Redis经典面试题
本篇文章简单介绍一些 Redis 常见的面试题。
Redis 是什么?
Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
与MySQL数据库不同的是,Redis的数据是存在内存中的。它的读写速度非常快,每秒可以处理超过10万次读写操作。因此redis被广泛应用于缓存,另外,Redis也经常用来做分布式锁。除此之外,Redis支持事务、持久化、LUA 脚本、LRU 驱动事件、多种集群方案。
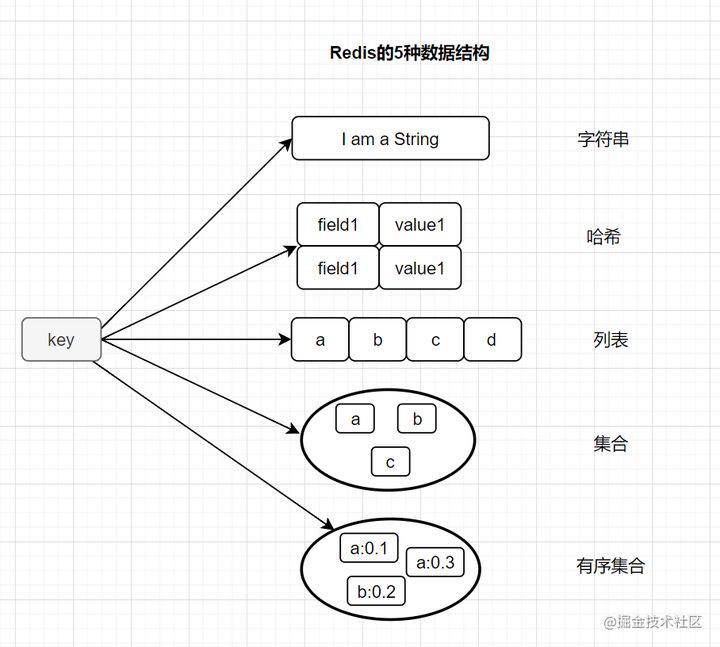
Redis 是一个开源的、基于内存的键值存储系统,通常用作数据库、缓存和消息中间件。它支持多种数据结构,如字符串、哈希、列表、集合、有序集合等。
Redis 的数据类型有哪些?
Redis 支持以下主要数据类型:
- 字符串(String):最基本的类型,可以存储字符串、整数或浮点数。
- 哈希(Hash):键值对的集合,适合存储对象。
- 列表(List):字符串列表,按照插入顺序排序,支持在头部或尾部插入元素。
- 集合(Set):无序且唯一的字符串集合。
- 有序集合(Sorted Set):类似于集合,但每个元素关联一个分数,用于排序。
除此之外还有 Geospatial、Hyperloglog、Bitmap 等
Redis 的常见应用场景有哪些?
Redis 的常见应用场景包括:
- 缓存:加速数据访问,减轻数据库压力。
- 会话存储:存储用户会话信息(可以使用哈希、String或者Sorted Set实现)。
- 排行榜:使用有序集合实现实时排行榜(使用的是Sorted Set这个数据类型,Sorted Set 底层维护了一个 socre 字段,通过这个字段可以)。
- 消息队列:使用列表或发布订阅功能实现消息队列(Redis 其实最开始就是用来做消息队列的,但是由于 Redis 实现的消息队列比较简单,而且Redis 的缓存太好用了,就渐渐的用的越来越少,其他的 MQ 也很好用)。
Redis 持久化(Redis 保证数据不丢失)
Redis 的持久化机制
Redis 提供了两种持久化机制:
- RDB(Redis DataBase)持久化:快照方式持久化,将某一个时刻的内存数据,以二进制的方式写入磁盘;
- AOF(Append Only File)持久化:文件追加持久化,记录所有非查询操作命令,并以文本的形式追加到文件中;
