阿里千问系列:Qwen3技术报告解读(上)

- 技术报告下载链接:Qwen3 Technical Report
- Github链接:https://github.com/QwenLM/Qwen3
模型概述
Qwen3是Qwen系列的最新模型,其包含密集型和混合专家(MoE)架构的一系列大语言模型,参数规模从6亿到2350亿不等。其核心创新在于将思考模式(复杂多步推理)和非思考模式(快速上下文响应)整合到统一框架中,支持根据用户查询动态切换模式,并引入思考预算机制在推理过程中自适应分配计算资源,平衡延迟与性能。同时,与前身 Qwen2.5 相比,Qwen3 的多语言支持从 29 种扩展到 119 种语言和方言,通过改进的跨语言理解和生成能力增强了全球可访问性。
相关背景
追求通用人工智能(AGI)或超级人工智能(ASI)长期以来一直是人类的目标。大型基础模型的最新进展,如 GPT-4o(OpenAI,2024)、Claude 3.7(Anthropic,2025)、Gemini 2.5(DeepMind,2025)、DeepSeek-V3(Liu 等人,2024)、Llama-4(Meta-AI,2025)和 Qwen2.5(Yang 等人,2024),已在实现这一目标方面取得了显著进展。
这些模型在跨越数万亿 token 的海量数据集上训练,有效将人类知识和能力提炼到参数中。此外,通过强化学习优化的推理模型(如 o3(OpenAI,2025)、DeepSeek-R1(Guo 等人,2025))的最新发展,凸显了基础模型提升推理时扩展能力和实现更高智能水平的潜力。
模型架构
如表中所示,Qwen3 系列包括 6 个密集型模型以和 2 个 MoE 模型 Qwen3-30B-A3B 和 Qwen3-235B-A22B。旗舰模型 Qwen3-235B-A22B 总参数为 2350 亿,其中每个 token 激活 220 亿参数。
Qwen3 密集型模型的架构与 Qwen2.5类似,包括使用分组查询注意力(GQA,2023)、SwiGLU(2017)、旋转位置嵌入(RoPE,2024)和带预归一化的 RMSNorm(2023)。此外,还移除了 Qwen2 中使用的 QKV 偏差,并在注意力机制中引入 QK-Norm(2023)以确保 Qwen3 的稳定训练。模型架构的关键信息见表 1。
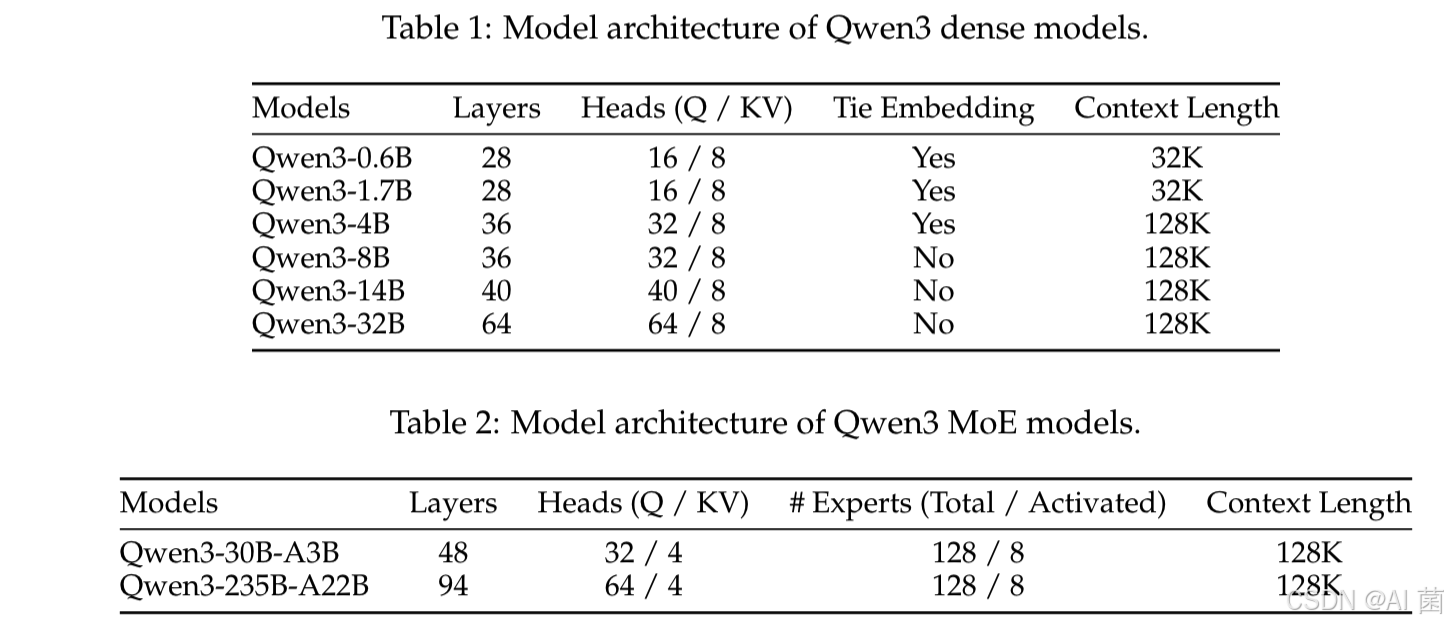
Qwen3 MoE 模型与 Qwen3 密集型模型共享相同的基础架构。模型架构的关键信息见表 2。Qwen3 MoE 模型共有 128 个专家,每个 token 激活 8 个专家。与 Qwen2.5-MoE 不同,Qwen3-MoE 设计中不包含共享专家。此外,Qwen3 MoE 采用全局批量负载均衡损失(2025)来促进专家专业化。这些架构和训练创新已在下游任务中显著提升了模型性能。
