MBPO 算法:让智能体像人一样 “先模拟后实操”—强化学习(17)
目录
1、先搞懂:MBPO 到底解决什么问题?
2、MBPO 的 3 个核心思想:
2.1、 先建一个 “环境模拟器”—— 智能体的 “练习沙盘”
2.2、模拟器里 “疯狂刷题”—— 用虚拟数据练策略
2.3、 偶尔 “回归真实”—— 避免模拟器 “跑偏”
3、MBPO 工作流程:4 步让智能体 “从新手到高手”
4、MBPO 为什么 “厉害”?3 个核心优势
4.1、数据效率超高:
4.2、安全性更好:
4.3、适应能力强:
5、MBPO 的 “小麻烦”:为什么不是万能的?
5.1、模拟器不准是大问题:
5.2、计算量更大:
6、完整代码
7、实验结果
1、先搞懂:MBPO 到底解决什么问题?
想象你在学开汽车 ——
- 新手阶段:你得在真实马路上练(对应 “无模型强化学习”,比如 PPO),但撞一次车成本太高,还危险;
- 聪明的做法:先在驾驶模拟器里练熟操作(对应 “基于模型”),再上真实马路微调 ——MBPO 算法就像这个 “先模拟后实操” 的过程,让智能体(比如机器人、游戏 AI)用更少的真实试错学会复杂任务。
核心目标:解决传统强化学习 “试错成本高、数据效率低” 的问题。比如训练机械臂抓东西,无模型算法可能要摔碎 1000 次杯子才学会,而 MBPO 靠 “虚拟模拟”,摔 100 次就能熟练。
2、MBPO 的 3 个核心思想:
2.1、 先建一个 “环境模拟器”—— 智能体的 “练习沙盘”
- 作用:就像天气预报模型能预测明天的天气,MBPO 会先学一个 “环境模拟器”,输入 “当前状态 + 动作”,就能输出 “下一步状态 + 奖励”。
比如玩 “超级马里奥”,模拟器能预测:“马里奥在 (10,20) 位置跳一下,会落到 (12,15),拿到 10 分”。 - 怎么建:
智能体先在真实环境里随便试几次(比如马里奥乱走几步),记录 “状态→动作→下一步状态→奖励” 的数据,用这些数据训练一个神经网络当模拟器。 - 关键:这个模拟器不需要 100% 准确,差不多就行 —— 就像人练车的模拟器,不用和真车完全一样,能练出操作感觉就够。
2.2、模拟器里 “疯狂刷题”—— 用虚拟数据练策略
有了模拟器,智能体就可以在里面 “开挂练习”:
- 比如训练机器人走路:
真实环境中走 10 步要花 10 分钟(还可能摔倒),但在模拟器里,1 分钟能虚拟走 1000 步,快速积累 “走稳” 的经验。 - 具体操作:
智能体用当前的 “走路策略” 在模拟器里跑,生成大量 “虚拟数据”(比如 “左腿迈大→差点摔→调整右腿”),用这些数据优化策略 —— 就像你在模拟器里练会 “转弯带刹车”,再上真车就熟练多了。
2.3、 偶尔 “回归真实”—— 避免模拟器 “跑偏”
模拟器再准,也和真实环境有差距(比如模拟器里地面摩擦力设小了,真实地面更滑)。如果一直只在模拟器里练,智能体可能会练出 “模拟器特有的怪招”(比如在虚拟中靠打滑加速,真实中就会摔)。
MBPO 的解决办法很简单:
- 定期 “抽查”:每练一段时间,就去真实环境走几步,收集最新的真实数据。
- 混合学习:把 “模拟器练出来的经验” 和 “真实环境的反馈” 混在一起优化策略,既保证效率,又不脱离现实 —— 就像你在模拟器练完,必须上真实马路跑两圈,才能真学会开车。
3、MBPO 工作流程:4 步让智能体 “从新手到高手”
用 “训练机械臂抓杯子” 举例子,一步步看 MBPO 怎么工作:
| 步骤 | 具体操作(机械臂案例) | 类比人类学习过程 |
|---|---|---|
| 1. 收集 “入门经验” | 机械臂随便动(随机策略),记录 “当前位置 + 夹爪力度→杯子是否被抓住→奖励多少”,存到 “经验库”。 | 婴儿乱挥手臂,感受 “碰到东西” 的反馈 |
| 2. 训练 “虚拟练习室”(环境模型) | 用经验库的数据训练模拟器:输入 “机械臂位置 + 力度”,模拟器能预测 “杯子会被推到哪 + 能不能抓住”。 | 小孩玩积木时,慢慢 “心里有数”:“用力推,积木会倒” |
| 3. 模拟器里 “疯狂刷题” | 机械臂用当前策略在模拟器里虚拟抓杯子 1000 次,生成大量 “虚拟经验”(比如 “力度 5N 时杯子会滑,8N 能抓住”)。 | 棋手在脑子里 “模拟” 多种走法,找出最优解 |
| 4. 结合真实反馈优化策略 | ① 去真实环境抓 3 次杯子,更新真实经验;② 把 1000 条虚拟经验 + 3 条真实经验混在一起,优化机械臂的 “抓握策略”(比如调整力度和角度)。 | 学生先做模拟题,再根据老师批改的真实试卷改错题 |
循环重复:每优化一次策略,就用新策略再去模拟器和真实环境收集数据,直到机械臂能稳稳抓住杯子 —— 整个过程中,真实试错可能只有几十次,远少于无模型算法的几千次。
4、MBPO 为什么 “厉害”?3 个核心优势
4.1、数据效率超高:
无模型算法(如 PPO)要 10000 次真实试错才能学会的任务,MBPO 靠模拟器可能只要 1000 次,尤其适合 “真实试错成本高” 的场景(比如训练自动驾驶,总不能天天撞车吧?)。
4.2、安全性更好:
危险动作(比如机械臂用力过猛可能折断)可以在模拟器里先排除,真实环境中几乎不会出现 “致命错误”—— 就像拆弹专家,肯定先在模拟器里练熟流程,再碰真炸弹。
4.3、适应能力强:
当环境轻微变化(比如杯子换成盘子),MBPO 不用重新学:先在模拟器里快速适应 “盘子更滑” 的特性,再去真实环境微调,比无模型算法 “重新学一遍” 快得多。
5、MBPO 的 “小麻烦”:为什么不是万能的?
5.1、模拟器不准是大问题:
如果模拟器预测错了(比如实际杯子是塑料的,模拟器当成玻璃的),智能体可能练出 “错误策略”(比如用太大劲捏碎塑料杯)。这就像用 “赛车模拟器” 学开卡车,练得再好也可能翻车。
5.2、计算量更大:
既要训练模拟器,又要在模拟器里生成虚拟数据,对电脑性能有要求 —— 就像你玩高画质游戏模拟器,电脑配置得够高才行。
6、完整代码
import gym
from collections import namedtuple
import itertools
from itertools import count
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.distributions.normal import Normal
import numpy as np
import collections
import random
import matplotlib.pyplot as plt
class PolicyNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_dim, action_bound):super(PolicyNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc_mu = torch.nn.Linear(hidden_dim, action_dim)self.fc_std = torch.nn.Linear(hidden_dim, action_dim)self.action_bound = action_bounddef forward(self, x):x = F.relu(self.fc1(x))mu = self.fc_mu(x)std = F.softplus(self.fc_std(x))dist = Normal(mu, std)normal_sample = dist.rsample() # rsample()是重参数化采样函数log_prob = dist.log_prob(normal_sample)action = torch.tanh(normal_sample) # 计算tanh_normal分布的对数概率密度log_prob = log_prob - torch.log(1 - torch.tanh(action).pow(2) + 1e-7)action = action * self.action_boundreturn action, log_probclass QValueNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_dim):super(QValueNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim + action_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, 1)def forward(self, x, a):cat = torch.cat([x, a], dim=1) # 拼接状态和动作x = F.relu(self.fc1(cat))return self.fc2(x)device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")class SAC:''' 处理连续动作的SAC算法 '''def __init__(self, state_dim, hidden_dim, action_dim, action_bound,actor_lr, critic_lr, alpha_lr, target_entropy, tau, gamma):self.actor = PolicyNet(state_dim, hidden_dim, action_dim,action_bound).to(device) # 策略网络# 第一个Q网络self.critic_1 = QValueNet(state_dim, hidden_dim, action_dim).to(device)# 第二个Q网络self.critic_2 = QValueNet(state_dim, hidden_dim, action_dim).to(device)self.target_critic_1 = QValueNet(state_dim, hidden_dim,action_dim).to(device) # 第一个目标Q网络self.target_critic_2 = QValueNet(state_dim, hidden_dim,action_dim).to(device) # 第二个目标Q网络# 令目标Q网络的初始参数和Q网络一样self.target_critic_1.load_state_dict(self.critic_1.state_dict())self.target_critic_2.load_state_dict(self.critic_2.state_dict())self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),lr=actor_lr)self.critic_1_optimizer = torch.optim.Adam(self.critic_1.parameters(),lr=critic_lr)self.critic_2_optimizer = torch.optim.Adam(self.critic_2.parameters(),lr=critic_lr)# 使用alpha的log值,可以使训练结果比较稳定self.log_alpha = torch.tensor(np.log(0.01), dtype=torch.float)self.log_alpha.requires_grad = True # 可以对alpha求梯度self.log_alpha_optimizer = torch.optim.Adam([self.log_alpha],lr=alpha_lr)self.target_entropy = target_entropy # 目标熵的大小self.gamma = gammaself.tau = taudef take_action(self, state):state = torch.tensor([state], dtype=torch.float).to(device)action = self.actor(state)[0]return [action.item()]def calc_target(self, rewards, next_states, dones): # 计算目标Q值next_actions, log_prob = self.actor(next_states)entropy = -log_probq1_value = self.target_critic_1(next_states, next_actions)q2_value = self.target_critic_2(next_states, next_actions)next_value = torch.min(q1_value,q2_value) + self.log_alpha.exp() * entropytd_target = rewards + self.gamma * next_value * (1 - dones)return td_targetdef soft_update(self, net, target_net):for param_target, param in zip(target_net.parameters(),net.parameters()):param_target.data.copy_(param_target.data * (1.0 - self.tau) +param.data * self.tau)def update(self, transition_dict):states = torch.tensor(transition_dict['states'],dtype=torch.float).to(device)actions = torch.tensor(transition_dict['actions'],dtype=torch.float).view(-1, 1).to(device)rewards = torch.tensor(transition_dict['rewards'],dtype=torch.float).view(-1, 1).to(device)next_states = torch.tensor(transition_dict['next_states'],dtype=torch.float).to(device)dones = torch.tensor(transition_dict['dones'],dtype=torch.float).view(-1, 1).to(device)rewards = (rewards + 8.0) / 8.0 # 对倒立摆环境的奖励进行重塑# 更新两个Q网络td_target = self.calc_target(rewards, next_states, dones)critic_1_loss = torch.mean(F.mse_loss(self.critic_1(states, actions), td_target.detach()))critic_2_loss = torch.mean(F.mse_loss(self.critic_2(states, actions), td_target.detach()))self.critic_1_optimizer.zero_grad()critic_1_loss.backward()self.critic_1_optimizer.step()self.critic_2_optimizer.zero_grad()critic_2_loss.backward()self.critic_2_optimizer.step()# 更新策略网络new_actions, log_prob = self.actor(states)entropy = -log_probq1_value = self.critic_1(states, new_actions)q2_value = self.critic_2(states, new_actions)actor_loss = torch.mean(-self.log_alpha.exp() * entropy -torch.min(q1_value, q2_value))self.actor_optimizer.zero_grad()actor_loss.backward()self.actor_optimizer.step()# 更新alpha值alpha_loss = torch.mean((entropy - target_entropy).detach() * self.log_alpha.exp())self.log_alpha_optimizer.zero_grad()alpha_loss.backward()self.log_alpha_optimizer.step()self.soft_update(self.critic_1, self.target_critic_1)self.soft_update(self.critic_2, self.target_critic_2)
class Swish(nn.Module):''' Swish激活函数 '''def __init__(self):super(Swish, self).__init__()def forward(self, x):return x * torch.sigmoid(x)def init_weights(m):''' 初始化模型权重 '''def truncated_normal_init(t, mean=0.0, std=0.01):torch.nn.init.normal_(t, mean=mean, std=std)while True:cond = (t < mean - 2 * std) | (t > mean + 2 * std)if not torch.sum(cond):breakt = torch.where(cond,torch.nn.init.normal_(torch.ones(t.shape, device=device),mean=mean,std=std), t)return tif type(m) == nn.Linear or isinstance(m, FCLayer):truncated_normal_init(m.weight, std=1 / (2 * np.sqrt(m._input_dim)))m.bias.data.fill_(0.0)class FCLayer(nn.Module):''' 集成之后的全连接层 '''def __init__(self, input_dim, output_dim, ensemble_size, activation):super(FCLayer, self).__init__()self._input_dim, self._output_dim = input_dim, output_dimself.weight = nn.Parameter(torch.Tensor(ensemble_size, input_dim, output_dim).to(device))self._activation = activationself.bias = nn.Parameter(torch.Tensor(ensemble_size, output_dim).to(device))def forward(self, x):return self._activation(torch.add(torch.bmm(x, self.weight), self.bias[:, None, :]))
class EnsembleModel(nn.Module):''' 环境模型集成 '''def __init__(self,state_dim,action_dim,model_alpha,ensemble_size=5,learning_rate=1e-3):super(EnsembleModel, self).__init__()# 输出包括均值和方差,因此是状态与奖励维度之和的两倍self._output_dim = (state_dim + 1) * 2self._model_alpha = model_alpha # 模型损失函数中加权时的权重self._max_logvar = nn.Parameter((torch.ones((1, self._output_dim // 2)).float() / 2).to(device),requires_grad=False)self._min_logvar = nn.Parameter((-torch.ones((1, self._output_dim // 2)).float() * 10).to(device),requires_grad=False)self.layer1 = FCLayer(state_dim + action_dim, 200, ensemble_size,Swish())self.layer2 = FCLayer(200, 200, ensemble_size, Swish())self.layer3 = FCLayer(200, 200, ensemble_size, Swish())self.layer4 = FCLayer(200, 200, ensemble_size, Swish())self.layer5 = FCLayer(200, self._output_dim, ensemble_size,nn.Identity())self.apply(init_weights) # 初始化环境模型中的参数self.optimizer = torch.optim.Adam(self.parameters(), lr=learning_rate)def forward(self, x, return_log_var=False):ret = self.layer5(self.layer4(self.layer3(self.layer2(self.layer1(x)))))mean = ret[:, :, :self._output_dim // 2]# 在PETS算法中,将方差控制在最小值和最大值之间logvar = self._max_logvar - F.softplus(self._max_logvar - ret[:, :, self._output_dim // 2:])logvar = self._min_logvar + F.softplus(logvar - self._min_logvar)return mean, logvar if return_log_var else torch.exp(logvar)def loss(self, mean, logvar, labels, use_var_loss=True):inverse_var = torch.exp(-logvar)if use_var_loss:mse_loss = torch.mean(torch.mean(torch.pow(mean - labels, 2) *inverse_var,dim=-1),dim=-1)var_loss = torch.mean(torch.mean(logvar, dim=-1), dim=-1)total_loss = torch.sum(mse_loss) + torch.sum(var_loss)else:mse_loss = torch.mean(torch.pow(mean - labels, 2), dim=(1, 2))total_loss = torch.sum(mse_loss)return total_loss, mse_lossdef train(self, loss):self.optimizer.zero_grad()loss += self._model_alpha * torch.sum(self._max_logvar) - self._model_alpha * torch.sum(self._min_logvar)loss.backward()self.optimizer.step()class EnsembleDynamicsModel:''' 环境模型集成,加入精细化的训练 '''def __init__(self, state_dim, action_dim, model_alpha=0.01, num_network=5):self._num_network = num_networkself._state_dim, self._action_dim = state_dim, action_dimself.model = EnsembleModel(state_dim,action_dim,model_alpha,ensemble_size=num_network)self._epoch_since_last_update = 0def train(self,inputs,labels,batch_size=64,holdout_ratio=0.1,max_iter=20):# 设置训练集与验证集permutation = np.random.permutation(inputs.shape[0])inputs, labels = inputs[permutation], labels[permutation]num_holdout = int(inputs.shape[0] * holdout_ratio)train_inputs, train_labels = inputs[num_holdout:], labels[num_holdout:]holdout_inputs, holdout_labels = inputs[:num_holdout], labels[:num_holdout]holdout_inputs = torch.from_numpy(holdout_inputs).float().to(device)holdout_labels = torch.from_numpy(holdout_labels).float().to(device)holdout_inputs = holdout_inputs[None, :, :].repeat([self._num_network, 1, 1])holdout_labels = holdout_labels[None, :, :].repeat([self._num_network, 1, 1])# 保留最好的结果self._snapshots = {i: (None, 1e10) for i in range(self._num_network)}for epoch in itertools.count():# 定义每一个网络的训练数据train_index = np.vstack([np.random.permutation(train_inputs.shape[0])for _ in range(self._num_network)])# 所有真实数据都用来训练for batch_start_pos in range(0, train_inputs.shape[0], batch_size):batch_index = train_index[:, batch_start_pos:batch_start_pos +batch_size]train_input = torch.from_numpy(train_inputs[batch_index]).float().to(device)train_label = torch.from_numpy(train_labels[batch_index]).float().to(device)mean, logvar = self.model(train_input, return_log_var=True)loss, _ = self.model.loss(mean, logvar, train_label)self.model.train(loss)with torch.no_grad():mean, logvar = self.model(holdout_inputs, return_log_var=True)_, holdout_losses = self.model.loss(mean,logvar,holdout_labels,use_var_loss=False)holdout_losses = holdout_losses.cpu()break_condition = self._save_best(epoch, holdout_losses)if