MLA(多头潜在注意力)原理概述
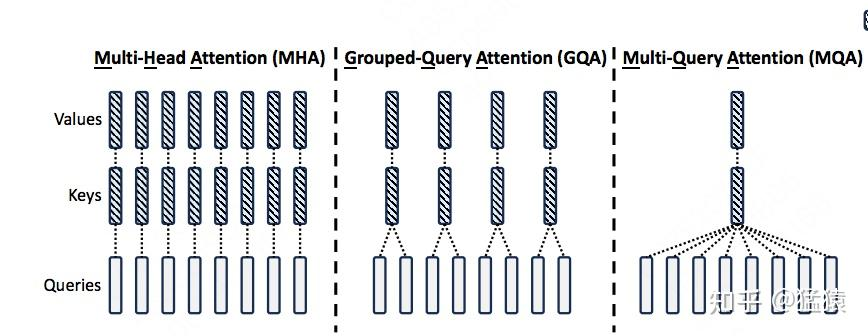
注意力机制的发展经历了MHA,MQA,GQA,MLA。
时间复杂度:MHA为O(n²),MQA、GQA、MLA通过优化降低至O(n)
为了减少KV缓存,主要有以下几种方法:
- 共享KV:多个Head共享使用1组KV,将原来每个Head一个KV,变成1组Head一个KV,来压缩KV的存储。代表方法:GQA,MQA等
- 窗口KV:针对长序列控制一个计算KV的窗口,KV
cache只保存窗口内的结果(窗口长度远小于序列长度),超出窗口的KV会被丢弃,通过这种方法能减少KV的存储,当然也会损失一定的长文推理效果。代表方法:Longformer等 - 量化压缩:基于量化的方法,通过更低的Bit位来保存KV,将单KV结果进一步压缩,代表方法:INT8等
- 计算优化:通过优化计算过程,减少访存换入换出的次数,让更多计算在片上存储SRAM进行,以提升推理性能,代表方法:flashAttention等
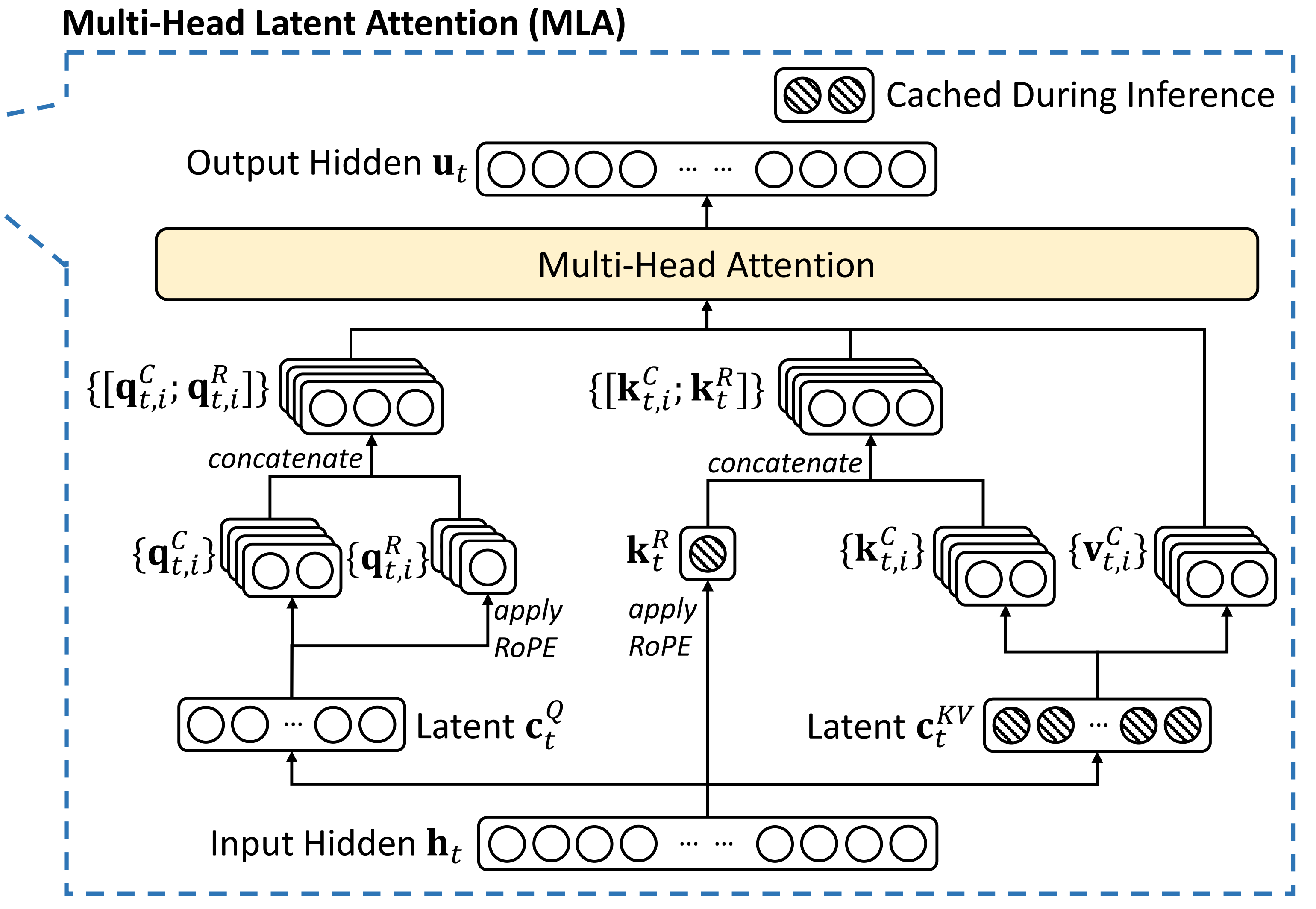
一、过程
1.KV部分
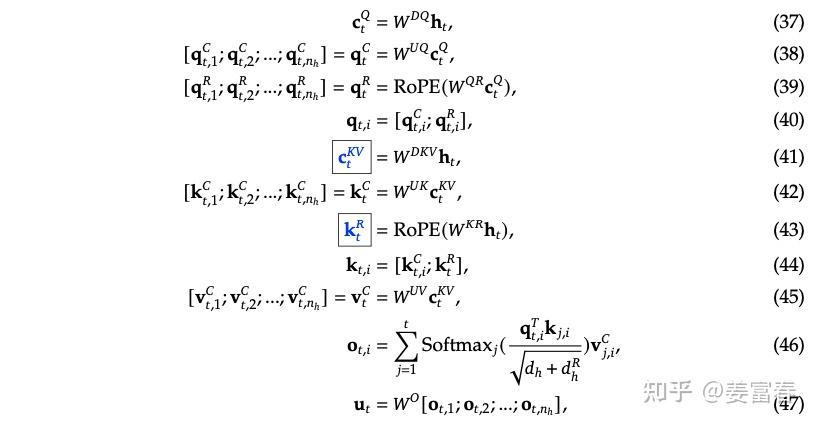
对于输入向量,使用矩阵W_DUK进行联合压缩,得到低秩矩阵C_KV。
然后分别使用W_UK和W_UV对K和V进行还原,得到K_C和V_C
为了加入ROPE旋转位置编码,从输入向量中通过线性映射得到共享的K_R。
合并K_C和K_R,得到完整的K。
2.Q 部分
对于输入向量,通过W_DQ压缩为Q_C。
然后从Q_C进行线性变换,得到Q_R。
一样合并,得到完整的Q。
3.注意力计算
进入正常的注意力计算公式。
4.整体公式
缓存
在MLA中,KV缓存,只需要缓存W_DUK和K_R即可。
二、问答环节
1.为什么MLA推理的计算量那么大,推理效率却高