关键改进
-
双模式整合
- 将思考模式(复杂多步推理)和非思考模式(快速上下文响应)整合到统一框架中,无需在专用推理模型(如QwQ32B)和对话优化模型(如GPT-4o)间切换,通过聊天模板或用户查询动态激活模式。
- 思考预算机制允许用户指定推理token长度,自适应分配计算资源,提升复杂任务性能。
-
多语言扩展
- 支持从29种语言扩展至119种语言及方言,预训练数据包含36万亿token,覆盖多语言文本、代码、STEM等领域,提升跨语言理解与生成能力。
-
架构优化
- 密集模型沿用Qwen2.5架构(GQA、SwiGLU、RoPE等),引入QK-Norm稳定训练;MoE模型采用128个专家,每token激活8个专家,提升推理效率。
- 旗舰模型Qwen3-235B-A22B为MoE架构,总参数2350亿,每token激活220亿参数,兼顾性能与效率。
-
训练策略
- 三阶段预训练:
① 通用阶段(30万亿token,4096上下文); 建立语言能力,学习通用世界知识。
② 推理阶段(5万亿token,增强STEM和编码数据); 进一步提高推理能力。
③ 长上下文阶段(百亿token,32768上下文),采用YARN和DCA技术扩展序列长度。 - 多阶段后训练:通过长CoT冷启动、推理RL、模式融合、通用RL逐步提升推理与对齐能力,轻量级模型采用强弱蒸馏,利用大模型知识降低计算成本。
- 三阶段预训练:
性能表现
-