- 混合持久化:RDB + AOF 混合方式的持久化,Redis 4.0 之后新增的方式,混合持久化是结合了 RDB 和 AOF 的优点,在写入的时候,先把当前的数据以 RDB 的形式写入文件的开头,再将后续的操作命令以 AOF 的格式存入文件,这样既能保证 Redis 重启时的速度,又能减低数据丢失的风险。
RDB 持久化:
优点:
- 速度快:相对于 AOF 持久化方式,RDB 持久化速度更快,因为它只需要在指定的时间间隔内将数据从内存中写入到磁盘上。
- 空间占用小:RDB 持久化会将数据保存在一个压缩的二进制文件中,因此相对于 AOF 持久化方式,它占用的磁盘空间更小。
- 恢复速度快:因为 RDB 文件是一个完整的数据库快照,所以在 Redis 重启后,可以非常快速地将数据恢复到内存中。
- 可靠性高:RDB 持久化方式可以保证数据的可靠性,因为数据会在指定时间间隔内自动写入磁盘,即使 Redis 进程崩溃或者服务器断电,也可以通过加载最近的一次快照文件恢复数据。
缺点:
- 数据可能会丢失:RDB 持久化方式只能保证数据在指定时间间隔内写入磁盘,因此如果 Redis 进程崩溃或者服务器断电,从最后一次快照保存到崩溃的时间点之间的数据可能会丢失。
- 实时性差:因为 RDB 持久化是定期执行的,因此从最后一次快照保存到当前时间点之间的数据可能会丢失。如果需要更高的实时性,可以使用 AOF 持久化方式。
所以,RDB 持久化方式适合用于对数据可靠性要求较高,但对实时性要求不高的场景,如 Redis 中的备份和数据恢复等。
AOF 持久化:
优点:
- 数据不容易丢失:AOF 持久化方式会将 Redis 执行的每一个写命令记录到一个文件中,因此即使 Redis 进程崩溃或者服务器断电,也可以通过重放 AOF 文件中的命令来恢复数据。
- 实时性好:由于 AOF 持久化方式是将每一个写命令记录到文件中,因此它的实时性比 RDB 持久化方式更好。
- 数据可读性强:AOF 持久化文件是一个纯文本文件,可以被人类读取和理解,因此可以方便地进行数据备份和恢复操作。
缺点:
- 写入性能略低:由于 AOF 持久化方式需要将每一个写命令记录到文件中,因此相对于 RDB 持久化方式,它的写入性能略低。
- 占用磁盘空间大:由于 AOF 持久化方式需要记录每一个写命令,因此相对于 RDB 持久化方式,它占用的磁盘空间更大。
- AOF 文件可能会出现损坏:由于 AOF 文件是不断地追加写入的,因此如果文件损坏,可能会导致数据无法恢复。
所以,AOF 持久化方式适合用于对数据实时性要求较高,但对数据大小和写入性能要求相对较低的场景,如需要对数据进行实时备份的应用场景。
混合持久化:
Redis 混合持久化是指将 RDB 持久化方式和 AOF 持久化方式结合起来使用,以充分发挥它们的优势,同时避免它们的缺点。
