mysql 复习
mysql定义与架构
数据库是按照数据结构来组织、存储和管理数据的仓库,方便我们增删查改。MySQL有客户端和服务器端,基于网络服务的,3306端口处于监听状态。
数据库的存储介质有以下两种:
- 磁盘,比如MySQL就是一种磁盘数据库。
- 内存,比如redis就是一种内存数据库。
数据库服务器、数据库和表的关系如下:
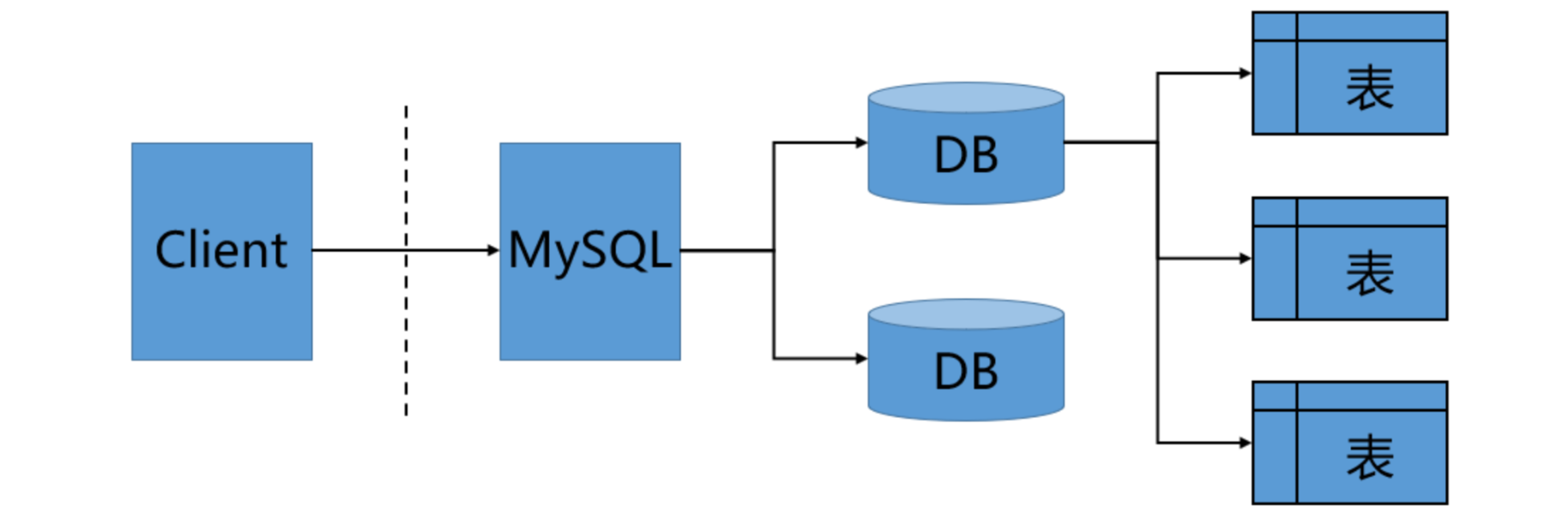
MySQL的架构设计如下:
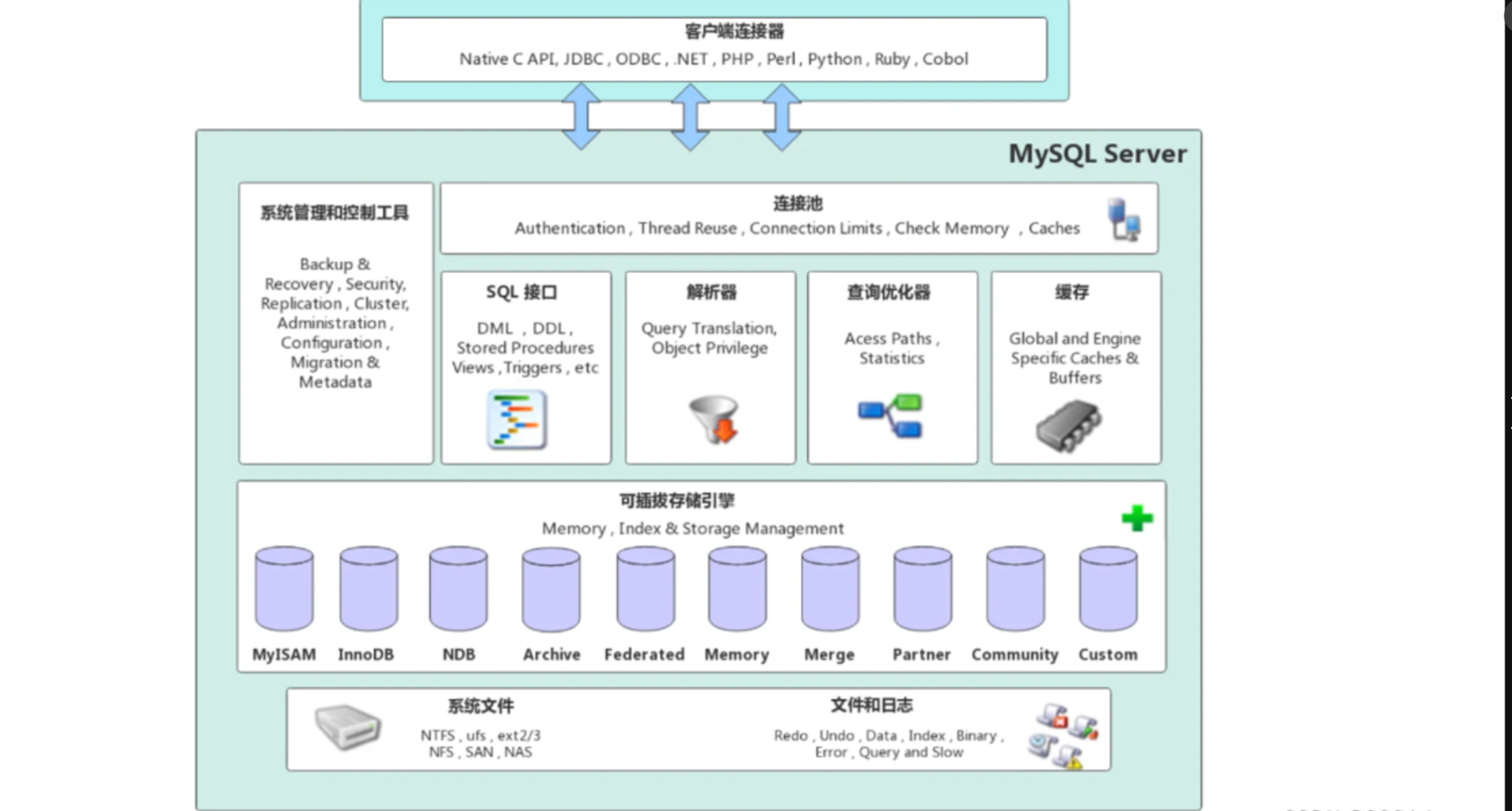
引擎层:由多种可拔插的存储引擎共同组成,真正负责MySQL中数据的存储和提取。
通过show engines语句可以查看MySQL支持的存储引擎,其中MySQL底层默认使用的存储引擎是InnoDB,该存储引擎支持事务、行级锁、外键等。
mysql数据类型
char和varchar比较
char和varchar的区别如下:
- char类型可存储字符上限为255,varchar类型可存储字符上限与表的编码格式有关。
- char(L)定义后,无论存储的字符串长度是否到达L,都会开辟用于存储L个字符的定长空间,如果存储的字符串长度超过L则会报错。
- varchar(L)定义后,会根据存储字符串的长度按需开辟空间,并且需要使用1-3字节的空间用于表示存储字符串的长度以及其他控制信息,如果存储的字符串长度超过L则会报错。
如何选取char和varchar类型?
