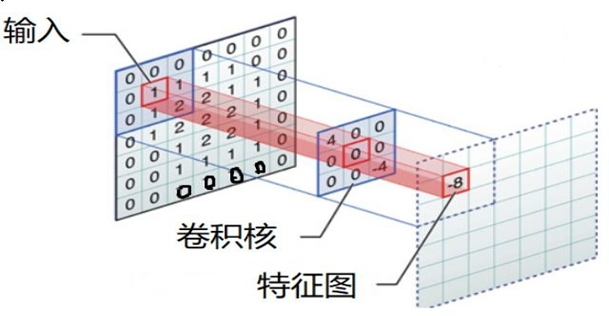
2.3 边缘填充
Padding
通过上面的卷积计算,我们发现最终的特征图比原始图像要小,如果想要保持图像大小不变, 可在原图周围添加padding来实现。
更重要的,边缘填充还更好的保护了图像边缘数据的特征。
2.4 步长Stride
按照步长为1来移动卷积核,计算特征图如下所示:

如果我们把 Stride 增大为2,也是可以提取特征图的,如下图所示:

stride太小:重复计算较多,计算量大,训练效率降低;
stride太大:会造成信息遗漏,无法有效提炼数据背后的特征;
2.5 多通道卷积计算
首先我们需要认识下通道,做到颗粒度对齐~
2.5.1 数字图像的标识
我们知道图像在计算机眼中是一个矩阵
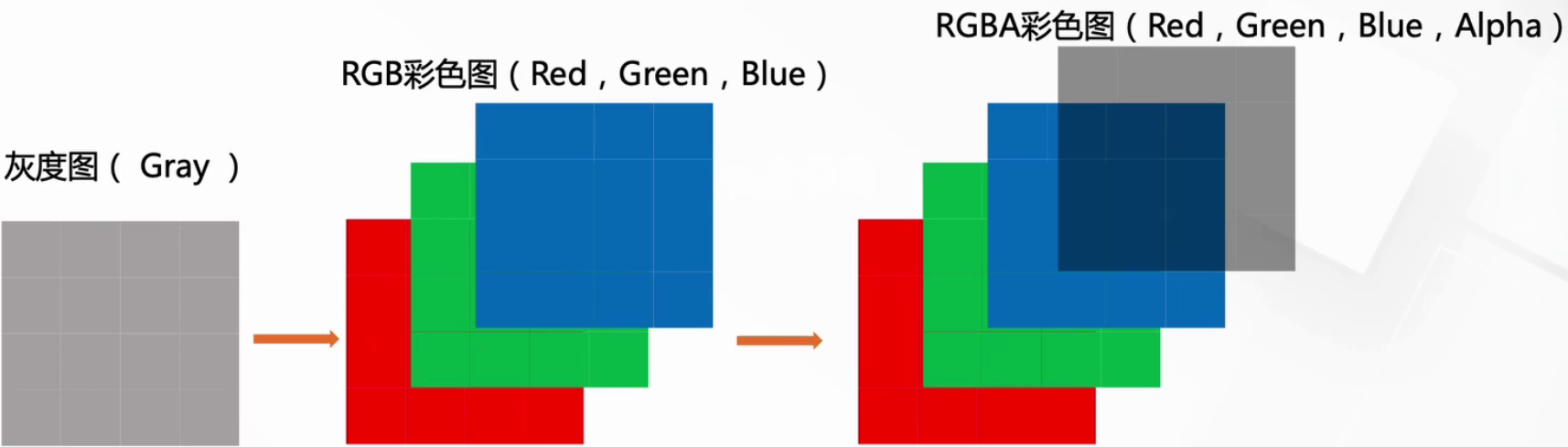
通道越多,可以表达的特征就越丰富~
2.5.2 具体计算实现
实际中的图像都是多个通道组成的,我们怎么计算卷积呢?
