数据结构(八)——查找
一、查找
1.查找:在数据集合中,寻找某种满足条件的数据元素的过程
2.查找表(查找结构):用于查找的数据集合
3.关键字:数据元素中某个数据项的值,用它可以标识一个数据元素
主关键字:关键字可以唯一地标识一个记录
4.平均查找长度:所有查找过程中进行关键字的比较次数的平均值![]()
Pi为概率,Ci为第i个元素所需要的比较次数
二、顺序查找
基本思想:从线性表的一端开始,逐个检查关键字是否满足给定的条件。若查找到某个
元素的关键字满足条件,则查找成功,返回该元素在线性表中的位置。若查查找到表的另一端,仍未找到符合给定条件的元素,则返回查找失败的信息



注意:对于线性链表只能进行顺序查找
eg:
答案:C
解释:

三、折半查找(二分查找)
仅适用于有序的顺序表

代码:
int Binary_Search(Seqlist L,ElemType key){int low = 0,high = L.TableLen-1,mid;while(low<=high){mid = (low + high)/2;if(L.ekem[mid] == key)return mid;else if(L.elem[mid]>key)high = mid - 1;elselow = mid + 1;}
}查找成功的平均查找长度
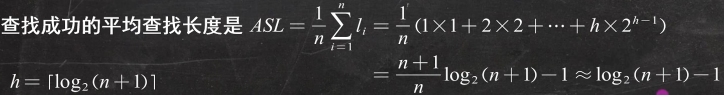
折半查找的时间复杂度为![]()
eg:

