大模型应用开发之微调与对齐
一、指令微调Instruction Tuning
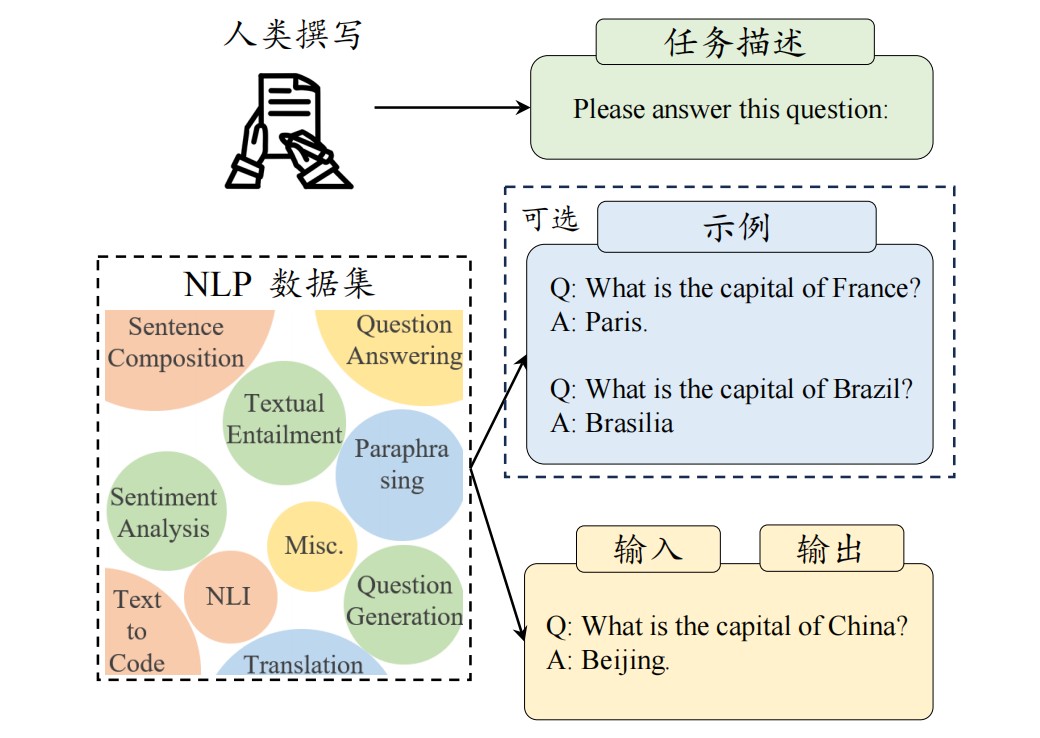
1、指令数据
大模型就像一个天赋异禀的学生,在前期预训练阶段通过大量的阅读知识积累拥有了大量的见识,但光有天赋知识却不会交流还不行,得有好的教材和老师教它怎么做题、怎么回答问题,这个“教材和老师的角色”,就由指令数据来扮演
1)指令数据组成
- 指令 (Instruction / Prompt): 清晰地告诉模型要做什么。比如“请回答法国的首都是哪里?”
- 可选的示例 (Demonstration / Example Input ): 给模型一个或多个输入样例,帮助它理解任务格式。比如问题:“巴西的首都是哪里?”
- 输入 (Input ): 针对当前任务的具体输入。比如“中国的首都是哪里?”