它的优缺点如下:
优点:
混合持久化结合了 RDB 和 AOF 持久化的优点,开头为 RDB 的格式,使得 Redis 可以更快的启动,同时结合 AOF 的优点,有减低了大量数据丢失的风险。
缺点:
- 实现复杂度高:混合持久化需要同时维护 RDB 文件和 AOF 文件,因此实现复杂度相对于单独使用 RDB 或 AOF 持久化方式要高。
- 可读性差:AOF 文件中添加了 RDB 格式的内容,使得 AOF 文件的可读性变得很差;
- 兼容性差:如果开启混合持久化,那么此混合持久化 AOF 文件,就不能用在 Redis 4.0 之前版本了。
所以,Redis 混合持久化方式适合用于,需要兼顾启动速度和减低数据丢失的场景。但需要注意的是,混合持久化的实现复杂度较高、可读性差,只能用于 Redis 4.0 以上版本,因此在选择时需要根据实际情况进行权衡。
Redis 集群
Redis 实现高可用
Redis 通过主从复制和哨兵机制实现高可用:
- 主从复制:主节点将数据同步到从节点,从节点可以处理读请求,减轻主节点压力。
- 哨兵机制:监控主从节点的状态,自动进行故障转移和主节点选举。
- Redis Cluster:将数据分布在不同的服务区上,以此来降低系统对单主节点的依赖。
如果读写都存在一台机器上,那么单点部署一旦宕机,就不可用了。为了实现高可用,通常的做法是,将数据库复制多个副本以部署在不同的服务器上,其中一台挂了也可以继续提供服务。
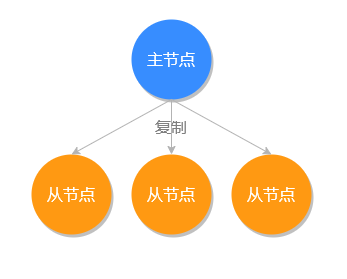
主从复制
所以主从复制就是指:主节点用来写数据,其他从节点负责读数据,同时同步主节点的新的数据。
如果说主节点宕机了,那么就不能写数据了,还是可以继续读取数据的,如果从节点宕机了,还有其他从节点的话(一般都是一主多从的),还是可以继续读数据的。
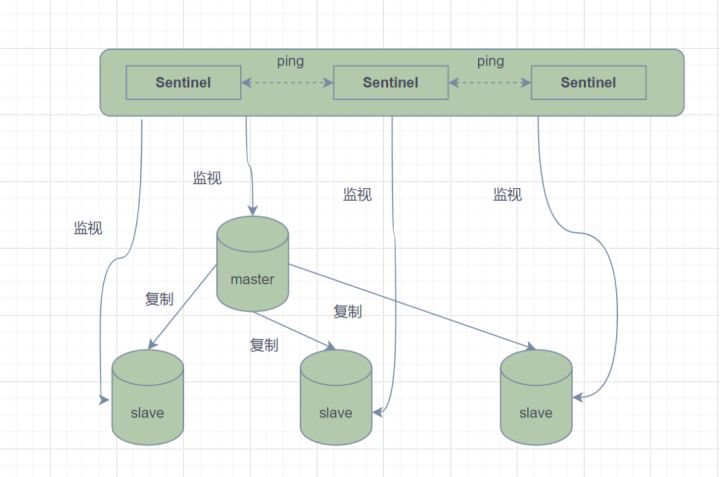
哨兵
哨兵模式就是指,添加监视器,去监听各个节点是否宕机了,从节点宕机了没关系,只不过是其他从节点压力增大了(不会是读取功能失效)。主从同步存在一个致命的问题,当主节点奔溃之后,需要人工干预才能恢复 Redis 的正常使用。 所以我们需要一个自动的工具——Redis Sentinel (哨兵模式) 来把手动的过程变成自动的,让 Redis 拥有自动容灾恢复 (failover) 的能力。
如果是主节点宕机了,那么就会被哨兵监听到,随后该监听的哨兵就会发起 “选主” 操作,其余哨兵就会进行投票,票数多的选为新的主节点。