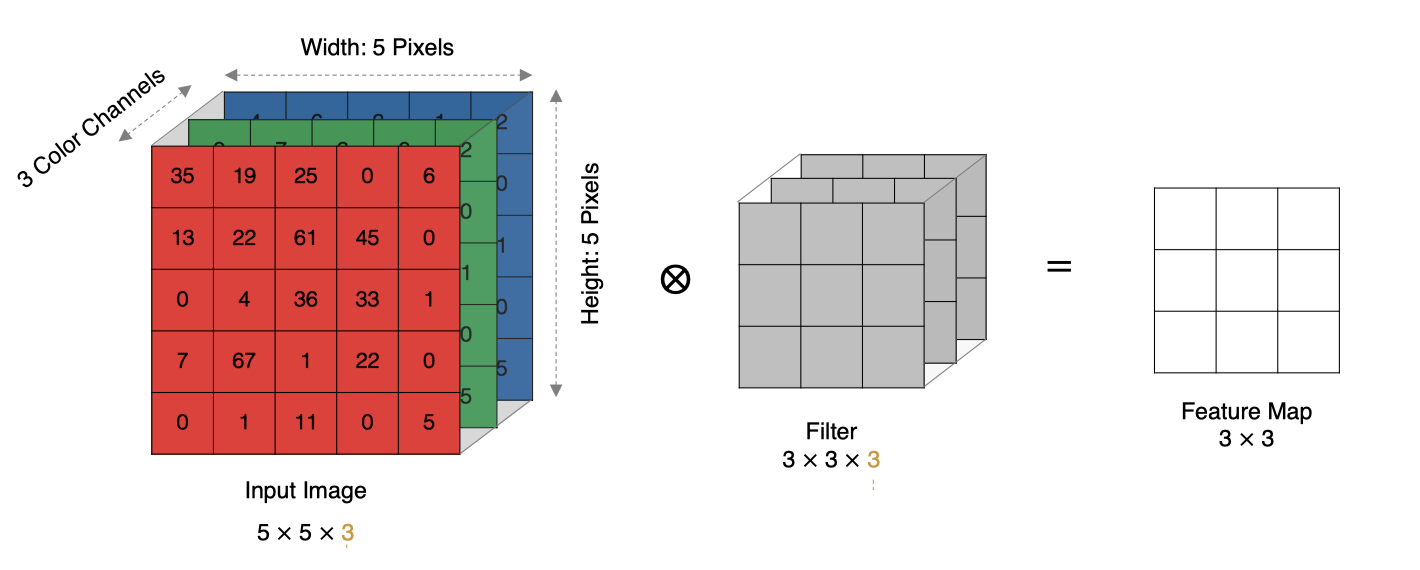
计算方法如下:
- 当输入有多个通道(Channel), 例如RGB三通道, 此时要求卷积核需要有相同的通道数。
- 卷积核通道与对应的输入图像通道进行卷积。
- 将每个通道的卷积结果按位相加得到最终的特征图。
如下图所示:
