多线程(二)
今天先来了解一个上一期的遗留概念 —— 前台线程与后台线程
一 . 前台线程与后台线程
大家应该多多少少都听过酒桌文化,咱们平常吃饭,座位次序是没有那么多讲究的,但是在跟领导吃饭,或者出席宴会和一些重要场所的饭局时,这个座位次序,朝向都是非常有讲究的,那么通过酒桌文化这个例子,我们就可以生动形象的描述出前台线程与后台线程关系

前台线程与后台线程的概念
前台线程:如果某个线程在执行过程中,能够阻止进程结束,该线程就被称为 “ 前台线程 ”。
后台线程:如果某个线程在执行过程中,不能够阻止进程结束,该线程就被称为 “ 后台线程 ”,后台线程又叫做 “ 守护线程 ”。
情景一:今天我们参加一个酒席,这个酒席就是一个 “ 进程 ”,围着桌子坐着这一圈,其中有一位领导,咱们就叫他王书记。当饭局进行过半了呢,这个时候,我吃饱了,我就想溜了,我就站起来说,我吃饱了,我先走了。但是呢,我作为一个小透明,咱没啥地位,咱说话不管用啊,所以,我说话并不管用,酒席仍然照常进行,所以我在这个酒席中扮演的就是一种 “ 后台线程 ” 的角色。
情景二:饭吃到一半,王书记说,我觉得大家都吃的差不多了,那么今天就到此为止吧,这个时候,就算我还没吃饱,我还想吃,但是不管用,人家王书记发话了是吧,这个时候,咱们也只有乖乖地跟着退场了,所以王书记在这个酒席中扮演的就是一种 “ 前台线程 ” 的角色。“ 前台线程 ” 就有着决定 “ 进程 ” 结束与否的权利。
在同一个进程当中,可以有多个前台线程。且当有多个前台线程的时候,必须所有的前台线程都结束了,该进程才会结束。
情景三:饭吃到一半,王书记说,我觉得大家都吃的差不多了,那么今天就到此为止吧,这个时候咱们旁边的李主任发话了,说我还没喝尽兴呢,咱们再喝会儿,那么这个酒席在这时候就散不了。等到什么时候李主任、王书记都觉得喝好了,并且此时桌子上也没有其他领导(前台线程)了,那么这个时候,酒席就应该真正结束了。
