Onload 用户指南 (UG1586)-笔记
tar包安装
下载:NIC 软件与驱动,选择OpenOnload,Onload-x.x.x.xxx 下载所需的 tar 文件
应将压缩的 tar 文件 (.tgz) 下载/复制到将要安装它的机器上的目录中
以 root 身份使用 tar 命令解压 tar 文件:
tar -zxvf onload-<version>.tgz
构建并安装 Onload
构建依赖项
基于 Debian 的发行版 - 包括 Ubuntu(任何内核):
apt-get install linux-headers-$(uname -r)
加载
Onload需要安装以下软件:
autoconfautomakebashbinutilsgawkgccgettextglibc-commonlibcap-devel。libtoolmakesed
onload_tcpdump
onload_tcpdump 需要安装以下附加软件包:
libpcaplibpcap-devel。
注意:如果未安装这些附加包,则不会构建 onload_tcpdump,但Onload 构建将会成功。
solar_clusterd 需要安装以下附加软件包:
python-devel。
onload_bpftools 需要安装以下附加软件包:
libelf开发包elfutil-devel或包libelf-dev需要使用“加载”选项。
安装 Onload
参考README.MD
加载 Onload 驱动程序
1.加载网络和Onload内核驱动程序:
- 如果您正在使用
sfc网络驱动程序(用于 8000 系列或 X2 系列适配器),只需使用以下onload_tool命令:# onload_tool reload - 这会将任何先前加载的
sfc网络驱动程序替换为sfc来自Onload分发的驱动程序。
- 确认成功:
# onloadOpenOnload <version>Copyright 2019-2022 Xilinx, 2006-2019 Solarflare Communications, 2002-2005 Level 5 NetworksBuilt: <date> <time> (release)Kernel module: <version>如果
Kernel module显示版本,则确认 Onload内核模块已安装并加载。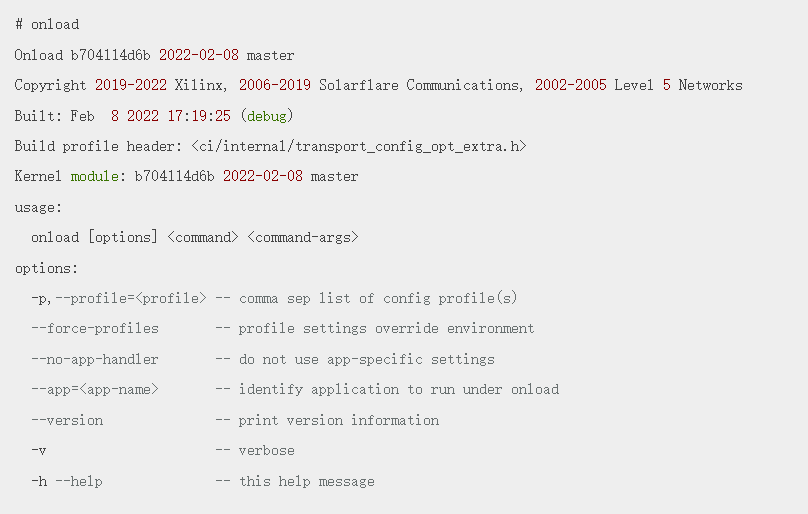
onload_tool reload是重新启动系统以加载Onload驱动程序。
配置网络接口

https://china.xilinx.com/content/dam/xilinx/publications/solarflare/drivers-software/SF-103837-CD-28_Solarflare_Server_Adapter_User_Guide.pdf
安装 Netperf 和 sfnettest
略(后面补充)测试 Onload 安装
运行加载

调优加载
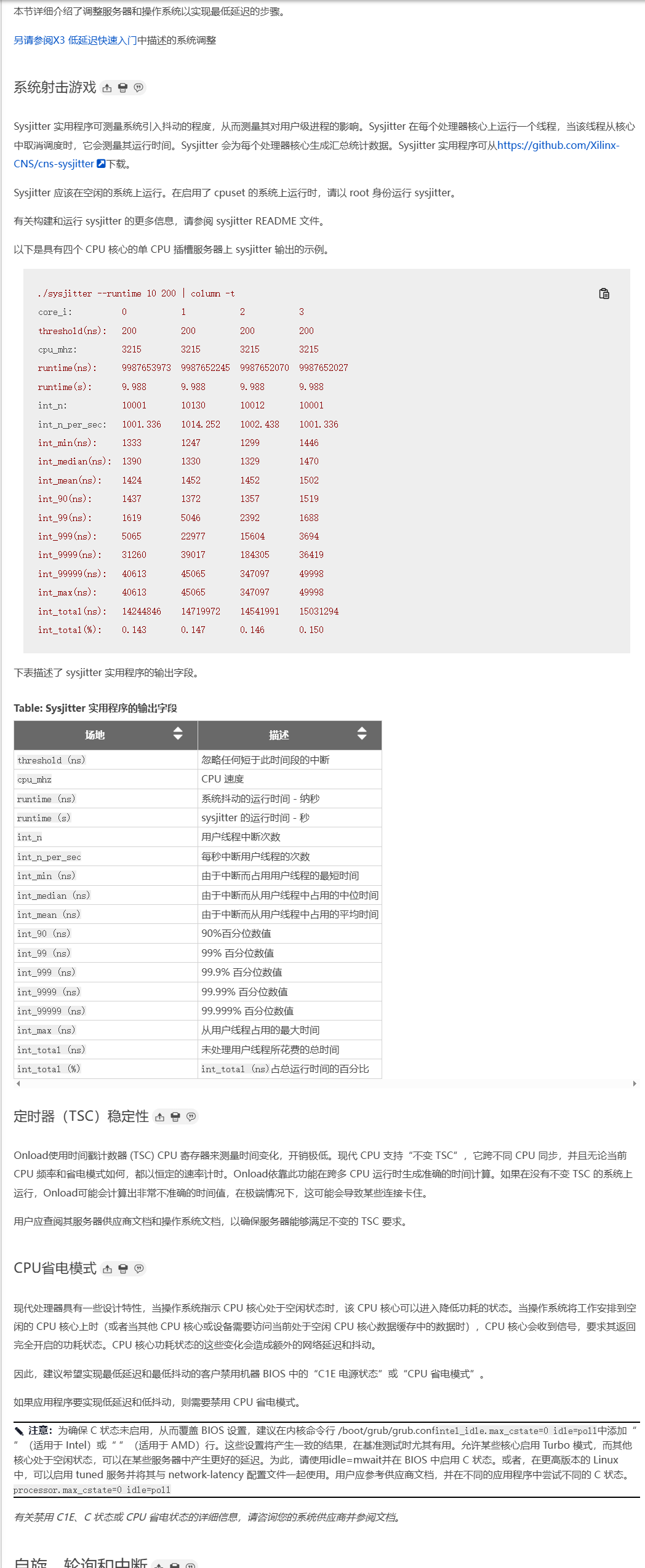
Sysjitter 实用程序可从https://github.com/Xilinx-CNS/cns-sysjitter下载
自旋、轮询和中断
NUMA 系统上的 Onload 部署
当部署在 NUMA 系统上时,除非充分考虑 NUMA 节点的选择、缓存内存的分配以及驱动程序、进程和中断的亲和性,否则应用程序负载吞吐量和延迟性能可能会受到不利影响。
为了获得最佳性能,加速应用程序应始终在距离网络适配器最近的 NUMA 节点上运行。正确的内存分配尤为重要,以确保将数据包缓冲区分配到正确的 NUMA 节点上,从而避免 QPI 流量不必要的增加并避免数据包丢失。