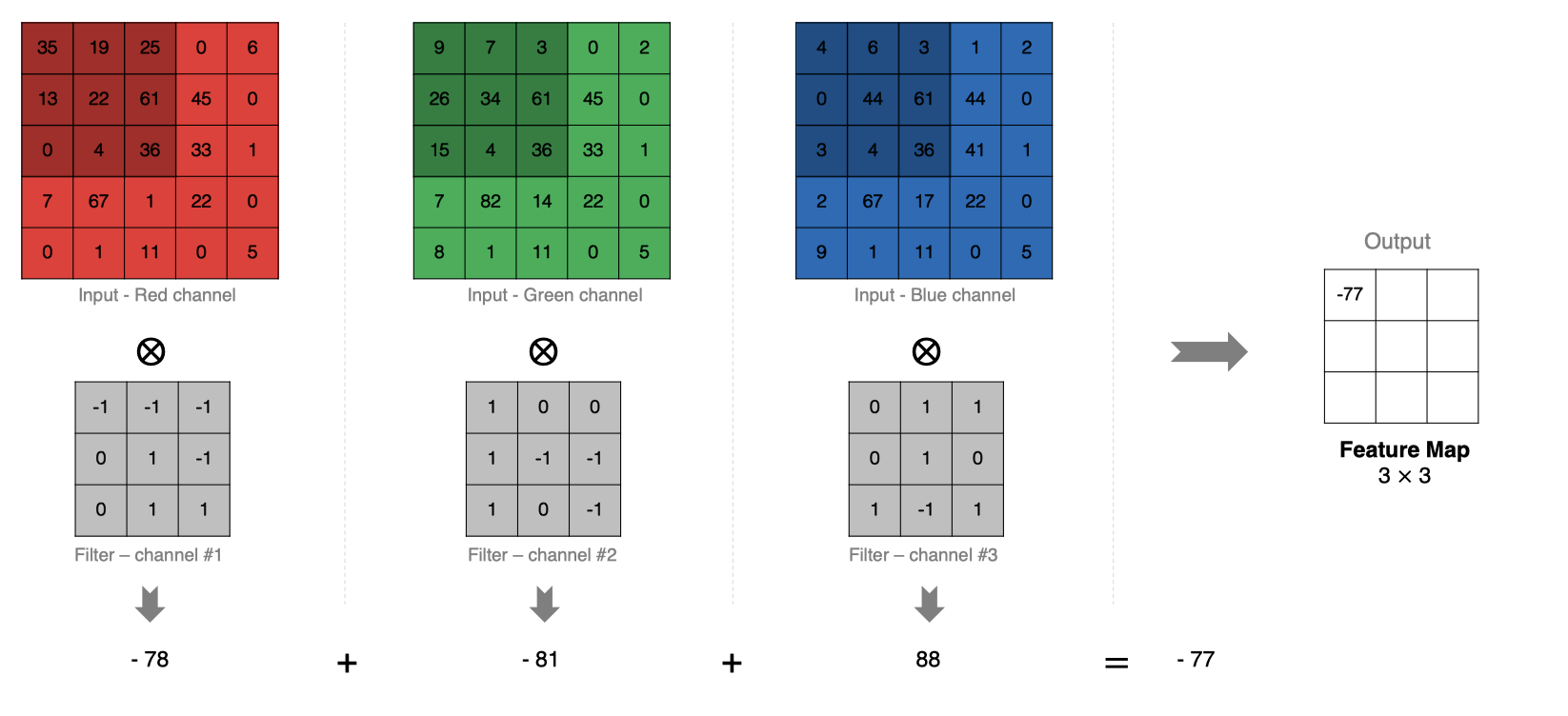
2.6 多卷积核卷积计算
实际对图像进行特征提取时, 我们需要使用多个卷积核进行特征提取。这个多个卷积核可以理解为从不同到的视角、不同的角度对图像特征进行提取。
那么, 当使用多个卷积核时, 应该怎么进行特征提取呢?