在咱们 Java 中,main(主线程)默认就是前台线程,无需设置。
二 . 线程的状态
线程大致分为六种状态:
(1)NEW:当前的 Thread对象虽然有了,但是内核的线程还没开始(还未调用 start )。
(2)TIMED_WAITING:当前的 Thread对象虽然还在,但是内核的线程已经被销毁了(线程已经结束)。
(3)BLOCKED:因为锁竞争引起的阻塞(有关 “ 锁 ” 这一概念,我们接下来会讲到)。
(4)WAITING:没有超时间的阻塞等待,比如 sleep、join(带参数版本)。
(5)TERMINATED:超时间的阻塞等待,比如 sleep、join(带参数版本)。
(6)RUNNABLE:就绪状态,正在 CPU 上运行或者随时可以去 CPU 上运行。
上述的线程状态,都可以通过 jconsole 观察到。
三 . 多线程带来的风险 —— 线程安全
接下来就是我们的重头戏,重中之重!关于多线程的安全问题。
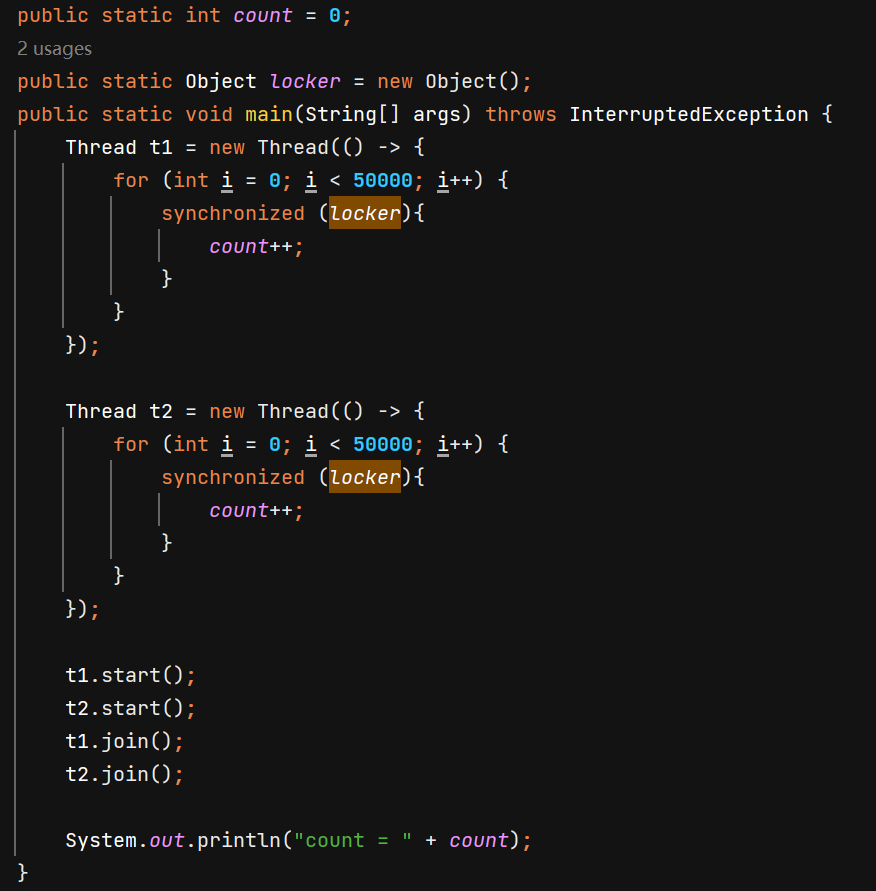
咱们直接来看一个例子:
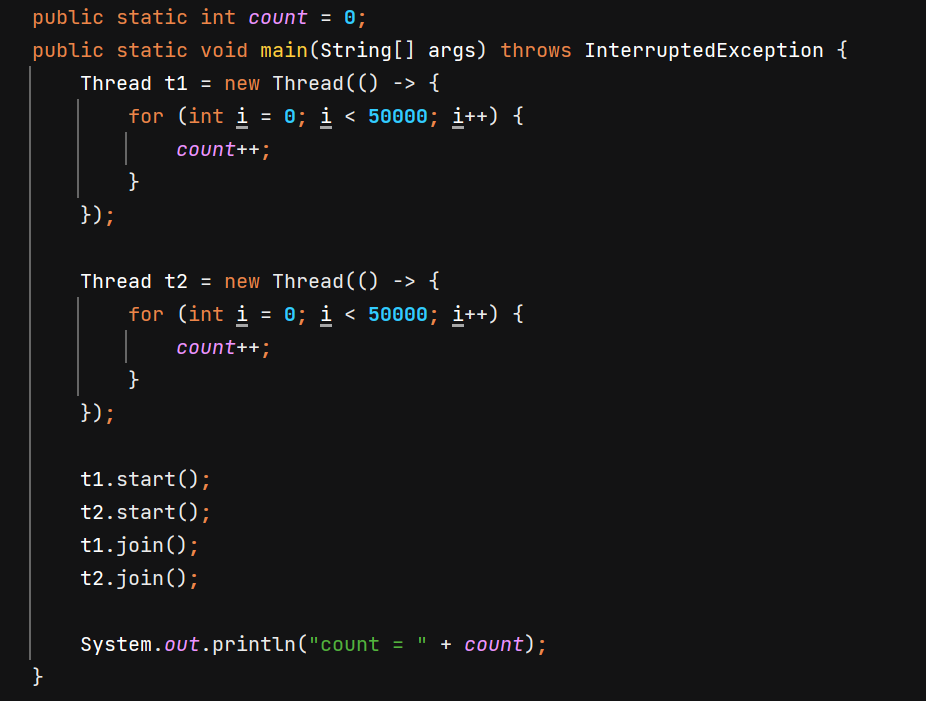
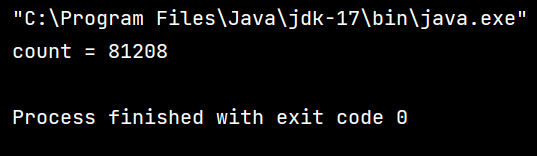
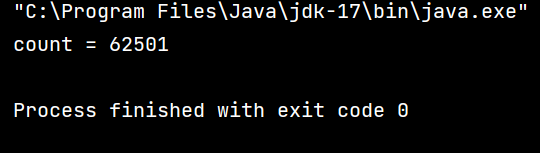
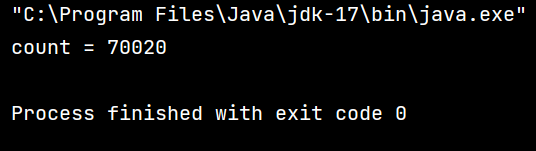
咱们可以看到,我们这段代码,通过两段 for 循环,对 count 进行两段 50000 的自增,我们的预期应该是 100000,可是结果不但不等于 100000,并且通过多次运行我们发现,每次得到的结果都不一样,这是为什么呢?
