NL2SQL代表,Vanna
Vanna 核心功能、应用场景与技术特性详解
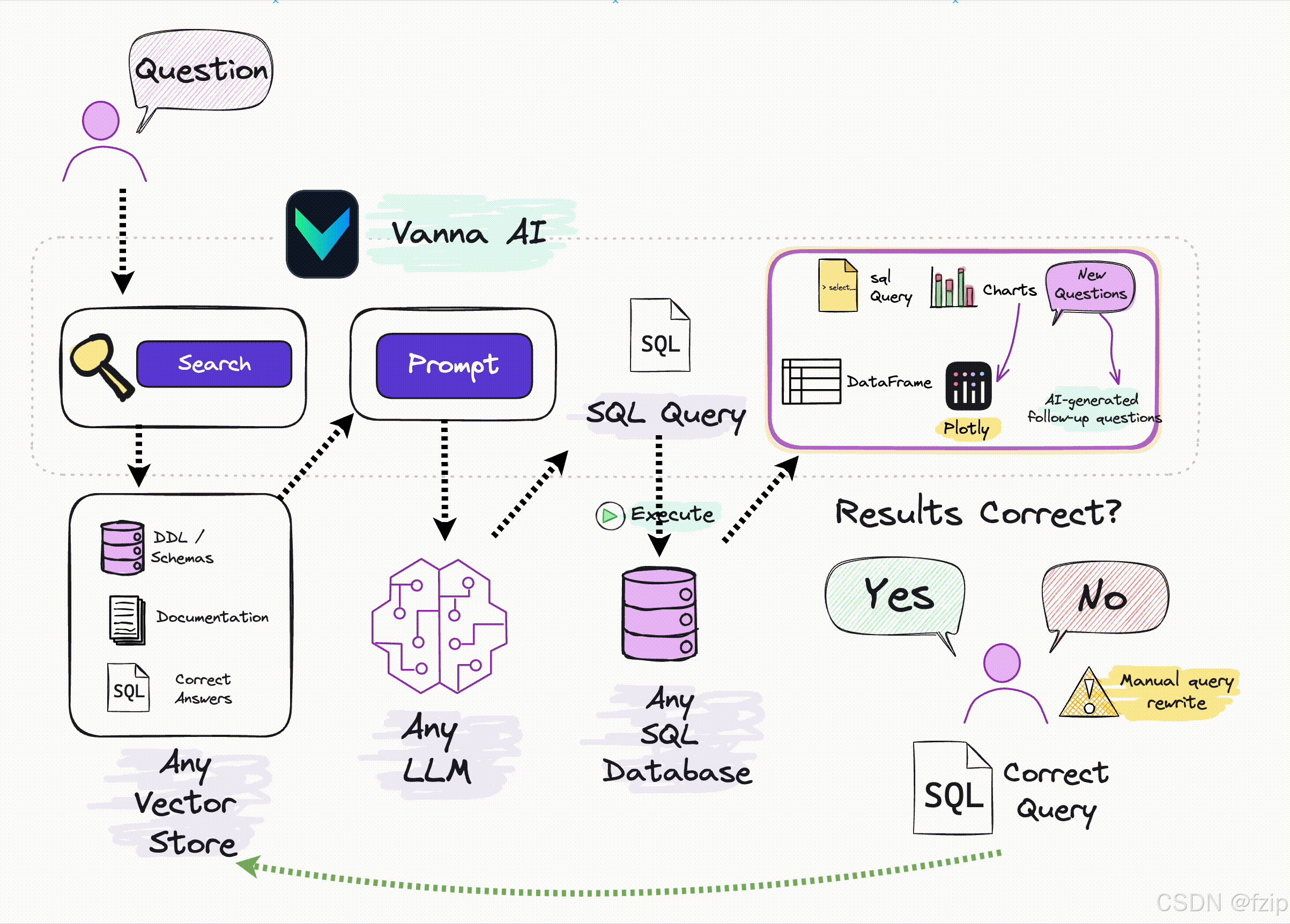
一、核心功能
1. 自然语言转SQL查询
Vanna 允许用户通过自然语言提问(如“显示2024年销售额最高的产品”),自动生成符合数据库规范的SQL查询语句。其底层采用 RAG(检索增强生成) 技术,结合向量数据库存储的上下文(表结构、历史查询模板)与大型语言模型(LLM)的生成能力,显著提升SQL准确性。测试数据显示,复杂场景下的生成准确率比传统LLM提升40%以上。
2. 多数据库兼容与自动执行
支持 PostgreSQL、Snowflake、BigQuery、DuckDB 等10+主流数据库,通过SQLAlchemy实现统一连接适配。生成的SQL可直接在目标数据库中执行,并返回结构化结果,避免人工复制粘贴操作。
3. 自动化数据可视化
集成Plotly等库,根据查询结果自动生成 交互式图表(如折线图、柱状图),支持导出CSV或对接Power BI等BI工具。例如,输入“各渠道ROI趋势”可同时获得SQL结果与趋势图。
4. 持续自学习机制
通过用户反馈(标记正确/错误SQL)、动态更新知识库(新增表结构)和社区贡献案例,实现模型性能的持续优化。某电商平台案例显示,人工修正比例从20%降至5%仅需3个月。
二、典型应用场景
| 场景分类 | 应用实例 | 价值体现 |
|---|---|---|
| 企业数据分析 | 销售经理输入“上月各地区销售额排名”,自动生成多表关联SQL并返回可视化报表 | 降低非技术人员使用门槛,缩短60%分析时间 |
| 教育与培训 | 教学平台构建SQL练习工具,学生提问后系统生成SQL并给出优化建议 | 帮助初学者理解SQL逻辑,提升学习效率 |
| 数据中台集成 | 低代码平台将Vanna作为底层引擎,用户通过拖拽配置生成ETL管道所需的复杂SQL | 简化数据管道开发,减少50%编码工作量 |
| 实时数据交互 | Slack/企业微信部署Vanna机器人,实时响应“当前库存预警产品有哪些”等业务查询 | 实现即时数据获取,增强团队协作效率 |
| 科研协作 | 研究团队在Jupyter Notebook中快速验证假设,通过auto_train积累领域特定查询模板 | 减少重复编码,聚焦数据洞察 |
三、关键技术特性
-
RAG架构突破传统LLM限制
- 检索阶段:向量数据库存储表结构、字段注释、历史优质SQL模板,实时匹配用户问题上下文
- 生成阶段:LLM(如GPT-4、Llama 2)基于检索结果生成语法规范的SQL,避免“幻觉”问题
- 效果:在涉及多表JOIN、窗口函数等复杂查询中,准确率比纯LLM方案提升超40%
-
模块化技术栈兼容性
- LLM支持:OpenAI、Anthropic、Hugging Face等主流模型,可本地部署Ollama框架