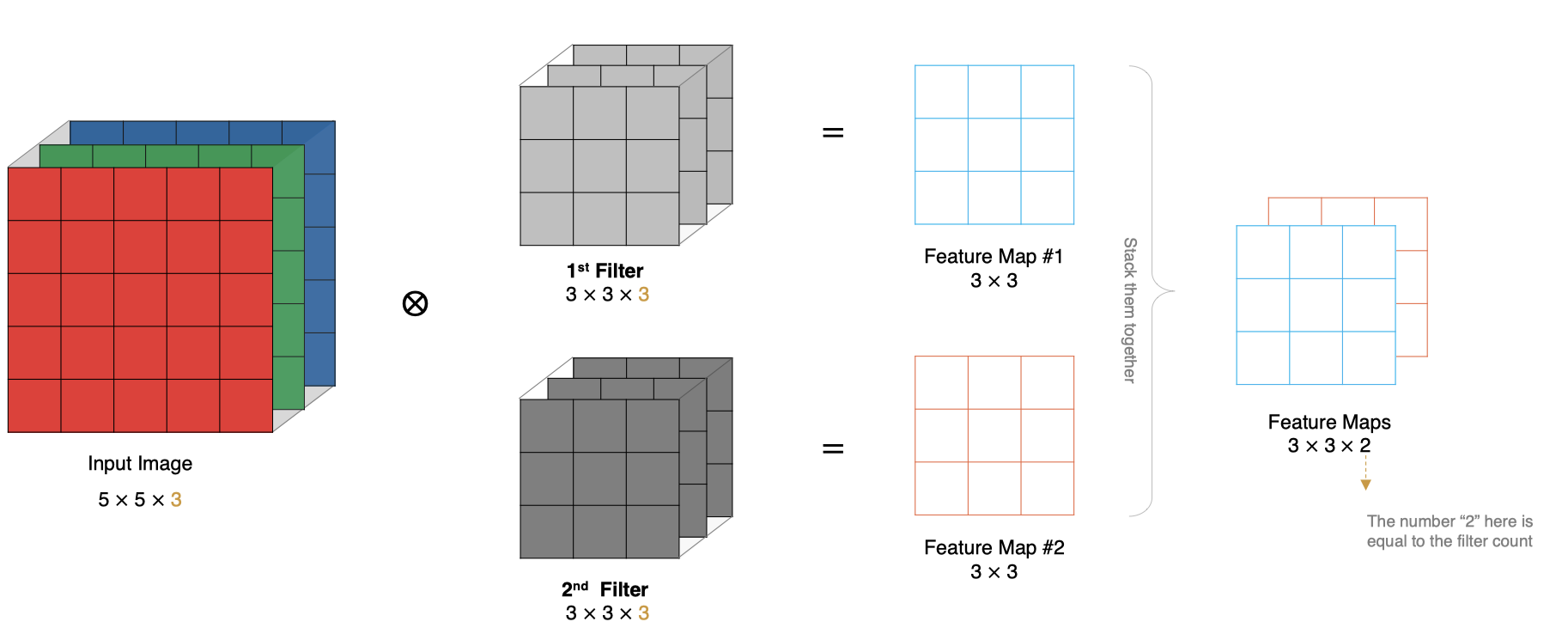
2.7 特征图大小
输出特征图的大小与以下参数息息相关:
- size: 卷积核/过滤器大小,一般会选择为奇数,比如有 1×1, 3×3, 5×5
- Padding: 零填充的方式
- Stride: 步长
那计算方法如下图所示:
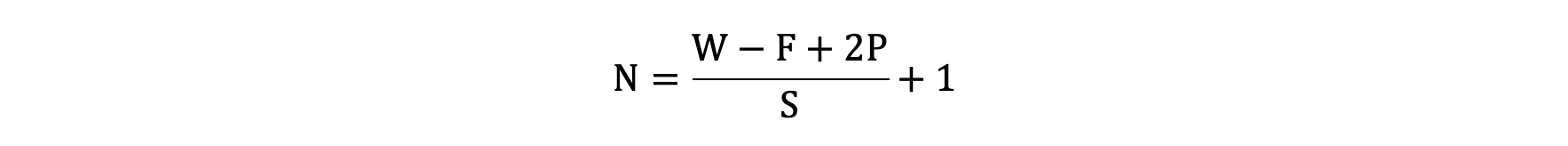
-
输入图像大小: W x W
-
卷积核大小: F x F
-
Stride: S
-
Padding: P
-
输出图像大小: N x N
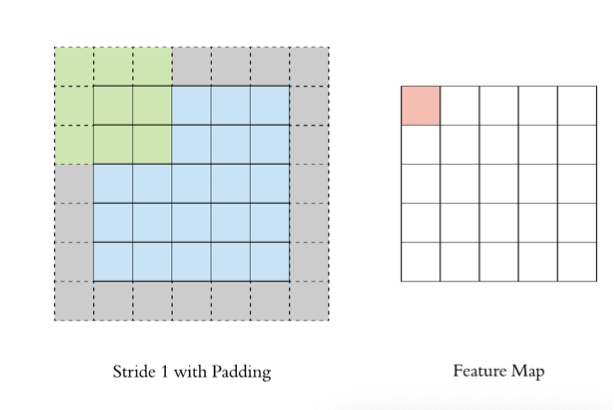
以下图为例:
- 图像大小: 5 x 5
- 卷积核大小: 3 x 3
- Stride: 1
- Padding: 1
- (5 - 3 + 2) / 1 + 1 = 5, 即得到的特征图大小为: 5 x 5
2.8 只卷一次?