char和varchar的优缺点如下:
- char类型的数据是定长的,因此磁盘空间比较浪费,但是效率高(直接访问定长的空间)。
- varchar类型的数据是变长的,因此磁盘空间比较节省,但是效率低(需要先读取存储字符串的长度,再访问指定长度的空间)。
MySQL表的约束
主键约束:

外键
- 外键用来定义主表和从表之间的关系,外键约束主要定义在从表上,主表必须有主键约束或唯一键约束。班级id中对应学生表的班级id
- 外键定义后,要求插入外键列的数据必须在主表对应的列存在或为null。
Mysql表的增删改
truncate截断表,表数据清楚重置,不可回滚,同时自增字段从0开始,delete from没有where子句则删除表数据。
update和delete都要配合where来使用。
mysql的单表查询
筛选分页结果
从第s条记录开始,向后筛选出n条记录:
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n; s默认为0
SQL中各语句的执行顺序
- where筛选符合条件。
- 根据group by子句对数据进行分组。需要配合聚合函数使用。
- 将分组后的数据依次执行select语句。
- 根据having子句对分组后的数据进行进一步筛选。
- 根据order by子句对数据进行排序。
- 根据limit子句筛选若干条记录进行显示。
显示平均工资低于2000的部门和它的平均工资

分组查询后的select 列只能是分组列,和聚合函数列,group by两列则需要两列相同。
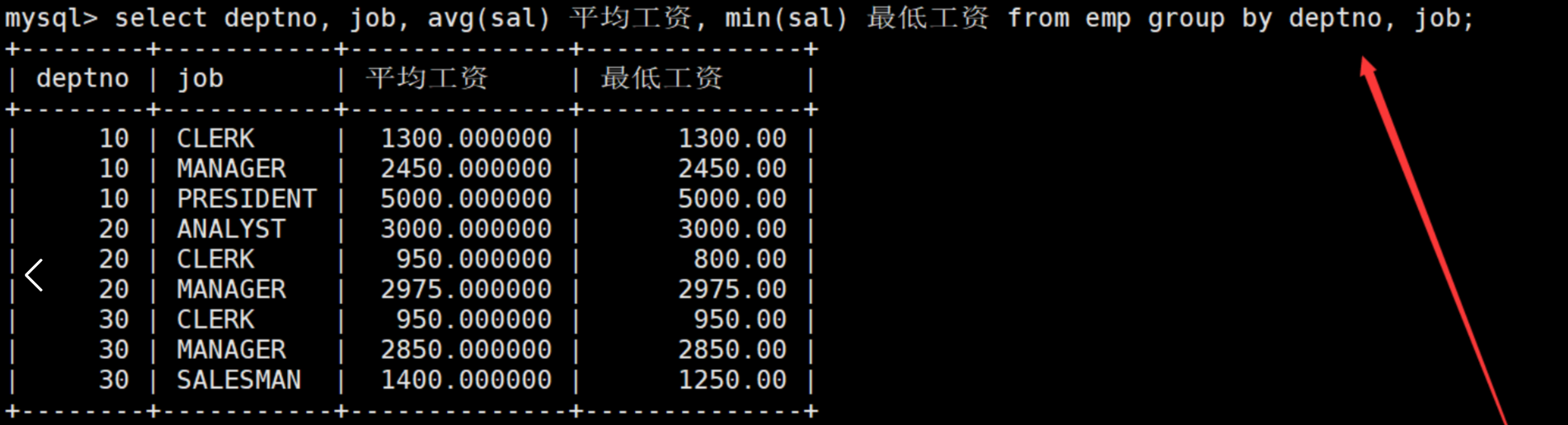
显示每个部门的每种岗位的平均工资和最低工资
在group by子句中指明依次按照部门号和岗位进行分组,在select语句中使用avg函数和min函数,分别查询每个部门的每种岗位的平均工资和最低工资。如下:
Mysql 多表查询
就是from两张表。同时select 列字段指名emp.name,dept.deptno具体指定。
