基础深度补全模型DepthLab: From Partial to Complete
许多任务本身就包含部分深度信息,例如:(1)三维高斯图像修复;(2)激光雷达深度补全;(3)利用 Dust3R 进行稀疏视角重建;以及(4)文本到场景的生成。而DepthLab模型能利用这些已知信息来实现更优的深度估计,提升下游任务的性能表现。

论文地址:[2412.18153] DepthLab: From Partial to Complete
项目地址: GitHub - ant-research/DepthLab: Official implementation of "DepthLab: From Partial to Complete"
Abstract
DepthLab一个基于图像扩散先验的基础深度修复模型,它能够有效应对在深度数据的广泛应用中的数据缺失问题。数据缺失问题在许多任务中非常常见,其根源在于数据采集不完整、视角变化等多种因素。DepthLab模型有两个显著优势:
1.它对深度缺失区域具有很强的适应性,能够为连续区域和孤立点提供可靠的修复结果。
2.在填充缺失值时,它能够最大程度上保持与已知深度条件下的尺度一致性。
凭借这些优势,此方法在各种下游任务中证明了其价值,包括三维场景修复、文本到三维场景生成、利用 DUST3R 进行的稀疏视角重建,以及激光雷达深度补全,在数值性能和视觉质量方面均超越了当前的解决方案。
1. Introduction
深度修复,即重建图像中缺失或被遮挡的深度信息这一任务,在众多领域中都至关重要,这些领域包括三维视觉 、机器人学 以及增强现实。一个强大的深度修复模型能够实现高质量的三维场景补全、编辑、重建和生成(如上图的DepthLab模型)。先前关于深度修复的研究主要可分为两种方法:
第一种方法专注于将全局稀疏的激光雷达深度数据补全为密集深度,通常在固定的数据集上进行训练和测试。然而,这些模型缺乏泛化能力,在各种不同的下游任务中的适用性也有限。
第二种方法采用单目深度估计器来推断单张图像的深度,使修复区域与已知深度对齐。
由于估计深度与现有几何结构之间的不对齐,这些方法常常存在显著的几何不一致性,尤其是在边缘处。最近的研究将 RGB 图像作为指导纳入到 UNet 的输入中以训练深度修复模型,但在复杂场景以及修复大面积缺失区域时,其性能仍不理想。
而DepthLab是一个用于 RGB 图像条件下深度修复的基础模型,它引入了一个双分支深度修复扩散框架。具体而言,该框架通过一个参考 U 型网络(Reference U-Net)处理单张参考图像,该网络提取 RGB 特征作为条件输入。同时,已知深度信息和指示需要修复区域的掩码被输入到深度估计 U 型网络(Depth Estimation U-Net)中。提取的 RGB 特征会逐层逐步地整合到深度估计 U 型网络中,以指导修复过程。在训练期间,对已知深度应用随机尺度归一化,以减轻由已知区域中的非全局极值引起的正则化溢出问题。此模型训练仅需几天的 GPU 时间,使用合成的 RGBD 数据进行训练即可。得益于扩散模型强大的先验知识,DepthLab在各种不同的场景中都展现出了很强的泛化能力。
并且由上图所示,DepthLab已经在许多下游任务中取得了出色的成果。
1.三维场景修复:在三维场景中,首先从已定位的参考视图对图像修复区域的深度进行修复,然后将这些点反投影到三维空间中以进行最优初始化,这显著提高了三维场景修复的质量和速度。
2.文本到场景生成:通过消除对齐的方法,大幅改进了从单张图像生成三维场景的过程。这一进展有效地缓解了先前因修复深度与已知深度之间的几何不一致而导致的边缘不连贯问题,从而显著提高了生成场景的连贯性和质量。
3.使用 DUST3R 进行稀疏视角重建:InstantSplat利用来自 DUST3R的点云作为无结构光运动(SfM)重建和新视角合成的初始化。通过向 DUST3R 深度图添加噪声作为潜在输入,来对缺乏跨视角对应关系的区域的深度进行优化,生成更精确、几何一致的深度图。这些优化后的深度图进一步提升了 InstantSplat 的初始点云质量。
(InstantSplat论文地址:[2403.20309] InstantSplat: Sparse-view Gaussian Splatting in Seconds)
4.激光雷达深度补全:传感器深度补全是与深度估计相关的一项重要任务。与在单个数据集(如 NYUv2)上进行训练和测试的现有方法不同,此方法在零样本设置下取得了可比的结果,并且只需进行极少的微调就能获得更好的效果。为了进行更全面的评估,通过对需要修复的区域应用各种类型的随机掩码,在深度估计基准上评估了其有效性。