break_condition or epoch > max_iter: # 结束训练breakdef _save_best(self, epoch, losses, threshold=0.1):updated = Falsefor i in range(len(losses)):current = losses[i]_, best = self._snapshots[i]improvement = (best - current) / bestif improvement > threshold:self._snapshots[i] = (epoch, current)updated = Trueself._epoch_since_last_update = 0 if updated else self._epoch_since_last_update + 1return self._epoch_since_last_update > 5def predict(self, inputs, batch_size=64):inputs = np.tile(inputs, (self._num_network, 1, 1))inputs = torch.tensor(inputs, dtype=torch.float).to(device)mean, var = self.model(inputs, return_log_var=False)return mean.detach().cpu().numpy(), var.detach().cpu().numpy()class FakeEnv:def __init__(self, model):self.model = modeldef step(self, obs, act):inputs = np.concatenate((obs, act), axis=-1)ensemble_model_means, ensemble_model_vars = self.model.predict(inputs)ensemble_model_means[:, :, 1:] += obsensemble_model_stds = np.sqrt(ensemble_model_vars)ensemble_samples = ensemble_model_means + np.random.normal(size=ensemble_model_means.shape) * ensemble_model_stdsnum_models, batch_size, _ = ensemble_model_means.shapemodels_to_use = np.random.choice([i for i in range(self.model._num_network)], size=batch_size)batch_inds = np.arange(0, batch_size)samples = ensemble_samples[models_to_use, batch_inds]rewards, next_obs = samples[:, :1][0][0], samples[:, 1:][0]return rewards, next_obs
class MBPO:def __init__(self, env, agent, fake_env, env_pool, model_pool,rollout_length, rollout_batch_size, real_ratio, num_episode):self.env = envself.agent = agentself.fake_env = fake_envself.env_pool = env_poolself.model_pool = model_poolself.rollout_length = rollout_lengthself.rollout_batch_size = rollout_batch_sizeself.real_ratio = real_ratioself.num_episode = num_episodedef rollout_model(self):observations, _, _, _, _ = self.env_pool.sample(self.rollout_batch_size)for obs in observations:for i in range(self.rollout_length):action = self.agent.take_action(obs)reward, next_obs = self.fake_env.step(obs, action)self.model_pool.add(obs, action, reward, next_obs, False)obs = next_obsdef update_agent(self, policy_train_batch_size=64):env_batch_size = int(policy_train_batch_size * self.real_ratio)model_batch_size = policy_train_batch_size - env_batch_sizefor epoch in range(10):env_obs, env_action, env_reward, env_next_obs, env_done = self.env_pool.sample(env_batch_size)if self.model_pool.size() > 0:model_obs, model_action, model_reward, model_next_obs, model_done = self.model_pool.sample(model_batch_size)obs = np.concatenate((env_obs, model_obs), axis=0)action = np.concatenate((env_action, model_action), axis=0)next_obs = np.concatenate((env_next_obs, model_next_obs),axis=0)reward = np.concatenate((env_reward, model_reward), axis=0)done = np.concatenate((env_done, model_done), axis=0)else:obs, action, next_obs, reward, done = env_obs, env_action, env_next_obs, env_reward, env_donetransition_dict = {'states': obs,'actions': action,'next_states': next_obs,'rewards': reward,'dones': done}self.agent.update(transition_dict)def