【多模态目标检测数据集】【VEDAI】航空影像中的车辆检测:小目标检测基准
Vehicle detection in aerial imagery : A small target detection benchmark
航空影像中的车辆检测:小目标检测基准

数据集链接
摘要
本文介绍了VEDAI:航空影像中的车辆检测(Vehicle Detection in Aerial Imagery),这是一个新的航空影像数据库,旨在为无约束环境下的自动目标识别算法提供基准测试工具。数据库中包含的车辆不仅尺寸较小,还呈现多种变化特征,如不同朝向、光照/阴影变化、镜面反射或遮挡现象。此外,每幅图像均提供多光谱波段及多分辨率版本。文中还给出了精确的实验协议,确保不同研究者获得的实验结果具备可复现性和可比性。最后,本文通过展示基线算法在该数据集上不同参数配置下的性能表现,既说明了该任务的挑战性,也为后续研究提供了基准对比数据。
关键词:检测 低分辨率图像 车辆 数据库 航拍图像 红外图像 目标检测 计算机视觉
1.引言
自动目标识别(Automatic Target Recognition,简称ATR)是计算机视觉领域一项自动检测图像中目标的任务,其研发历史已超过35年。此类ATR系统的基本目标在于协助或取代人工在目标检测与识别过程中的角色,从而构建高效可靠的高性能系统。典型应用场景包括监视与侦察——随着现代高分辨率监视传感器产生海量数据带宽的图像,这两项任务正日益需要更高程度的自动化。如Wong[1]所述:对200平方英里区域实施一英尺分辨率(适合识别多数目标的精度)的监视任务,将产生约1.5×10¹²像素的数据。若将区域分割为1000万像素的图像组,图像判读员需处理超过10万张图像,这种不切实际的工作负荷将导致分析延误或缺失。此外,时间延误会使可移动目标发生位移,导致后续任务中无法追踪。因此车辆检测在国防应用中具有关键意义。
尽管在计算机视觉文献中自动目标识别(ATR)已有相当悠久的历史,但即便在该领域最新发展的背景下,这仍是一个具有挑战性的问题。本文实验部分给出的数据便印证了这一点。
传统的ATR处理方法通常遵循以下流程[2]:(i) 预处理阶段,旨在增强目标对比度并降低噪声与杂波;(ii) 目标检测,即定位图像中可能存在的目标区域,通常通过计算高对比度图像区域实现;(iii) 分割阶段,精确地从背景中提取潜在目标;(iv) 识别阶段,从这些潜在目标中提取视觉特征并最终进行分类。
现代自动物体检测方法采用了一种截然不同的范式。其核心思想是通过直接将输入空间与最终决策空间相关联来避免中间决策过程,并广泛运用机器学习技术。两个典型范例分别是基于哈尔小波和级联增强分类器的Viola-Jones人脸检测器[3],以及采用方向梯度直方图(HOG)结合支持向量机(SVM)分类器的Dalal-Triggs行人检测器[4]。流行的词袋模型[5]同样在物体检测领域取得了成功应用[6]。这种高效机器学习算法与判别性特征的结合,构成了现代物体检测技术的基石。近期通过采用更复杂的物体模型(如可变形部件模型[7])也取得了更多改进。
解释该领域进展的一个原因是公开数据集的发布,这些数据集使得新算法能够在真实条件下进行开发、评估和比较。PASCAL VOC [8] 基准测试提供了目标检测的关键数据集之一。从2005年到2013年,每年都会组织评估活动。PASCAL VOC的检测竞赛要求从测试图像的二十个可能目标类别中预测每个物体的边界框和标签。2012年,共有超过10,000张标注图像可用于训练和验证。相关工作部分还介绍了其他多个可用于不同检测任务(如行人检测、人脸检测)评估的数据集,例如ImageNet [9] 或LabelMe [10]。
然而,这些数据集均未真正适配ATR需求。实际上,ATR的特殊性在于需要检测微小目标,而现有数据集中的物体在图像中的尺寸通常超过200像素,甚至可能成为图像主体。近期数据集更关注物体外观多样性、铰接物体和类别数量,而非目标尺寸、图像噪声、多光谱图像或传感器技术等特性
另一方面,据我们所知,近期提出的目标检测方法(如[4,7,11])均未在ATR背景下进行过评估。
在此背景下,本文的动机有两点。首先,本文介绍了VEDAI(航空影像车辆检测)这一新型数据库,该数据库旨在解决现实工业框架下航空图像中小型车辆检测的任务。该数据集旨在促进无约束环境下航空多类车辆检测新算法的开发,使评估图像分辨率或色彩波段对检测结果的影响成为可能。图像包含多种背景,如森林、城市、道路、停车场、建筑工地或田野。此外,待检测车辆具有不同朝向,可能受镜面光斑干扰、被遮挡或伪装。对车辆类型未设置特定限制。这种背景与车辆外观的多样性将推动自动场景分析、场景监视及目标检测领域的进步。其次,我们对若干基线算法进行了基准测试,并展示其在所提数据集上的性能,以便为研究者提供比较基准。
本文的组织结构如下。在第二部分介绍相关工作后,我们于第三部分详细阐述了数据集(包括图像、车辆类别与背景类型、标注信息及数据集的组织方式)。为使算法间比较成为可能,第四部分给出了与该数据集配套的评估方案。最后在第五部分第二节(5.2节)中,我们展示了基于该数据集的基线算法实验,提供基准测试结果并分析了参数对性能的影响。
2.相关工作
物体检测——常被视为计算机视觉领域最具挑战性的任务之一——在计算机视觉文献中拥有悠久历史。本节将聚焦该问题的三个层面:(i) 用于开发、验证与比较物体检测器的公开数据集;(ii) 衡量检测性能的不同方法;(iii) 当前最先进的物体检测技术方案。
2.1. 目标检测数据库
现代计算机视觉方法依赖于机器学习,并需要经过标注的训练数据。此外,越来越多的方法需要相互比较,以确定哪些是最有前景的途径。其结果是,近期大量新的数据集被创建并公开。尽管其中大多数与物体/场景识别相关(例如[12–16])——这与我们的问题相关但需求不同——但专门针对物体检测的数据集却很少。
更准确地说,用于检测的数据集通常分为以下几类:(i) 行人检测 (ii) 人脸检测 (iii) 日常物体检测 (iv) 车辆检测。这些数据集的概述见表1。
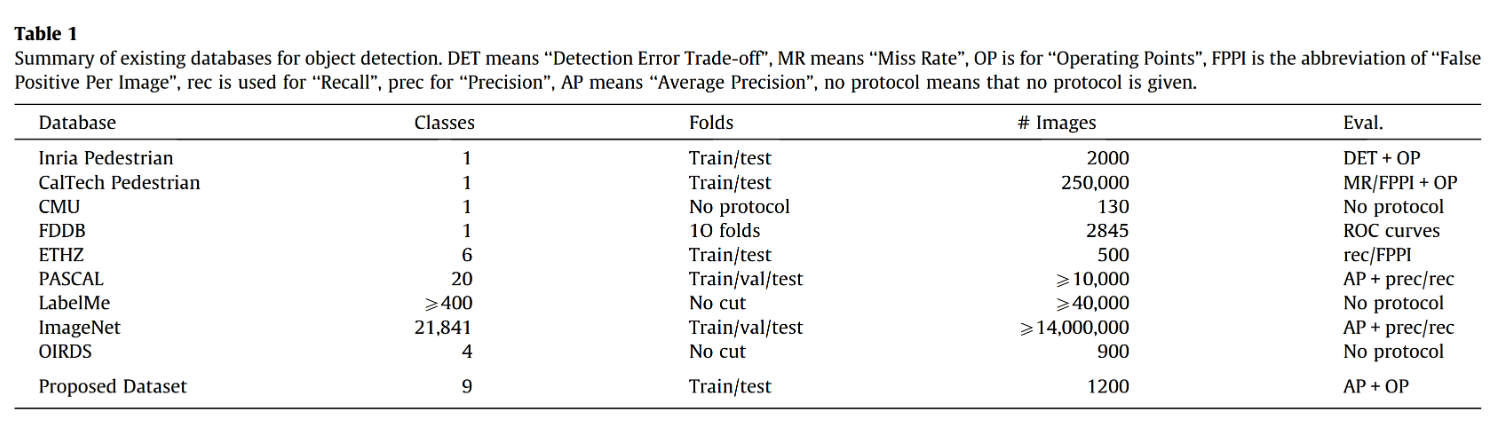
表1 现有目标检测数据库概览。DET指"检测错误权衡",MR表示"漏检率",OP代表"操作点",FPPI是"每张图像误报数"的缩写,rec用于指代"召回率",prec表示"精确率",AP意为"平均精度",no protocol表示未提供评估协议。
2.1.1. 行人/行人检测
这是非常流行的检测任务之一,可能源于其广泛的应用场景(如监控、图像索引、交通安全等)。INRIA行人数据集最初由文献[4]提出,包含数百张不同分辨率(64×128、70×134、96×160)的人体裁剪图像。该数据集同时提供完整背景图像,并按训练集与测试集划分。图像来源包括多组个人照片及少量网络图片,人物呈现任意朝向且背景多样。许多行人是从原始照片背景中截取的旁观者,因此其姿态理论上不存在特定偏差。该数据集的提出是因为先前的基准数据集——MIT行人数据集[17]——挑战性不足。
加州理工学院行人数据集[18]的推出源于INRIA行人数据集被认为规模过小且难度不足,该数据集更专注于行人检测任务。该数据集采集自城市常规交通环境中行驶车辆拍摄的图像,包含25万帧视频中标注的35万个行人边界框。系统采用双重边界框标注遮挡情况,并通过帧间关联标注形成轨迹跟踪。
这两个数据集之间图像数量的增加(从数百到数千)反映了当前数据集制作的一个趋势。
2.1.2. 人脸检测