这是因为,不同架构的 CPU 有不同的指令集。而 count++ 这一操作在 CPU 的视角上来看,是细分为三个指令的:
(1)load:把内存中的数据读取到 CPU 寄存器中。
(2)add:把 CPU 寄存器里的数据 + 1 。
(3)save:把寄存器中的数据再写回内存。
针对这三个操作,不同 CPU 里的指令集对应指令的名称不同,例如:X86 的 CPU 和 arm 的 CPU 和 mips 的 CPU 还有 risc - v 的 CPU 都会有对应的操作,但是具体指令的名字有差异。
而 CPU 在调度执行的时候,我们两个线程是针对同一个 count 进行操作的,(此时的 count 是一个多个线程都可以访问的到的 “ 共享数据 ”)而我们线程调度运行,是一种 “ 抢占式执行,随机调度 ”,随时有可能把线程给切换走,咱们看图理解:
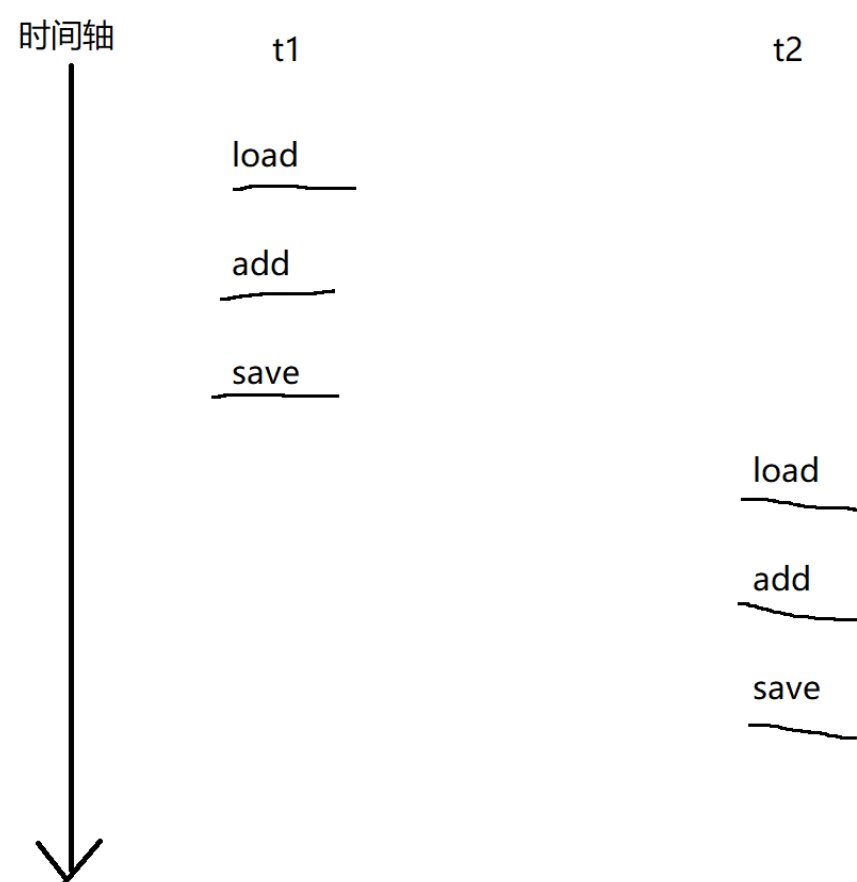
这是咱们理想的执行顺序,t1 执行完一次然后再由 t2 执行(t2 执行完再由 t1 执行也可以)。
但是经常会出现以下情况:
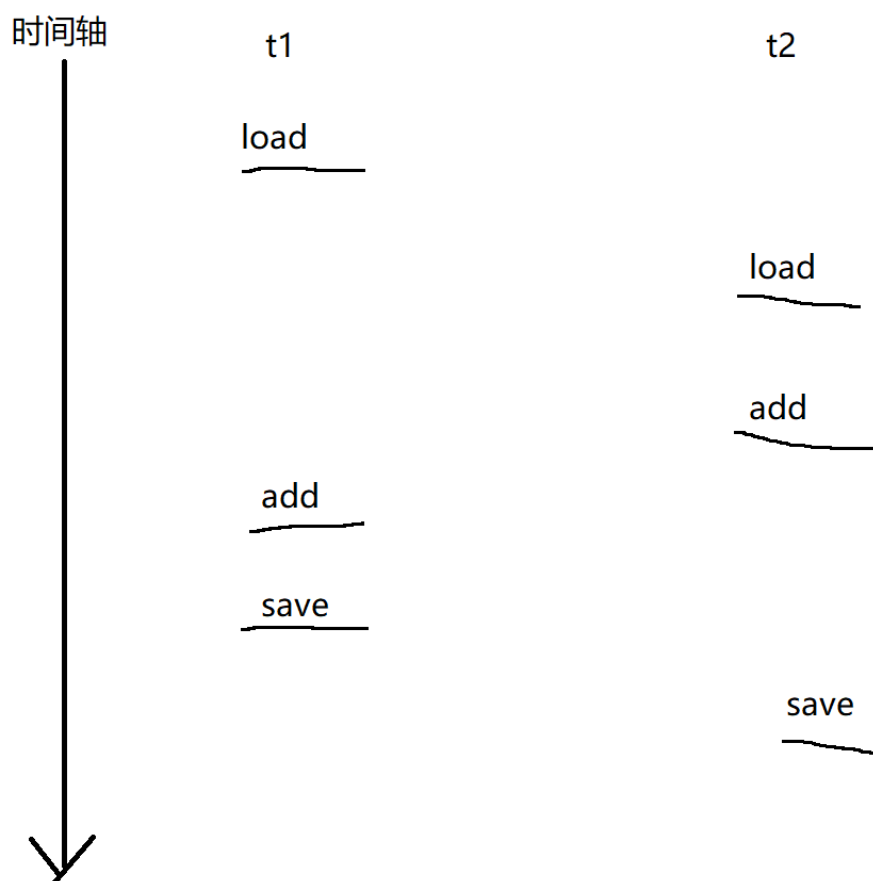