- 输出 (Output ): 模型应该给出的正确答案或完成的内容。比如“北京”。
2)指令数据构建方法
“教材”从哪里来呢?主要有三种方法:
- 基于现有的 NLP 任务数据集:学术界已经有很多现成的、高质量的 NLP 数据集,比如机器翻译、文本摘要、文本分类等。这些数据集通常都有明确的“输入-输出”对。 我们给这些现成的“输入-输出”对配上一个明确的“指令(PromptSource 平台: 一个方便大家贡献和使用指令模板的平台)
- 基于对话数据构建:从聊天中学做事,收集真实用户提交给模型的查询。对于这些查询,让人类标注员编写高质量的回答,或者从模型生成的多个回答中挑选最好的。把“用户查询”作为指令,把“人工编写/筛选的回复”作为输出,组成训练数据
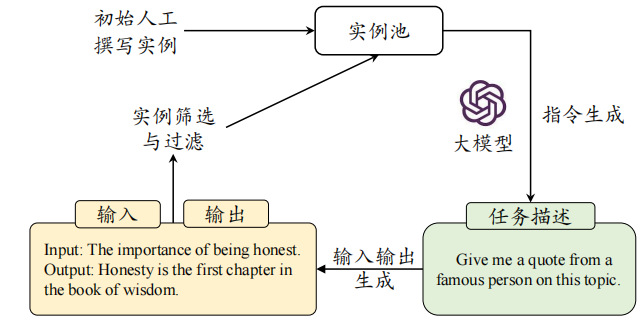
- 基于合成数据构建:人工标注指令数据成本太高、效率太低
- Self-Instruct - “自己出题自己做”:先准备少量人工编写的“种子指令”。让种子模型根据这些种子指令,生成更多新的、更多样化的指令。(比如给它看几个指令,让它再写 10 个类似的)。 判断新生成的指令是否需要输入。如果需要,再让种子模型为这个指令生成合适的输入(比如,指令是“写一首关于春天的诗”,模型就自己想一个关于春天的主题作为输入)。 让种子模型根据生成的“指令”和“输入”,生成对应的“输出”(标准答案)。 对生成的数据进行过滤,去除低质量、重复或不合适的样本
- Evol-Instruct - “指令进化论”: 对已有的指令,通过特定的“演化提示”(比如“增加约束条件”、“深化”、“具体化”、“增加推理步骤”等),让强大的语言模型(如 ChatGPT)将其改写得更复杂。确保演化后的指令仍然是有效且可解的。再让模型为这些“进化”后的复杂指令生成对应的输出
3)指令数据构建考虑因素
怎么让我们的“教材”质量更高?
- 指令格式
- 指令数量
- 指令数据质量
- 任务多样性
2、指令微调训练策略
1)训练参数优化