人脸检测是另一个众所周知的检测任务。与行人检测不同,尽管人脸检测常被视为与安防或安全等重要应用相关的关键任务,但现存的数据集却寥寥无几。现有的大多数人脸相关数据库实际上都面向人脸识别(例如文献[15]),而非人脸检测。CMU-MIT数据集[19](包含MIT数据集[20])是过去广泛使用的基准数据集之一,仅包含130张不同图像,共计507张不同人脸(仅正面视角)。此外,该数据集规模较小,且评估协议和指标未明确定义。正如Hjelmås和Low[21]所指出的,众多使用该数据集的研究论文所呈现的结果无法进行可靠比较。较新的是,柯达公司汇编并发布了一个用于评估人脸检测与识别算法的新图像数据库[22],包含300张不同尺寸的图像,其中人脸尺寸从13×13像素到300×300像素不等。最后,人脸检测领域最常用且知名的数据集是人脸检测数据集基准(FDDB,[23]),其图像源自Faces in the Wild数据集[24]。值得注意的是,FDDB移除了所有宽度或高度小于20像素的人脸。
2.1.3. 日常生活物品
其他一些数据库具有更通用的目的,混合了多种通常取自日常生活的物体类别。例如ETHZ数据集[25]包含5个不同类别(即"标志"、“瓶子”、“长颈鹿”、“杯子"和"天鹅”),这些类别以特定形状为特征。该数据集包含独立的训练和测试子集,图像采集自Flickr和谷歌图片搜索,不仅包含照片还涵盖绘画、素描及计算机渲染图像。每类约有40张训练图像和40张测试图像。
另一个包含日常生活物体的数据集来自Pascal VOC挑战赛[8],这是计算机视觉领域最著名的挑战之一。该挑战包含检测任务,最新版Pascal VOC采用包含20个类别的数据集,总计数千张图像,划分为训练集、验证集和测试集。原始图像源自其他公开数据集及Flickr等网站。
第三个多类别挑战来自LabelMe数据集[10]。该数据库的独特之处在于允许用户自主标注,因此精确类别数量会动态变化。截至2006年12月,该数据集包含11,845张静态图像上的111,490个多边形标注和18,524段视频序列,仍有大量图像待标注。
最后值得提及的是当前热门的ImageNet数据集[9],可用于目标检测任务,其图像总量超过1,400万张。
诸如Flickr图片这类常用于公开数据集的图像,多为消费级相机拍摄的摄影作品。虽然这类图像显然适用于图像检索算法的评估,但其场景与空中监控存在显著差异。此外,目标对象通常是图片的主体(例如车辆常位于图像中央且尺寸较大)。为说明这一点,图1展示了部分来自PASCAL VOC数据集的车辆样本。至于规模更大的ImageNet数据集,其设计初衷完全未考虑监控安防应用,既不包含航拍图像中的车辆标注,也没有红外图像数据。除少量航拍图像中出现在道路或高速公路上、但因尺寸过小(即使人工观察)难以可靠检测的车辆外,我们基本未找到符合本文研究任务的适用图像。

2.1.4. 车辆检测
如[27,28]的研究所示,我们目前展示的数据库存在一些固有偏差,这可以通过图像采集方式得到解释。此外,这些数据与本文研究任务存在显著差异。更贴近我们研究兴趣的是,车辆检测在过去十年间获得了广泛关注。尽管现有车辆数据库资源丰富,但多数库中的车辆均为地面视角拍摄且作为图像主体(如INRIA汽车数据集[29])。部分(更接近的)航拍图像目标检测研究采用了航空数据库[30,31],但遗憾的是这些数据并未公开。因此据我们所知,现有关于航拍图像车辆检测的研究成果均无法复现。
我们可以提及[32]的研究工作,该研究汇总了9个专门用于航空影像中车辆追踪的序列。然而这些序列仅有9个,最多包含50幅图像,且全部拍摄于城市环境。据我们所知,目前唯一可用的数据集是OIRDS(高空影像研究数据集)[26],该数据集包含900张标注图像中的180辆车辆,涵盖五类车型(卡车、皮卡、轿车、厢式货车及未知类型),标注信息包括颜色、镜面反射度、离地距离等。图2展示了OIRDS数据集的部分样本。但该数据库存在两个问题,导致其难以作为目标检测算法的基准:首先,未定义评估协议,存在不同评估可能采用不同训练/测试图像及评分标准的风险;其次,数据集由20种不同来源的图像(总计900张)聚合而成,缺乏统计规律性——平均每个来源仅提供45张图像,样本量明显不足。

图2. 四幅示例性OIRDS图像[26]。
这些问题使得结果难以复现,阻碍了其他研究人员与这项工作进行任何比较。例如,使用该数据集的文献[33]作者采用了自行划分的数据库分类(简单、中等和困难),但未明确每个分类中的具体图像集,导致结果无法复现。同样,文献[34]虽使用了该数据集,却仅给出定性结果。
2.1.5. 性能评估
公正的检测算法实证评估当且仅当明确定义评估协议时方可实现。除数据集外,还需指定评估指标。本节综述了目标检测文献中使用的各类性能度量标准。
首先,正如Dollár等人[18]所指出的,我们可以将多篇目标检测论文(如[4])中采用的"逐窗口性能评估"与目标检测领域常规的"整图性能评估"[35]进行对比。逐窗口评估假设检测任务通过以下方式完成:对以目标物体为中心的裁剪窗口进行分类,并与不含目标图像的窗口进行对比。传统观点认为更高的逐窗口得分会带来更好的整图检测性能,但[18]证明在实际应用中,逐窗口性能可能无法有效预测整图性能。
如Davis和Goadrich[36]所述,接收者操作特征曲线(ROC曲线)[37]是二元决策问题结果呈现的常用方法(例如[3,19])。需注意,尽管目标检测器常输出概率分数,但通常会根据不同操作点通过判别阈值进行二值化处理。ROC曲线是以图形化方式展示二元分类系统在不同判别阈值下的性能表现,通过绘制不同阈值设置下的真阳性率(TPR=正例中判对比例)与假阳性率(FPR=负例中判错比例)的关系曲线实现。ROC曲线有时会被检测错误权衡曲线(DET曲线,如[4,38])替代,后者绘制的是错误拒绝率与错误接受率的关系。DET曲线与ROC曲线信息量相同,但采用1-TP而非TP作为指标。其坐标轴通过标准正态偏差进行非线性缩放,使得权衡曲线较ROC曲线更趋近线性,有助于在高性能区间观察细微差异。
然而,当类别分布存在严重偏斜时,ROC曲线可能会对算法性能呈现过于乐观的评估。这在基于滑动窗口的目标检测中尤为典型,因为待处理的窗口绝大多数为负样本,而每张图像中仅有极少量正样本窗口。在监控应用场景下这一现象更为显著——可能连续数百帧图像中都未出现需检测的车辆。因此,假阳性数量的大幅波动仅会导致ROC分析采用的假阳性率发生微小变化。
在处理高度偏斜的数据集时,精确率-召回率(PR)曲线[39]能更全面地反映算法性能。召回率定义为正确预测的真正例(TP)占所有正例(P)的比例,即召回率=TP/P;而精确率则是真正例(TP)在所有阳性预测(假正例FP加真正例TP)中的占比,即精确率=TP/(TP+FP)。该曲线被广泛用于评估目标检测算法性能,例如文献[40–43]所述方案。
与其用曲线表示性能,更常见的做法是采用适用于特定应用的特定操作点。常用测量指标包括给定阈值下的每图像误报率(FPPI)与每窗口误报率(FPPW)。例如文献[4]选择在10^4 FPPI处召回率对应的操作点,而文献[18]选用1 FPPI(见图2)。当固定某一特征(如FPPI)时,另一特征(如召回率)即可表征性能,这反映了算法在预期FPPI或FPPW下的行为特征。工业场景中算法需满足规范要求,这解释了为何企业常采用此类指标。其他操作点如等错误率(即错误接受率与召回率相等的点)偶有使用,此类选择通常因其计算简便而带有任意性。
