lmm-r1开源程序是扩展 OpenRLHF 以支持 LMM RL 训练,用于在多模态任务上重现 DeepSeek-R1
一、软件介绍
文末提供程序和源码下载学习
lmm-r1开源程序是扩展 OpenRLHF 以支持 LMM RL 训练,用于在多模态任务上重现 DeepSeek-R1。
二、简介
小型 3B 大型多模态模型(LMMs)由于参数容量有限以及将视觉感知与逻辑推理相结合的固有复杂性,在推理任务上存在困难。高质量的跨模态推理数据也相对稀缺,进一步增加了训练的复杂性。为了解决这些挑战,我们提出了 LMM-R1,一个两阶段的基于规则的强化学习框架,该框架能够有效地增强推理能力:
- 基础推理增强(FRE):利用纯文本数据建立强大的推理基础
- 多模态泛化训练(MGT):将这些能力扩展到多模态领域
这种方法克服了数据限制,同时在各种推理任务中显著提高了性能。
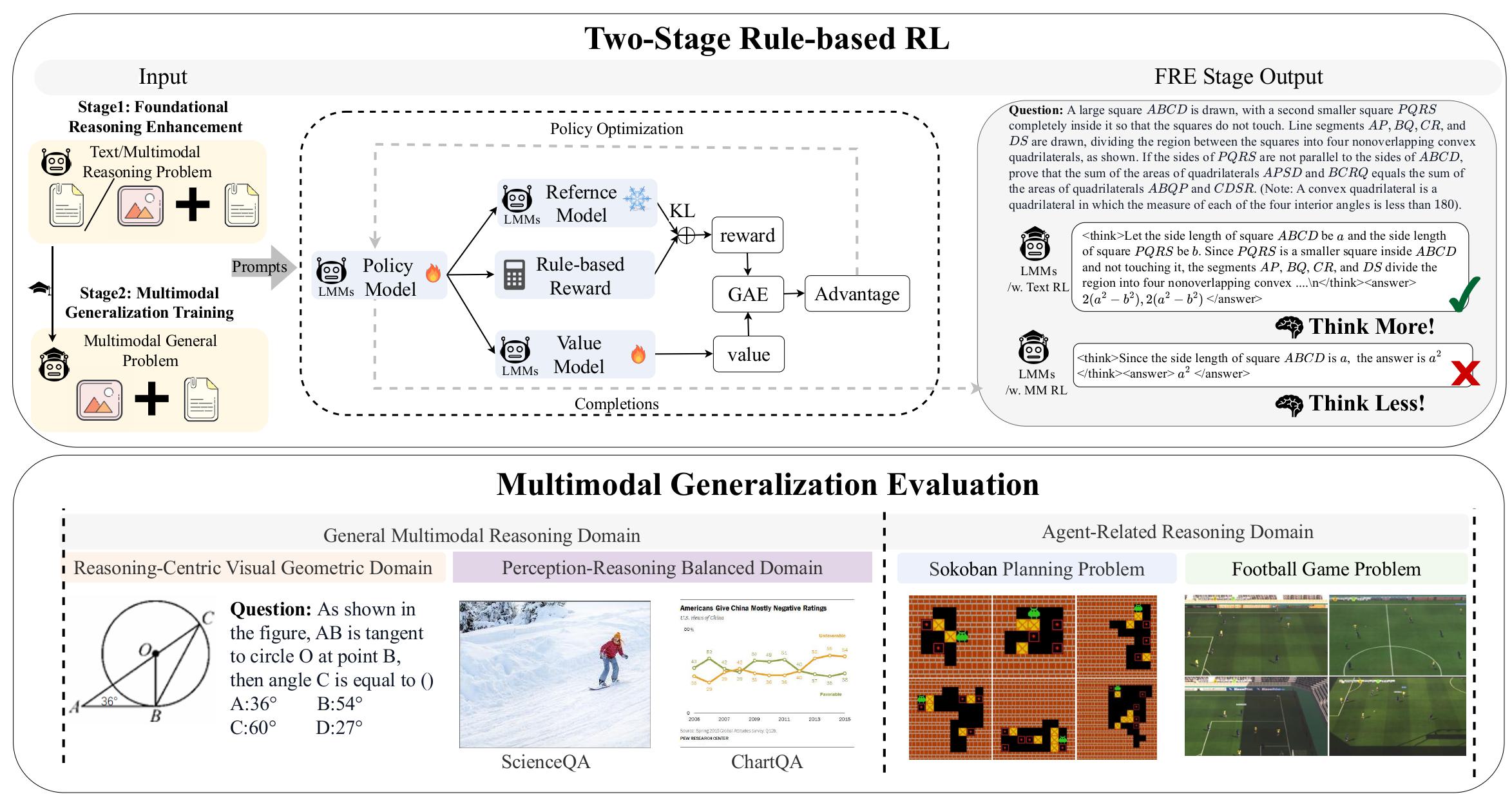
三、Demo 演示
Geometry Question: 几何问题:

Sokoban Demo: Sokoban 演示
