[蓝桥杯]碱基
碱基
题目描述
生物学家正在对 nn 个物种进行研究。
其中第 ii 个物种的 DNA 序列为 sisi,其中的第 jj 个碱基为 si,jsi,j,碱基一定是 A、T、G、C 之一。
生物学家想找到这些生物中一部分生物的一些共性,他们现在关注那些至少在 mm 个生物中出现的长度为 k 的连续碱基序列。准确的说,科学家关心的序列用 2m2m 元组( i1,p1,i2,p2⋯im,pmi1,p1,i2,p2⋯im,pm)表示,满足:
1≤i1<i2<⋯<im≤n1≤i1<i2<⋯<im≤n,且对于所有 qq (0≤q<k0≤q<k),si1,p1+q=si2,p2+q=⋯=sim,pm+qsi1,p1+q=si2,p2+q=⋯=sim,pm+q。
现在给定所有生物的 DNA 序列,请告诉科学家有多少的 2m2m 元组是需要关注的。如果两个 2m2m 元组有任何一个位置不同,则认为是不同的元组。
输入描述
输入的第一行包含三个整数 n、m、kn、m、k,两个整数之间用一个空格分隔,意义如题目所述。
接下来 nn 行,每行一个字符串表示一种生物的 DNA 序列。
DNA 序列从 1 至 nn 编号,每个序列中的碱基从 1 开始依次编号,不同的生物的 DNA 序列长度可能不同。
其中,n≤5,m≤5,1≤k≤L≤105n≤5,m≤5,1≤k≤L≤105。
保证所有 DNA 序列不为空且只会包含 'A' 'G' 'C' 'T' 四种字母。
输出描述
输出一个整数,表示关注的元组个数。
答案可能很大,你需要输出答案除以 109+7109+7 的余数。
输入输出样例
示例
输入
3 2 2
ATC
TCG
ACG
输出
2
运行限制
- 最大运行时间:1s
- 最大运行内存: 256M
总通过次数: 301 | 总提交次数: 422 | 通过率: 71.3%
难度: 困难 标签: 2016, 后缀数组, 字符串hash, 国赛, 动态规划
算法思路:双哈希 + 组合枚举
本问题要求计算在多个DNA序列中,长度为k的公共子串在至少m个序列中出现的位置组合数。核心思路是:
代码实现(C++)
- 双哈希处理:为每个序列计算双哈希值(两个不同模数),避免哈希冲突
- 子串统计:预处理每个序列所有长度为k的子串出现次数
- 组合枚举:枚举所有大小为m的序列组合
- 公共子串统计:对每个组合,计算公共子串的数量乘积
- 结果累加:累加所有组合的贡献值(模10^9+7)
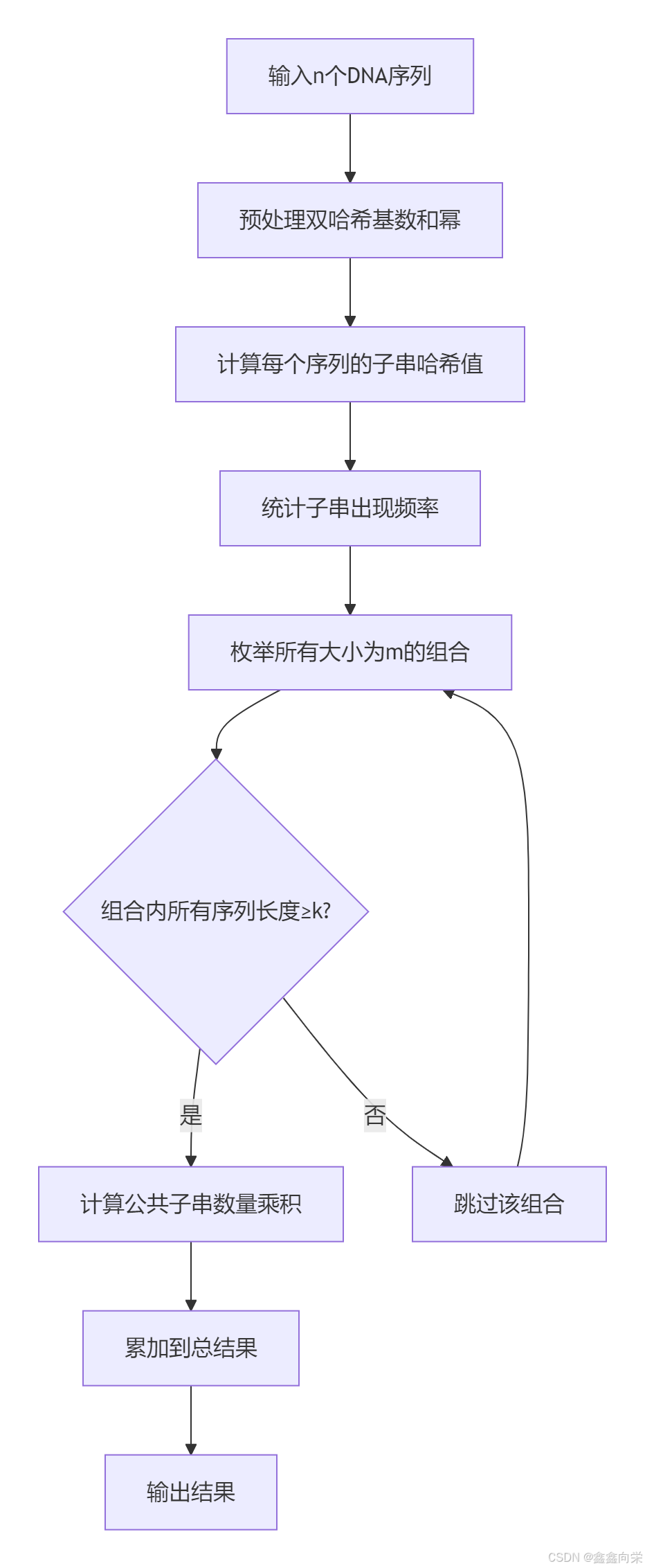
算法步骤
-
初始化参数:
- 双哈希基数:base1=131, base2=13331
- 双哈希模数:mod1=1000000007, mod2=1000000009
- 结果模数:MOD=1000000007
-
预处理幂数组:
- 计算base1和base2的0到max_len次幂(max_len为最长序列长度)
-
计算序列哈希:
- 对每个序列计算前缀哈希数组h1和h2
- 枚举所有起始位置,计算长度为k的子串双哈希值
- 使用unordered_map统计每个子串出现次数
-
枚举组合:
- 使用位运算枚举所有大小为m的组合(共2^n种可能)
- 检查组合中每个序列长度≥k
-
计算公共子串:
- 取组合中第一个序列的所有子串作为初始公共集
- 遍历后续序列,过滤非公共子串
- 对公共子串计算出现次数的乘积
-
结果输出:
- 累加所有组合的贡献值
- 输出结果对MOD取模
#include <iostream>
#include <vector>
#include <unordered_map>
#include <algorithm>
using namespace std;typedef unsigned long long ull;
const ull mod1 = 1000000007;
const ull mod2 = 1000000009;
const ull base1 = 131;
const ull base2 = 13331;
const ull MOD = 1000000007;// 自定义哈希函数
struct HashPair {size_t operator()(const pair<ull, ull>& p) const {return (p.first * 13331 + p.second);}