另一种用标量数值而非曲线来表征检测算法性能的方法,是采用曲线下面积指标,如受试者工作特征曲线下面积(AUROC)。算法性能越优,其AUROC值越接近1。同理,平均精确率(Average Precision)即精确率-召回率曲线下的面积。通常按照Manning等[44]所述方法,采用11点插值曲线计算平均精确率。尽管该指标不适用于监控任务评估(此类场景更宜采用操作点评估法),但由于其近年被计算机视觉领域广泛采用(如标准评测集PASCAL VOC[8]),我们仍将其纳入评估协议。
此外,评估协议还需明确预测结果为真正例的判定标准,即预测结果与目标对象相匹配的条件。检测算法通常输出检测对象周围的矩形区域(边界框)。当预测边界框的位置和尺度均正确时,(通常)可判定预测结果正确。这一判定常通过计算杰卡德指数(如[8])实现,该指数定义为两个矩形边界框(标注真值与预测结果)交集面积与并集面积的比值。亦有研究采用简单重叠度量法(如[33])。当图像中存在多个对象时,同一标注真值可能对应多个检测结果(例如并排排列的多个对象),可通过构建二分图[45,46]或放宽重叠判定标准[47,48]等方式处理该情况。
最终,如Hoiem等人[49]所指出的,使用矩形边界框存在一些问题,因为物体的形状通常并非矩形,如图3所示。

图3. 左侧:根据Jaccard指数,预测框(蓝色框)被判定为假阳性,因其标注真值框(绿色框)覆盖了非目标物体。右侧:虽然预测框(蓝色框)覆盖了猫且仅覆盖猫,但由于未完全覆盖,仍被判定为假阳性。从另一角度看,该区域也可被视作真阳性。(关于图例中颜色引用的说明,请参阅本文网络版。)
2.2. 最先进的物体检测方法
滑动窗口分类是目标检测领域的主导范式。其核心思想是独立判断所有子窗口属于目标或非目标,并通过非极大值抑制阶段筛选出主要边界框。
这些方法的不同之处在于它们所使用的分类器,通常包括增强型分类器(如[3,50,51])、支持向量机分类器(如[4,52,7,53])、神经网络(如[54]),以及近年来的卷积深度网络[11,55–58]。
分类器采用基于特征的表征方式,能够对微小位移或光照变化等基本变换保持一定的鲁棒性。最有效的特征包括:基于积分直方图计算的Haar类小波(如[59])、边缘片段(如[51])、形状片段(如[61])、梯度方向直方图(HOG,如[4,62])、词袋模型(如[63])、多尺度空间金字塔[64]、协方差描述符(如[38])、共生特征(如[65])、局部二值模式(如[66])、颜色自相似性(如[67]),以及这些特征的组合(如[66,50,67,65,68])。在深度学习方法中,特征与分类器被同步学习。
若大多数基于滑动窗口的方法将目标(及其关联模板)视为刚性物体,一些近期研究则成功探索了由空间组织的不同部件组合来表示目标的模型。例如,可提及基于[69]图像结构的可变形部件模型(DPM)[7,53,61]、姿态基元模型[70]或[71]的部件混合模型。
提升滑动窗口速度的一种方法——继Viola和Jones[3]的成功之后——是采用级联结构。为此,[43,42]研究成功将级联应用于[7]提出的星型结构模型。此外还可通过替代方案跳过大概率不包含目标的窗口,例如Vedaldi等[72]提出的跳跃窗口级联形式的兴趣点检测、使用目标显著性算子(如objectness[73,74])或采用分割技术[41,40]生成类物体窗口假设候选区域。
有几项研究专门针对车辆检测。[30]的研究对不同方法进行了比较,但使用的是经典特征和经典分类器。他们还利用了颜色信息,这在红外图像中无法使用。[75]的研究采用了像素分类方法,这与滑动窗口方法不同。然而,他们的研究同样基于学习颜色特征来检测车辆。
3.VEDAI数据集
如引言所述,我们的动机是提出一个能够支持开发与基准测试的数据集。(小型)目标检测算法,更具体地说,是航空图像中的车辆检测。
数据集规格必须满足以下约束条件:图像应无版权限制或至少在计算机视觉领域可自由使用(这一标准要求较高,因为航拍图像通常成本高昂);不同目标的数量及类型应足够多样化以体现相关应用需求;背景应尽可能丰富多样;目标尺寸应较小(以像素计);数据集附带的标注信息中必须包含足够完整的地面实况数据,以支持目标检测算法的开发与评估。
3.1 图像
在审查了所有符合先前要求的可能图像来源后,我们决定保留犹他州AGRC[76]提供的卫星图像,该资源包含大量可自由分发的航空正射影像。具体而言,我们选用了HRO 2012 6英寸摄影集,其分辨率为每像素4.92英寸×4.92英寸(即每像素12.5厘米×12.5厘米)。这些图像拍摄于2012年春季。原始图像包含4个未压缩的色彩通道(三个可见光通道和一个近红外通道)。
原始卫星图像体积过大,可能超出标准检测算法的处理能力。因此我们决定将其分割为较小的图像。这一做法还有另一优势:可以使数据集聚焦于关键区域。由于图像中绝大部分区域都是重复的相似纹理(如湖泊、山脉、森林),若直接使用会影响性能评估的准确性。我们通过自主选择关键区域,尽可能确保数据集在车辆类型、背景环境及干扰物等方面实现最大程度的多样性。
共计1210张1024×1024像素的图像经过人工筛选后被分为4个子集(见表2):(i) 大尺寸彩色图像(LCIs),(ii) 小尺寸彩色图像(SCIs),(iii) 大尺寸红外图像(LIIs),(iv) 小尺寸红外图像(SIIs)。为便于扩展数据库,UTA数据库中提供了每张1024×1024图像在大图中的精确位置。需说明的是,小尺寸图像均为大尺寸图像的精确复制,仅通过降采样至512×512像素使目标尺寸缩小。彩色图像包含三个8位通道(R、G、B),而红外图像仅有一个8位通道。所有图像的拍摄高度均保持一致——这与PASCAL[8]或LabelMe[10]等数据集中目标距离多变的特点形成显著差异。此设计源于监视应用的特性:飞机通常与地面保持已知距离,且监视系统常具有明确的高度参数规范。此外,本数据集未包含斜视角图像(遗憾未能获取此类素材)。这两项限制虽简化了问题复杂度,但实验结果证明该数据库仍具研究价值。按目标尺寸和成像类型划分数据集,对应了监视应用的两大核心需求。近红外图像集的加入使得算法能在无色彩线索的情况下验证性能。尽管图像数量不多,但足以代表工业级新型传感器可采集的典型数据量。用户亦可基于其他数据训练后在本数据集测试。
虽然某些数据集仅包含单一类型的背景(例如[31]仅包含城市环境中的道路车辆),但我们的数据集涵盖多种不同类型的背景(例如田野、草地、山脉、城区等)。
包含过多车辆的图像(如大型停车场场景,详见文献[33])已被排除,因为对此类图像采用随机位置输出的算法即可获得合理评分。此外,本研究更关注孤立车辆检测及避免复杂背景下的误报。图4展示了部分示例图像。
3.2 车辆
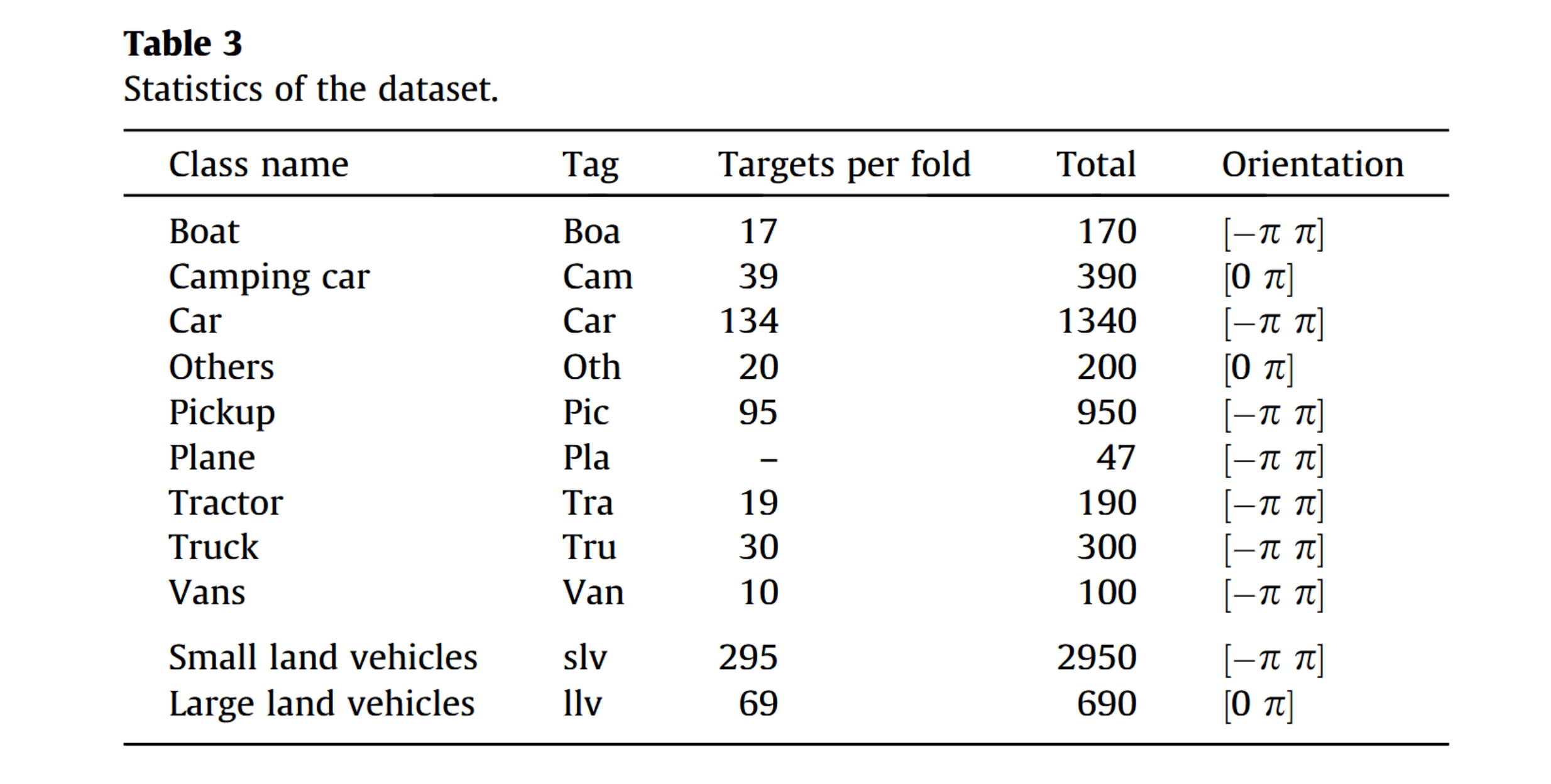
所提出的数据集包含九类不同车辆,分别为“飞机”、“船舶”、“露营车”、“轿车”、“皮卡”、“拖拉机”、“卡车”、“厢式货车”及“其他”类别。图6展示了这些类别的典型图像示例。实验中还定义并考虑了两个元类别:“小型陆地车辆”类别(含“轿车”、“皮卡”、“拖拉机”和“厢式货车”类)与“大型陆地车辆”类别(含“卡车”和“露营车”类)。平均每张图像包含5.5辆车辆,约占图像总像素的0.7%。
‘plane’, ‘boat’, ‘camping car’, ‘car’, ‘pick-up’, ‘tractor’, ‘truck’, ‘van’, ‘other’

3.3. Folds