指令微调中的优化器设置(AdamW 或 Adafactor)、稳定训练技巧(权重衰减 和梯度裁剪)和训练技术(3D 并行、ZeRO 和混合精度训练)都与预训练保持阶段一致,与预训练的不同之处:
- 目标函数:指令微调可以被视为一个有监督的训练过程,通常采用的目标函数为序列到序列损失,仅在输出部分计算损失,而不计算输入部分的损失
- 批次大小和学习率:指令微调阶段通常只需要使用较小的批次大小和学习率对模型进行小幅度的调整
- 多轮对话高效训练:将所有一个对话的多轮内容一次性输入模型,通过设计损失掩码来实现仅针对每轮对话的模型输出部分进行损失计算,从而显著减少重复前缀计算的开销
2)指令数据规划
除了训练参数,怎么组织我们的“教材”(指令数据)也很重要
- 平衡数据分布:混合使用多个不同来源、不同类型的指令数据集
- 多阶段指令数据微调:分阶段、有侧重地进行微调(先用大量的通用 NLP 任务指令数据进行微调,打好基础。 再用少量但高质量的对话指令数据进行进一步微调,提升对话能力和遵循复杂指令的能力)
- 结合预训练数据与指令微调数据:在指令微调阶段,混合一部分预训练数据,保持原有的通用知识和语言建模能力,防止性能退化
3、参数高效微调/轻量化微调 (PEFT)
每次我们想模型更新一点新东西(比如让它适应一个新的任务或领域),都要把整个巨大的模型(几百亿甚至上千亿参数)都重新训练一遍,那成本太高了,简直是“杀鸡用牛刀”!所以我们在微调时,冻结大部分预训练模型的参数,只训练少量新增的或选择的参数。这样就能用很少的计算资源和时间,达到接近全参数微调的效果
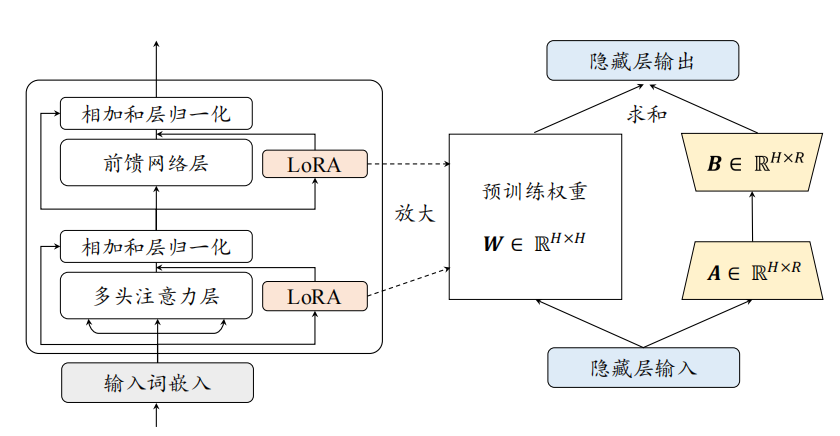
1)低秩适配微调方法 (Low-Rank Adaptation, LoRA)
核心思想: 大语言模型虽然参数很多,但它们在适应新任务时,参数的改变量(ΔW)可能具有“低秩 (Low Rank)”特性。也就是说,这个改变量可以用两个更小的矩阵相乘来近似表示。
2)其他高效微调
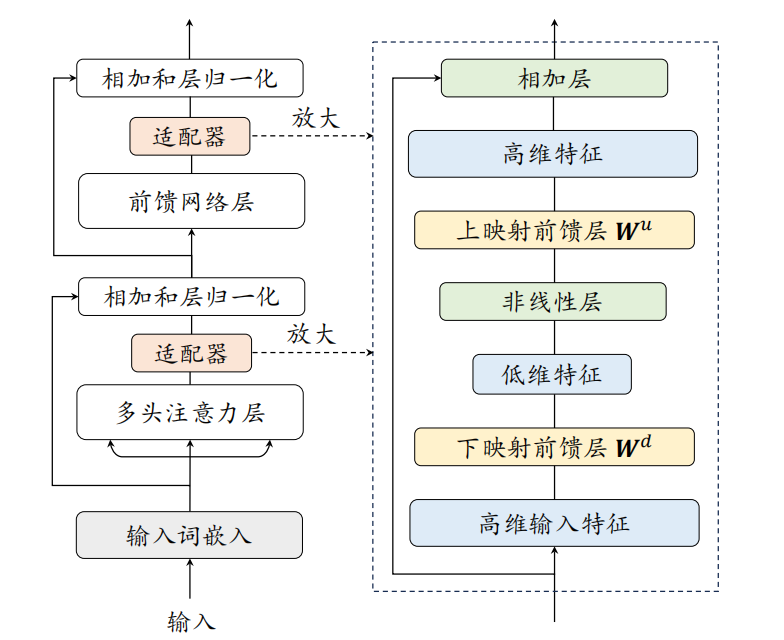