train_model(self):obs, action, reward, next_obs, done = self.env_pool.return_all_samples()inputs = np.concatenate((obs, action), axis=-1)reward = np.array(reward)labels = np.concatenate((np.reshape(reward, (reward.shape[0], -1)), next_obs - obs),axis=-1)self.fake_env.model.train(inputs, labels)def explore(self):obs, done, episode_return = self.env.reset(), False, 0while not done:action = self.agent.take_action(obs)next_obs, reward, done, _ = self.env.step(action)self.env_pool.add(obs, action, reward, next_obs, done)obs = next_obsepisode_return += rewardreturn episode_returndef train(self):return_list = []explore_return = self.explore() # 随机探索采取数据print('episode: 1, return: %d' % explore_return)return_list.append(explore_return)for i_episode in range(self.num_episode - 1):obs, done, episode_return = self.env.reset(), False, 0step = 0while not done:if step % 50 == 0:self.train_model()self.rollout_model()action = self.agent.take_action(obs)next_obs, reward, done, _ = self.env.step(action)self.env_pool.add(obs, action, reward, next_obs, done)obs = next_obsepisode_return += rewardself.update_agent()step += 1return_list.append(episode_return)print('episode: %d, return: %d' % (i_episode + 2, episode_return))return return_listclass ReplayBuffer:def __init__(self, capacity):self.buffer = collections.deque(maxlen=capacity)def add(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))def size(self):return len(self.buffer)def sample(self, batch_size):if batch_size > len(self.buffer):return self.return_all_samples()else:transitions = random.sample(self.buffer, batch_size)state, action, reward, next_state, done = zip(*transitions)return np.array(state), action, reward, np.array(next_state), donedef return_all_samples(self):all_transitions = list(self.buffer)state, action, reward, next_state, done = zip(*all_transitions)return np.array(state), action, reward, np.array(next_state), done# ======================== 主函数 ========================
if __name__ == "__main__":real_ratio = 0.5env_name = 'Pendulum-v0'env = gym.make(env_name)num_episodes = 20actor_lr = 5e-4critic_lr = 5e-3alpha_lr = 1e-3hidden_dim = 128gamma = 0.98tau = 0.005 # 软更新参数buffer_size = 10000target_entropy = -1model_alpha = 0.01 # 模型损失函数中的加权权重state_dim = env.observation_space.shape[0]action_dim = env.action_space.shape[0]action_bound = env.action_space.high[0] # 动作最大值rollout_batch_size = 1000rollout_length = 1 # 推演长度k,推荐更多尝试model_pool_size = rollout_batch_size * rollout_lengthagent = SAC(state_dim, hidden_dim, action_dim, action_bound, actor_lr,critic_lr, alpha_lr, target_entropy, tau, gamma)model = EnsembleDynamicsModel(state_dim, action_dim, model_alpha)fake_env = FakeEnv(model)env_pool = ReplayBuffer(buffer_size)model_pool = ReplayBuffer(model_pool_size)mbpo = MBPO(env, agent, fake_env, env_pool, model_pool, rollout_length,rollout_batch_size, real_ratio, num_episodes)return_list = mbpo.train()episodes_list = list(range(len(return_list)))plt.plot(episodes_list, return_list)plt.xlabel('Episodes')plt.ylabel('Returns')plt.title('MBPO on {}'.format(env_name))plt.show()
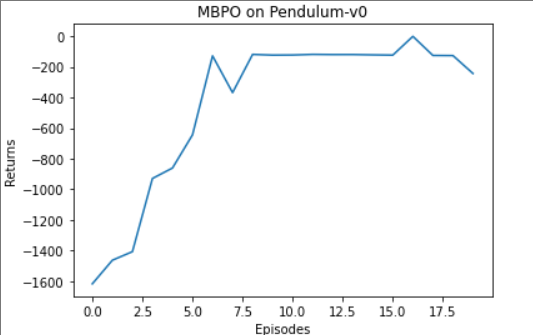
7、实验结果