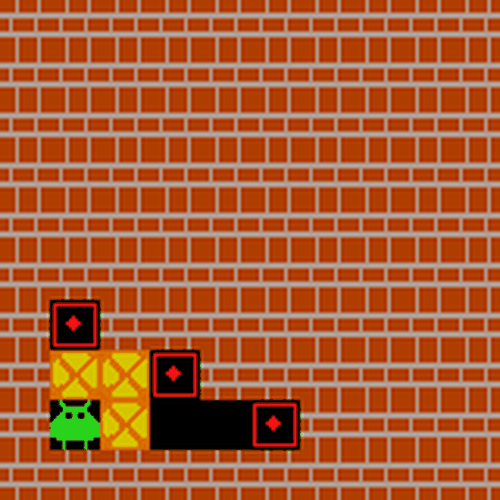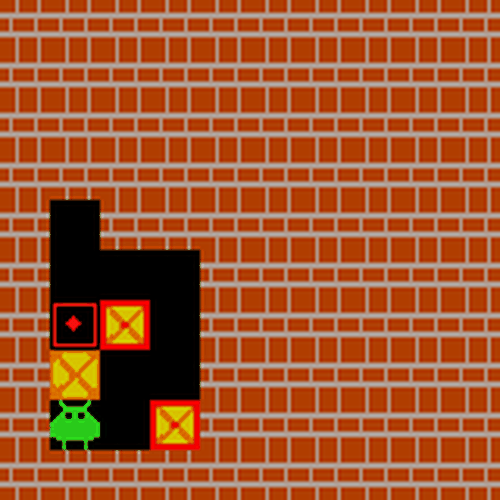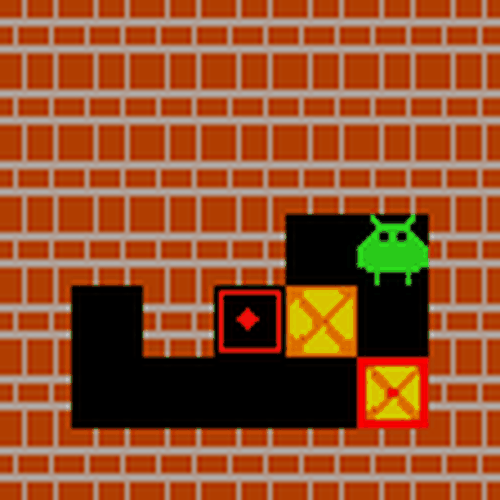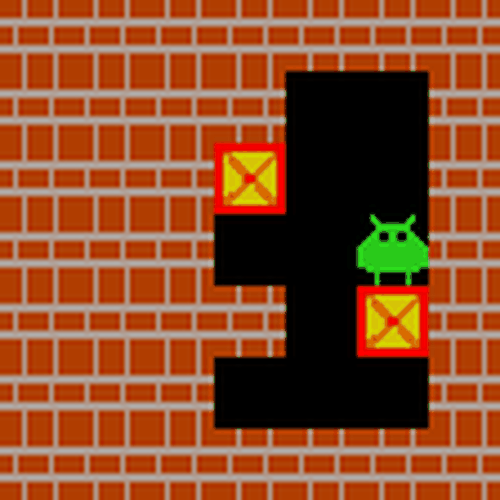
四、Quick Start 快速开始
Installation 安装(源码文末下载)
git clone https://github.com/TideDra/lmm-r1.git
cd lmm-r1
pip install -e .[vllm]
pip install flash_attn --no-build-isolation
Note 注意
We recommend using vLLM 0.7.2 or higher. We also provided the Dockerfiles for vLLM and One-Click Installation Script of Nvidia-Docker.
