hadoop完整安装教程(附带jdk1.8+vim+ssh安装)
本篇带领大家在uabntu20虚拟机上安装hadoop,其中还包括jdk1.8、ssh、vim的安装教程,(可能是)史上最全的安装教程!!!若有疑问可以在评论区或者私信作者。建议在虚拟机上观看此博客,便于复制粘贴。同时要注意自己设置的用户名是否与本篇博客的用户名相同,若不同的话请注意自己修改。
一、创建hadoop用户并且提高权限
- sudo useradd -m hadoop -s /bin/bash
- sudo passwd hadoop
- sudo adduser hadoop sudo
二、更新apt
1.切换到hadoop用户
先重启虚拟机,在切换hadoop用户,更新系统权限
2.更新apt
- sudo apt-get update

3.下载vim用户修改文件
- sudo apt-get install vim

- 继续执行,输入y

三、下载ssh
1.下载ssh
- sudo apt-get install openssh-server

- 输入y进行安装

2.在本机登录ssh
- ssh localhost
(1)输入yes并设置密码

(2)推荐设置成无密码,接着上一步继续输入即可
- exit # 退出刚才的 ssh localhost
- cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
- ssh-keygen -t rsa # 会有提示,都按回车就可以
- cat ./id_rsa.pub >> ./authorized_keys # 加入授权

![]()
四、安装jdk1.8
1.安装
- sudo apt install openjdk-8-jdk -y

2.验证
- java -version
- javac -version

五、安装hadoop
1.安装hadoop
- wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.4.1/hadoop-3.4.1.tar.gz -P ~/Downloads
也可以在镜像网站选择你想要的版本更换在路径上
Index of /apache/hadoop/common
 2.解压并移动到/usr/local
2.解压并移动到/usr/local
- cd ~/Downloads
- sudo tar -zxvf hadoop-3.4.1.tar.gz -C /usr/local
- cd /usr/local
- sudo mv hadoop-3.4.1 hadoop
- sudo chown -R hadoop /usr/local/hadoop
![]()

3.查看jdk安装路径
- readlink -f $(which java)
![]()
- nano ~/.bashrc
将下面的代码写入文件,ctrl+o保存-回车确认-ctrl+x退出
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64(你的java实际路径)
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
![]()
保存并执行
- source ~/.bashrc
六、配置 Hadoop 文件
1. hadoop-env.sh文件
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
找到这一行:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
填入你 Java 的安装路径,比如:
/usr/lib/jvm/java-8-openjdk-amd64
2. core-site.xml文件
nano $HADOOP_HOME/etc/hadoop/core-site.xml
添加内容如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
3. hdfs-site.xml文件
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
创建对应目录:
mkdir -p ~/hadoopdata/hdfs/namenodemkdir -p ~/hadoopdata/hdfs/datanode
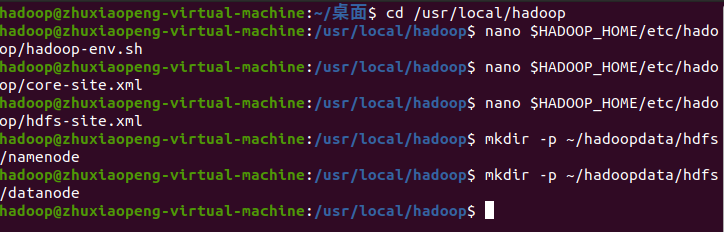
七、启动 Hadoop
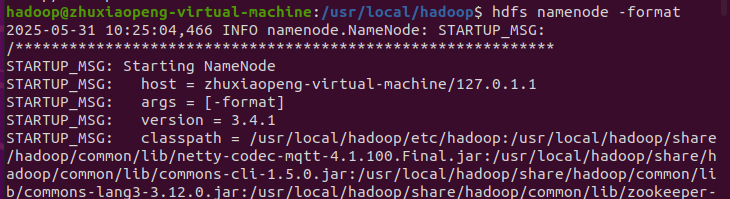
1. 格式化 HDFS
hdfs namenode -format
如果看到 Successfully formatted,说明格式化成功。或者启动一下试试
2. 启动服务
start-dfs.sh start-yarn.sh
使用 jps 查看进程:
jps
你应该能看到:NameNode、DataNode、ResourceManager、NodeManager 等进程。
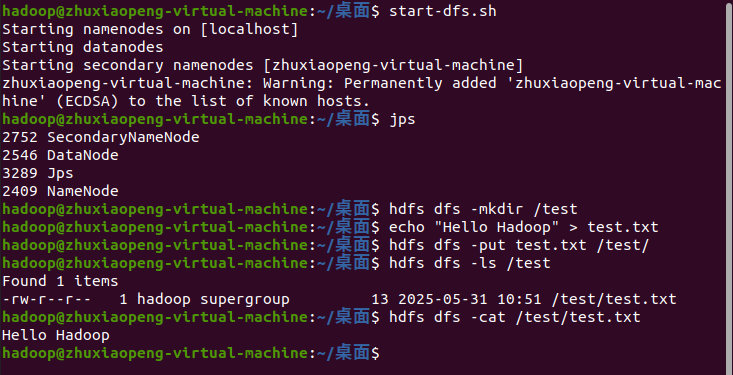
- 输入图片中其他的命令,用于测试文件系统功能
八、访问 Hadoop Web UI
-
HDFS 管理界面:http://localhost:9870
-
YARN 管理界面:http://localhost:8088
若安装中出现了问题,可以在评论区讨论或者私信作者。