一般来说都是单数的哨兵,如果非要设置双数的哨兵,也可以让发起选主的哨兵的权重大一些,平票的问题也可以解决。
当然这个选主操作不是由首先发现的哨兵直接做出判断的(有可能做出一个误判),而是先进入一个 “ 主观 ” 下线,等到其他哨兵都确认了确实有问题了,就会将该节点标记为客观下线
如下图所示:
Cluster集群模式
单点存在的不足
- Redis 单节点部署时面临的容量瓶颈、高可用性和水平扩展问题,一主多从的部署写的能力还是会达到上限。
- 单节点 Redis 的数据存储受限于单机内存(通常几十 GB),无法处理海量数据(如 TB 级缓存或日志存储)。单线程模型在高并发下易达到 CPU 上限,无法利用多核服务器资源。
- 单节点无法通过添加机器分担负载,只能升级硬件(垂直扩展),成本高昂且有上限。
所以可以将多个 哨兵模式(不是多个哨兵)组合起来,该模式下存在多个主节点。
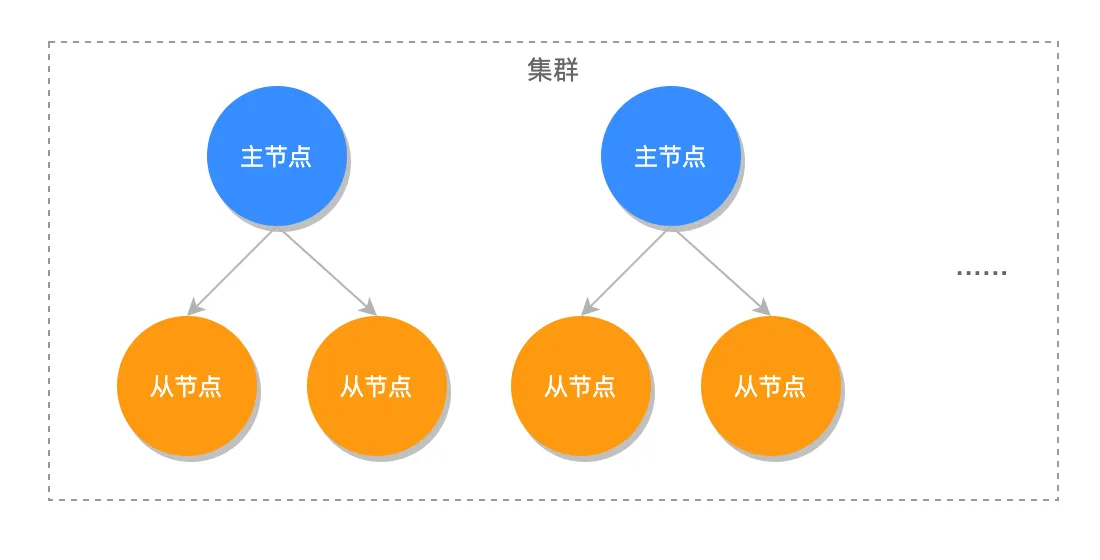
从上图可以看出 Redis 的主从同步只能有一个主节点,而 Redis Cluster 可以拥有无数个主从节点,因此 Redis Cluster 拥有更强大的平行扩展能力,也就是说当 Redis Cluster 拥有两个主从节点时,从理论上来讲 Redis 的性能相比于主从来说性能提升了两倍,并且 Redis Cluster 也有自动容灾恢复的机制。
Redis Cluster 是 Redis 官方提供的分布式解决方案,通过分片(Sharding)实现数据在多个节点之间的自动分片和负载均衡,解决了 Redis 单节点的容量和可用性瓶颈。
在Cluster 集群模式中引入了 哈希槽的概念:
- 哈希槽(Hash Slot)
Redis Cluster 将整个数据库分为16384 个哈希槽(Hash Slot),每个键通过CRC16(key) % 16384计算后映射到对应的槽。- 节点分配
每个节点负责一部分哈希槽(例如,3 节点集群中每个节点约负责 5461 个槽)。节点动态添加 / 删除时,槽会自动迁移,无需重启集群。Redis Cluster集群中,需要确保16384个槽对应的node都正常工作,如果某个node出现故障,它负责的slot也会失效,整个集群将不能工作。
Redis 关于脑裂问题
Redis 脑裂是指在分布式系统中,由于网络分区等原因,导致 Redis 集群中的部分节点与其他节点失去联系,从而形成多个独立的子集群,每个子集群都认为自己是主集群,进而引发数据不一致等问题。
例如图下所示:
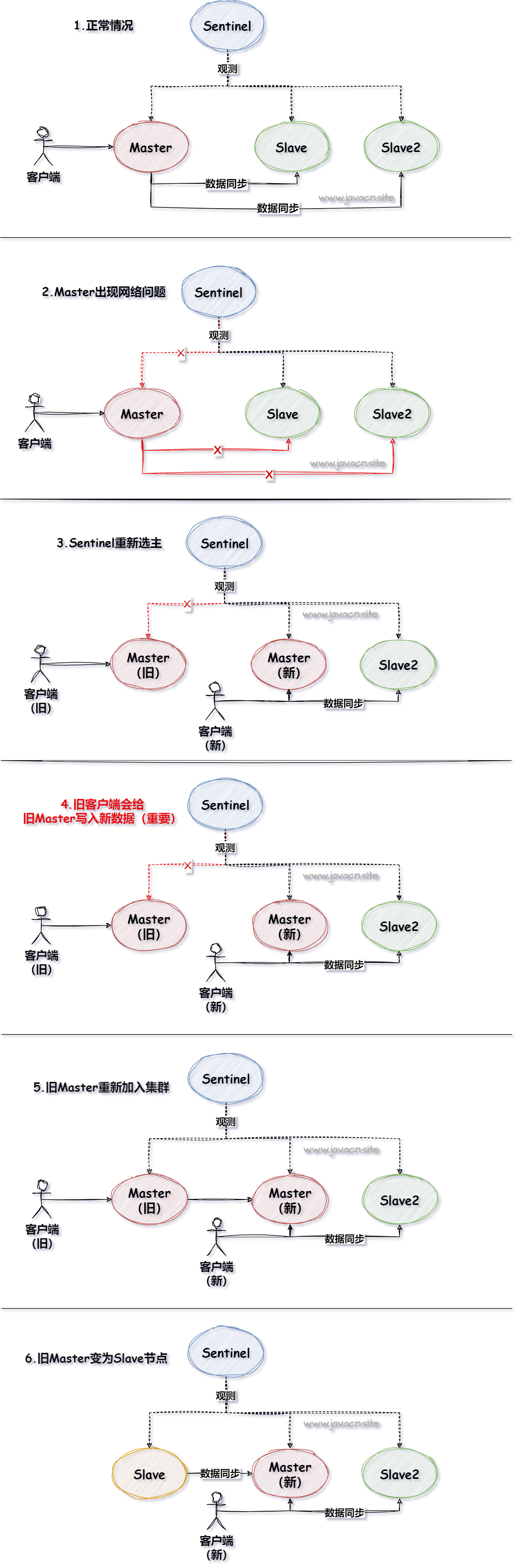