图像在每个子集中被分为10折,以便采用10折验证方案。划分方式确保每折包含的各类别车辆数量大致相同,但“飞机”类别因目标数量过少而无法均等分配。表3提供了该数据库的一些统计信息。
3.4. 标注
数据集中每个目标均由一名人工操作员按以下方式标注:首先标注图像中车辆中心的坐标及其朝向(与水平线的夹角,模p或2p)、四个角点的像素坐标以及类别标签。此外还包含两个二值标志位,分别表示车辆是否被遮挡以及是否完全位于图像内。对于"房车"和"其他"类别这类前后区分不明显的目标,朝向角度设定在1⁄20p范围内。针对"飞机"类别,我们确保机翼平面位于标注矩形框内,且朝向与机身方向一致。对于"其他"类别,其朝向与车辆长度方向一致。数据集提供的一个单独标注文件汇总了所有标注信息,表4展示了部分示例条目。

为便于使用,标注文件也以独立文件集形式提供,每个图像对应一个文件,其文件名与对应图像名称一致(例如图像00000010.png的标注文件命名为00000010.txt)。这些文件包含的信息与主标注文件完全相同。针对512×512分辨率图像(包括红外与彩色图像)和1024×1024分辨率图像,分别提供不同的标注文件集。同时提供数据库浏览工具,该工具可查看指定图像集的车辆多边形标注框及朝向信息,示例见图5。

4. 性能评估
如前所述,我们提出这一新数据集的动机是为计算机视觉社区提供工具,以推动自动目标检测领域的发展。然而,唯有明确评估性能的方式,方能衡量进展。本节旨在定义伴随该数据集的评估协议,这些评估将针对每个子数据集及每个类别独立进行。
4.1. 协议
该协议采用十倍交叉验证流程,这是机器学习领域评估算法的标准方法[77]。交叉验证是一种模型验证技术,用于评估统计分析结果在独立数据集上的泛化能力。单轮交叉验证需将数据样本划分为互补子集:在一个子集(称为训练集)上执行分析,在另一个子集(称为测试集)上验证分析结果。为降低方差,需使用不同划分方式执行多轮交叉验证,并将各轮验证结果取均值。本研究所用数据集提供预定义折叠(即每折图像列表固定),其折叠划分确保每折中各类别车辆数量大致相同。
在10折交叉验证中,保留其中1折作为测试数据以评估模型性能,其余9折作为训练数据。该过程重复进行10次,确保每个子样本均被用作测试数据一次。最终将10次结果取平均值作为单一估计值,并同时报告10折结果的标准差。
这种方法相对于重复随机子采样的优势在于:所有观测数据既用于训练也用于验证,且每个观测数据仅用于测试一次。请注意,尽管提供了训练/验证划分,但任何划分都可用于交叉验证。测试折叠的性能将通过下一节定义的性能指标进行评估。
4.2. 指标
待评估的检测算法需处理测试折中某组包含的图像集,并输出一组预测结果,即目标在测试图像中的预测位置。检测结果为五元组向量,分别包含目标被检测出的图像ID、目标类别、其在图像坐标系中的坐标以及置信度分数。检测分数取值范围不受限制,但分数越高表示对该检测结果的置信度越高。
理想情况下——由于我们关注不同的工作点(如ROC曲线的不同点位)——工作点应作为检测算法的参数,并针对不同工作点分别运行算法。这对于依赖级联结构的算法尤为重要,因为它们无法为整个分数范围对检测结果进行评分(低分结果会被级联的前几层过滤掉)。不过出于简化考虑,且因该设定覆盖大多数情况,我们假设检测算法能够提供评分,并通过相应阈值处理获得不同工作点。
在实际应用中,算法需输出一个文本文件,每行对应一个预测检测结果,如表5所示。每行包含图像ID、类别、检测位置及置信度分数。

在此类情境中常规采用的做法是,我们旨在评估不同工作点的性能表现——如前所述,这通过调整检测阈值来实现。更具体而言,第一项指标是精确率-召回率曲线(Precision-Recall Curves),选择该指标是因为:(i) 与ROC曲线不同,它不受图像处理窗口数量的影响;(ii) 该指标在计算机视觉文献中被广泛使用。第二项指标是给定每幅图像误报数(False Positive Per Image)下的平均召回率,这更贴近应用开发者的实际需求。两项指标的具体定义将在下文中详述。
对于给定图像I和特定阈值t,只有I中得分高于t的检测结果才被视为有效检测,其余则予以排除。在阈值t条件下,图像I中与真实标注匹配的检测数量记为真正例(True Positive)或TP(I; t),而对应非目标区域的检测结果则记为假正例(False Positive)或FP(I; t)。同理,未被检测到的目标(漏检)记为假负例(False Negative)或FN(I; t)。
它使我们能够针对给定的操作点t,定义给定测试折的精确率和召回率如下:
precision(t)=∑l∈foldTP(l,t)∑l∈foldTP(l,t)+∑l∈foldFP(l,t)\mathrm{precision}(t)=\frac{\sum_{l\in\mathrm{fold}}\mathrm{TP}(l,t)}{\sum_{l\in\mathrm{fold}}\mathrm{TP}(l,t)+\sum_{l\in\mathrm{fold}}\mathrm{FP}(l,t)}precision(t)=∑l∈foldTP(l,t)+∑l∈foldFP(l,t)∑l∈foldTP(l,t)
recall(t)=∑I∈foldTP(I,t)NT\mathrm{recall}(t)=\frac{\sum_{I\in\mathrm{fold}}\mathrm{TP}(I,t)}{N_T}recall(t)=NT∑I∈foldTP(I,t)
其中NT表示所考虑折叠中的目标数量。我们还将每幅图像误报率(FPPI)定义为:
FPPI(t)=∑l∈foldFPNtest\mathrm{FPPI}(t)=\frac{\sum_{l\in\mathrm{fold}}\mathrm{FP}}{N_{\mathrm{test}}}FPPI(t)=Ntest∑l∈foldFP
其中Ntest为所考察折次中的图像数量。
通过考虑所有可能的t值得到的完整精确率-召回率曲线包含丰富信息,但通常需要将其概括为单一数值。传统方法是采用11点插值平均精确率:在0.0、0.1、0.2……1.0这11个召回率水平上测量插值精确率,随后计算这些插值精确率的算术平均值。该方法曾应用于TREC 8[44]。实际应用中需选定具体t值,可根据精确率-召回率曲线的预期工作点进行选择。
除平均精度外,我们还针对每张图像10²、10¹、1及10个误检的四种不同FPPI率计算了召回率。
共计获得5项测量指标:平均精度均值(mean average precision)及4种召回率下的FPPI值。这5项指标均在10个测试折(test folds)上分别计算,并报告其均值与相应标准差。
我们现在需要定义何为真正例(True Positive),即当预测目标与真实标注中的某个目标相符时的情况。原则上,需要找到预测与真实标注之间的最佳匹配组合。但在我们的案例中,由于目标互不重叠且物体仅具单一尺度,故可通过将每个预测分配至真实标注中最近的目标来大幅简化该过程。
通过将预测目标的坐标(以像素为单位)表示为 p = (x, y),将地面实况中最接近目标的坐标表示为 P = (X, Y),若预测值位于以地面实况为中心的椭圆内,则视为正确预测(即真阳性 TP),判定标准如下:
(p−P)t(cosαsinα)−sinα(01H2)(cosαsinα)cosα(p−P)⩽1(4)\begin{aligned}(p-P)^t\binom{\cos\alpha}{\sin\alpha}&-\sin\alpha\\(0&\frac{1}{H^2})\binom{\cos\alpha}{\sin\alpha}&\cos\alpha\end{aligned}(p-P)\leqslant1\\(4)(p−P)t(sinαcosα)(0−sinαH21)(sinαcosα)cosα(p−P)⩽1(4)