我们推荐使用 vLLM 0.7.2 或更高版本。我们还提供了 vLLM 的 Dockerfile 以及 Nvidia-Docker 的一键安装脚本
Prepare Datasets 准备数据集
LMM-R1 需要多模态提示数据集以 OpenAI 兼容的消息格式:
[{"message":"[{\"role\": \"user\",\"content\": [{ \\"type\": \"image\",\"image\": \"file:///path/to/your/image.jpg\",}, \{\"type\": \"text\", \"text\": \"How many cats in the image?\"},],}]","answer": "$3$"},
]
Note that message is a stringfied list. An example dataset examples/data/test_message.jsonl is for reference.
请注意,消息是一个字符串化的列表。示例数据集 examples/data/test_message.jsonl 仅作参考。
- We can use
--input_keyto specify theJSON key nameof the input datasets--prompt_data {name or path}(PPO) or--dataset {name or path}. Do not use--apply_chat_templatefor multimodal prompt, the message will be processed internally.
我们可以使用--input_key来指定输入数据集--prompt_data {name or path}(PPO)或--dataset {name or path}的JSON key name。不要使用--apply_chat_template作为多模态提示,消息将内部处理。 - OpenRLHF also support mixing multiple datasets using
--prompt_data_probs 0.1,0.4,0.5(PPO) or--dataset_probs 0.1,0.4,0.5.
OpenRLHF 还支持使用--prompt_data_probs 0.1,0.4,0.5(PPO)或--dataset_probs 0.1,0.4,0.5混合多个数据集。
Training 训练
Our training process follows the two-stage approach described in the paper. We provide scripts for each stage to facilitate reproduction of our results.
我们的训练过程遵循论文中描述的两阶段方法。我们为每个阶段提供脚本,以方便重现我们的结果。
Stage 1: Foundational Reasoning Enhancement (FRE)
阶段 1:基础推理增强(FRE)
This stage focuses on enhancing the model's reasoning capabilities using text-only data.
该阶段侧重于使用纯文本数据增强模型的推理能力。
# Train with text-only data (FRE-Text)
bash examples/scripts/lmm_r1/train_fre_text.sh# Train with multimodal data (FRE-Multi) for comparison
bash examples/scripts/lmm_r1/train_fre_multi.sh
The FRE-Text script uses the DeepScaler-40K dataset with rule-based RL to enhance the model's foundational reasoning capabilities. This stage is crucial for establishing strong reasoning abilities before moving to multimodal tasks.
FRE-Text 脚本使用 DeepScaler-40K 数据集,通过基于规则的强化学习来增强模型的基础推理能力。这一阶段对于在转向多模态任务之前建立强大的推理能力至关重要。
Stage 2: Multimodal Generalization Training (MGT)
阶段 2:多模态泛化训练(MGT)
This stage extends the reasoning capabilities to multimodal domains through continued training on specific tasks.
此阶段通过在特定任务上持续训练,将推理能力扩展到多模态领域。
# Train on geometry domain (MGT-Geo)
bash examples/scripts/lmm_r1/train_mgt_geo.sh# Train on perception-reasoning balanced domain (MGT-PerceReason)
bash examples/scripts/lmm_r1/train_mgt_percereas.sh
Each MGT script continues training from the FRE-Text checkpoint, focusing on a specific domain:
每个 MGT 脚本从 FRE-Text 检查点继续训练,专注于特定领域:
- MGT-Geo: Uses VerMulti-Geo dataset (15K geometry problems) to enhance geometric reasoning
MGT-Geo:使用 VerMulti-Geo 数据集(15K 几何问题)来增强几何推理 - MGT-PerceReason: Uses the full VerMulti dataset to balance perception and reasoning capabilities.
MGT-PerceReason:使用完整的 VerMulti 数据集来平衡感知和推理能力。
We release our final model, MGT-PerceReason.
我们发布了我们的最终模型,MGT-PerceReason。
Direct RL Training (for comparison)
直接 RL 训练(用于比较)
We also provide scripts for direct RL training without the FRE stage, which we use as comparison baselines in our paper:
我们还提供了没有 FRE 阶段的直接 RL 训练脚本,我们在论文中将这些脚本用作比较基线:
# Direct RL training on geometry domain
bash examples/scripts/lmm_r1/train_direct_rl_geo.sh
These scripts train the baseline model directly on domain-specific data, skipping the FRE stage, which helps demonstrate the effectiveness of our two-stage approach.