这张图就很好的说明了问题:
- 因为网络问题,导致原来的主节点(旧)并未同步新的主节点,旧的还不知道已经重新选主了;
- 此时,原来连接了旧主节点的客户端还在往这里写数据,其他新连接的客户端向新节点写数据;等到网络恢复后,旧节点与新节点比较一下版本号,发现新的节点版本号比他大,它也就明白了已经进行了一次选主操作了;
- 这个时候旧节点就降级为从节点,并向新的主节点进行请求同步数据,此时问题来了:那在网络故障的情况下,旧的客户端向 Redis 中写的数据怎么办呢?
- 此时就发现数据丢失了。
在网络故障期间看似是有两个大脑,不同的客户端向不同的节点进行写数据。
脑裂的主要原因其实就是哨兵集群认为主节点出现“假故障”了,于是开始主从切换,选举出了新的主节点,这就导致短暂的出现了两个主节点。
redis集群没有过半机制会有脑裂问题,网络分区导致脑裂后多个master对外提供写服务,一旦网络分区恢复,会将其中一个master变为从节点,这时会有大量数据丢失。
redis集群应对脑裂的解决办法应该是取限制原主库接收请求,Redis提供了两个配置项:
- min-slaves-to-write:主库能进行数据同步的最少从库数量。
- min-slaves-max-lag:主从进行数据复制时,从库给主库发送ACK消息的最大延迟秒数。
这两项必须同时满足,不然主节点会禁止写入操作,这就解决了因脑裂导致数据丢失的问题。
举个例子,我们把min-slaves-to-write设置为1,把min-slaves-max-lag设置为10。
如果Master节点因为某些原因挂了12s,导致集群判断主节点客观下线,开始主从切换。
同时,因为原Master宕机了12s,没有一个(min-slaves-to-write)从节点与主节点之间的数据复制在10s(min-slaves-max-lag)内,不满足配置要求,原Master就无法执行写操作了。
那么这样做就可以解决脑裂问题吗?
答案是不可以的,这两个配置项主要是针对脑裂时数据丢失问题进行防范,但并不能完全解决脑裂可能带来的所有问题,如脑裂发生后多个子集群之间的协调、数据冲突的处理等。还需要结合其他措施,如使用 Redis Sentinel 或 Redis Cluster 的自动故障转移机制等,来全面应对 Redis 脑裂问题。
按照官方文档所言,redis 并不能保证强一致性
Redis + Sentinel 集群,是最终一致性产品
对于要求强一致性的应用,更应该倾向于 传统关系型数据库 如mysql ,或者使用强一致性的 协调组件 Zookeeper。
缓存三兄弟
Redis 如何处理缓存穿透?