其中W和H分别表示目标像素高度与宽度的一半,a代表目标的(真实)方位角。根据构造原理,椭圆会与目标边缘相切(飞机类别除外,但需注意该类别因图像数量过少不参与检测)。因此,两个目标的椭圆不存在重叠区域,故无需考虑更复杂的分配流程。若多个检测结果对应同一真实目标,则取置信度最高者记为真正例(TP),其余既非假正例(FP)亦非真正例的结果予以剔除。但所有的误报(False Alarms)均计入误报统计。
5.实验
我们在自己的数据集上测试了若干最新算法,提供了可供对比的基准结果。这些实验的动机在于:(i) 通过展示前沿算法在该数据集上的表现来刻画数据特征;(ii) 提供基线结果以便定位新方法的性能水平。我们深知这些并非最优算法,但可作为强有力的对比基准,同时也印证了该数据集的挑战性。
我们将研究重点集中于滑动窗口方法——当前此类任务最高效的解决方案。具体而言,我们实现了基于支持向量机(SVM)的标准滑动窗口流程,采用三种特征描述符:梯度方向直方图(HOG)[4]、局部二值模式(LBP)[78]和局部三值模式(LTP)[79]。同时实验了文献[7]提出的可变形部件模型(DPM)代码,该模型能将目标分解为不同根节点和部件。为全面对比,我们还实现了模板匹配算法[80](该技术曾是小目标检测的传统方案),并测试了基于霍夫森林[81]的非滑动窗口检测协议。
5.1. 不同检测器的实验设置
5.1.1 滑动窗口流水线
5.1.1.1. 视觉特征。待分类的矩形区域通过以下三种特征之一或其组合(表征的串联)来表示。下文将更精确地描述这些特征的实现方式(即方向梯度直方图、局部二值模式或局部三值模式)。
我们对HOG31(梯度方向直方图31维)的实现基于文献[4],并采用了Felzenszwalb等人[7]提出的改进方案,该方案预计能获得更优结果。Felzenszwalb团队[7]指出,在标准HOG特征中增加对比度敏感与不敏感特征可提升性能。该算法生成31维描述符:前27个分量对梯度方向敏感,后4个分量对梯度强度敏感。在下述表格中我们将统一称该描述符为HOG31。本方案采用的梯度范数为彩色图像多通道下的最大范数。特征提取时,待表征的矩形区域按16×16像素的块网格划分,块间重叠8像素。每个块计算有向梯度直方图时,无符号方向采用9个方向区间,有符号方向则采用18个方向区间。
局部二值模式(LBP)[78]由图像的局部差异构成。具体而言,图像中每个像素p通过以下方式获得二进制编码:code = ∑_(i∈V) 2^i (I§ < I(p_i)),其中p_i为待编码像素p邻域(V)内的像素点。我们采用3×3邻域,可生成256种可能的编码组合。仅使用均匀模式LBP,即当二进制编码循环遍历时,0到1或1到0的跳变不超过两次的模式(因此共有59种均匀LBP)。在16×16单元格内计算编码直方图,并进行L1归一化处理。
局部三值模式(LTP)[79]是LBP的扩展方法,旨在处理近恒定图像区域的问题。该编码通过设定阈值,将中心像素与邻域像素的差值表示为三种不同值(1、0或-1)。三值模式由考虑正负分量的两个二进制模式组合而成:编码公式为code = Σi∈V 2^i·s(pi - p) + Σi∈V 2^(i+|V|)·s(p - pi)。实验中采用标准阈值τ=5。与LBP类似,仅保留均匀LTP模式以消除噪声编码。特征直方图在16×16像素块中计算,并通过L1范式归一化。对于LBP和LTP,彩色图像通过三通道取均值转换为灰度图像处理。
5.1.1.2 支持向量机(SVM)分类器。实验中我们采用svmlight[82]库。为提高效率,所有实验均使用线性核函数。初始分类器以训练集中的目标区域作为正样本,随机选取的背景区域(不与目标重叠)作为负样本进行训练。如文献[4]所述,通过添加难分负样本(即得分最高的假阳性区域)可二次提升分类器性能。该过程循环迭代直至遍历整个数据库。
5.1.1.3. 步长。该算法的关键参数之一是步长,即滑动窗口在两个位置之间的移动量(以像素为单位)。实际应用中,对于1024×1024图像,步长设为8像素——这在效率与性能之间取得了较好平衡;对于512×512图像则设为4像素。由于车辆尺寸可近似已知,除原始尺度外仅需探索4个放大尺度(所有尺度均大于原始尺度),因模型是以最小尺寸的正样本构建而成。尺度缩放因子为2的1/10次方,此为典型取值(如文献[7]所示)。实际操作中,图像会进行降采样处理,而滑动窗口尺寸保持不变。
5.1.1.4 多根分类器。由于采用线性分类器,仅用单一模型表示物体外观通常不够。实践中我们采用文献[7]的多根SVM方法,使用12个不同根模型对目标进行建模。将目标朝向聚类为6组,每组学习一个检测器。每个视角通过平均训练边界框尺寸获得固定宽高比。需注意:训练分类器所用的矩形区域并非标注真值区域,而是基于前述步长参数选择网格中最接近区域,从而使训练样本能捕捉目标在边界框内因步长产生的偏移。此外,我们根据车辆朝向对所有图像进行镜像翻转,再训练另一组6个检测器,最终形成共计12个检测器。每个检测器均独立应用于图像。
5.1.1.5 非极大值抑制。据观察,滑动窗口检测器通常会对单个目标输出多个检测结果。在文献中,过滤这些多余检测结果的操作通常称为非极大值抑制(NMS)[3]。实验中我们采用Viola和Jones[3]的方法:当两个检测结果重叠时,仅保留得分最高的检测结果。该方法可合并来自不同检测器的结果。
5.1.2. 模板匹配
此外,我们还实现了一种标准模板匹配方法。模板通过根据目标朝向对训练目标进行聚类获得,随后采用k-medoid算法[83]为每个聚类生成2个代表性模板。我们通过归一化平方差之和来定位模板出现位置:
s(f)=1/mintemplate(∑(f(i)−template(i))2∣∣f∣∣∗∣∣template∣∣)s(f)=1/\min_{\mathrm{template}}\left(\frac{\sum\left(f(i)-\mathrm{template}(i)\right)^2}{\sqrt{||f||*||\mathrm{template}||}}\right)s(f)=1/templatemin(∣∣f∣∣∗∣∣template∣∣∑(f(i)−template(i))2)
5.1.3. 可变形部件模型
我们在可变形部件模型(DPM)检测器[7]上的实验采用了最新公开的实现版本2。仅需设置一个参数——用于模型学习的根部件数量。但为适配我们的数据库,需进行若干调整:为使DPM能检测如此微小的目标,我们不得不放大图像并移除原代码中舍弃小型正样本的过滤逻辑。参照[84]的研究,我们禁用了部件学习机制,因为在如此小的目标上学习部件特征缺乏实际意义。
相较于我们自研的检测流程,DPM存在若干差异:其一,采用镜像处理策略,将每个根部件划分为左右对称的两个子部件;其二,具有潜在学习能力,可将形态相似的样本自动归类,而非仅依赖目标朝向和宽高比进行匹配。
5.1.4. 随机霍夫森林
我们还测试了[81]提出的随机霍夫森林算法(该算法不基于滑动窗口协议)。所有数据集均使用15棵树进行测试。针对VeDAI-Small数据集采用4×4图像块(预实验表明该尺寸效果最佳),对VeDAI-Large数据集则采用8×8图像块。
5.2. 结果