2.9 卷积参数共享
数据是 32 × 32 × 3 32×32×3 32×32×3 的图像,用 10 10 10 个 5 × 5 5×5 5×5 的filter来进行卷积操作,所需的权重参数有多少个呢?
- 5 × 5 × 3 = 75 5×5×3 = 75 5×5×3=75,表示每个卷积核只需要 75 75 75个参数。
- 10个不同的卷积核,就需要 10 ∗ 75 = 750 10*75 = 750 10∗75=750个卷积核参数。
- 如果还考虑偏置参数 b b b,最终需要 750 + 10 = 760 750+10=760 750+10=760 个参数。
全连接参数量: 10 ∗ 28 ∗ 28 ∗ ( 32 ∗ 32 ∗ 3 + 1 ) 全连接参数量: 10 * 28 * 28 *(32 * 32 * 3 + 1) 全连接参数量:10∗28∗28∗(32∗32∗3+1)
2.10 局部特征提取
通过卷积操作,CNN具有局部感知性,能够捕捉输入数据的局部特征,这在处理图像等具有空间结构的数据时非常有用。
2.11 PyTorch卷积层 API

test01 函数使用一个多通道卷积核进行特征提取, test02 函数使用 3 个多通道卷积核进行特征提取:
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import osdef showimg(img):plt.imshow(img)# 隐藏刻度plt.axis("off")plt.show()def test001():dir = os.path.dirname(__file__)img = plt.imread(os.path.join(dir, "彩色.png"))# 创建卷积核# in_channels:输入数据的通道数# out_channels:输出特征图数,和filter数一直conv = nn.Conv2d(in_channels=4, out_channels=1, kernel_size=3, stride=1, padding=1)# 注意:卷积层对输入的数据有形状要求 [batch, channel, height, width]# 需要进行形状转换 H, W, C -> C, H, Wimg = torch.tensor(img, dtype=torch.float).permute(2, 0, 1)print(img.shape)# 接着变形:CHW -> BCHWnewimg = img.unsqueeze(0)print(newimg.shape)# 送入卷积核运算一下newimg = conv(newimg)print(newimg.shape)# 蒋NCHW->HWCnewimg = newimg.squeeze(0).permute(1, 2, 0)showimg(newimg.detach().numpy())# 多卷积核
def test002():dir = os.path.dirname(__file__)img = plt.imread(os.path.join(dir, "彩色.png"))# 定义一个多特征图输出的卷积核conv = nn.Conv2d(in_channels=4, out_channels=3, kernel_size=3, stride=1, padding=1)# 图形要进行变形处理img = torch.tensor(img).permute(2, 0, 1).unsqueeze(0)# 使用卷积核对图片进行卷积计算outimg = conv(img)print(outimg.shape)# 把图形形状转换回来以方便显示outimg = outimg.squeeze(0).permute(1, 2, 0)print(outimg.shape)# showimg(outimg)# 显示这些特征图for idx in range(outimg.shape[2]):showimg(outimg[:, :, idx].squeeze(-1).detach())if __name__ == "__main__":test002()效果:

知识拓展(AI生成)
1. 什么是多通道卷积?在处理RGB图像时,如何体现多通道卷积的特性?
