游戏开发常见数据压缩
- 无损压缩
原理:通过消除数据中的冗余信息(如重复模式、统计冗余),实现数据完全还原。
适用场景:需要精确还原的数据(如代码、配置、网络协议)。
- 有损压缩
原理:通过丢弃人眼/人耳不敏感的细节信息(高频信号、颜色微小差异),牺牲部分质量以大幅减少数据量。
适用场景:音视频、纹理、动画等非关键精度数据。
常见通用编码
-
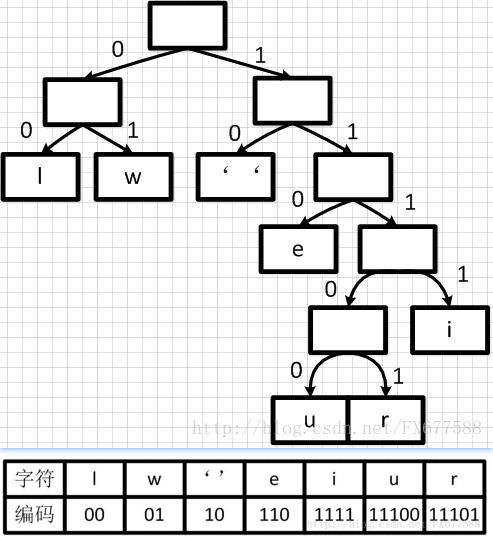
霍夫曼编码(Huffman Coding)
-
原理:根据符号出现频率构建变长编码表,高频符号用短码,低频符号用长码。
-
比如压缩:
we will we will r u
-
-
算术编码(Arithmetic Coding)
-
https://zhuanlan.zhihu.com/p/390684936
-
原理:将整个输入流映射为一个[0,1)区间的小数,通过概率模型动态调整区间。
-
优势:比霍夫曼编码更接近熵极限。
-
游戏应用:
- 高压缩率需求场景(如离线资源包)。
-
图片压缩
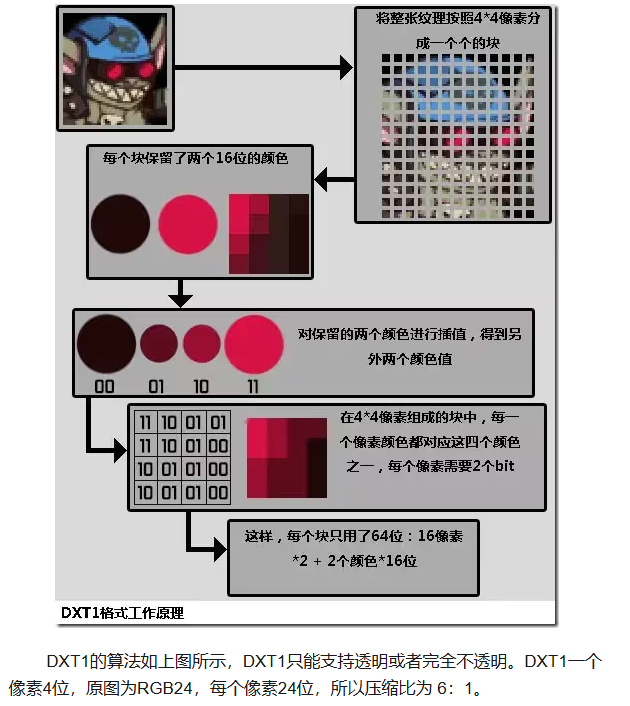
DXT1
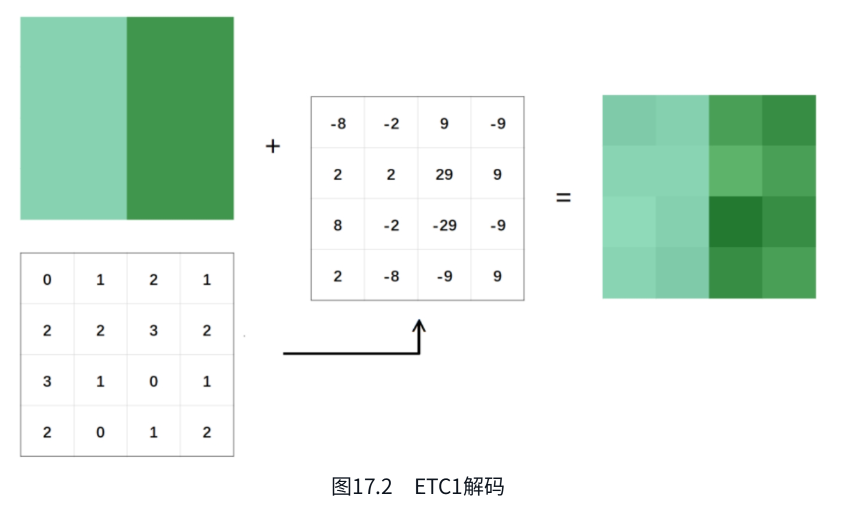
ETC1/ETC2
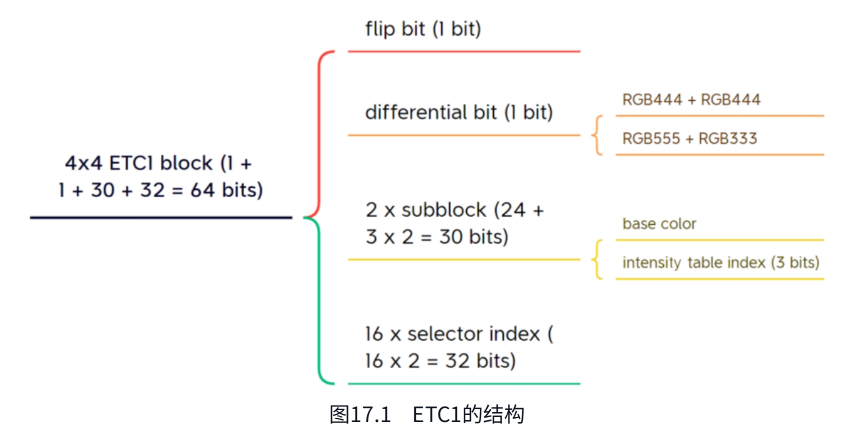
原理:
- 分块:纹理划分为4x4像素块。