本节呈现了四种不同的实验结果。首先,我们在小型红外图像数据集(SII子集)上对第5节介绍的基准检测器性能进行了比较。其次,在其余三个子集上评估了最优基准检测器的表现,并就图像类型和分辨率的影响展开分析。第三,我们提出了一项简短的参数研究,针对不同检测算法的关键参数进行了实验验证。最后,我们展示了评估流程中的参数如何影响性能评价结果。
5.2.1. SII子集上的结果
该子集最为困难,因为仅使用一个带宽且图像尺寸最小。定量结果如表6所示。
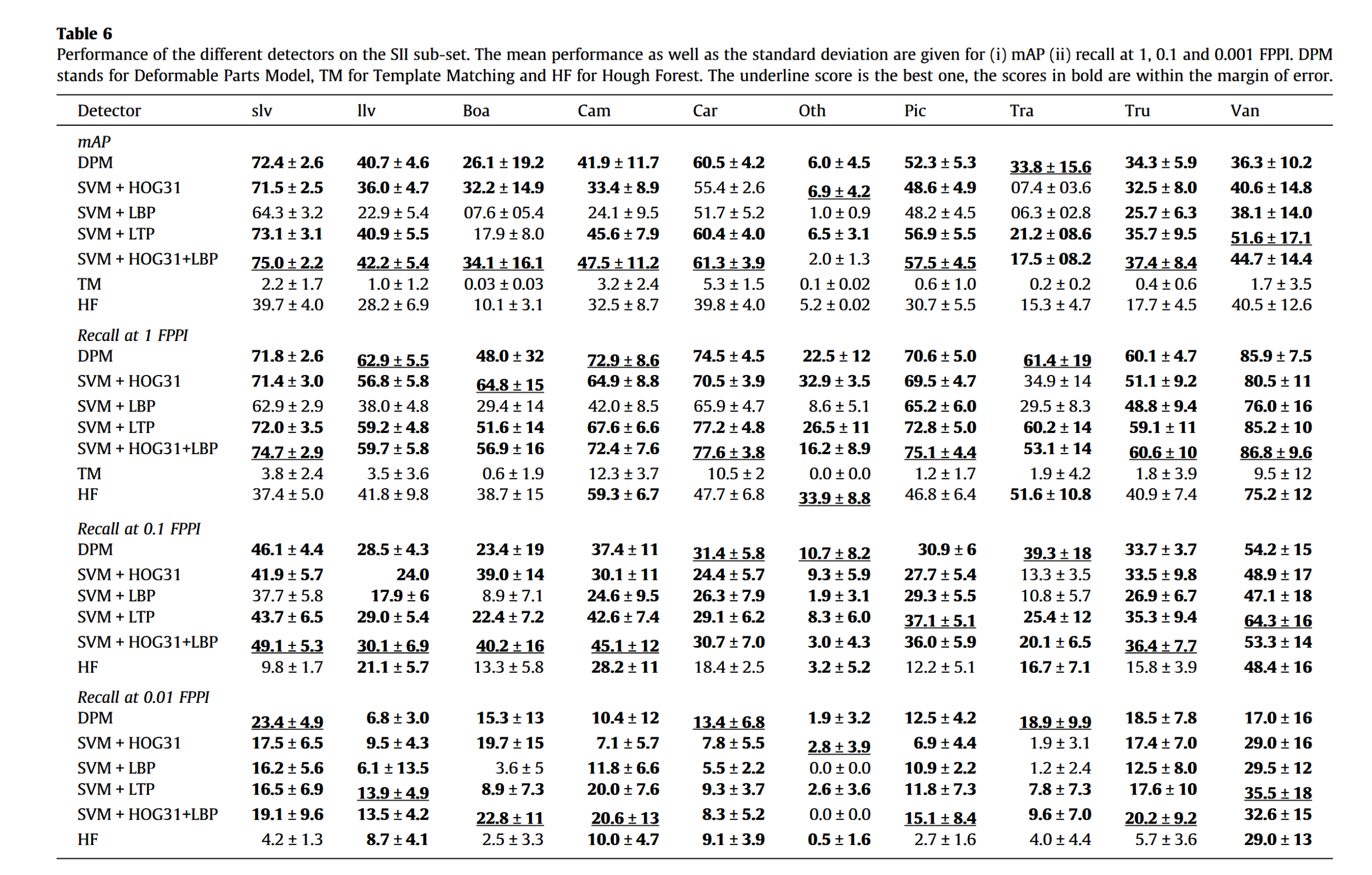
G的检测器相当。最后,霍夫森林方法虽显示出一定潜力,但仍逊于所有SVM+特征组合方法。
但从该表格中我们获得的最重要启示是:这些方法的整体表现均不理想。事实上,即便平均准确率(mAP)较高,在0.01 FPPI(这是目标应用场景中的实际工作点)处的召回率仅介于10%至20%之间,这意味着绝大多数目标未被检测到。同时可以注意到,在低FPPI值时,由于检测到的目标数量过少导致方差估计不可靠,标准偏差会显著增大。这些不佳结果与先前关于低分辨率图像(640×480像素)中行人检测的研究结论一致——在0.1 FPPI条件下,漏检率超过60%[85,86]。
训练样本较少的类别(如“拖拉机”、“船只”和“其他”)难以学习,这符合预期。然而“厢式货车”类别虽训练样本少但检测效果尚可,可能因其外观与其他类别差异显著。
5.2.2 大尺寸图像与彩色图像上的性能表现
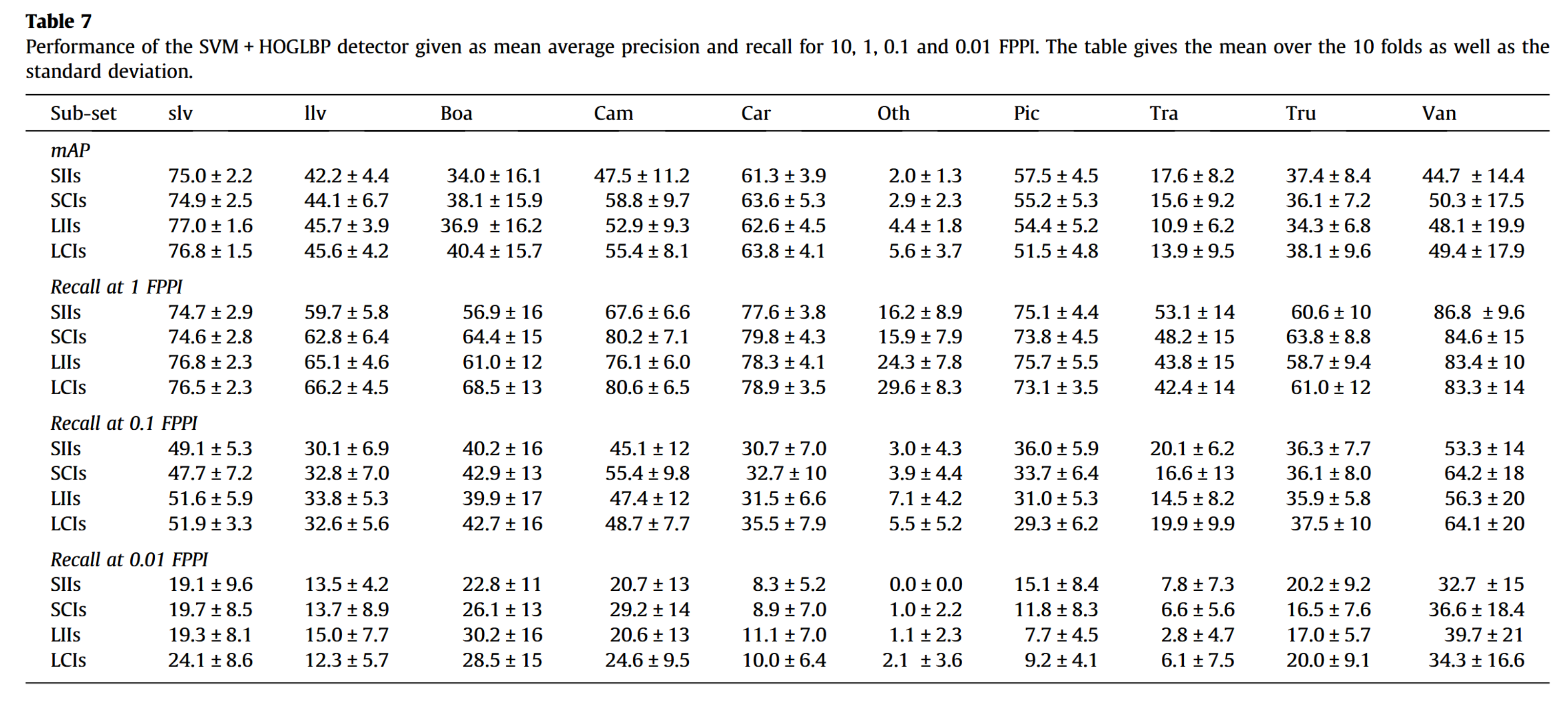
我们选取了在小尺寸图像子集(即SVM+HOG+LBP检测器)上表现最佳的检测器,并在其他三个子集(LIIs、SCIs、LCIs)上进行了测试。结果如表7所示。彩色图像的检测结果通常更优,尽管HOG特征并未充分利用色彩信息。值得注意的是,"皮卡"和"拖拉机"类别的检测性能反而不及红外图像,这可能是由于此类车辆常载有货物,在可见光波段会产生大量无关色彩梯度。综上,成像技术(红外或彩色)的选择取决于目标应用场景。
分辨率同样是性能提升的一个因素,即便我们原本预期会有更显著的差距。某些类别的性能提升非常明显(例如‘其他’、‘摄像机’、‘船只’),但出乎意料的是‘皮卡车’和‘拖拉机’类别的性能却有所下降。这可能是由于这些车辆后部的负载在低分辨率下会变得模糊,从而使其外观显得更为稳定。
5.2.3. 参数研究
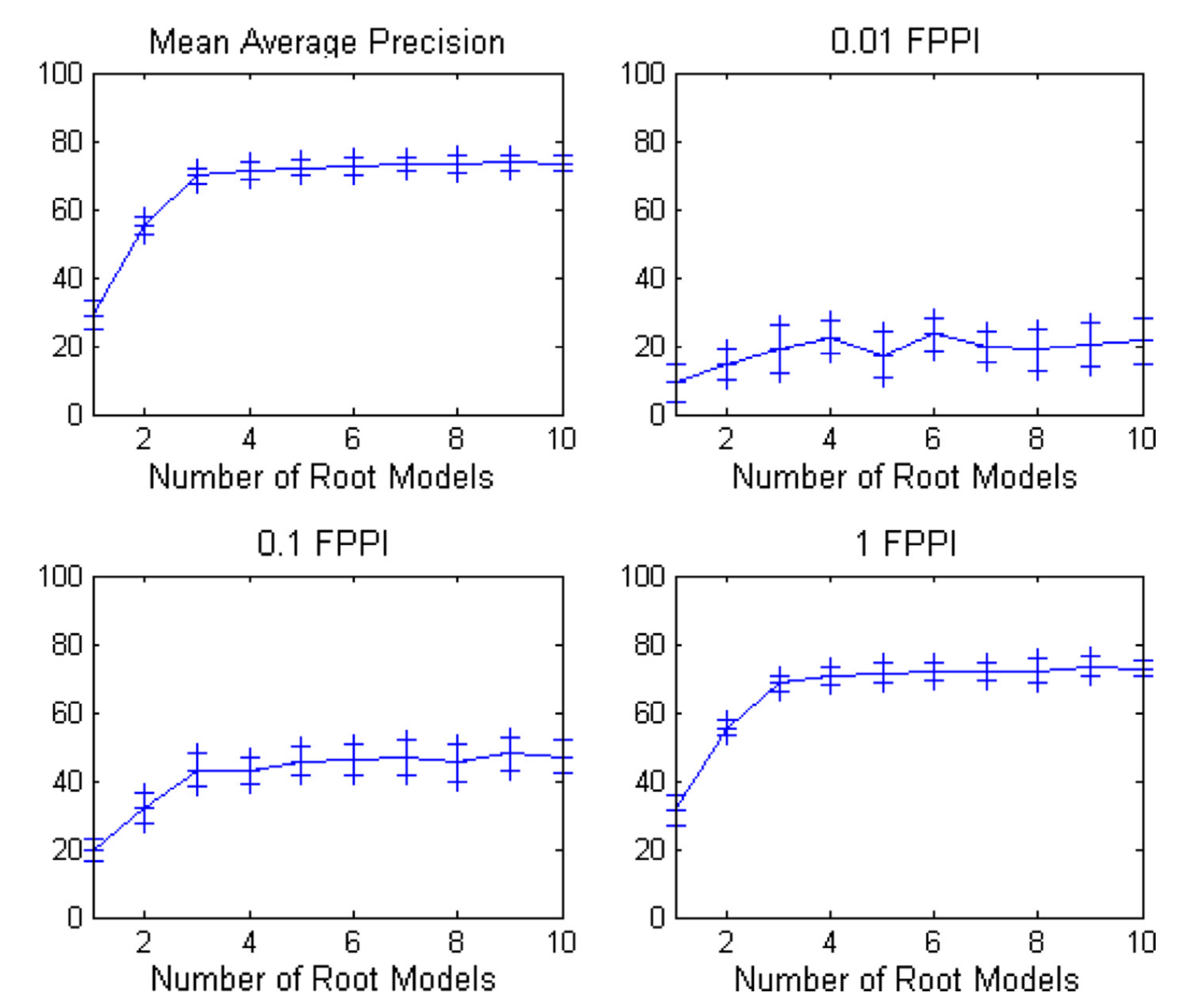
5.2.3.1 根模型数量。模型的根数量对获得良好性能至关重要,这实际上是影响最显著的参数。初步实验表明,至少需要四个根才能实现优良性能(参见图7)。由于目标长宽比会因车辆可能朝向和外观的多样性而产生极大差异,因此需要配置具有不同长宽比的多个根模型。对于可变形部件模型(DPM),在根模型基础上添加部件可略微提升性能,但会导致代码极不稳定(我们认为当根模型尺寸过小时,部件尺寸会低于临界阈值),最终无法输出结果。不过在代码成功运行的情况下,我们观察到其能使交叉验证集的mAP指标提升3%。该结果与Divvala等人[87]的早期研究结论一致,即根模型数量比隐式学习或可变形部件更为关键。
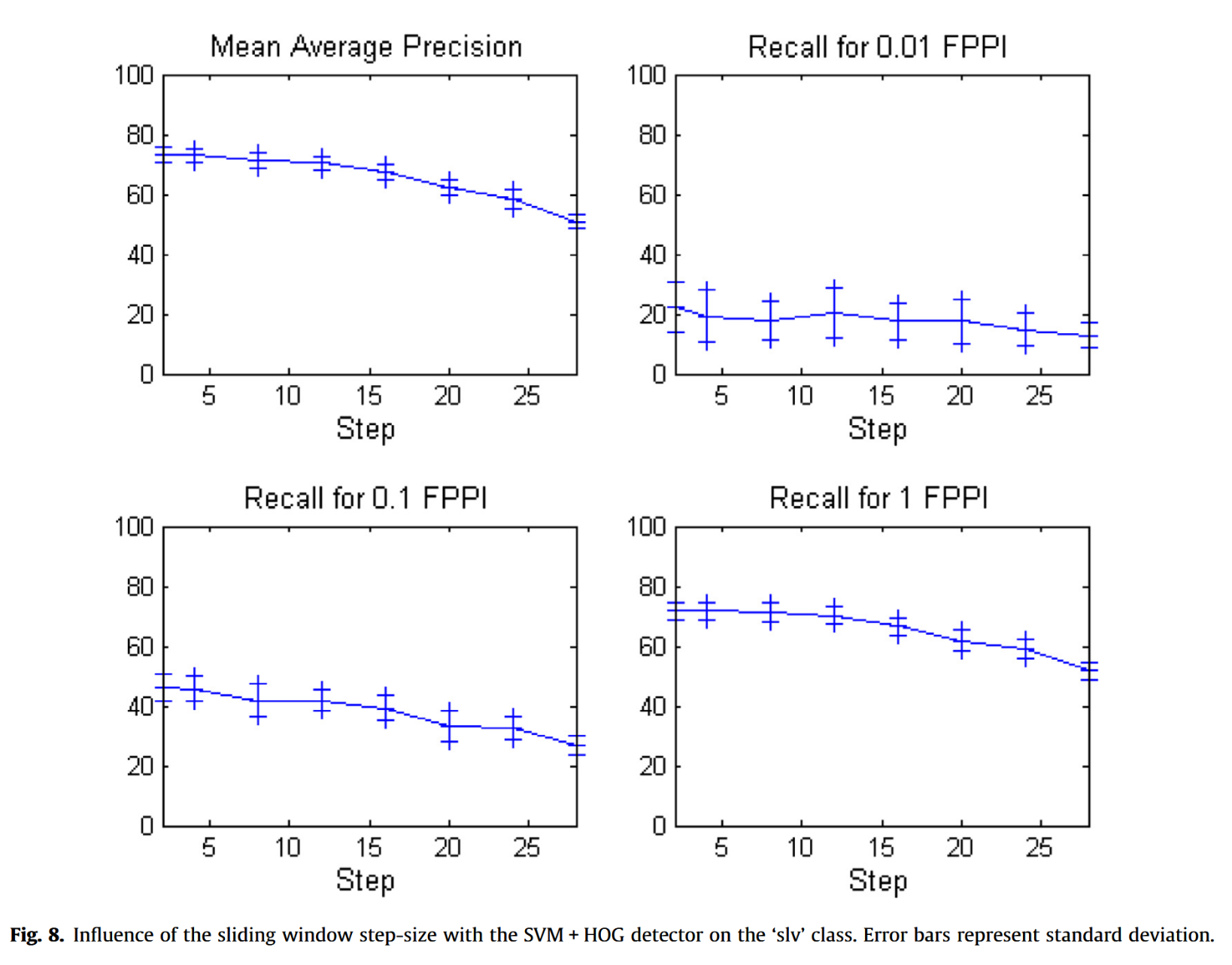
5.2.3.2. 滑动窗口参数。滑动窗口算法中的步长会影响性能。图8显示,若步长过大(超过学习阶段步长的两倍),性能会显著下降(0.01 FPPI处的召回率除外,因其本身已极低故不受影响)。当前结果为SVM+HOG检测器在’slv’类别上的表现,但其他类别及检测器也观察到类似现象。
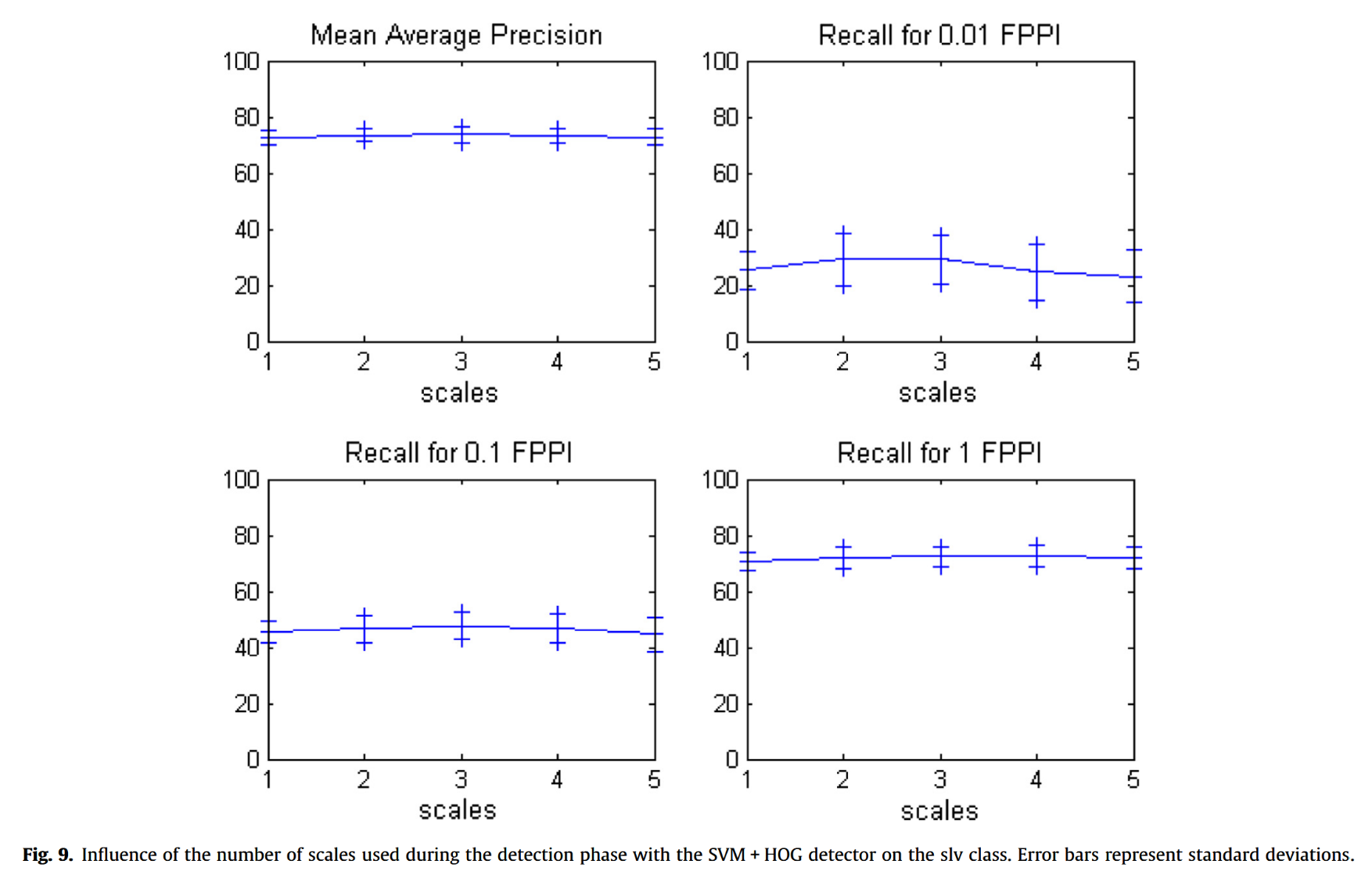
图像处理时所采用的尺度数量也会影响性能,但影响不大,如图9所示。这是预料之中的结果,因为摄像头与目标之间的距离是固定且已知的。
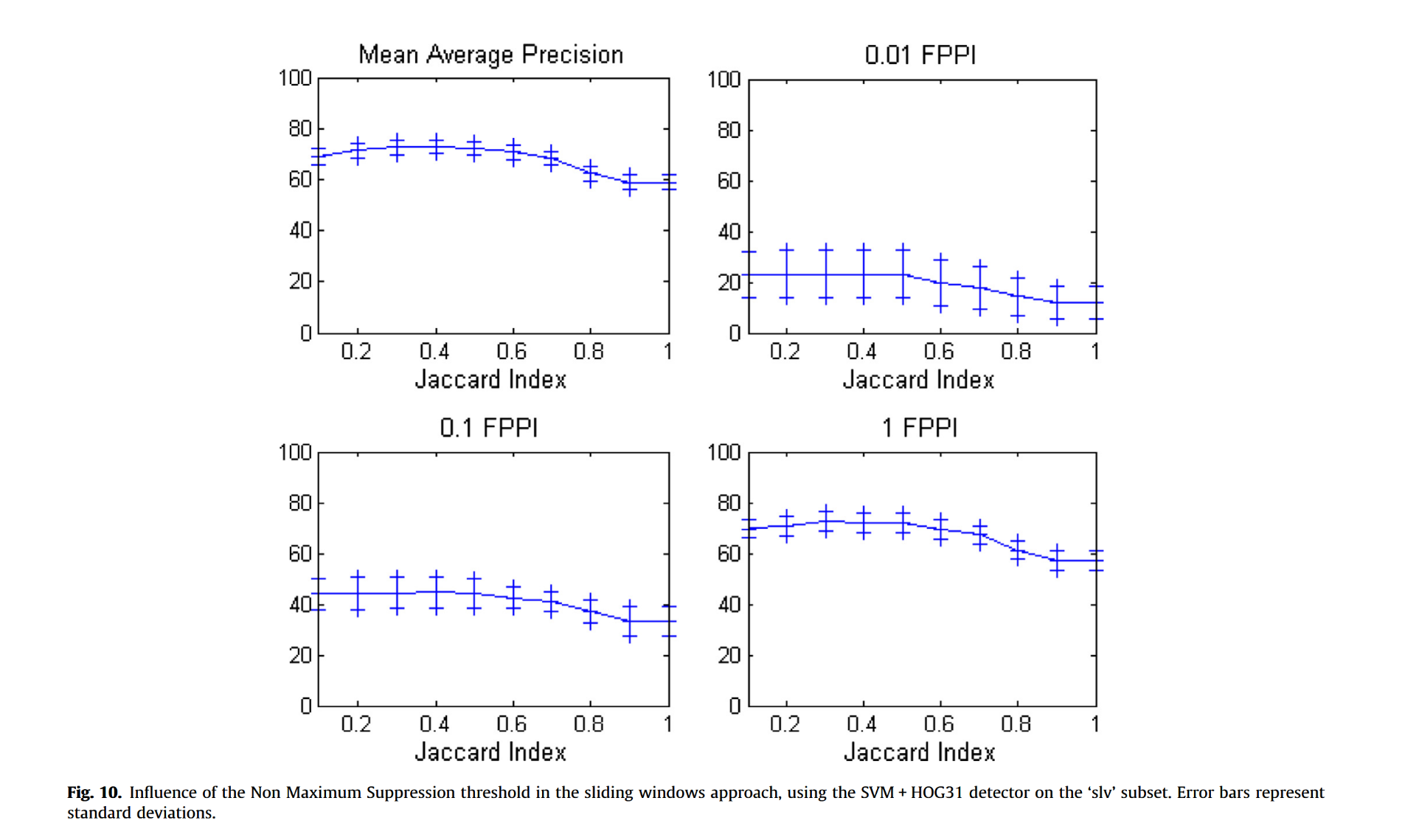
我们还测试了非极大值抑制所用阈值的影响。需注意的是,当两个检测结果过于接近(以它们之间的杰卡德指数衡量重叠程度时),仅保留最佳检测结果(即得分最高的那个)。图10显示,选择极小的杰卡德指数(如0.1)会略微降低结果。但由于目标通常彼此间距较大,检测结果很少受非极大值抑制影响。若阈值过高,非极大值抑制阶段无法充分消除重复检测,性能会下降10%。
5.2.4 进一步分析
5.2.4.1 单一类别分析。此处我们研究一种略有差异的场景:人工移除所有不属于待评估检测器类别的目标。实际操作中,仅将背景区域的预测视为假阳性(由其他类别车辆引发的检测直接舍弃,既不记为真阳性也不计数)。
表8显示,在此情况下性能仅有小幅提升。唯一显著的改进在于轿车与皮卡之间的误判减少。这表明大部分误检确实源于背景区域而非其他类别的车辆,这是由于图像中复杂背景区域占据最大比例所致。
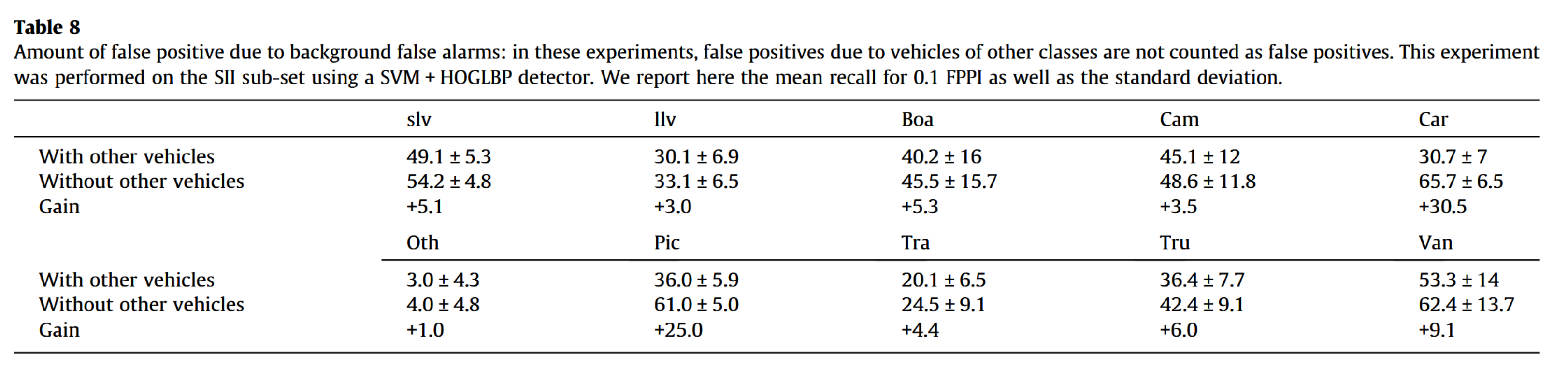
5.2.4.2 检测精度
以下实验旨在评估检测的准确性。需注意:当检测框中心落在由车辆像素尺寸规定的椭圆区域内时,该检测记为真阳性。阈值为1.0时,椭圆恰好与车辆边缘重合。通过图11可观察到不同阈值设定对性能的影响。性能表现相对稳定,说明:(i) 检测结果较为精确;(ii) 度量定义中的阈值取值合理,其选择不具有关键性。
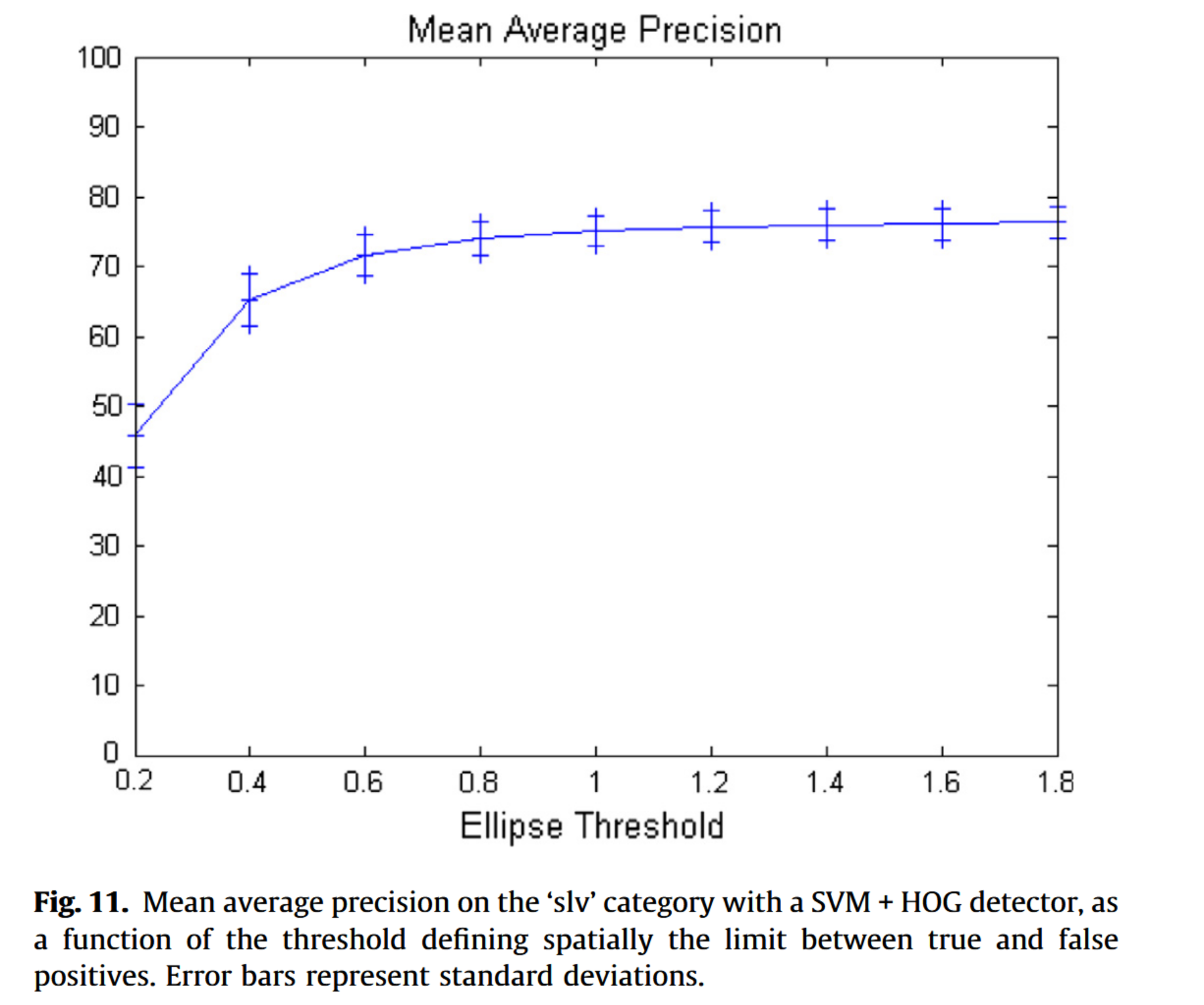
图11. 采用SVM+HOG检测器在’slv’类别上的平均精度均值,作为定义真阳性与假阳性空间分界阈值的函数。误差条表示标准偏差。
5.2.4.3 对小位移的不变性
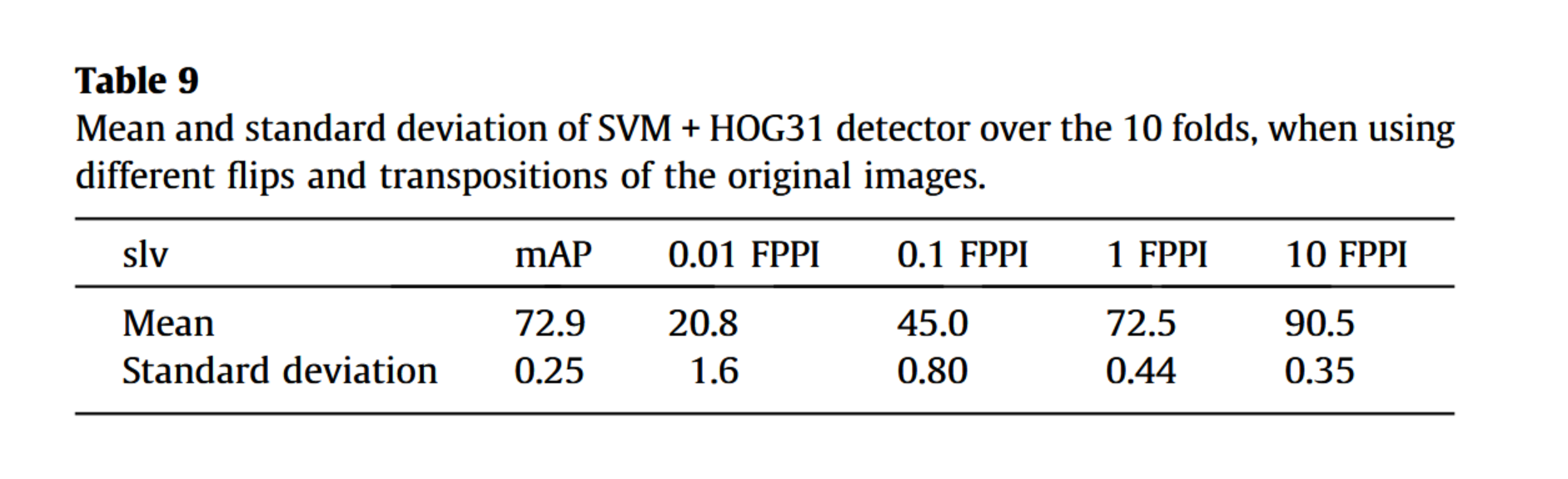
为测量基准对小目标位移的不变性,我们通过水平翻转、垂直翻转及双向翻转原始图像,生成六种数据集变体。对转置图像同样施加这些变换。此举旨在使目标相对于滑动窗口位置发生偏移(需注意滑动窗口步长为8像素),同时目标朝向也将改变。我们在’slv’类别上运行SVM+HOG31算法,并测量这7个子集(原始集加6个人工生成集)的性能标准差。如表9所示,该标准差小于折间差异,表明检测器对小目标位移具有相对不变性。
6.总结
本文介绍了VEDAI(航空影像车辆检测)这一新型数据库,用于评估航拍图像中小型车辆的检测性能。该数据集包含多种车辆类别,共计1200余幅图像中标注的3700多个目标。图像按两种尺寸(1024×1024和512×512)及彩色或红外光谱分为四类,背景与目标均具有多样性。本数据集提供明确定义的图像划分标准与评估指标,确保可靠性,其图像数据及标注均公开可用。
除数据集外,我们还对不同最先进的检测器进行了实验与评估。这些实验的主要结论是:所有检测器在该数据集。例如,在“汽车”类别上的最佳结果为召回率13.4±6.8(0.01FPPI时),显然低于目标应用的需求。我们希望该数据集能够促进开发出全新且更高效的目标检测算法。
7.引用文献
- [1] T. Wong, Atr applications in military missions, in: IEEE Symposium on Computational Intelligence in Security and Defense Applications, 2007, pp. 30–32.
- [2] B. Bhanu, Automatic target recognition: state of the art survey, IEEE Trans. Aerosp. Electron. Syst. 22 (1986) 364–379.