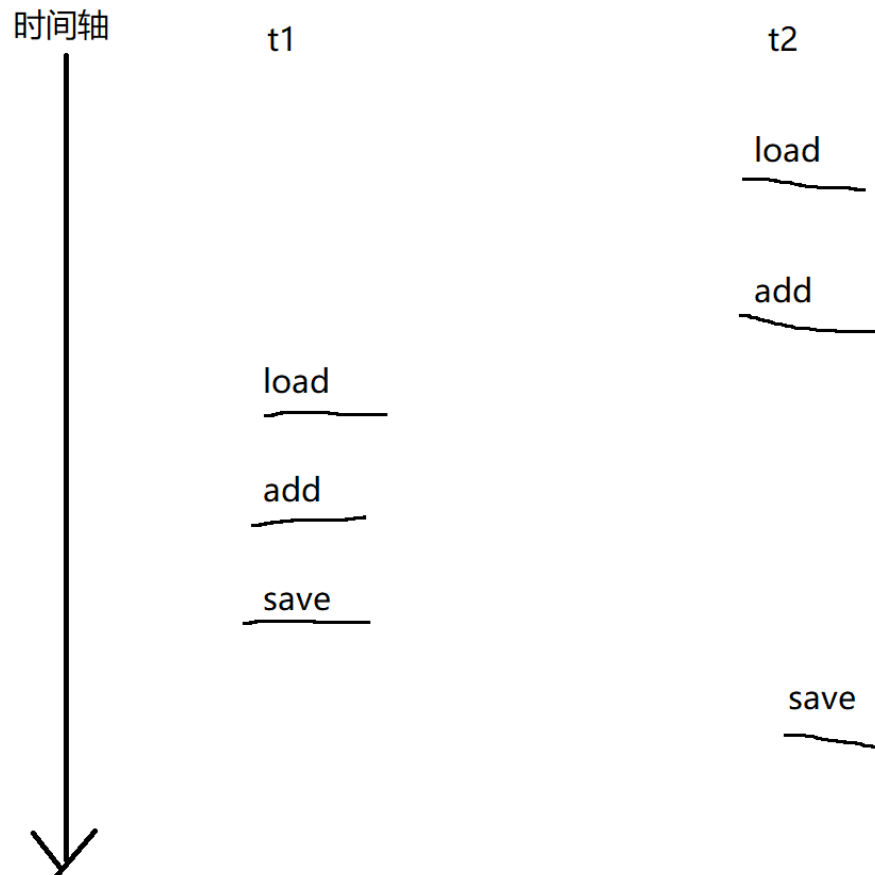
如果是以上的这类情况,咱们就可以看出,当我们其中一个线程刚刚改完寄存器中的数据,还未将值写回内存,此时线程就被切走了,那么后续明明是两次自增的值就会被覆盖,实际上只自增了一次,这就是为什么我们得不到理想值 100000 且每次的值都不一样。
这里大家思考一个问题,咱们运行的值有没有可能小于 50000 呢?答案是可能的,理论上来讲,有可能会出现咱们以下这种在一个线程还未执行完,另一个线程被调度执行的两次的情况(虽然这种情况可能性极小,但是理论上可实现):
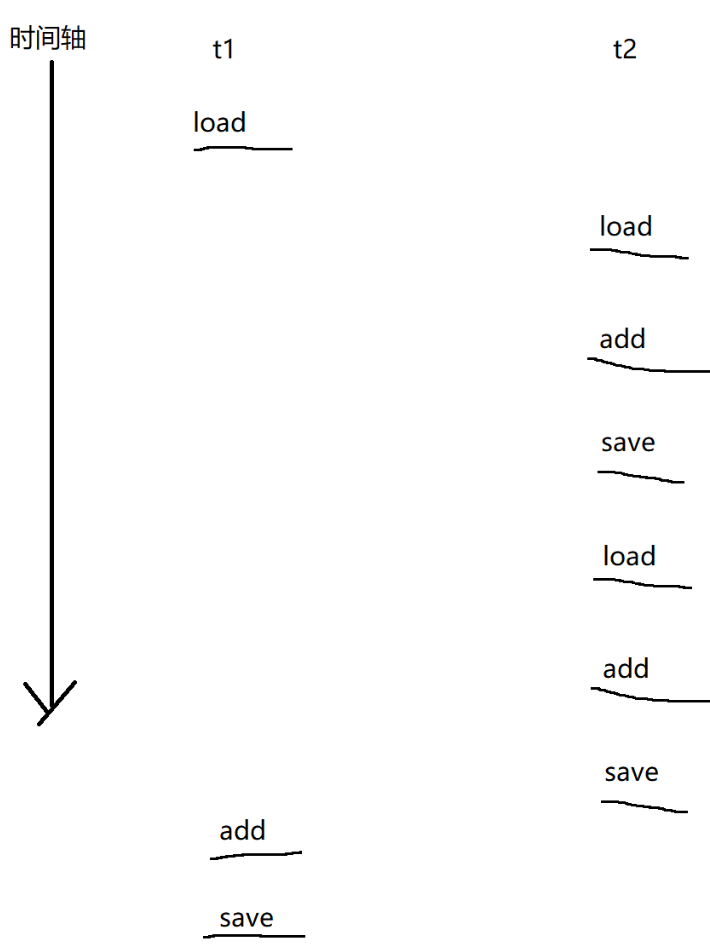
四 . 锁
那么为了解决上述问题,咱们就引入了一个概念 —— 锁,咱们对概念进行 “ 上锁操作 ”,让这三个分开的指令变成一个不可分割的 “ 原子 ”,这个时候我们在执行线程调度的时候就不会存在这一个线程还没执行完就被切走的状况。
synchronized 关键字
(1)synchronized的互斥性:
要使用锁咱们就必须要使用 synchronized 关键字。synchronized 会起到互斥效果,某个线程执行到某个对象的 synchronized 当中时,其它线程如果也执行到同一个对象,synchronized 就会变成阻塞等待状态,等待另一个线程执行完再执行,这就是我们的 “ 上锁操作 ”。
1 . 进入 synchronized 修饰的代码块自动加锁。
2 . 退出 synchronized 修饰的代码块自动解锁。
关于 synchronized(){},()中放的是指定锁对象,锁对象可以写成任意 的 Object 或其子类,{} 放的就是要打包成一个整体的代码。当然,我们对于要执行的两个或多个线程,都必须加锁,一个加锁,另一个不加锁,等于没有锁。
(就比如我们所见到的公共厕所的门锁,当有人进去上厕所并锁门时,此时我们再想进去就只能等这个人 “ 完成任务 ” 出来,将锁解开,咱们才能进去)

这个时候我们不管运行多少次,得到的答案都是我们预期结果 100000。
(2)synchronized的可重入性:
同一个线程加锁两次,就会出现死锁的情况:
死锁情景一:

死锁情景二:
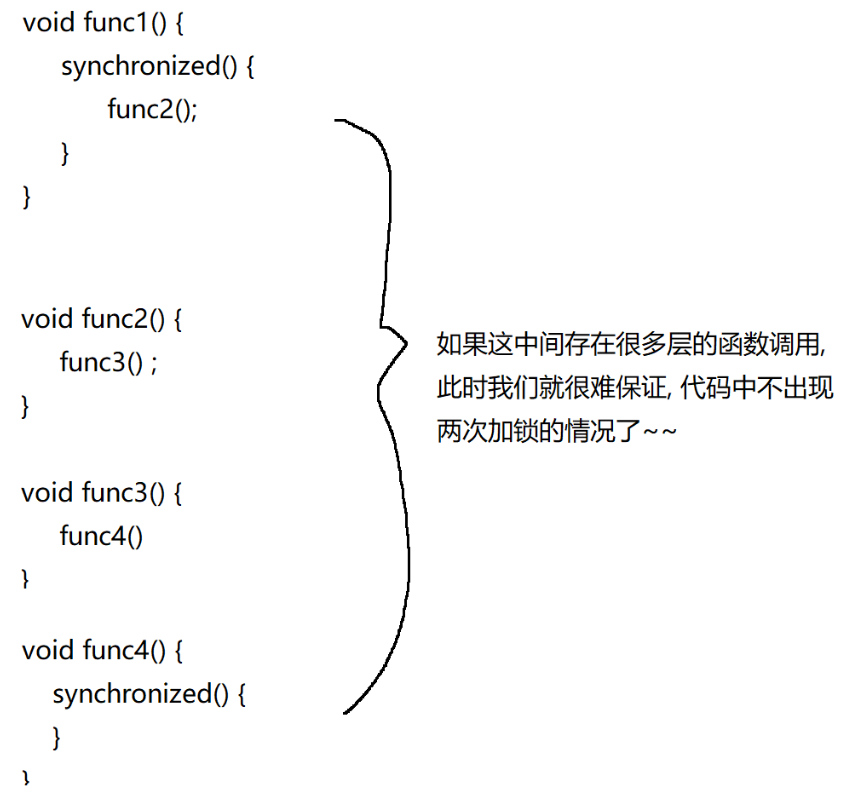