- 适配器微调 (Adapter Tuning):在预训练好的 Transformer 模型的每一层内部,插入一些小型的、可训练的神经网络模块,这些模块就叫做“适配器 (Adapter)”。在微调时,只训练这些新加入的适配器模块的参数,而原始 Transformer 的参数保持冻结
- 前缀微调 (Prefix Tuning):不修改预训练模型的任何参数,而是在输入序列的前面添加一小段可训练的、连续的向量序列,称为“前缀 (Prefix)”。这个前缀就像一个任务相关的“小抄”或者“引导语”,它会指导模型如何处理后续的真实输入以完成特定任务
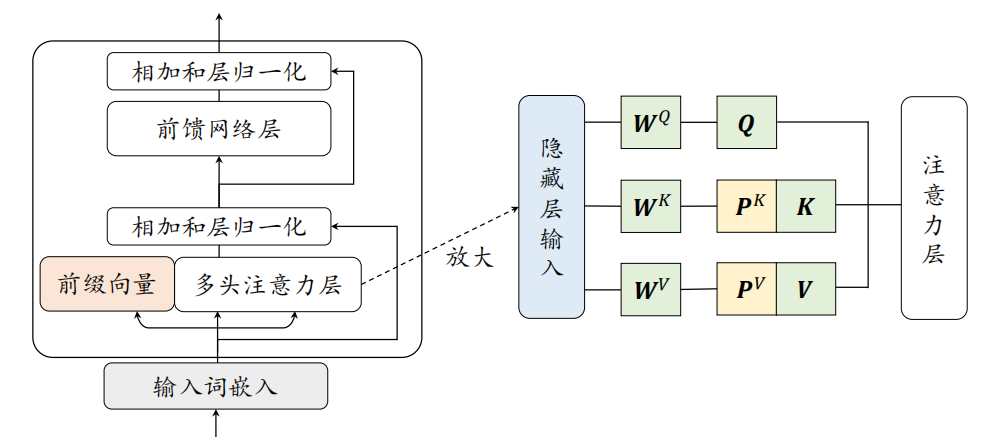
在每一层的多头注意力模块的 Key (K) 和 Value (V) 向量序列的前面,各自拼接上一段可学习的前缀向量(通常这些前缀向量在不同层之间不共享,但可以通过一个小型网络如 MLP 从一个更小的参数集生成)。
- 提示微调 (Prompt Tuning / P-Tuning):采用在输入前添加可学习“提示”的思想,但只在模型的输入嵌入层添加,并且这些提示向量在所有层共享
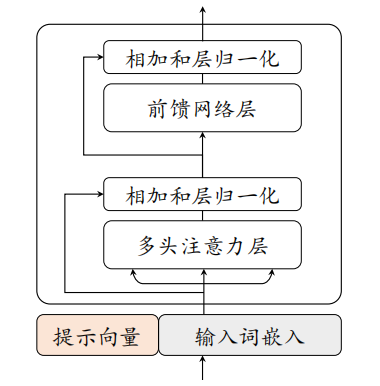
在原始输入词元嵌入序列的前面,拼接一小段可学习的、连续的提示向量。只训练提示参数: 微调时,只更新这些提示向量的参数
二、人类对齐
在大语言模型的预训练和有监督微调的过程中,主要是根据上下文内容来预测下一个词元。但是,这一过程并未充分考虑人类的价值观或偏好,可能导致大语言模型从数据中学习到不符合人类期望的生成模式。为了规避这些潜在风险,研究人员提出了“人类对齐”这一关键概念,旨在保证大语言模型的行为与人类期望和价值观相一致。(指令微调让模型"会做事",但往往做的事情需要符合价值观,需要做对事,做好事,所以通过人类对齐训练让模型"做对事")
1、对齐标准
与预训练和指令微调不同,人类对齐引入全新的评估标准:
-