- [3] P. Viola, M.J. Jones, Robust real time face detection, 2004, pp. 137–154.
- [4] N. Dalal, B. Triggs, Histograms of oriented gradients for human detection, in: IEEE Conference on Computer Vision and Pattern Recognition, 2005, pp. 886893.
- [5] G. Csurka, C. Dance, L. Fan, J. Willamowski, C. Bray, Visual categorization with bags of keypoints, in: European Conference on Computer Vision, 2004, p. 22.
- [6] H. Harzallah, F. Jurie, C. Schmid, Combining efficient object localization and image classification, in: International Conference on Computer Vision, 2009, pp. 237–244.
- [7] P. Felzenszwalb, R. Girshick, D. Mcallester, D. Ramanan, Object detection with discriminatively trained part based models, IEEE Trans. Pattern Anal. Mach. Intell. 32 (2009) 1627–1645.
- [8] M. Everingham, L.V. Gool, C.K.I. Williams, J. Winn, A. Zisserman, The pascal VOC challenge, Int. J. Comput. Vision 88 (2010) 303–338.
- [9] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, L. Fei-Fei, Imagenet: a large-scale hierarchical image database, in: IEEE Conference on Computer Vision and Pattern Recognition, 2009, pp. 248–255.
- [10] B.C. Russell, A. Torralba, K.P. Murphy, W.T. Freeman, Labelme: a database and web-based tool for image annotation, Int. J. Comput. Vision 77 (2008) 157173.
- [11] Q.V. Le, Building high-level features using large scale unsupervised learning, in: ICASSP, IEEE, 2013, pp. 8595–8598.
- [12] S. Munder, An experiment study on pedestrian classification, vol. 28, 2006.
- [13] Y. LeCun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based learning applied to document recognition, Proc. IEEE 86 (1998) 2278–2324.
- [14] A. Torralba, R. Fergus, W.T. Freeman, 80 million tiny images: a large data set for nonparametric object and scene recognition, IEEE Trans. Pattern Anal. Mach. Intell. 30 (2008) 1958–1970.
- [15] P.J. Phillips, H. Wechsler, J. Huang, P.J. Rauss, The FERET database and evaluation procedure for face recognition algorithms, Image Vis. Comput. 16 (1998) 295–306.
- [16] F.S. Samaria, A.C. Harter, Parameterisation of a stochastic model for human face identification, in: IEEE Workshop on Applications of Computer Vision, 1994, pp. 138–142.
- [17] C. Papageorgiou, T. Poggio, A trainable system for object detection, Int. J. Comput. Vision 38 (2000) 15–33.
- [18] P. Dollár, C. Wojek, B. Schiele, P. Perona, Pedestrian detection: a benchmark, in: IEEE Conference on Computer Vision and Pattern Recognition, 2009, pp. 304311.
- [19] H.A. Rowley, S. Baluja, T. Kanade, Neural network-based face detection, IEEE Trans. Pattern Anal. Mach. Intell. 20 (1998) 23–38.
- [20] K.-K. Sung, T. Poggio, Example-based learning for view-based human face detection, IEEE Trans. Pattern Anal. Mach. Intell. 20 (1998) 39–51.
- [21] E. Hjelmås, B.K. Low, Face detection: a survey, Comput. Vision Image Understand. 83 (2001) 236–274.
- [22] A. Loui, C. Judice, S.S. Liu, An image database for benchmarking of automatic face detection and recognition algorithms, in: ICIP, 1998, pp. 146–150
- [23] V. Jain, E. Learned-Miller, Fddb: a benchmark for face detection in unconstrained settings, Tech. Rep. UM-CS-2010-009, University of Massachusetts, Amherst, 2010.