2. Method
给定一个原始的(不完整或失真的)深度图、一个指示待修复目标区域的二值掩码,以及一张条件 RGB 图像,目标是利用这张 RGB 图像来预测出一张完整的深度图。这需要在保留未掩码区域深度值的同时,准确估计掩码区域的深度。这个过程自然地使估计的深度与现有的几何结构对齐,消除已知区域和目标修复区域之间的不一致性。
为了实现这一目标,DepthLab引入了一个基于双分支扩散的深度修复框架,该框架包含一个用于提取 RGB 特征的参考 U 型网络(Reference U-Net),以及一个以原始深度图和修复掩码为输入的估计 U 型网络(Estimation U-Net)。作者没有使用常用的文本条件,而是通过 CLIP 图像编码器的交叉注意力机制来捕捉丰富的语义信息。通过参考 U 型网络和估计 U 型网络之间的注意力机制进行逐层特征融合,从而实现更细粒度的视觉引导。
以下是DepthLab的pipline:
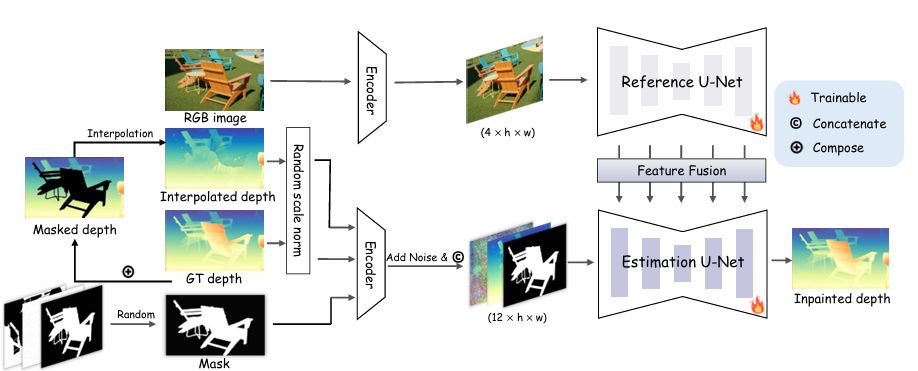
2.1. Network Design
两个分支都使用了 Marigold模型 [31] 作为基础模型,该模型是在 “稳定扩散 V2”(Stable Diffusion V2)模型 [56] 的基础上进行微调得到的。这种设计无需学习从 RGB 到深度的转换,从而提高了训练效率。下面给出了每个网络的详细架构。
(Stable Diffusion V2论文地址:[2112.10752] High-Resolution Image Synthesis with Latent Diffusion Models
Marigold论文地址:[2312.02145] Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
)
Depth encoder and decoder.使用一个固定的变分自编码器(VAE)编码器 E,将 RGB 图像及其对应的深度图编码到潜空间中。由于编码器 E 最初是为三通道 RGB 输入设计的,因此单通道深度图会在三个通道上复制,以匹配 RGB 格式。值得注意的是,由于 VAE 编码器是为非稀疏输入设计的,所以作者在编码前应用最近邻插值来密集化稀疏深度图。在推理过程中,使用解码器 D 对步骤 t=0 时去噪后的深度潜变量 z (d)₀∈R⁴ˣʰˣʷ进行解码,并将三个通道的平均值用作预测的深度图。与估计相对深度并使用最小二乘法优化来获得度量深度的 Marigold 不同,DepthLab的深度修复旨在基于已知深度区域的值和尺度直接估计度量深度图。
Estimation U-Net.估计去噪 U 型网络(Estimation Denoising U-Net)的输入由三个部分组成:含噪深度潜变量、掩码深度潜变量
以及编码后的掩码
,这三个部分在通道维度上进行拼接。经过 VAE 编码后,潜空间中的深度表示具有 4 个通道,其空间维度(h,w)相较于原始输入维度(H,W)被下采样了 8 倍。值得注意的是,为了更精确地保留掩码信息,作者没有像传统图像修复方法那样简单地对掩码进行下采样,而是使用 VAE 编码器 E 对原始掩码
进行编码,得到
,这种方式能够有效保留掩码中的稀疏和细粒度信息。
在训练过程中,含噪深度潜变量zt(d)通过将初始深度图d编码到潜空间后,在第t步添加噪声得到。掩码深度潜变量z(d′)则是通过对原始真实深度图应用随机掩码,然后在修复区域进行最近邻插值,并通过 VAE 编码生成。由于 Stable Diffusion 的 VAE 在重建密集信息方面表现出色,这种方法能够更好地保留稀疏点和复杂边缘边界处的已知深度值。
Reference U-Net.InFusion方法将单张参考图像输入编码器,随后将图像潜在特征与含噪深度潜在特征、掩码深度潜在特征以及下采样后的掩码进行拼接,最终得到一个包含 13 个通道的特征。然而,这种方法可能会丢失区域深度信息,或者在生成清晰的深度边缘时遇到困难,尤其是在进行大面积图像修复或使用复杂参考图像时。当时的研究表明,额外使用一个 U 型网络(U-Net)可以从参考图像中提取更精细的特征。受这些研究结果的启发,DepthLab采用了类似的架构。
首先分别从参考 U 型网络(Reference U-Net)和估计去噪 U 型网络(Estimation Denoising U-Net)中获取两个特征图,即 和