在我们 Java 中 synchronized 对于同一线程来说是 “ 可重入锁 ”,不会出现自己把自己锁死的情况,而 C++ / Python 中的锁,就没有进行这样的特殊处理,二次加锁就会出现死锁。
死锁情景三:
还有一种特殊的情景,这种情况下形成的死锁,咱们 Java 的可重入锁机制也无能为力了。
例如:我们此时有两个线程 t1,t2,有两把锁 locker1,locker2
1 . t1 先对 locker1 加锁, t2 先对 locker2 加锁。
2 . t1 在未释放 locker1 的情况下,再对 locker2 加锁;同时 t2 在未释放 locker2 的情况下,再对 locker1 加锁。
这个样子 t1 在等待 t2 释放 locker2,而 t2 在等待 t1 释放 locker1,谁也不让着谁,。
总结一下,形成死锁的四个必要条件:
(1)锁的基本特性:锁是互斥的。
(2)锁是不可被抢占的:线程一拿到了锁,如果线程一不主动释放锁,那么线程而就不能将锁强行抢过来。
(3)请求和保持:线程一拿到了锁一,在线程一未释放锁一的情况下再去拿锁二。
(4)循环等待 / 环路等待 / 循环依赖:多个线程获取锁的过程,存在循环等待。
(重点注意:synchornized 是可重入锁!!!)