- 向量数据库:Chroma(轻量级)、Milvus(分布式)、Azure Search(企业级)自由切换
- 部署架构:单机脚本快速验证概念,支持横向扩展至每秒数千次高并发查询
-
企业级安全与隐私
- 数据隔离:SQL在用户本地环境执行,仅向LLM发送脱敏元数据(如表名)
- 权限控制:RBAC机制限制用户访问范围,审计日志记录所有查询操作
- 合规认证:满足金融/医疗领域数据治理要求,支持私有化部署
-
开发者友好生态
- 多终端界面:提供Jupyter、Streamlit、Flask、Slack等现成模板,5分钟即可搭建查询工具
- API设计:
vn.ask("问题")单一接口封装复杂逻辑,支持错误重试与语法校验 - 社区驱动:开源社区贡献案例持续丰富公共知识库,加速跨行业适配
四、技术架构与扩展性
-
分层架构设计
-
扩展能力
- 自定义LLM:通过继承
VannaBase类集成私有化模型 - 插件系统:开发数据清洗、异常检测等扩展模块
- 混合云部署:适配AWS/GCP/Azure云原生服务,支持Kubernetes集群管理
- 自定义LLM:通过继承
五、安装与快速入门
-
基础环境搭建
# 安装核心包与MySQL适配组件 pip install vanna[mysql,openai] -
初始化配置
from vanna.openai import OpenAI from vanna.chromadb import ChromaDB_VectorStoreclass MyVanna(ChromaDB_VectorStore, OpenAI):def __init__(self, config=None):ChromaDB_VectorStore.__init__(self, config=config)OpenAI.__init__(self, config=config)vn = MyVanna(config={"api_key": "sk-...", "model": "gpt-4"}) -
训练与使用
# 注入领域知识 vn.train(ddl="CREATE TABLE sales (id INT, product VARCHAR(50), amount DECIMAL(10,2))")# 自然语言查询 result = vn.ask("2024年销售额最高的前5个产品是什么?") print(result.sql) # 输出生成SQL result.plot() # 显示可视化图表
六、未来发展方向
- 增强型自然语言理解:支持多轮对话修正查询条件
- 智能优化建议:自动推荐索引优化、查询性能调优方案
- 跨模态交互:结合语音输入与AR/VR数据展示
- 行业解决方案:预置零售、金融、医疗等垂直领域知识包
Vanna通过 开源协作+企业级功能 的双轮驱动模式,正在重塑数据查询范式。其设计平衡了易用性与专业性,既适合个人开发者快速验证想法,也能满足大型组织复杂的数据治理需求。