。然后,沿着w维度将这两个特征图进行拼接,得到
。接下来,对拼接后的特征图执行自注意力操作,并提取结果特征图的前半部分作为输出。这样一来,我们在训练过程中就能够利用基础模型各层的精细语义特征。
此外,由于参考 U 型网络和估计去噪 U 型网络具有相同的架构和初始权重 (二者均在 Marigold 数据集上进行了预训练) , 估计去噪 U 型网络可以在相同的特征空间内有选择地从参考 U 型网络中学习相关特征。
2.2. Training Protocol(训练方案)
Depth normalization.在推理过程中,由于修复区域的深度是未知的,我们无法确定整个深度图的最小和最大深度值。为了在训练期间模拟这种情况,先计算已知深度区域的最小值和最大值(dmin和dmax),并将它们线性归一化到 [-1, 1] 的范围内。值得注意的是,局部最小值和最大值可能并不总是与全局最小值和最大值相对应,这可能会在变分自编码器(VAE)解码过程中导致溢出。为了解决这个问题,在归一化过程中引入一个范围在 [0.2, 1.0] 内的随机压缩因子 β,以便更有效地处理这些情况。深度值使用以下公式进行归一化:
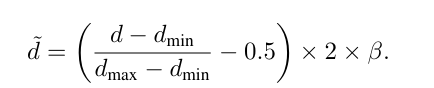
这种方法遵循了稳定扩散变分自编码器(Stable Diffusion VAE)的规则,同时也强制实现了一种规范的、仿射不变的深度表示,该表示与数据统计无关。这确保了深度值受到近平面和远平面的约束,提供了稳定性并减少了数据分布的影响。最后对网络输出应用反归一化操作,以恢复绝对深度尺度并实现深度修复。
Masking strategy.为了在大量的下游任务中实现最大程度的覆盖,这里采用了多种掩码策略。首先从线条、圆形、正方形或者这些形状的随机组合中随机选择来创建掩码。其次,为了增强深度补全任务(即从传感器捕获的稀疏深度数据中恢复出完整的深度图),作者实施了随机点掩码策略,在这种策略下,只有 0.1% 到 2% 的点被设置为已知点。最后,为了改进对于目标级别的修复,使用基于区域的 Segment Anything Model(Grounded-SAM) 来标注训练数据,随后根据掩码的置信度分数对其进行筛选。总的来说,多种掩码策略的联合应用进一步增强了此方法的鲁棒性。
(Grounded-SAM:[2401.14159] Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks)
3.Experiments
1.使用了两个涵盖室内和室外场景的合成数据集来训练DepthLab。第一个数据集是超仿真数据集Hypersim,这是一个具有照片级真实感的数据集,包含 461 个室内场景。作者从中选取了 365 个场景,在剔除不完整的样本后,总共约有 54,000 个训练样本。第二个数据集是Virtual KITTI,这是一个合成的街道场景数据集,包含五个具有不同条件(如天气和相机视角)的场景。作者使用了其中的 4 个场景,大约有 20,000 个训练样本。
(Virtual KITTI:[2001.10773] Virtual KITTI 2)
2.使用来自Marigold的预训练权重来初始化参考 U 型网络(Reference U-Net)和估计 U 型网络(Estimation U-Net)。其他预训练权重请参见原文补充材料。训练过程共进行 200 个轮次(epochs),初始学习率为 1e-3。每 50 个轮次后,学习率会按计划衰减。作者这里仅使用随机翻转作为数据增强的方式。利用八块 A100-80G 的图形处理器(GPU),训练过程在两天内完成。
4.Future Work
1.采用一致性模型或基于流的方法来加快采样速度。
(Consistency Models:[2303.01469] Consistency Models
Flow Matching for Generative Modeling:[2210.02747] Flow Matching for Generative Modeling
Rectified Diffusion:[2410.07303] Rectified Diffusion: Straightness Is Not Your Need in Rectified Flow
)
2.进一步微调现有的图像变分自动编码器(VAE),以便更有效地对稀疏信息进行编码,比如稀疏掩码和深度信息。
3.将这种修复技术扩展到法向量估计模型中,这能够促进对不同三维属性进行更多样化的编辑。