- 划分子块:尝试水平(4x2)或垂直(2x4)分割,选择误差更小(比如颜色差)的方向(由flip bit标记)。
- 基色编码:每个子块存储两个基色(类似平均颜色)(BaseColor1和BaseColor2),格式为RGB444或RGB555。
- 调制表选择:每个子块选择一张预定义的4级调制表(如{-8, -2, +2, +8})。
- 像素颜色生成:对每个像素,根据基色和调制值计算最终颜色:Color=BaseColorextended+ModValue×ScaleColor=BaseColorextended+ModValue×Scale
- 示例:
- 基色为RGB444(12, 3, 8) → 扩展到RGB888(12×17, 3×17, 8×17) = (204, 51, 136)。
- 调制值为+8 → 最终颜色为(204+8, 51+8, 136+8) = (212, 59, 144)。
ASTC
-
分块里面还分区域,区域中可以根据颜色差异动态调整,比如颜色相近的要的数据少。
-
目前游戏主要用这种。
PVRTC
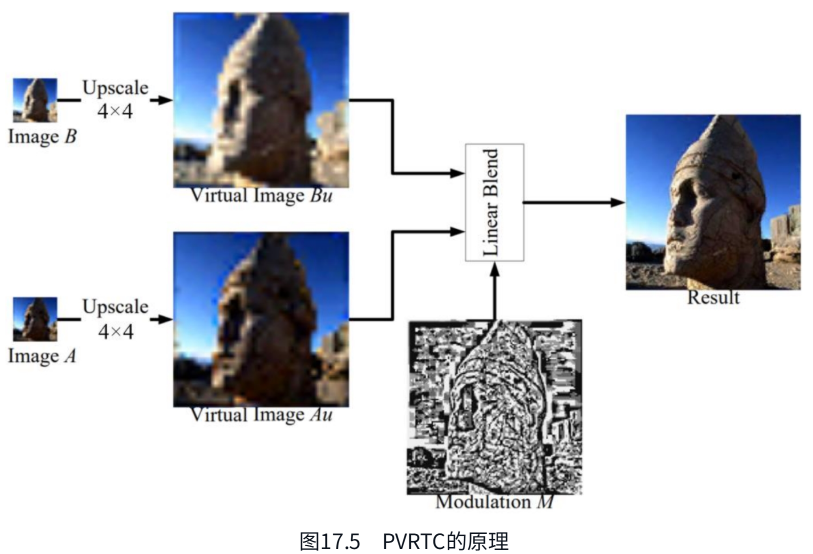
-
主要用于iOS,压缩率比ASTC好一点,但表现上ASTC更好。
-
高频低频(颜色变化剧烈程度)区分不同格式,再插值混合。
音频
- 人耳听不到的过滤之类的。哈夫曼编码。
模型
- 将法线向量编码为八面体映射(2个值代替3个)