volatile 关键字
volatile 关键字所修饰的变量,能保持内存的 “ 可见性 ”。
内存可见性问题:内存可见性问题本质上是编译器 / JVM 对代码进行优化的时候,优化出 “BUG”。如果代码是单线程的,编译器 / JVM 优化代码时非常准确的。优化之后,不会影响到逻辑。但是代码如果是多线程的,编译器 / JVM 优化代码时就可能出现误判(编译器 / JVM 的 BUG)导致不该优化的地方进行了优化,这也就造成了我们的 “ 内存可见性 ” 问题。
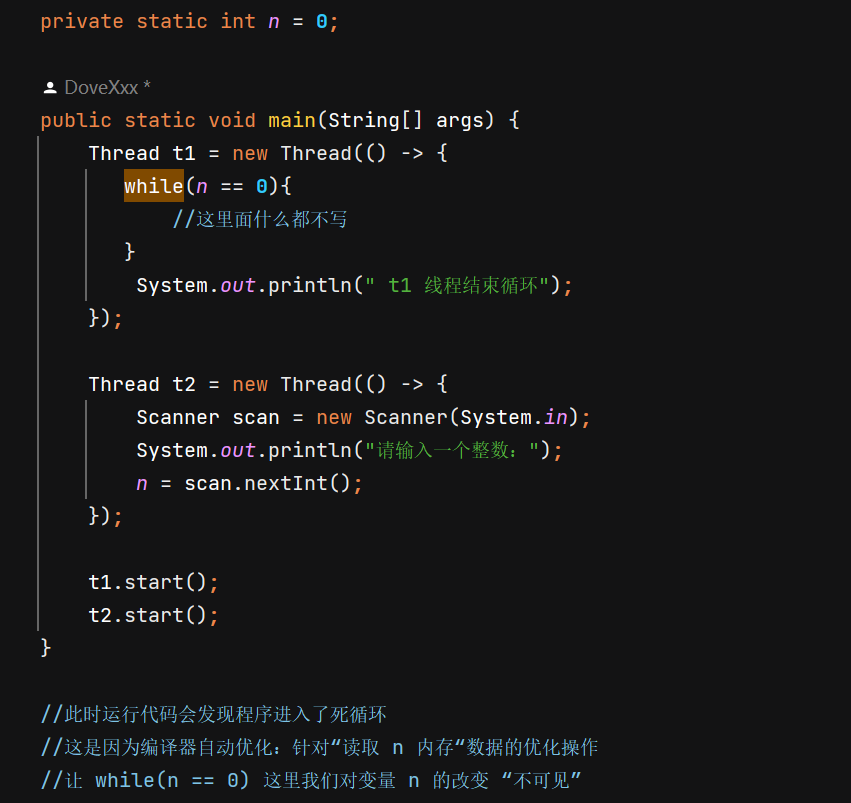
如上述代码所示,此时我们运行该代码,不管输入什么值,发现程序根本动不了,这是因为我们编译器的自动优化,会一直默认我们的 n = 0,不会改变,所以此刻我们即使对变量 n 赋值使其为非零数,依旧不能走出循环。
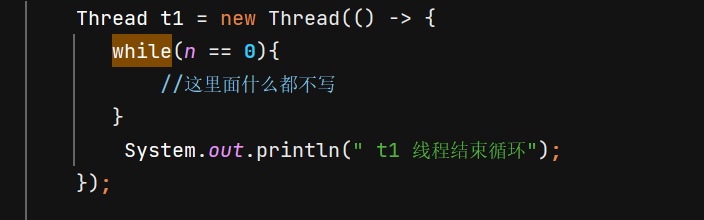
在我们上述线程中,这个 while 循环会执行非常非常非常多次,而每次循环执行到这里,就会执行一个 n == 0 的这样一个判定,大致分为两步:
(1)从内存中读取数据到寄存器中(这一步非常慢)。
(2)通过类似于 cmp 指令比较寄存器里的 n 值与 0(这个指令执行的非常快)。
此时当我们的 JVM 在执行到这一代码的时候,发现每次循环的过程中,执行操作(1)的开销非常大,并且每次循环的结果都是一样的啊,JVM 根本没意识到,用户可能在未来对 n 的值进行修改。所以它就自作主张,直接将操作(1)这一步骤给优化掉了。