有用性:最基本的要求。模型要能提供有用的信息,准确完成任务,理解上下文,展现出一定的创造性和多样性。它应该主动询问不清楚的地方,而不是瞎猜+
-
诚实性:模型的输出要真实、客观,不能胡编乱造、歪曲事实,避免产生误导。
-
无害性:模型不能生成或传播有害、歧视、暴力或侵犯隐私的内容。对于那些可能导致危害的请求,它应该懂得拒绝。
2、基于人类反馈的强化学习RLHF
由于对齐标准难以通过形式化的优化目标进行建模,因此研究人员提出了基于人类反馈的强化学习(RLHF),引入人类反馈对大语言模型的行为进行指导(就像家长和社会教孩子价值观:家长说:"这样回答很好,给你点赞!"(正面反馈)社会说:"这种话不能说,这样做不对!"(负面反馈))
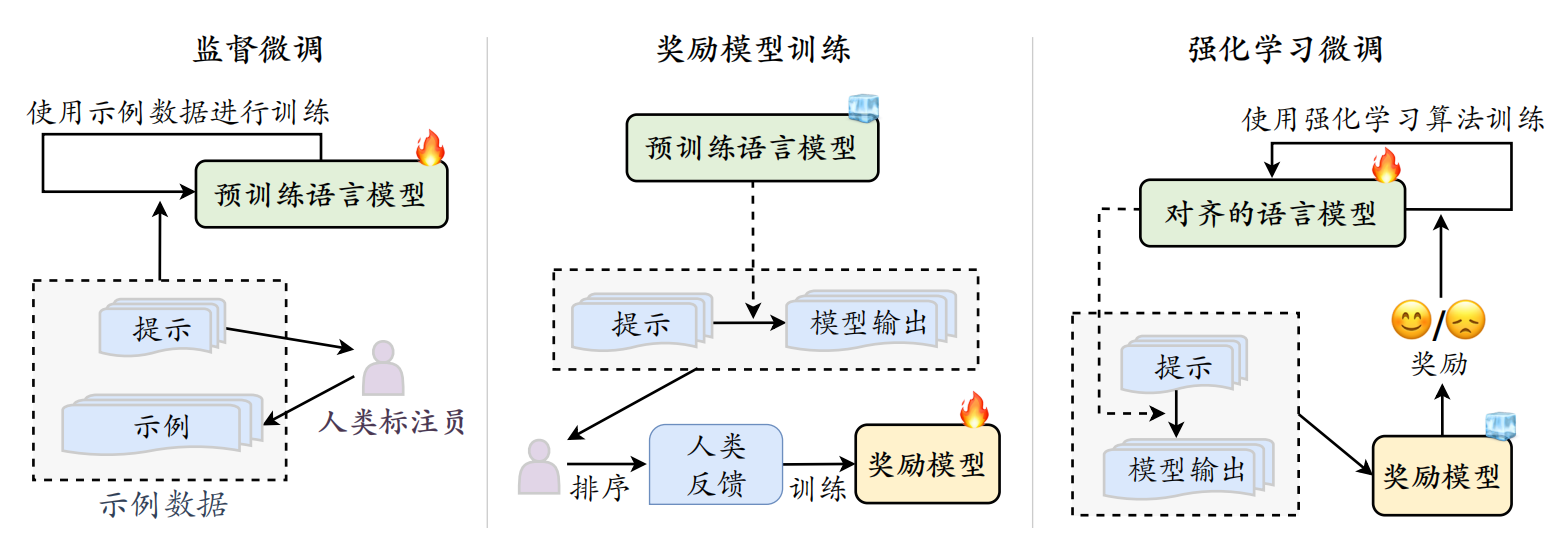
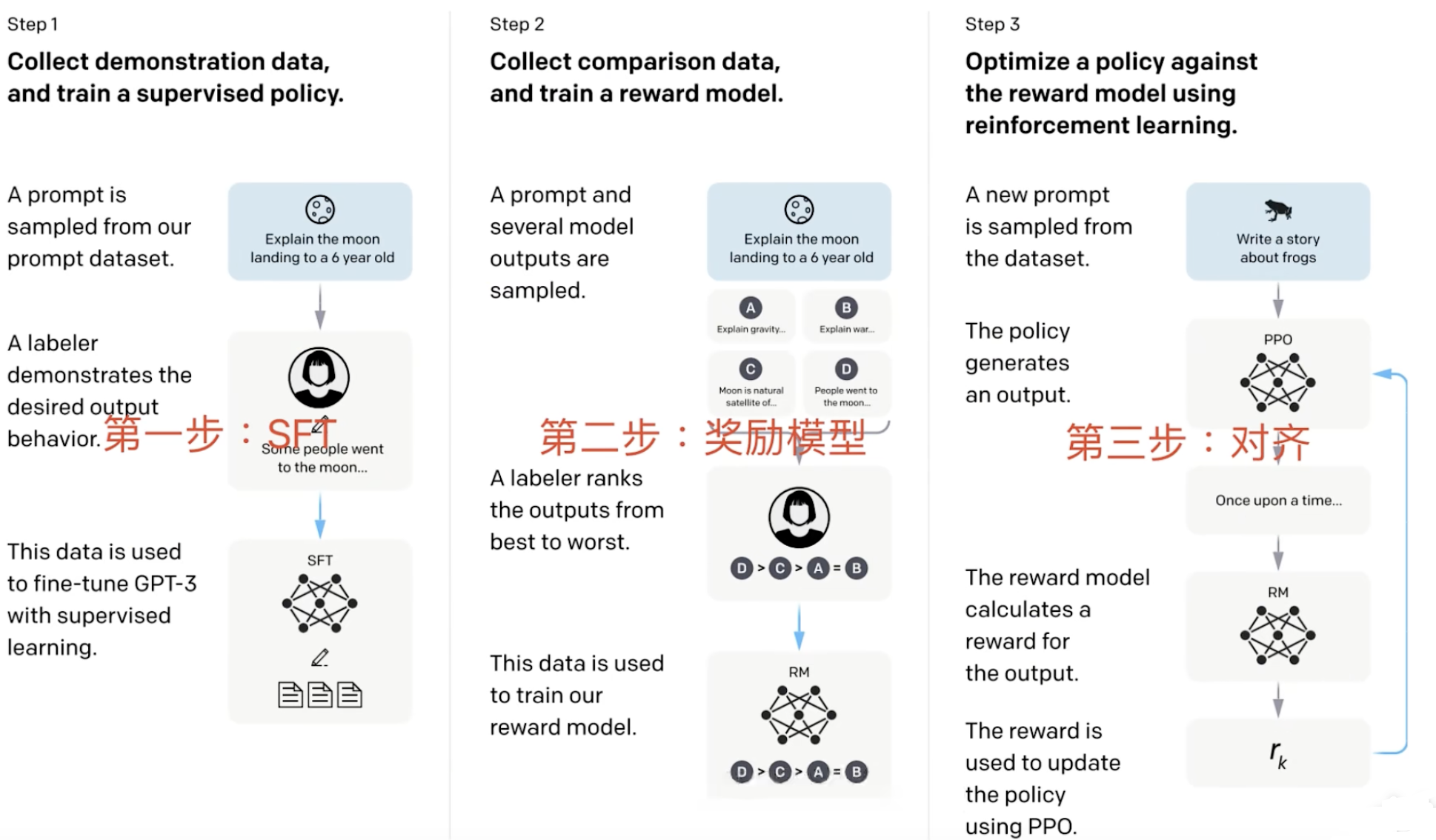
1)监督微调
-
目标: 让预训练好的大语言模型先学会按照指令进行对话和完成任务的基本能力。这是对齐的起点。
-
做法:
- 收集高质量的“指令-优质回答”数据对
- 用这些数据对预训练模型进行微调: 这和我们之前讲的指令微调类似,模型学习模仿这些优质的回答。
-
产出: 一个经过 SFT 的模型 (SFT Model),它已经具备了初步的指令遵循能力。
2)奖励模型训练
-
目标: 训练一个模型,让它学会评价 SFT 模型生成的回答的好坏,并给出一个“分数”(奖励值)。这个“AI裁判”要能代表人类的偏好。
-
做法:
-
收集人类偏好数据:
a. 让 SFT 模型针对同一个指令(提示)生成多个不同的回答 (比如 2-7 个)。 b. 让人类标注员对这些回答进行排序,选出哪个最好,哪个次好,哪个最差等等。这个排序就体现了人类的偏好。 -
训练奖励模型:
-
输入: 指令和一对模型生成的回答(一个好的回答 Y_w 和一个坏的回答Y_l)。
-
输出: 一个标量值,表示这对回答之间的偏好程度,或者直接是每个回答的“好坏分数”。
-
目标: 奖励模型要学会给人类偏好的回答打高分,给不偏好的回答打低分。
-