基准测试
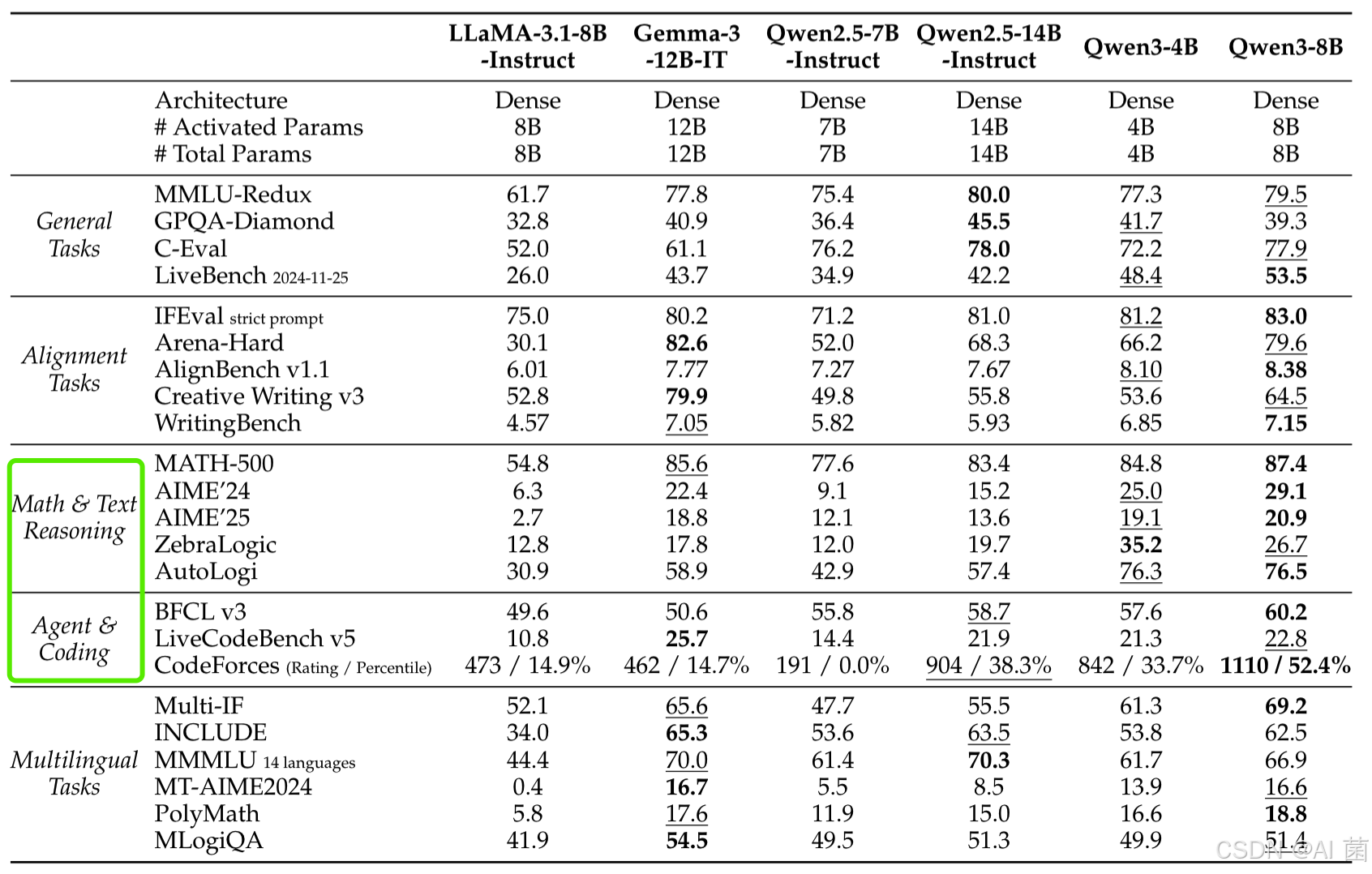
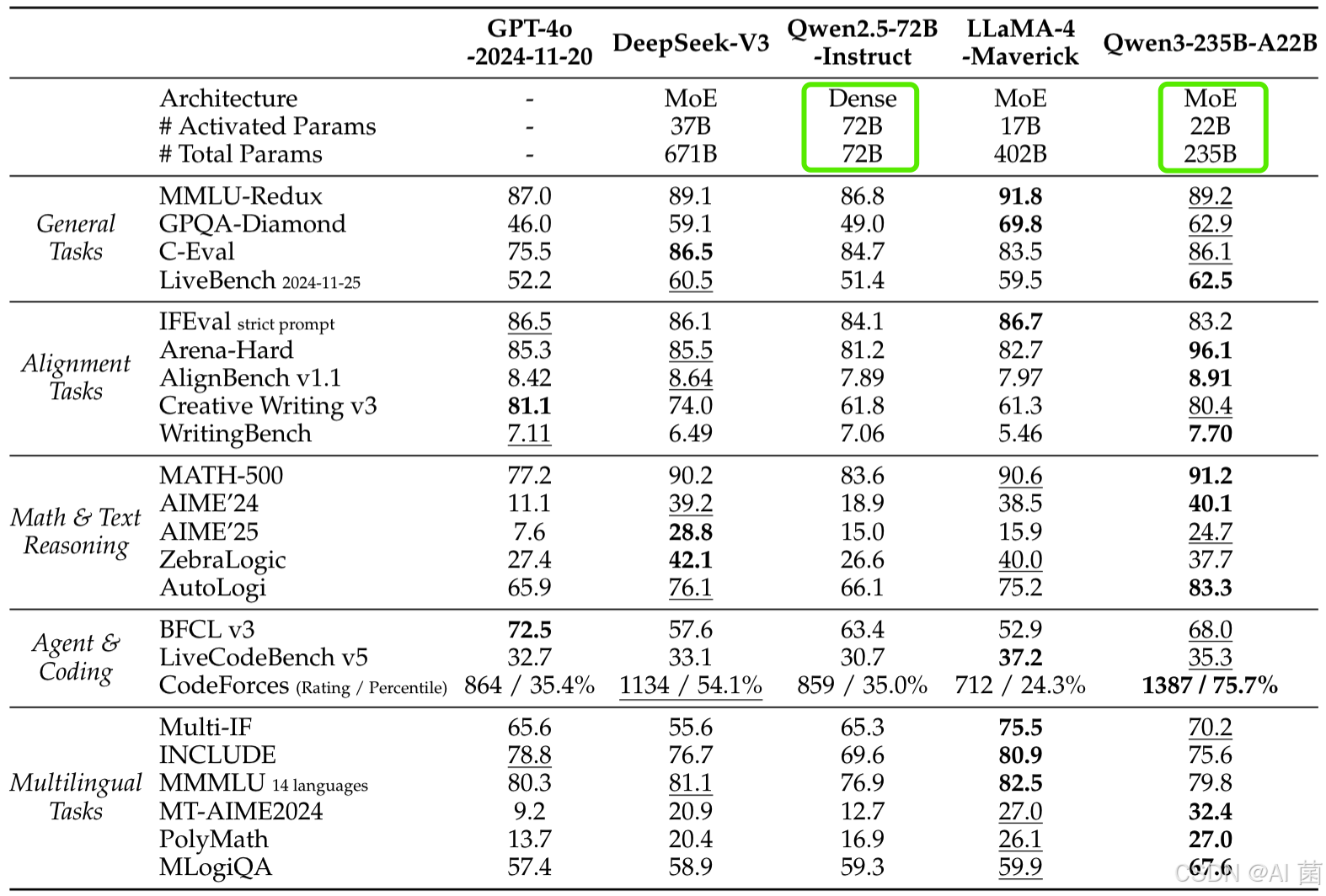
- 推理任务:旗舰模型在AIME’24(85.7)、LiveCodeBench v5(70.7)等基准领先,超越DeepSeek-R1、Llama-4等开源模型,接近OpenAI-o1、Gemini2.5-Pro等闭源模型。
- 多语言任务:在MGSM、MMMLU等基准中表现优异,支持55种语言的数学推理(MT-AIME24),跨语言性能显著提升。
- 轻量级模型:如Qwen3-8B在编码和数学任务中超越Qwen2.5-14B,体现蒸馏效果。
-
效率优势
- MoE模型以更少的激活参数(如Qwen3-235B-A22B仅220亿激活参数)实现与密集模型相当性能,降低推理成本。
- 强弱蒸馏使小模型(如Qwen3-0.6B)性能接近更大规模旧模型,GPU训练成本仅为RL的1/10。
开源与未来方向
- 开源协议:所有模型基于Apache 2.0开源,支持学术与商业使用。
- 未来计划:进一步扩大高质量预训练数据,优化模型压缩与长上下文能力,强化基于环境反馈的代理RL系统,提升复杂任务处理能力。
总结
Qwen3通过双模式整合、多语言扩展和高效训练策略,成为当前开源大模型中的领先者,在推理、编码、多语言等任务中表现卓越,为通用AI研究与应用提供了强大的工具。