有用的命令
- 要识别 NUMA 节点、插槽内存和 CPU 核心分配:
# numactl -H - 要识别适配器本地的 NUMA 节点:
# cat /sys/class/net/<interface>/device/numa_node - 要识别特定 NUMA 节点上的内存分配和使用情况:
# cat /sys/devices/system/node/node<N>/numastat - 要识别 NUMA 节点到核心的映射,请使用以下方法之一:
# numactl --hardware# cat /sys/devices/system/node/node<N>/cpulist
驱动程序加载 - NUMA 节点
加载时,Onload模块会创建各种常用数据结构。为了确保这些数据结构在距离网络适配器最近的 NUMA 节点上创建,onload_tool reload应将其关联到正确的 NUMA 节点上的核心。
# numactl --cpunodebind=1 onload_tool reload 当同一服务器中的不同 NUMA 节点上有多个受支持的适配器时,用户在加载驱动程序时必须选择一个节点,同时还要确保中断 IRQ 与每个适配器的正确本地 CPU 节点关联。
onload_tool reload 是单线程的,因此使用“cpunodebind=0,1”运行意味着该命令可以在任一节点上运行,直到命令完成后用户才能识别该节点。
内存策略
为了保证内存分配的合理性,并确保内存分配不会失败,应该选择绑定到特定 NUMA 节点的内存策略。如果未指定策略,系统通常会使用默认策略,在进程正在执行的节点上分配内存。
应用处理
大多数由 Onload 进行的处理都发生在 经过 Onload 加速的应用程序 的上下文中。
可以使用多种方法将 Onload 加速的进程绑定(affinitize)到特定 CPU,包括:
-
使用
numactl、 -
使用
taskset、 -
使用
cpusets, -
或通过编程方式设置 CPU 亲和性(Affinity)。
-
简单来说:Onload 会在加速的应用程序中完成大部分处理,你可以通过多种手段控制这些应用程序运行在哪些 CPU 上。
工作队列(Workqueues)
一个被 Onload 加速的应用程序会创建 两个共享工作队列(shared workqueues),以及 每个网络栈(per-stack)一个专属的工作队列。
工作队列的实现方式在不同版本的 Linux 内核中有所不同,相应地,设置其 CPU 亲和性(affinity)的方法也不同。
在较新的 Linux 内核(3.10 及以上)中,Onload 工作队列在创建时会自动绑定到创建它们的 NUMA 节点上。因此,如果驱动程序的加载过程和被 Onload 加速的应用程序都绑定到了正确的节点上,那么 Onload 栈将被创建在正确的节点上,此时不需要额外的操作。
⚠️ 注意:不建议通过
sysfs为工作队列指定cpumask,因为这可能会破坏 Onload 对执行顺序的要求。
在较旧的 Linux 内核中,工作队列线程是以专用线程的形式创建的,可以使用 taskset 或 cpusets 来设置这些线程的 CPU 亲和性。
可以通过名称识别出 Onload 所有栈共享的两个工作队列:
-
onload-wqueue -
sfc_vi
每个栈专属的工作队列名称格式为 onload-wq<栈ID>(例如,栈1对应的工作队列名为 onload-wq:1)。
可以使用 onload_stackdump 命令查看当前 Onload 栈的信息及其对应进程的 PID,例如:
# onload_stackdump
#stack-id stack-name pids 0 - 106913
再使用 Linux 的 pidof 命令获取 Onload 工作队列线程的 PID:
# pidof onload-wq:0 sfc_vi onload-wqueue
106930 105409 105431
推荐做法:
-
在驱动程序加载完成后,立即设置共享工作队列的 CPU 亲和性;
-
在 Onload 网络栈创建完成后,立即设置每个栈工作队列的 CPU 亲和性。
中断(Interrupts)
当 Onload 以中断驱动模式运行时(参见《Interrupt Handling - Using Onload》章节),应将中断绑定(affinitize)到与运行 Onload 应用程序相同的 NUMA 节点上,但不要绑定到与应用程序相同的 CPU 核心上。
当 Onload 采用轮询(spinning 或 busy-wait)模式时,几乎不会产生中断,因此中断被处理在哪个 CPU 上并不是主要问题。
验证(Verification)
可以使用 onload_stackdump lots 命令来验证内存分配是否发生在正确的 NUMA 节点上:
# onload_stackdump lots | grep numa numa nodes: creation=0 load=0 numa node masks: packet alloc=1 sock alloc=1 interrupt=1
解释如下:
-
load参数 表示驱动程序被加载到的节点; -
creation参数 表示为 Onload 栈分配内存的节点; -
numa node masks中:-
packet alloc表示分配网络数据包缓冲的 NUMA 节点; -
sock alloc表示分配 socket 内存的节点; -
interrupt表示实际发生中断的 NUMA 节点。
-
说明:
掩码值的含义如下:
-
1表示 NUMA 节点 0, -
2表示 NUMA 节点 1, -
3表示 节点 0 和 1 都有。
✅ 对大多数场景而言,load 和 creation 最好指向同一个节点,且该节点应是靠近网络适配器的本地节点。
要识别网络接口所连接的 NUMA 节点,可执行以下命令:
# cat /sys/class/net/<interface>/device/numa_node
查看线程绑定情况
若想查看每个被 Onload 加速的线程的 CPU 亲和性,可使用:
# onload_stackdump threads
sfc 驱动程序的中断处理

性能抖动
在任何系统中,降低或消除抖动都是获得最佳性能的关键,然而,抖动导致性能不佳的原因可能难以确定,也难以补救。以下部分列出了一些需要考虑的关键点。
- 减少抖动的第一步应该是考虑X2 低延迟快速入门中指定的配置设置- 这包括禁用 irqbalance 服务、中断调节设置和防止 CPU 内核切换到省电模式的措施。
- 使用 isolcpus 隔离应用程序(或至少是应用程序的关键线程)将使用的 CPU 核心,并防止操作系统管理任务和其他非关键任务在这些核心上运行。
- 设置一个应用程序线程在一个核心上运行,并将该线程的中断设置在单独的核心上 - 但位于同一物理 CPU 包中。即使在旋转时,中断仍然可能发生,例如,如果应用程序 由于忙于执行其他工作而长时间无法调用Onload堆栈。
- 理想情况下,每个自旋线程都会分配一个单独的核心,这样,即使它发生阻塞或被取消调度,也不会妨碍其他重要线程的工作。抖动的一个常见原因是多个自旋线程共享同一个 CPU 核心。抖动峰值可能表明一个线程被另一个线程占用了 CPU 核心。