这些脚本直接在特定领域的数据上训练基线模型,跳过了 FRE 阶段,有助于证明我们两阶段方法的有效性。
五、Features 功能
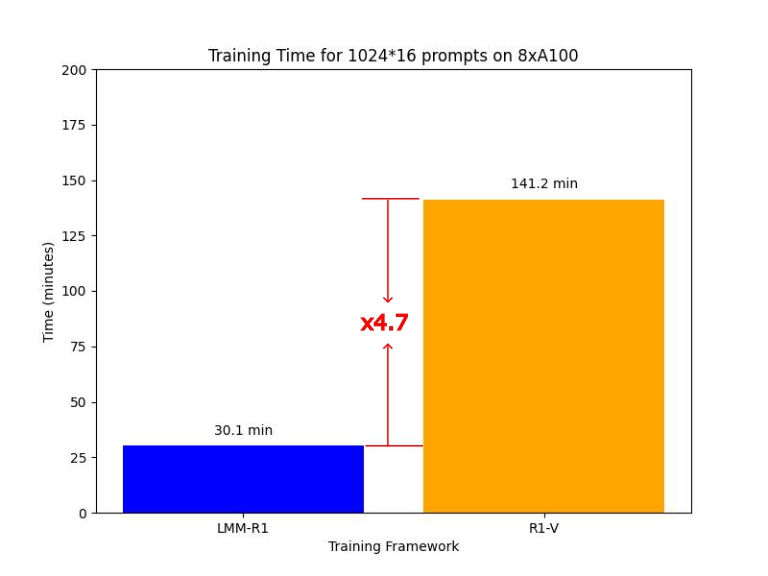
LMM-R1 是 OpenRLHF 的一个分支,旨在提供高性能的 LMM 强化学习基础设施,以增强多模态推理能力。我们目前支持 LMM 的 PPO/REINFORCE++/RLOO 训练,与 R1-V(GRPO)相比,实现了 4.7 倍的加速(RLOO)
- Support LMM training (Qwen2.5-VL, Phi3.5-V, Phi4-Multimodal).
支持 LMM 训练(Qwen2.5-VL,Phi3.5-V,Phi4-多模态)。 - Distributed PPO and REINFORCE++/RLOO implementations based on Ray.
基于 Ray 的分布式 PPO 和 REINFORCE++/RLOO 实现 - Ray-based Reinforced Finetuning基于 Ray 的强化微调
- Support Ray-based PPO and REINFORCE++/RLOO using Hybrid Engine (
--colocate_all_models,--vllm_enable_sleepand--vllm_gpu_memory_utilization 0.5)
支持使用混合引擎(--colocate_all_models、--vllm_enable_sleep和--vllm_gpu_memory_utilization 0.5)的基于 Ray 的 PPO 和 REINFORCE++/RLOO - Full RLHF fine-tuning support for models with over 70 billion parameters.
支持超过 70 亿参数的模型的完整 RLHF 微调 - Integration with vLLM for accelerated generation in RLHF tasks (
--vllm_num_engines).
与 vLLM 集成以加速 RLHF 任务中的生成(--vllm_num_engines)。 - Support for multiple reward models (
--reward_pretrain model1,model2...) and remote reward models (--remote_rm_url).
支持多种奖励模型(--reward_pretrain model1,model2...)和远程奖励模型(--remote_rm_url)。 - Integration of FlashAttention2 (
--flash_attn).
集成 FlashAttention2(--flash_attn)。 - Support for QLoRA (
--load_in_4bit) and LoRA (--lora_rank,--target_modules).
支持 QLoRA(--load_in_4bit)和 LoRA(--lora_rank,--target_modules)。 - Logging support with Wandb (
--use_wandb) and TensorBoard (--use_tensorboard).
使用 Wandb(--use_wandb)和 TensorBoard(--use_tensorboard)的日志支持。 - Checkpoint recovery functionality (
--load_checkpointand--save_steps).
检查点恢复功能(--load_checkpoint和--save_steps)。 - Provided multi-node training scripts, such as Ray PPO.
提供了多节点训练脚本,例如 Ray PPO。
六、软件下载
夸克网盘分享
本文信息来源于GitHub作者地址:https://github.com/TideDra/lmm-r1