多通道卷积是指在卷积神经网络中,针对输入数据的多个通道(如RGB图像的红、绿、蓝三个通道)分别进行卷积操作,并将结果通过加权求和的方式整合为一个输出特征图的过程。其特性在处理RGB图像时主要体现在以下方面:
- 卷积核的深度与输入图像的通道数一致(如3通道的RGB图像对应3深度的卷积核),每个卷积核能够提取输入图像各通道的组合特征。
- 通过多个卷积核的组合使用,能够捕捉图像在不同通道上的复杂特征关联,从而提升模型对图像内容的理解能力。
2. 假设你有一个3通道(如RGB)的输入图像,其尺寸为64x64,应用一个大小为3x3、深度也为3的卷积核进行卷积操作,请描述这个过程。
对于一个尺寸为64x64的3通道(RGB)输入图像,应用一个大小为3x3、深度为3的卷积核时,卷积操作的过程如下:
- 卷积核在输入图像的每个通道上进行滑动,每个位置计算卷积核与图像局部区域的逐元素乘积之和。
- 将三个通道的计算结果相加,得到一个标量值,作为输出特征图对应位置的值。
- 重复上述操作,覆盖整个输入图像,最终生成一个深度为1的特征图(若使用多个卷积核,则输出特征图的深度等于卷积核的数量)。
3. 请计算一个大小为5x5、深度为3的卷积核应用于具有10个通道的输入时,需要多少个可学习参数。如果有偏置项,总参数量是多少?
一个5x5大小、深度为3的卷积核应用于具有10个通道的输入时,可学习参数的数量计算如下:
- 权重参数:卷积核的每个深度(3)与输入通道数(10)对应,因此权重参数总数为5×5×10×3=750个。
- 偏置参数:若包含偏置项,则每个卷积核对应一个偏置,因此总参数量为750+3=753个。
4. 解释卷积层中的偏置项是什么,并讨论在神经网络中引入偏置项的好处。
卷积层中的偏置项是一个与卷积核对应的可学习参数,加在卷积操作后的结果上。引入偏置项的好处包括:
- 提供模型的灵活性:偏置项允许模型在激活函数前调整输出的基准值,使其能够更好地拟合数据。
- 增强表达能力:偏置项为网络提供了额外的自由度,有助于提高模型对复杂模式的表达能力。
5. 在实际应用中,为什么有些卷积层会选择不包含偏置项?列举并解释可能的情况。
在实际应用中,有些卷积层选择不包含偏置项的可能情况包括:
- 当卷积层后面紧跟着批量归一化(Batch Normalization)层时,偏置项的作用会被归一化过程吸收,因此可以省略偏置以减少参数量。
- 在某些轻量级模型设计中,为了降低计算复杂度和参数量,可能会省略偏置项,特别是在输入数据已经过适当归一化的情况下。
6. 在多通道卷积过程中,权重共享如何在不同通道间实现特征学习的协同作用?请结合实际应用案例进行说明。
多通道卷积过程中,权重共享通过以下方式在不同通道间实现特征学习的协同作用:
- 卷积核的权重在所有输入通道上共享,使得模型能够学习跨通道的共性特征。
- 在目标检测任务中,不同通道的特征(如边缘、纹理)通过共享权重的卷积核进行整合,形成对目标形状的有效表示。
7. 当处理高维输入数据时(例如视频帧序列或高光谱图像),针对多个通道上的卷积操作,你可能会采取哪些优化策略以减少计算复杂度并提高模型性能?