模型结构: 奖励模型通常也是一个大语言模型(比如 InstructGPT 用了一个 6B 的 GPT-3 模型作为 RM),只是它的最后一层被修改为输出一个标量奖励值,而不是词汇表的概率分布。
-
损失函数 ( 偏好对损失): 核心思想是最大化“好回答的奖励分数”与“坏回答的奖励分数”之间的差距。比如,如果 Y_w 比 Y_l 好,那么 r(Y_w) 应该大于 r(Y_l)
-
-
-
产出: 一个训练好的奖励模型 (RM),它可以为任何输入的“指令-回答”对打分,分数越高代表越符合人类偏好。
3)强化学习训练
-
目标: 利用训练好的奖励模型作为“环境反馈”,进一步优化 SFT 模型的行为,使其生成的回答能够获得更高的奖励分数(即更符合人类偏好)。
-
做法:
-
策略模型 (Policy Model): SFT 模型在这里扮演“策略模型”的角色,负责生成回答。
-
环境 (Environment): 接收策略模型生成的回答。
-
奖励 (Reward): 奖励模型 (RM) 对策略模型生成的回答进行打分,这个分数就是强化学习中的“奖励”。
-
强化学习算法 (如 PPO ): 根据奖励信号,调整策略模型(SFT 模型)的参数,使其倾向于生成能够获得更高奖励的回答
-
-
产出: 一个经过 RLHF 优化的最终模型 (RL Model),它生成的回答在“有用性、诚实性、无害性”方面通常比 SFT 模型有显著提升。
3、非强化学习的对齐方法
回归到更简单直接的监督微调 (Supervised Fine-tuning, SFT)。关键在于构建高质量的“对齐数据集”,并设计巧妙的监督学习算法,让模型直接从这些数据中学习到什么是“好”的,什么是“坏”的。所以要实现这种非 RL 的对齐,主要考虑两个关键要素:高质量对齐数据的收集 和 监督微调的对齐算法。
1)对齐数据的收集
- 基于奖励模型的方法
可以直接用这个训练好的 (奖励模型 RM)来给大量的模型输出打分。
-
让(如 SFT 后的)大语言模型针对各种输入生成响应。
-
用训练好的 RM 对这些响应进行评分。
-