因此再后来我们每次循环的时候,不会重新读取内存中的数据,而是直接读取寄存器 / cache 中的数据(缓存的结果)。但是,当我们用户修改 n 的值的时候,即使内存中的 n 的值已经发生改变,但是由于 t1 线程每次循环,不会去真正地读内存,感知不到 n 的存在。综上所述,优化过后,内存中 n 的改变,对于 t1 线程来说是 “ 不可见 ” 的。
此处就需要引出我们的 volatile 关键字,当变量被 volatile 关键字所修饰时,在系统内就会提示编译器,这个变量是易变的,在后续我们会赋予其新的值,所以编译器就不会对这个变量进行优化。
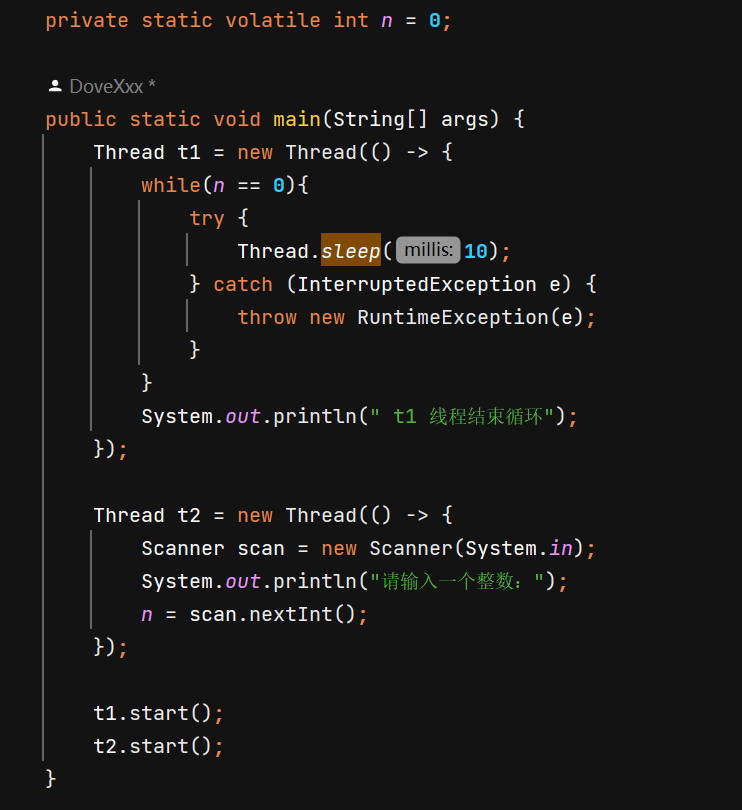
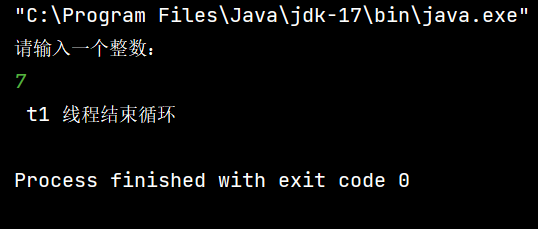
如图所示,我们将变量 n 使用 volatile 修饰后,代码便可以正常运行了。volatile 修饰某个变量,就是告诉编译器,这个变量的值是 “ 易变 ” 的,不要对其进行优化。
注意:volatile 只是解决内存存在性问题,不能解决原子性问题。如果两个针对同一个变量进行修改(如 count++ ),此时 volatile 就无能为力了。
OKK,今天有关于多线程的讲解就到此为止,咱们欲知后事如何,且听下回分解,咱们下期见!与诸君共勉!!!