针对高维输入数据(如视频帧序列或高光谱图像),可采取以下优化策略:
- 使用深度可分离卷积:将标准卷积分解为逐深度卷积和逐点卷积,显著减少计算量。
- 应用分组卷积:将输入通道分组,每组独立进行卷积操作,降低计算复杂度。
- 采用稀疏连接:设计稀疏连接模式,减少卷积核与输入通道的全连接关系。
8. 请推导一个多通道卷积层(包括多个滤波器和每个滤波器对应的偏置项)前向传播过程中的矩阵运算表达式,并解释反向传播时这些参数(权重和偏置)的梯度是如何计算的。
前向传播过程的矩阵运算表达式为:
![[ Y_{ijk} = b_k + \sum_{m=1}^{M} \sum_{p=1}^{P} \sum_{q=1}^{Q} X_{i+p-1,j+q-1,m} \cdot W_{pqmk} ]](https://i-blog.csdnimg.cn/direct/4e6c8af0d65d4a4db1081c7670802e0b.png)
其中,( X ) 是输入,( W ) 是权重,( b ) 是偏置,( Y ) 是输出。
反向传播中权重和偏置的梯度计算基于链式法则:
- 权重梯度:通过输入数据和输出梯度的卷积计算。
- 偏置梯度:等于输出梯度在对应特征图上的总和。
9. 现代深度学习框架中存在将通道注意力机制融入到卷积层的设计,例如SENet中的Squeeze-and-Excitation模块。请描述这一机制如何影响卷积层对多通道信息的处理,并讨论其优势。
SENet中的Squeeze-and-Excitation模块通过以下方式影响卷积层对多通道信息的处理:
- Squeeze操作:对每个通道进行全局平均池化,获取通道级统计特征。
- Excitation操作:通过全连接层学习通道间的依赖关系,生成通道权重。
其优势在于能够动态调整通道权重,增强重要特征通道的表达,抑制不重要通道,从而提升模型对关键信息的关注能力。
10. 举例说明一种或多通道特征融合的方法,比如深度可分离卷积中的点wise卷积或者跨通道卷积,并阐述它们如何促进不同通道间的特征交互。
深度可分离卷积中的点wise卷积是一种多通道特征融合方法:
- 点wise卷积使用1x1卷积核,将输入的多个通道特征进行线性组合,生成新的通道特征。
- 该方法通过跨通道的线性变换,促进不同通道间特征的交互与融合,同时保持计算效率。
11. 假设你在训练一个用于图像分类的深度卷积神经网络时,发现由于输入图像的多通道特性导致模型过拟合,请提出至少两种通过调整卷积层结构或配置来缓解过拟合的技术方案,并讨论其原理。
针对多通道特性导致的过拟合,可采用以下技术方案:
- 增加Dropout层:在卷积层后添加Dropout层,随机丢弃部分神经元输出,防止模型对训练数据的过度拟合。
- 应用Batch Normalization:通过归一化每层的输入,稳定训练过程,降低过拟合风险,同时减少对偏置项的依赖。
12. 讨论卷积层中偏置项的作用以及它可能引入的问题(如模型的平移不变性)。在某些场景下为何会选择去除偏置项?如果有,会采用什么替代策略来补偿去除偏置带来的潜在损失?
偏置项在卷积层中的作用包括提供模型灵活性和增强表达能力。然而,它可能引入的问题包括:
- 破坏平移不变性:偏置项的加入可能使模型对输入的平移变换敏感。
在某些场景下(如使用Batch Normalization后),去除偏置项的原因在于其作用可被归一化层吸收,从而简化模型结构并减少参数量。
13. 比较全局平均池化、全局最大池化以及具有偏置项的1x1卷积在获取通道级统计特征方面的异同,并根据特定任务需求阐述何时选择哪种方法更为合适。
- 全局平均池化:对每个通道进行全局平均,提取通道的平均响应特征,适用于需要平滑统计的任务(如图像分类)。
- 全局最大池化:提取通道的最大响应,强调显著特征,适用于需要突出关键信息的任务(如目标检测)。
- 1x1卷积:通过线性组合通道特征,生成新的通道级表示,适用于特征融合与通道间关系建模任务。
在特定任务中,若需要对通道特征进行非线性组合和降维,1x1卷积可能更为合适;若仅需提取简单统计特征,则全局池化方法更为高效。