- [24] T.L. Berg, A.C. Berg, J. Edwards, D.A. Forsyth, Who’s in the picture, Adv. Neural Inform. Process. Syst. 17 (2005) 137–144.
- [25] V. Ferrari, T. Tuytelaars, L. Van Gool, Object detection by contour segment networks, in: European Conference on Computer Vision, 2006, pp. 14–28.
- [26] F. Tanner, B. Colder, C. Pullen, D. Heagy, M. Eppolito, V. Carlan, C. Oertel, P. Sallee, Overhead imagery research data set: an annotated data library and tools to aid in the development of computer vision algorithms, in: Proceedings of IEEE Applied Imagery Pattern Recognition Workshop, 2009, pp. 1–8.
- [27] A. Torralba, A.A. Efros, Unbiased look at dataset bias, in: IEEE Conference on Computer Vision and Pattern Recognition, IEEE, 2011, pp. 1521–1528.
- [28] J. Ponce, T.L. Berg, M. Everingham, D.A. Forsyth, M. Hebert, S. Lazebnik, M. Marszalek, C. Schmid, B.C. Russell, A. Torralba, et al., Dataset issues in object recognition, in: Toward Category-level Object Recognition, Springer, 2006, pp. 29–48.
- [29] P. Carbonetto, G. Dorkó, C. Schmid, H. Kück, N. De Freitas, Learning to recognize objects with little supervision, Int. J. Comput. Vision 77 (2008) 219–237.
- [30] J. Gleason, A.V. Nefian, X. Bouyssounousse, T. Fong, G. Bebis, Vehicle detection from aerial imagery, in: IEEE International Conference on Robotics and Automation, 2011, pp. 2065–2070.
- [31] U. Stilla, E. Michaelsen, U. Soergel, S. Hinz, H. Ender, Airborne monitoring of vehicle activity in urban areas, Int. Arch. Photogramm. Remote Sens. 35 (2004) 973–979.
- [32] website, http://www.ipf.kit.edu/english/downloads_707.php.
- [33] A. Kembhavi, D. Harwood, L.S. Davis, Vehicle detection using partial least squares, IEEE Trans. Pattern Anal. Mach. Intell. 33 (2011) 1250–1265.
- [34] C. Diegert, A combinatorial method for tracing objects using semantics of their shape, in: 2010 IEEE 39th Applied Imagery Pattern Recognition Workshop (AIPR), IEEE, 2010, pp. 1–4.
- [35] J. Ponce, M. Hebert, C. Schmid, A. Zisserman, Toward Category-Level Object Recognition, Springer, 2006.
- [36] J. Davis, M. Goadrich, The relationship between precision-recall and ROC curves, in: International Conference on Machine Learning, 2006, pp. 233–240.
- [37] L. Lusted, Signal detectability and medical decision-making, Science (1971) 1217–1219.
- [38] O. Tuzel, F. Porikli, P. Meer, Region covariance: a fast descriptor for detection and classification, in: European Conference on Computer Vision, 2006, pp. 589–600.
- [39] V. Raghavan, P. Bollmann, G.S. Jung, A critical investigation of recall and precision as measures of retrieval system performance, ACM Trans. Inform. Syst. (1989) 205–229.
- [40] C. Gu, P.A. Arbelez, Y. Lin, K. Yu, J. Malik, Multi-component models for object detection, in: European Conference on Computer Vision, 2012, pp. 445–458.
- [41] K.E.A. van de Sande, J.R.R. Uijlings, T. Gevers, A.W.M. Smeulders, Segmentation as selective search for object recognition, in: International Conference on Computer Vision, 2011, pp. 1879–1886.
- [42] M. Pedersoli, A. Vedaldi, J. Gonzlez, A coarse-to-fine approach for fast deformable object detection, in: IEEE Conference on Computer Vision and Pattern Recognition, 2011, pp. 1353–1360.
- [43] P.F. Felzenszwalb, R.B. Girshick, D.A. McAllester, Cascade object detection with deformable part models, in: IEEE Conference on Computer Vision and Pattern Recognition, 2010, pp. 2241–2248.
- [44] C.D. Manning, P. Raghavan, H. Schütze, Introduction to Information Retrieval, Cambridge University Press, Cambridge, 2008.
- [45] G. Liu, R.M. Haralick, Optimal matching problem in detection and recognition performance evaluation, Pattern Recogn. 35 (10) (2002) 2125–2139.
- [46] X. Jiang, C. Marti, C. Irniger, H. Bunke, Distance measures for image segmentation evaluation, EURASIP J. Appl. Signal Process. 2006 (2006) 1–10, http://dx.doi.org/10.1155/ASP/2006/35909. Article ID 35909.
- [47] A. Hoover, G. Jean-Baptiste, X. Jiang, P.J. Flynn, H. Bunke, D.B. Goldgof, K. Bowyer, D.W. Eggert, A. Fitzgibbon, R.B. Fisher, An experimental comparison of range image segmentation algorithms, vol. 18, 1996, pp. 673–689.
- [48] V.Y. Mariano, J. Min, J.-H. Park, R. Kasturi, D. Mihalcik, H. Li, D. Doermann, T. Drayer, Performance evaluation of object detection algorithms, in: IAPR International Conference on Pattern Recognition, vol. 3, 2002, pp. 965–969.
- [49] D. Hoiem, Y. Chodpathumwan, Q. Dai, Diagnosing error in object detectors, in: European Conference on Computer Vision, 2012, pp. 340–353.
- [50] P. Dollár, Z. Tu, P. Perona, S. Belongie, Integral channel features, in: British Machine Vision Conference, 2009, p. 5.
- [51] B. Wu, R. Nevatia, Detection of multiple, partially occluded humans in a single image by bayesian combination of edgelet part detectors, in: International Conference on Computer Vision, 2005, pp. 90–97.
- [52] S. Maji, A. Berg, J. Malik, Classification using intersection kernel support vector machines is efficient, in: IEEE Conference on Computer Vision and Pattern Recognition, 2008, pp. 1–8.
- [53] L. Zhu, Y. Chen, A.L. Yuille, W.T. Freeman, Latent hierarchical structural learning for object detection, in: IEEE Conference on Computer Vision and Pattern Recognition, 2010, pp. 1062–1069.
- [54] X. Wang, A discriminative deep model for pedestrian detection with occlusion handling, in: IEEE Conference on Computer Vision and Pattern Recognition, 2012, pp. 3258–3265.
- [55] W. Ouyang, X. Wang, Joint deep learning for pedestrian detection, in: International Conference on Computer Vision, IEEE, 2013, pp. 2056–2063.
- [56] A. Krizhevsky, I. Sutskever, G.E. Hinton, Imagenet classification with deep convolutional neural networks, in: Advances in Neural Information Processing Systems, 2012, pp. 1097–1105.
- [57] A. Sharif Razavian, H. Azizpour, J. Sullivan, S. Carlsson, Cnn features off-theshelf: an astounding baseline for recognition, arXiv preprint arXiv:1403.6382.
- [58] M. Oquab, L. Bottou, I. Laptev, J. Sivic, Learning and transferring mid-level image representations using convolutional neural networks, in: IEEE Conference on Computer Vision and Pattern Recognition, 2014.
- [59] P. Viola, M.J. Jones, D. Snow, Detecting pedestrians using patterns of motion and appearance, Int. J. Comput. Vision 63 (2005) 153–161.
- [60] F.M. Porikli, Integral histogram: a fast way to extract histograms in cartesian spaces, in: IEEE Conference on Computer Vision and Pattern Recognition, 2005, pp. 829–836.
- [61] P. Sabzmeydani, G. Mori, Detecting pedestrians by learning shapelet features, in: IEEE Conference on Computer Vision and Pattern Recognition, 2007, pp. 1–8.
- [62] T. Malisiewicz, A. Gupta, A.A. Efros, Ensemble of exemplar-svms for object detection and beyond, in: International Conference on Computer Vision, 2011, pp. 89–96.
- [63] C.H. Lampert, M.B. Blaschko, T. Hofmann, Beyond sliding windows: object localization by efficient subwindow search, in: IEEE Conference on Computer Vision and Pattern Recognition, 2008.
- [64] A. Bosch, A. Zisserman, X. Muoz, Representing shape with a spatial pyramid kernel, in: Conference on Image and Video Retrieval, 2007, pp. 401–408.
- [65] W.R. Schwartz, A. Kembhavi, D. Harwood, L.S. Davis, Human detection using partial least squares analysis, in: International Conference on Computer Vision, 2009, pp. 24–31.
- [66] X. Wang, T. Han, S. Yan, An hog-lbp human detector with partial occlusion handling, in: International Conference on Computer Vision, 2009, pp. 32–39.
- [67] S. Walk, N. Majer, K. Schindler, B. Schiele, New features and insights for pedestrian detection., in: IEEE Conference on Computer Vision and Pattern Recognition, 2010, pp. 1030–1037.
- [68] M. Enzweiler, D. Gavrila, Monocular pedestrian detection: Survey and experiments, IEEE Trans. Pattern Anal. Mach. Intell. 31 (2009) 2179–2195.
- [69] P.F. Felzenszwalb, D.P. Huttenlocher, Pictorial structures for object recognition, Int. J. Comput. Vision 61 (2005) 55–79.
- [70] L.D. Bourdev, J. Malik, Poselets: body part detectors trained using 3d human pose annotations, in: International Conference on Computer Vision, 2009, pp. 1365–1372.
- [71] Y. Yang, D. Ramanan, Articulated pose estimation with flexible mixtures-ofparts, in: IEEE Conference on Computer Vision and Pattern Recognition, 2011, pp. 1385–1392.
- [72] A. Vedaldi, V. Gulshan, M. Varma, A. Zisserman, Multiple kernels for object detection, in: International Conference on Computer Vision, 2009, pp. 606613.
- [73] B. Alexe, T. Deselaers, V. Ferrari, What is an object?, in: IEEE Conference on Computer Vision and Pattern Recognition, 2010, pp. 73–80.
- [74] E. Rahtu, J. Kannala, M.B. Blaschko, Learning a category independent object detection cascade, in: International Conference on Computer Vision, 2011, pp. 1052–1059.
- [75] H.-Y. Cheng, C.-C. Weng, Y.-Y. Chen, Vehicle detection in aerial surveillance using dynamic bayesian networks, IEEE Trans. Image Process. 21 (4) (2012) 2152–2159.
- [76] website, Utah agrc website, 2012. http://gis.utah.gov/.
- [77] C.M. Bishop et al., Pattern recognition and machine learning, vol. 1, Springer, New York, 2006.
- [78] T. Ojala, M. Pietikainen, T. Maenpaa, Multiresolution gray-scale and rotation invariant texture classification with local binary patterns, IEEE Trans. Pattern Anal. Mach. Intell. 24 (2002) 971–987.
- [79] X. Tan, B. Triggs, Enhanced local texture feature sets for face recognition under difficult lighting conditions, in: Analysis and Modeling of Faces and Gestures, 2007, pp. 168–182.
- [80] R. Brunelli, Template Matching Techniques in Computer Vision: Theory and Practice, 2009.
- [81] J. Gall, V. Lempitsky, Class-specific hough forests for object detection, in: 2013 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, 2009, pp. 1022–1029.
- [82] T. Joachims, Making large-scale support vector machine learning practical, 1999. http://svmlight.joachims.org/.
- [83] L. Rousseeuw, L. Kaufman, Clustering by means of medoids, Statistical data analysis based on the L1-norm and related methods, pp. 405–416.
- [84] D. Park, D. Ramanan, C. Fowlkes, Multiresolution models for object detection, in: European Conference on Computer Vision, 2010, pp. 241–254.
- [85] J. Yan, X. Zhang, Z. Lei, S. Liao, S.Z. Li, Robust multi-resolution pedestrian detection in traffic scenes, in: IEEE Conference on Computer Vision and Pattern Recognition, vol. 1, 2013.
- [86] P. Dollar, C. Wojek, B. Schiele, P. Perona, Pedestrian detection: an evaluation of the state of the art, vol. 34, 2012, pp. 743–761.
- [87] S.K. Divvala, A.A. Efros, M. Hebert, How important are ıdeformable partsˆı in the deformable parts model?, in: European Conference on Computer Vision, 2012, pp. 31–40.