根据分数高低,我们就能得到一批“好样本”(高分)、“中等样本”(中等分)、“差样本”(低分)。
-
这些带有“好坏标签”(分数)的数据就可以用于后续的监督微调,帮助模型学习区分不同质量的输出。
-
如果 RM 是基于偏好排序训练的,我们还可以用它来直接筛选出“明显更好”的输出。
- 基于大语言模型的方法
奖励模型虽然有用,但训练它本身也需要大量人工标注的偏好数据。让一个已经对齐得比较好或者能力非常强的大语言模型(比如 ChatGPT)直接来生成或评价数据
-
自我评价和修正 (Self-critique and Refinement) (如图 8.3):
-
让一个模型针对一个输入生成一个初始响应。
-
然后,让同一个模型或者另一个更强的模型对这个初始响应进行评价,指出其中的问题(比如不安全、不真实、不符合指令等)。
-
再让模型根据这个评价,修正原始的响应,生成一个更好的版本。
-
这样,我们就得到了一对数据:“(可能不太好的)初始响应” vs. “(经过评价和修正的)更好响应”。
-
-
直接生成符合特定标准的数据: 通过精心设计的提示 (Prompt),引导一个强大的语言模型直接生成符合特定对齐标准(如“无害”、“有用”)的“指令-回答”对。
2)监督对齐算法DPO (Direct Preference Optimization)
- 动机: RLHF 过程复杂,涉及多个模型的训练和不稳定的强化学习。DPO 试图找到一种更简单、更直接的方法,直接从人类的偏好数据(比如,对于同一个指令,回答 A 比回答 B 好)中学习,而不需要显式地训练一个奖励模型,也不需要强化学习。
- 核心思想: 将“学习奖励模型”和“用奖励优化策略模型”这两个步骤合并成一个单一的、基于监督学习的损失函数。它直接优化语言模型,使其更倾向于生成人类偏好的响应,同时降低生成人类不偏好的响应的概率。
- 与 RLHF 的关系: DPO 可以看作是 RLHF 目标的一种等价的、但更直接的优化形式。它巧妙地利用了强化学习理论中的一些关系,推导出了一种可以直接用偏好数据进行监督训练的损失函数。