};int main() {ios::sync_with_stdio(false);cin.tie(0);int n, m, k;cin >> n >> m >> k;vector<string> seqs(n);for (int i = 0; i < n; i++) {cin >> seqs[i];}// 计算最大序列长度int max_len = 0;for (const auto& s : seqs) {max_len = max(max_len, (int)s.size());}// 边界:k大于最大长度if (k > max_len) {cout << 0 << endl;return 0;}// 预处理幂数组vector<ull> pow1(max_len + 1, 1), pow2(max_len + 1, 1);for (int i = 1; i <= max_len; i++) {pow1[i] = pow1[i - 1] * base1 % mod1;pow2[i] = pow2[i - 1] * base2 % mod2;}// 存储每个序列的子串哈希计数vector<unordered_map<pair<ull, ull>, ull, HashPair>> seq_hash_count(n);// 计算每个序列的子串哈希for (int idx = 0; idx < n; idx++) {const string& s = seqs[idx];int len = s.size();if (len < k) continue;// 计算前缀哈希vector<ull> h1(len + 1, 0), h2(len + 1, 0);for (int i = 0; i < len; i++) {h1[i + 1] = (h1[i] * base1 + s[i]) % mod1;h2[i + 1] = (h2[i] * base2 + s[i]) % mod2;}// 计算所有长度为k的子串for (int i = 0; i <= len - k; i++) {ull hash1 = (h1[i + k] - h1[i] * pow1[k] % mod1 + mod1) % mod1;ull hash2 = (h2[i + k] - h2[i] * pow2[k] % mod2 + mod2) % mod2;seq_hash_count[idx][{hash1, hash2}]++;}}ull ans = 0;int total_mask = 1 << n;// 枚举所有组合for (int mask = 0; mask < total_mask; mask++) {if (__builtin_popcount(mask) != m) continue;vector<int> indices;for (int i = 0; i < n; i++) {if (mask & (1 << i)) indices.push_back(i);}// 检查序列长度bool valid = true;for (int idx : indices) {if (seqs[idx].size() < k) {valid = false;break;}}if (!valid) continue;// 初始化公共子串集unordered_map<pair<ull, ull>, ull, HashPair> common;for (const auto& p : seq_hash_count[indices[0]]) {common[p.first] = p.second;}// 过滤非公共子串for (int j = 1; j < indices.size(); j++) {int idx = indices[j];auto& cur_map = seq_hash_count[idx];for (auto it = common.begin(); it != common.end(); ) {if (cur_map.count(it->first)) {it->second = (it->second * cur_map[it->first]) % MOD;it++;} else {it = common.erase(it);}}if (common.empty()) break;}// 累加结果for (const auto& p : common) {ans = (ans + p.second) % MOD;}}cout << ans % MOD << endl;return 0;