缓存穿透是指查询一个不存在的数据,导致请求直接到达数据库。
缓存穿透一般都是这几种情况产生的:
- 业务不合理的设计,比如大多数用户都没开守护,但是你的每个请求都去缓存,查询某个userid查询有没有守护。
- 业务/运维/开发失误的操作,比如缓存和数据库的数据都被误删除了。
- 黑客非法请求攻击,比如黑客故意捏造大量非法请求,以读取不存在的业务数据。
解决方法包括:
- 布隆过滤器:预先将所有可能的键存储在布隆过滤器中,查询时先检查是否存在。
- 缓存空值:对于查询不到的数据,缓存一个空值,并设置较短的过期时间。
- 针对恶意用户,可以对其进行限制,限制操作次数
布隆过滤器:
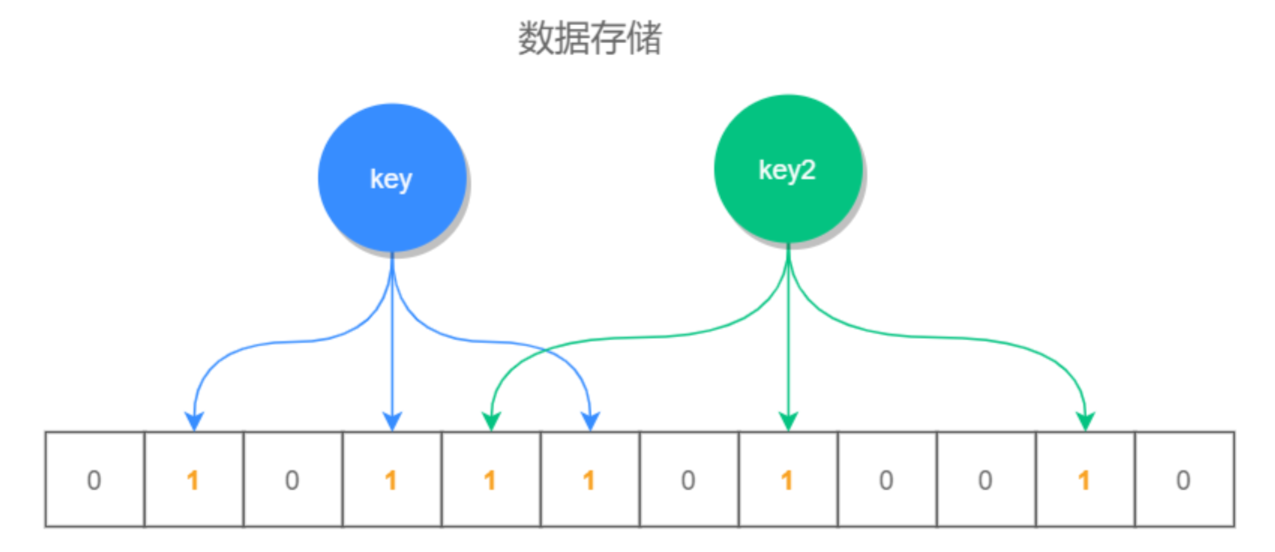
布隆过滤器原理:它由初始值为0的位图数组和N个哈希函数组成。一个对一个key进行N个hash算法获取N个值,在比特数组中将这N个值散列后设定为1,然后查的时候如果特定的这几个位置都为1,那么布隆过滤器判断该key存在。
Redis 如何处理缓存雪崩?
缓存雪崩是指大量缓存同时失效,导致请求直接到达数据库。
可能造成缓存雪崩的原因:
- 大量缓存键同时过期:当缓存键设置了相同的过期时间,或者由于某种原因导致大量的键同时失效,会导致缓存雪崩。
- 缓存服务器故障:当缓存服务器发生故障,无法提供服务时,请求将直接访问后端服务,导致压力集中在后端服务上。
解决方法包括:
- 设置不同的过期时间:避免大量缓存同时失效。
- 使用分布式锁:在缓存失效时,使用分布式锁控制数据库访问,防止数据库被压垮。
- 设置熔断机制:在缓存失效的情况下,通过设置熔断机制,直接返回默认值或错误信息,避免请求直接访问后端服务,减轻后端服务的压力。
- 实时监控和报警:监控缓存系统的状态和性能指标,及时发现异常情况,并通过报警机制通知运维人员进行处理,减少缓存雪崩的影响。
Redis 如何处理缓存击穿?
