kafka初步介绍
Kafka角色介绍
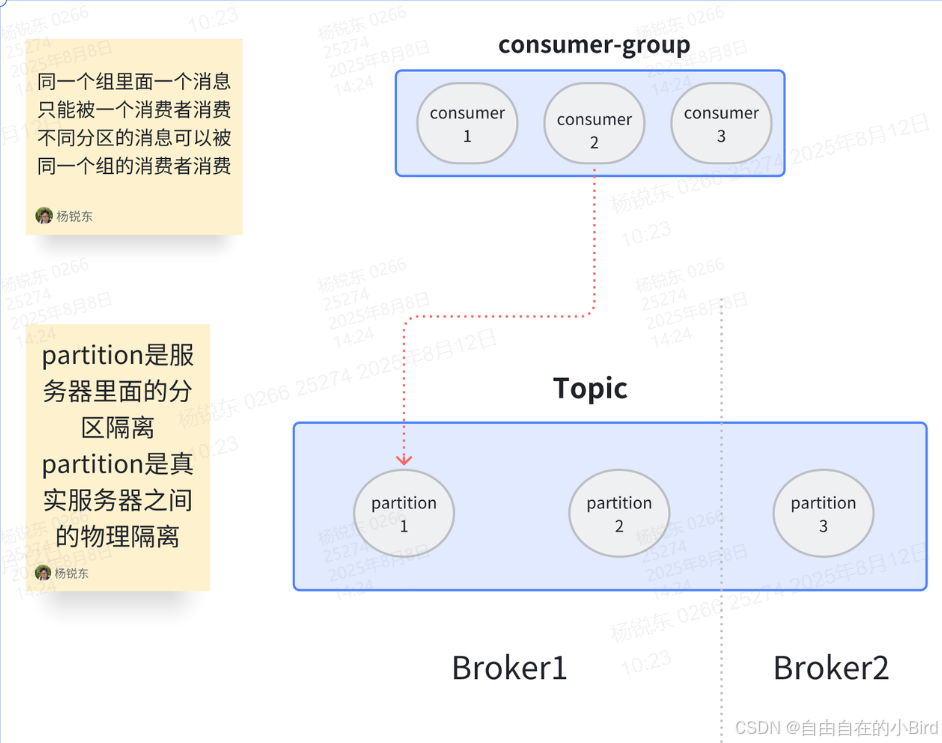
Topic
Topic主题的意思,消费者必须指定主题用于的消息发送,生产者也必须指定主题用于消息的接收。topic只是逻辑上的划分。
partition
partition是分区的意思,他的主要作用是将发送到一个topic的数据做一个划分。如果有4个partition那么消费者就可以去这四个分区中获取消息,理想情况下提高了4倍效率。(降低Topic处理消息的压力)其中的offset是用来记录消息在分区当中的物理位置,可以用来保证在同一分区下消息的顺序性。
partition是将消息以物理的形式进行隔离,就是在一个目录下由不同文件存储。
broker
broker即kafka服务器中的一个节点。用于接收生产者发来的消息、将消息写入磁盘(分区对应的日志文件)、向消费者提供消息、参与分区副本的同步与 Leader 选举
consumer-group
消费者组是让一组消费者消费一个或者多个主题的分区,一个消费者组中一个分区只会被其中一个消费者消费。
分组的好处:组相当于调度中心,如果组内有人丢失消息了,组内维护有offset可以帮忙你送。谁没活都去配置中心领。
为什么不用一个分组消费一个分区。每个组offset不共享,当组内无法处理时外部就会从最开始的消息开始消费出现重复消费。扩展也麻烦想要扩展只能加消费者组。
熟悉Kafka配置
kafka的配置可以通过配置类的形式进行设置,但是我们使用SpringBoot可以通过properties/yaml文件的形式加载配置(值得注意的是properties文件都是以扁平键值对,用 . 分割;yaml文件是通过树形结构)然后就可以通过注解的形式使用Kafka
#表示配置Kafaka服务地址,通过 ,可以配置多台服务
spring.kafka.bootstrap-servers = 127.0.01
#表示Kafka消息失败重试次数
spring.kafka.producer.retries=3
#设置批量发送消息大小的阀值,达到16kb就会批量发送。
#批次发送的意义是为了减少网络开支成本,多条消息建立一次网络通道
#但是这里没有设置消息等待发送时间,也就是每一条消息都会立即发送,这条消息更像是一个保险策略
spring.kafka.producer.batch-size=16384
#设置缓冲区大小,消息都会放到缓冲区里面等待
spring.kafka.producer.buffer-memory=33554432
#消息确认机制 0表示无需ack机制 1表示需要leader节点确认(ACK机制) -1 表示需要所有节点都确认
spring.kafka.producer.acks=1
#设置键值对的序列化方式。kafka对于生产者和消费者都必须设置序列化类型,
#因为Kafka将生产者消息将对象转为字符数组,消费者需要将字符数组转为需要的类型
#所以为了让Kafka能够接收消费消息都需要设置序列化类型
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
----------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------------
#消费者组的意义是为了记录一个组中消息消费到的位置也就是offset
#这样新加入的消费者就知道从哪里开始执行任务
spring.kafka.consumer.group-id=default-group-td-geek
#兜底策略,避免因消息正在消费时,偏移量提交时宕机导致该条消息不消费。
#手动提交,只有在消息被消费完毕之后才会去提交偏移量
spring.kafka.consumer.enable-auto-commit=false
#兜底策略,当消费者启动时,判断偏移量是否可靠,如果不可靠 配置lateset让消费者从最新消息开始消费 配置earliest让消费者从最早消息开始消费
spring.kafka.consumer.auto-offset-reset=latest
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer消息生产者
只需要注入Kafka客户端,调用客服端对象的send方法就可以发送消息,send方法需要指定消息发送到的topic,还有具体的数据。同时我们可以设置key值用于,分区运算,保证消息顺序(在同一个分区下消息可以保证顺序性)
消息消费者
通过注解的方式绑定监听器,监听器可以接收指定的topic用来消费消息。
@KafkaListener(topics = {"alphaess_"})
//ConsumerRecord<String, String> 是Kafka中消息记录对象,第一个String指的是Key 第二个String指的是Value
public void onMessage1(ConsumerRecord<String, String> record){// 消费的哪个topic、partition的消息,打印出消息内容System.out.println("简单消费:"+record.topic()+"-"+record.partition()+"-"+record.value());
}