答:我们可以将LLM的推理分两部分:第一个Token的生成(Prefill)和后续每个Token的生成(Generation),Prefill阶段涉及到对输入所有Token的并行计算,然后把对应的KV Cache存下来,这部分对于计算、带宽和显存都是瓶颈,MLA虽然增大了计算量,但KV Cache的减少也降低了显存和带宽的压力,大家半斤八两;
但是Generation阶段由于每步只计算一个Token,实际上它更多的是带宽瓶颈和显存瓶颈,因此MLA的引入理论上能明显提高Generation的速度。
2.mla和lora的区别
答:
1,目标上,MLA是一种注意力机制优化方案 ,旨在通过低秩分解压缩键值(KV)矩阵,减少计算复杂度;LoRA 是一种模型微调技术。
2.结构上,MLA直接改造注意力层,LORA是在原模型的权重矩阵旁插入低秩分解的适配层。
3.前者要加ROPE位置编码,后者没有。
3.MLA的矩阵吸收



参考文献
deepseek技术解读(1)-彻底理解MLA(Multi-Head Latent Attention) - 姜富春的文章 - 知乎
https://zhuanlan.zhihu.com/p/16730036197
缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA - 苏剑林的文章 - 知乎
https://zhuanlan.zhihu.com/p/700588653
再读MLA,还有多少细节是你不知道的 - 猛猿的文章 - 知乎
https://zhuanlan.zhihu.com/p/19585986234
https://blog.csdn.net/v_JULY_v/article/details/141535986?fromshare=blogdetail&sharetype=blogdetail&sharerId=141535986&sharerefer=PC&sharesource=qq_43814415&sharefrom=from_link