缓存击穿是指某个热点数据过期或失效时,同时有大量的请求访问该数据,导致请求直接访问数据库或后端服务,导致系统性能下降甚至崩溃的现象。
缓存击穿可能发生的原因包括:
- 热点数据失效:当某个热点数据过期时,此时大量请求访问该数据,导致缓存失效,请求直接访问数据库。
- 并发访问热点数据:在高并发环境下,大量的请求同时访问同一个热点数据,导致该热点数据在缓存失效期间被并发地访问,触发缓存击穿。
为了解决缓存击穿问题,可以采取以下策略:
- 设置热点数据永不过期或过期时间较长:对于一些热点数据,可以将其设置为永不过期,或者设置一个较长的过期时间,确保热点数据在缓存中可用,减少因为过期而触发的缓存击穿。
- 加互斥锁或分布式锁:在访问热点数据时,可以引入互斥锁或分布式锁,保证只有一个线程去访问后端服务或数据库,其他线程等待结果。当第一个线程获取到数据后,其他线程可以直接从缓存获取,避免多个线程同时访问后端服务,减轻压力。
- 限制并发访问:通过限制并发访问热点数据的请求量,可以控制请求的流量,避免过多请求同时访问热点数据
Redis 的分布式锁如何实现?
SETNX + EXPIRE(有原子性问题)
在 Redis 中实现分布式锁可以使用 SETNX 和 EXPIRE 命令来实现,SETNX 是 "SET if Not eXists" 的缩写,是一个原子性操作,用于在指定的 key 不存在时设置 key 的值。如果 key 已经存在,SETNX 操作将不做任何事情,返回失败;如果 key 不存在,SETNX 操作会设置 key 的值,并返回成功。而 EXPIRE 是设置锁的过期时间的,主要为了防止死锁的发生
SETNX 和 EXPIRE 一起使用可以实现分布式锁的功能,但存在锁误删的问题,比如线程 1 设置的过期时间为 5s,而线程 1 执行了 7s,那么在第 5s 之后锁过期了,那么其他线程就可以拥有这把锁了,之后线程 1 执行完业务,又执行了锁删除操作,那么此时锁就被误删了
如何解决呢?
在删除之前,先判断一下持有锁的持有者是非为它本身。
给每个锁的 value 中添加拥有者的标识,删除之前先判断是否是自己的锁,如果是则删除,否则不删除。当然删除时任然不是个原子操作,所以还是有问题,给它加个 lua 脚本来判断并删除锁,lua 脚本可以保证 redis 中多条语句执行的原子性,所以就可以解决此问题了。
还可以使用 Redission 框架来实现
Redisson 框架:封装了分布式锁、可重入锁、公平锁、红锁(RedLock)等功能,简化开发。
Redis 过期策略和内存淘汰策略
Redis 的过期策略有哪些?
Redis 的过期策略包括:
- 定期删除:每隔一段时间随机检查一批键,删除其中过期的键。
- 惰性删除:在访问键时检查其是否过期,如果过期则删除。
Redis中同时使用了惰性过期和定期过期两种过期策略。
- 假设 Redis当前存放非常多的key,并且都设置了过期时间,如果每隔一定时间去检查这些 全部的 key,那么CPU的负载就会特别高,甚至挂掉
- 因此,redis 采用的是定期过期,每隔一段时间就随机抽取一定数量的 key 来进行检查和删除
- 但是,最后可能会有很多已经过期了的key 没被删除,这个时候采用 惰性删除,当用户获取的时候,redis 进行检查一下,过期了就给他删掉
Redis 的内存淘汰策略有哪些?
Redis 提供了多种内存淘汰策略,包括:
noeviction:不淘汰数据,返回错误。allkeys-lru:从所有键中淘汰最近最少使用的键。volatile-lru:从设置了过期时间的键中淘汰最近最少使用的键。allkeys-random:从所有键中随机淘汰键。volatile-random:从设置了过期时间的键中随机淘汰键。volatile-ttl:从设置了过期时间的键中淘汰剩余时间最短的键。
在 Redis 4.0 版本中又新增了 2 种淘汰机制:
- volatile-lfu:淘汰所有设置了过期时间的键值中,最少使用的键值;
- allkeys-lfu:淘汰整个键值中最少使用的键值。
Redis 的事务机制如何工作?