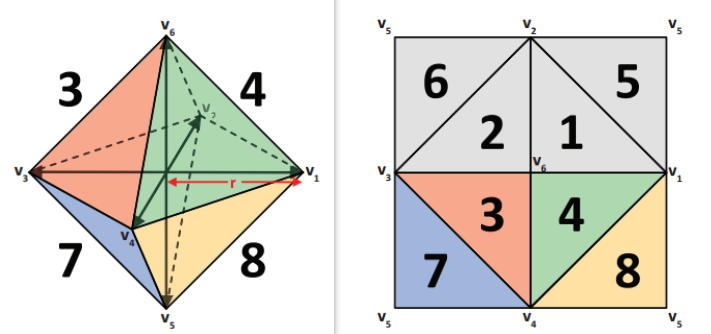
-
网格简化LOD,顶点合并。
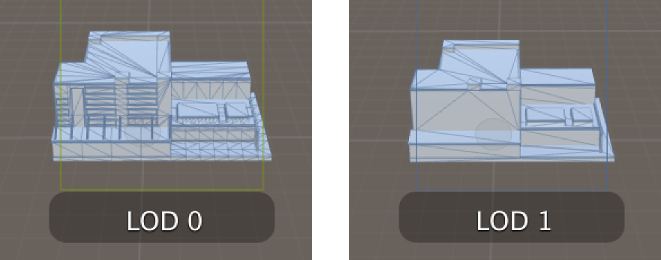
-
网格合并,比如场景模型很多细节多个对象,合并成一个大的网格。
-
动画的关键帧量化,用插值代替。
-
动画数据浮动值限制,比如去掉小数点后4位。
数据协议
-
常用数据格式:json、bson、msgpack
-
Protobuf:字段key用数字ID代替
-
MessagePack、BSON:用二进制json格式代替。
资源包
-
LZ77、LZ4、LZMA
-
通过滑动窗口和哈希表加速查找重复字符串,用长度-距离对(Length-Distance Pair)替代重复内容。

- unity打AB包支持这两格式,目前用的LZ4。
其他
-
网络同步:仅发送变化的数据,如玩家位置同步(+5, -1, 0),而不是完整坐标。
-
代码编译:去掉注释,变量名简化。
-
降低数据精度:浮点数坐标转为16位整数。
-
配置表:
-
转表lua时,用元表,把重复项用短ID替换。
-
翻译表:繁体台湾有时一样,只保留一个,代码查找不到查另外一个。
-
-
流式加载的数据:差分压缩,如前面玩家坐标同步,只记录和前一个或某个标准值的差值,省去记录完整值得占用空间。
-
将长文件路径字符串,计算成短hash替换。
-
数字+大小字母实现(10+26*2)进制组合。