答案:A
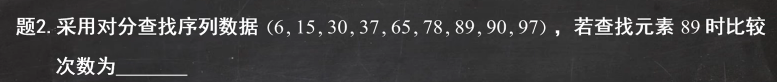
答案:2
四、散列表
1.散列函数:Hash(key) = Addr
同义词:散列函数可能会把两个或两个以上的不同关键字映射到同一地址
![]()
(1)直接定址法:H(key) = key H(key)=a*key+b
(2)除留余数法: m 取一个不大于但最接近或等于m的质数p H(key)= key%p (3)数字分析法 (4)平方取中法
2.解决冲突的方法:
(1)开放地址法:可存放新表项的空闲地址既向它的同义词表项开放,又向它的非同义词表项开放。其数学递推公式为 Hi = (H(key) + di) %m
①★线性探测法: di = 0,1,2,3,...,m-1
②平方探测法:di = 0^2,1^2,-1^2,2^2,-2^2,...,k^2,-k^2 (k<=m/2)
③再散列法:di = Hash2(key)
eg:关键字序列为{19,14,23,01,68,20,84,27,55,11,10,79},按散列函数H(key) = key%13 和线性探测处理冲突构造散列表,其中散列表长度为16
解析:①列出表格,从0开始,长度为16
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 关键字 比较次数 ② 关键字序列中元素依次进行 key%13
第一个为19,H(19) = 19%13 = 6,将19填在6下方,比较次数为1次
第二个为14,H(14) = 14%13 = 1,将14填在1下方,比较次数为1次
第三个为23,H(23) = 23%13 = 10,将23填在10下方,比较次数为1次
第四个为01,H(01) = 01%13 = 1,将01填在1下方,但是14已经填在了1下方,产生了冲突,题干告知通过线性探测处理冲突,Hi = (H(key) +di)%m,di = 0,1,2,...,m-1。所以H(01) = (01+1)%13=2,所以将01填在2下方,比较次数为2次
第五个为68,H(68) = 68%13 = 3,将68填在3下方,比较次数为1次
第六个为20,H(20) = 20%13 = 7,将20填在7下方,比较次数为1次
第七个为84,H(84) = 84%13 = 6,将68填在6下方,但是19已经填在了6下方,产生了冲突,题干告知通过线性探测处理冲突,Hi = (H(key) +di)%m,di = 0,1,2,...,m-1。所以H(84) = (84+1)%13=7,所以将84填在7下方,此时比较2次,但是20以及填在了7下方,产生了冲突,H(84) = (84+2)%13=2,所以将84填在8下方,比较次数为3次
......
以此类推,得到下表
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 关键字 14 01 68 27 55 19 20 84 79 23 11 10 比较次数 1 2 1 4 3 1 1 3 9 1 1 3
查找成功的平均查找长度为:
(这里的查找次数就是比较次数) 所以 (1+2+1+4+3+1+1+3+9+1+1+3)/12 = 2.5
查找不成功的平均查找长度为:
(这里的查找次数不是比较次数,散列后的地址个数是取余的值,例如本题为13)
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 关键字 14 01 68 27 55 19 20 84 79 23 11 10 比较次数 1 2 1 4 3 1 1 3 9 1 1 3 0位置为空,查找失败,次数为1;1位置查找成功,则计算从1开始到下一个为空位置的距离,1到13的距离为13(这里要加上第13个位置所以是12+1=13);同理,2位置为12,3位置为11,...,12位置为2。
所以(1+13+12+11+10++9+8+7+6+5+4+3+2)/13 = 7
查找失败的平均查找长度是通过计算每个位置查找失败的次数,然后将所有位置的查找失败次数相加,再除以散列表的长度得到的,对于每个位置,计算查找失败的次数,这通常涉及到从假定存在的位置开始查找
(2)拉链法:为了避免非同义词发生冲突,把所有的同义词存储在一个线性链表中
eg:关键词序列为{19,14,23,01,68,20,84,27,55,11,10,79},散列函数为H(key) =key%13,用拉链法解决冲突
解析:①取余计算
H(19)=19%13
H(14)=14%13 =1
H(23)=23%13=10
H(01)=01%13=1
H(68)=68%13=3
H(20)=20%13=7
H(84)=84%13=6
H(27)=27%13=1
H(55)=55%13=3
H(11)=11%13=11
H(10)=10%13=10
H(79)=79%13 =1②放入线性表中,相同结果的往后放
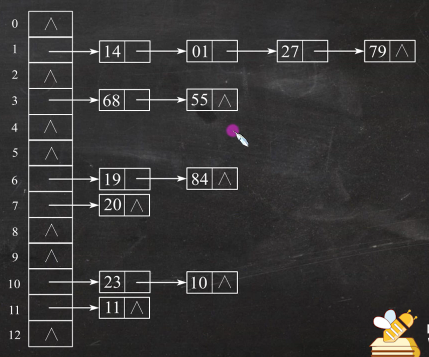
查找成功的平均查找长度为:
查找1次:
5个;查找两次:
4个;查找三次:
1个;查找四次:
1个;
所以 (1*6+2*4+3*1+4*1)/12 = 1.75
查找不成功的平均查找长度为:
查找1次不成功:
7个;查找2次不成功:
2个;查找3次不成功:
3个;查找4次不成功:无;查找5次不成功:
1个;
所以 (1*7+2*2+3*3+4*0+5*1)/13 = 25/13
散列表的查找长度取决于三个因素:散列函数、处理冲突的方法和装填因子
装填因子α = 表中记录数n / 散列表长度m
散列表的平均查找长度依赖于散列表的装填因子α,不直接依赖于n或m
α越大,表示装填的记录越“满”,发生冲突的可能性就越大
五、习题

答案:D

答案:A
解析:表中共 10个元素,第一次取[(1+10)/2]=5 (向下取整),与第5个元素 20比较,58>20,在右子表(30,50,70,88,100}中进行査找;对于右子表{30,50,70,88,100},取[(6+10)/2]=8,与第8个元素 70 比较,58<70,在左子表{30,50}中进行査找;对于左子表{30,50},取[(6+7)/2]=6,与第6个元素 30 比较,58>30,在右子表{50}中进行査找;对于右子表{50},取[(7+7)/2]=7,与第7个元素 50 比较,58>50,所以最终查找失败。在查找过程中,依次与表中20、70、30、50进行了比较,因此答案选择 A。

答案:A
解析:此题考查的知识点是折半査找的思想。把关键字按完全二叉树的形式画出查找树,按结点!高度计算比较次数。12个结点可以画出高度为4的完全二又树,1层1个结点比较1次,2层2个结点比较2次,3层4个结点比较3次,4层5个结点比较4次,(1*1+2*2+3*4+4*5)/12≈3.1

答案:B

答案:C