cat /proc/<pid>/sched您可以使用应用程序线程的调度统计信息来检测这一点。该nr_involuntary_switches计数器记录进程被取消调度的次数,例如由于中断处理程序或同一 CPU 核心上运行的其他任务而取消调度的次数。 - 当 时
EF_STACK_LOCK_BUZZ=1,线程将在等待获取堆栈锁时自旋 EF_BUZZ_USEC 周期。锁自旋可能导致争夺锁的线程之间出现不公平现象,从而导致某个线程资源匮乏。这种情况的发生次数会被计入“stack_lock_buzz”计数器中。当 EF_POLL_USEC(自旋)启用时,EF_STACK_LOCK_BUZZ 默认启用。 - 如果多线程应用程序执行大量套接字操作,堆栈锁争用会导致发送/接收性能抖动。在这种情况下,如果每个争用线程都有自己的堆栈,则可以提高性能。这可以通过 EF_STACK_PER_THREAD 来管理,该选项会为每个线程创建的套接字创建一个单独的Onload堆栈。有关示例,请参阅最小化锁争用。
如果单独的堆栈不是一种选择,那么减少 EF_BUZZ_USEC 周期或完全禁用堆栈锁蜂鸣可能会有所帮助。
- 始终重要的是,需要相互通信的线程在同一个 CPU 包上运行,以便这些线程可以共享内存缓存。
有关详细信息,请参阅NUMA 系统上的 Onload 部署。
- 当某些套接字已加速而其他套接字未加速时,也可能会引入抖动。Onload将确保加速套接字优先于非加速套接字,尽管这种延迟仅在几微秒(而非毫秒)左右,但损失始终在非加速套接字一侧。您可以配置环境变量 EF_POLL_FAST_USEC 和 EF_POLL_NONBLOCK_FAST_USEC 来管理加速套接字相对于非加速套接字的优先级。
- 如果流量稀疏,旋转将带来相同的延迟优势,但用户应确保使用 EF_POLL_USEC 变量配置的旋转超时时间足够长,以确保在接收到流量时线程仍在旋转。
有关详细信息,请参阅旋转、轮询和中断。
- 当应用程序仅需要偶尔发送和接收时,在对等体之间实现 keepalive(心跳机制)可能会有所帮助。这可以将进程数据保留在 CPU 内存缓存中。由于缓存效应,延迟一段时间后调用发送或接收函数,会导致调用时间比在紧密循环中调用时明显更长。
- 一些适配器支持在不实际传输数据的情况下预热发送路径。这同样可以将数据保留在缓存中,从而减少抖动。
- 在某些服务器上,BIOS 设置(例如电源和利用率监控)可能会通过在所有 CPU 核心上执行监控任务而导致不必要的抖动。用户应检查 BIOS 并确定是否可以禁用周期性任务(以及相关的 SMI)。
- sysjitter 实用程序可用于识别和测量空闲系统所有核心上的抖动 - 有关详细信息,请参阅Sysjitter。
使用 Onload 调整配置文件
在应用程序用户空间中设置的环境变量可用于配置和控制加速应用程序性能的各个方面。这些变量可以使用 Linux 的 export 命令导出。例如:
export EF_POLL_USEC=100000 Onload支持调整配置文件脚本文件,这些脚本文件用于将环境变量分组到单个文件中,以便从Onload命令行调用。
该latency配置文件将EF_POLL_USEC=100000忙等待自旋超时设置为 100 毫秒。此外,该配置文件还会针对新建连接或空闲连接禁用 TCP 快速启动,因为额外的 TCP ACK 会增加接收路径的延迟。要使用该配置文件,请在onload命令行中输入它。例如:
onload --profile=latency netperf -H onload2-sfc -t TCP_RR Onload安装后,它提供的配置文件位于以下目录中 - 该目录将被以下onload_uninstall命令删除:
/usr/libexec/onload/profiles 用户定义的环境变量可以写入用户定义的配置文件脚本文件(扩展名为 .opf),并存储在服务器上的任意目录中。然后应在 onload 命令行中指定该文件的完整路径。例如:
onload --profile=/tmp/myprofile.opf netperf -H onload2-sfc -t TCP_RR 例如,Onload分布提供的延迟配置文件如下所示:
# Onload low latency profile. # Enable polling / spinning. When the application makes a blocking call # such as recv() or poll(), this causes Onload to busy wait for up to 100ms # before blocking. onload_set EF_POLL_USEC=100000 # Disable FASTSTART when connection is new or has been idle for a while. # The additional acks it causes add latency on the receive path. onload_set EF_TCP_FASTSTART_INIT 0 onload_set EF_TCP_FASTSTART_IDLE 0 有关环境变量的完整列表,请参阅参数参考。
延迟最佳配置文件
最佳延迟配置文件的目标是针对给定版本的Onload实现尽可能低的延迟。这意味着:
- 配置文件中使用的某些功能可能是实验性的。
- 配置文件中的功能组合可能并不适合所有部署或所有类型的流量。
- 该配置文件可能会在版本之间发生变化。
随着新的低延迟功能的推出,它们将被添加到配置文件中。
因此,建议如下:
- 始终创建配置文件的重命名副本,并使用该副本。
这将避免在更新Onload时配置文件意外更改,并可能破坏您的应用程序。
- 在部署配置文件副本之前,请务必在非生产环境中对其进行测试和调整。
这将避免因不适合您的生产系统的设置组合而导致的问题。
nginx_reverse_proxy 配置文件
Onload的集群功能已得到扩展,通过正确关联Onload堆栈和应用程序工作进程,可以更好地支持 NGINX 应用程序的主进程模式和热重启操作。为此,请使用以下设置:
EF_SCALABLE_FILTERS_ENABLE: 2 EF_CLUSTER_HOT_RESTART: 1 参见EF_CLUSTER_HOT_RESTART和EF_SCALABLE_FILTERS_ENABLE。
新的nginx_reverse_proxy配置文件包含一组相关配置示例,其中包含更多设置。此配置文件会搜索 NGINX 配置文件,然后使用其中的设置来设置正确的Onload参数。类似的技术也可用于创建针对其他应用程序的配置文件。
特定应用的调优
高级调整需要更仔细地检查应用程序的性能。
Onload包含一个名为的诊断应用程序onload_stackdump,可用于监视Onload性能并设置调整选项。
以下示例演示了如何使用onload_stackdump来检查系统性能的各个方面,从而确定应设置哪些环境变量来调优应用程序。该过程应满足这些调优目标。
- 尽可能在用户级别进行处理。
请参阅用户级处理。
- 尽可能减少中断。
看到尽可能少的中断。
- 消除水滴。
请参阅消除掉落。
- 尽量减少锁争用。
请参阅最小化锁争用。
有关更多示例和使用,onload_stackdump请参阅onload_stackdump。

待续。。。
引用:
AMD Technical Information Portal