- 开始事务(MULTI):客户端发送
MULTI命令,标记事务的开始。 - 命令入队:后续发送的命令不会立即执行,而是进入队列等待。
- 执行事务(EXEC):客户端发送
EXEC命令,Redis 按顺序执行队列中的所有命令。 - 返回结果:EXEC 返回所有命令的执行结果,顺序与入队时一致。
示例代码:
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> SET key1 "value1"
QUEUED
127.0.0.1:6379> SET key2 "value2"
QUEUED
127.0.0.1:6379> EXEC
1) OK
2) OK
2. 事务的关键特性
原子性(Atomicity)
- 单条命令原子性:Redis 保证单个命令的原子性(如
INCR操作不会被打断)。 - 事务级原子性:Redis 事务不支持回滚,若队列中某个命令失败(如类型错误),其他命令仍会继续执行。
MULTI SET key1 "value1" INCR key1 # 错误:对字符串执行 INCR SET key2 "value2" EXEC # 结果:key1 被设置,key2 也被设置,INCR 失败
隔离性(Isolation)
- Redis 是单线程执行命令,事务执行期间不会被其他客户端命令打断,保证了事务的隔离性。
3. WATCH 机制(乐观锁)
Redis 提供 WATCH 命令实现乐观锁,用于实现 CAS(Compare-and-Swap)操作:
- 原理:在
MULTI前使用WATCH监视一个或多个键,若事务执行前这些键被其他客户端修改,则整个事务会被放弃(EXEC 返回nil)。 - 典型场景:实现分布式锁或计数器的原子递增。
示例:库存扣减(CAS 操作)
WATCH stock # 监视库存键
GET stock # 获取当前库存
# 判断库存是否足够,若足够则执行事务
MULTI
DECRBY stock 1
EXEC # 若期间 stock 被修改,EXEC 返回 nil,需重试
4. 事务的局限性
- 不支持回滚:Redis 认为 “错误通常由编程错误导致”,因此不支持事务回滚,简化了内部实现。
- 串行执行:事务中的命令按顺序执行,无法并发,可能影响性能。
- 不支持嵌套:Redis 事务不能嵌套,每个事务必须以
MULTI开始,EXEC结束。
5. 与其他数据库事务的对比
| 特性 | Redis 事务 | 传统数据库(如 MySQL) |
|---|---|---|
| 原子性 | 部分支持(不支持回滚) | 完全支持(ACID) |
| 隔离性 | 基于单线程保证 | 通过锁或 MVCC 实现 |
| 持久性 | 依赖持久化配置 | 通常通过 WAL 保证 |
| 嵌套事务 | 不支持 | 支持 |
| 复杂查询 | 仅支持简单命令组合 | 支持 SQL 复杂查询 |
6. 最佳实践
- 替代方案:对于复杂事务需求,可考虑使用 Lua 脚本(Redis 保证脚本执行的原子性)。
-- 原子性地实现库存扣减 if redis.call("GET", "stock") > 0 thenredis.call("DECR", "stock")return 1 elsereturn 0 end - 错误处理:事务执行后需检查返回值,若 EXEC 返回
nil,需重试整个操作。 - 性能考量:避免在事务中包含大量命令,减少客户端等待时间。
Redis 的性能优化有哪些方法?
Redis 的性能优化方法包括:
- 使用合适的数据结构:根据场景选择最合适的数据结构。
- 减少网络延迟:将 Redis 部署在靠近应用服务器的地方。
- 批量操作:使用
MGET、MSET等命令减少网络请求次数。 - 持久化优化:根据业务需求选择合适的持久化策略。
- 根据业务需求设置合理的内存淘汰策略(
maxmemory-policy),如allkeys-lru(适合缓存场景)或volatile-lru(适合带过期时间的键)。 - 限制最大内存(
maxmemory),防止 Redis 因内存溢出崩溃。