纳米AI搜索与百度AI搜、豆包的核心差异解析
一、技术定位与设计目标
1、纳米AI搜索:轻量化边缘计算导向 专注于实时数据处理与资源受限环境下的高效响应,通过算法优化和模型压缩技术,实现在物联网设备、智能终端等低功耗场景的本地化部署。其核心优势在于减少云端依赖,保障隐私安全与即时决策能力。
2、百度AI搜:搜索引擎生态延伸 基于百度搜索体系构建,强调信息整合与多模态交互(文本、图像、语音)。其技术重心在于通用知识检索的准确性和搜索场景的智能化扩展,服务于大众信息获取需求。
3、豆包:生活化个人助手 定位于日常场景的便捷服务,通过自然语言处理技术提供语音交互、日程管理等轻量级功能,侧重用户生活效率提升而非专业数据处理。

二、功能架构差异
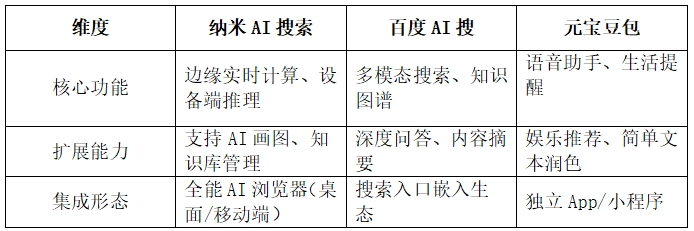
三、适用场景与用户群体
1、纳米AI搜索
场景:工业物联网设备监控、自动驾驶实时决策、智能家居本地化控制。
用户:企业开发者、硬件厂商及对隐私与延时敏感的专业用户。
2、百度AI搜
场景:开放式信息检索、学术研究辅助、多源内容整合。
用户:学生、研究人员及需高效获取结构化信息的普通用户。
3、豆包
场景:个人日程规划、语音操控家居、休闲娱乐互动。
用户:大众消费者,尤其注重生活便利性的非技术群体。
四、技术实现路径对比
纳米AI:采用模型剪枝与量化技术压缩参数规模,适配嵌入式芯片;支持本地知识库构建以降低网络传输负载。
百度AI搜:依赖搜索引擎的历史数据积累优化语义理解,通过海量网页索引增强结果覆盖广度。
豆包:聚焦垂直场景的对话引擎优化,以轻型模型实现高频交互的流畅性。

五、生态与发展方向
1、纳米AI构建“AI工具集”生态,整合智能体开发、AI写作等功能模块,向跨平台生产力工具演进。
2、百度AI搜 强化与百度云、Apollo等企业服务的协同,推动B端解决方案闭环。
3、豆包依托字节跳动内容生态,探索娱乐化服务(如短视频指令交互)与轻社交功能融合。
总结:差异的本质是场景分化
纳米AI搜索是面向边缘计算时代的专用基础设施,为设备端智能提供底层支持;
百度AI搜延续搜索核心优势,致力于泛化信息的智能获取;
豆包则锚定个人生活场景,以最小化使用门槛实现高频服务触达。
三类工具因目标场景的分化形成互补,而非直接竞争。用户选择需基于实时性需求、隐私权重及功能复杂度综合考量。