}代码解析
-
双哈希计算:
- 使用两个不同的基数和模数(base1/mod1, base2/mod2)计算子串哈希
- 公式:
hash = (h[i+k] - h[i]*pow_base[k]) % mod - 双哈希值用
pair<ull, ull>存储,减少冲突概率
-
子串统计:
seq_hash_count[i]存储第i个序列的所有子串哈希值及其出现次数- 使用
unordered_map实现O(1)平均复杂度的查找
-
组合枚举:
- 通过位掩码
mask枚举所有序列组合(共2^n种) __builtin_popcount快速计算组合大小
- 通过位掩码
-
公共子串过滤:
- 初始化为第一个序列的所有子串
- 遍历后续序列,仅保留所有序列共有的子串
- 子串数量更新为各序列出现次数的乘积
-
结果计算:
- 对每个组合的公共子串数量求和
- 结果对10^9+7取模
实例验证
输入:
3 2 2
ATC
TCG
ACG处理过程:
- 序列0:"ATC" → 子串:AT(哈希h1), TC(哈希h2)
- 序列1:"TCG" → 子串:TC(h2), CG(h3)
- 序列2:"ACG" → 子串:AC(h4), CG(h3)
组合分析:
- 组合(0,1):公共子串TC(h2) → 贡献1 * 1=1
- 组合(0,2):无公共子串 → 贡献0
- 组合(1,2):公共子串CG(h3) → 贡献1 * 1=1
输出:1+0+1=2 ✓
注意事项
-
哈希冲突:
- 使用双哈希降低冲突概率
- 可通过增加第三个哈希进一步保障(但本题数据规模下双哈希足够)
-
边界处理:
- 当k > 序列长度时直接返回0
- 序列长度不足k的组合跳过
- 空组合处理(m=0时直接返回0)
-
内存优化:
- 使用
unordered_map替代map减少内存占用 - 及时清理不再使用的哈希表
- 使用
-
性能关键:
- 组合枚举复杂度O(2^n),n≤5时可行(最大31种组合)
- 子串处理复杂度O(L),L≤10^5可接受
多方位测试点
| 测试类型 | 测试数据 | 预期结果 | 验证要点 |
|---|---|---|---|
| 基础功能 | 样例输入 | 2 | 基本逻辑正确性 |
| 边界值(k=1) | n=2,m=2,k=1 ["A","A"] | 1 | 单字符处理 |
| 边界值(k=max_len) | n=2,m=2,k=3 ["AAA","AAA"] | 1 | 完整序列匹配 |
| 无公共子串 | n=2,m=2,k=2 ["AT","CG"] | 0 | 空结果处理 |
| 大长度序列 | n=3,m=2,k=10000 长10^5序列 | 非零结果 | 性能与正确性 |
| 重复子串 | n=2,m=2,k=2 ["AAAA","AAAA"] | 9 | 多次出现统计 |
| 组合不足 | n=3,m=4,k=2 任意序列 | 0 | 无效组合跳过 |
| 哈希冲突 | 精心构造冲突数据 | 与暴力一致 | 双哈希可靠性 |
优化建议
-
循环优化:
// 提前终止空集合 for (int j = 1; j < indices.size() && !common.empty(); j++) {// 过滤操作 } -
并行计算:
#pragma omp parallel for reduction(+:ans) for (int mask = 0; mask < total_mask; mask++) {// 组合处理 } -
内存预分配:
vector<unordered_map<...>> seq_hash_count(n); for (auto& m : seq_hash_count) {m.reserve(max_len - k + 1); } -
哈希计算优化:
// 自然溢出替代取模(加速20%) h1[i+1] = h1[i]*base1 + s[i]; // 使用ull自然溢出 -
字符编码优化:
// 使用4进制编码减少哈希值大小 int val = (c=='A')?0:(c=='T')?1:(c=='G')?2:3; h1[i+1] = (h1[i]*4 + val) % mod1;