from emp ,dept 对多张表取笛卡尔积,就是得到这多张表的记录的所有可能有序对组成的集合,比如下面对员工表和部门表进行多表查询,由于查询语句中没有指明筛选条件,因此最终得到的结果便是员工表和部门表的笛卡尔积。 多表查询使用where子句筛选得到有意义的结果。
显示部门号为10的部门名、员工名和员工工资
由于部门名只有部门表中才有,而员工名和员工工资只有员工表中才有,因此需要同时使用员工表和部门表进行多表查询,在where子句中指明筛选条件为员工的部门号等于部门编号,并且部门号为10的记录。如下:

自连接
- 自连接是指在同一张表进行连接查询,也就是说我们不仅可以取不同表的笛卡尔积,也可以对同一张表取笛卡尔积。
- 如果一张表中的某个字段能够将表中的多条记录关联起来,那么就可以通过自连接将表中通过该字段关联的记录组合起来。
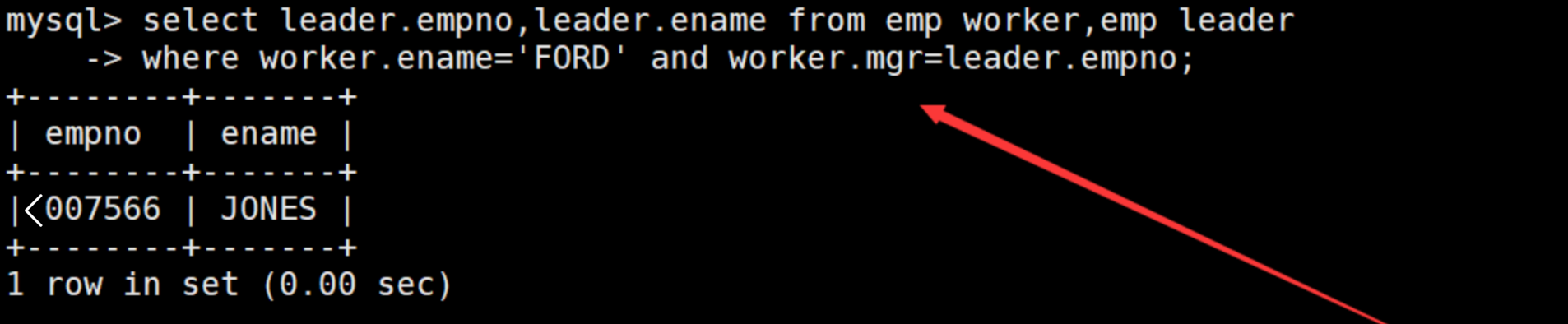
显示员工FORD的上级领导的编号和姓名
也可以用slect子查询解决。
1. 指名从leader表中取出对应列 2.指名两表连接之后的筛选条件。
多表的内外连接
from两表,在where条件下进行多表查询的方式本质就是内连接,用标准的内连接SQL编写:
- from 员工表 inner join 部门表 on连接条件
- 在on子句后指明内连接的条件为员工的部门号等于部门的部门号,保证筛选出来的数据是有意义的。
- 在and之后指明筛选条件为员工的姓名为SMITH,也可以改为where子句。

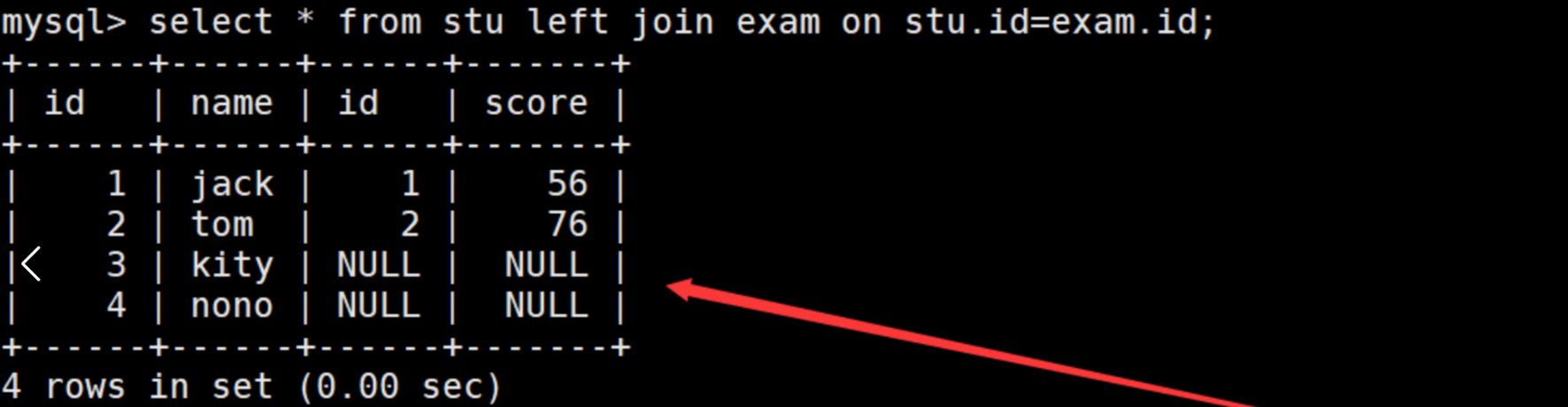
左外连接
学生表和成绩表。要求将没有成绩的学生的个人信息也要显示出来,可将左边学生表为主表。
MySQL索引
构建索引就是构建一颗page组成的 B+树。
- 数据库表中存储的数据都是以记录为单位的,如果在查询数据时直接一条条遍历表中的数据记录,那么查询的时间复杂度将会是 O ( N )
- 索引虽然提高了数据的查询速度,但在一定程度上也会降低数据增删改的效率,因为这时在对表中的数据进行增删改操作时,除了需要进行对应的增删改操作之外,可能还需要对底层建立的数据结构进行调整维护。
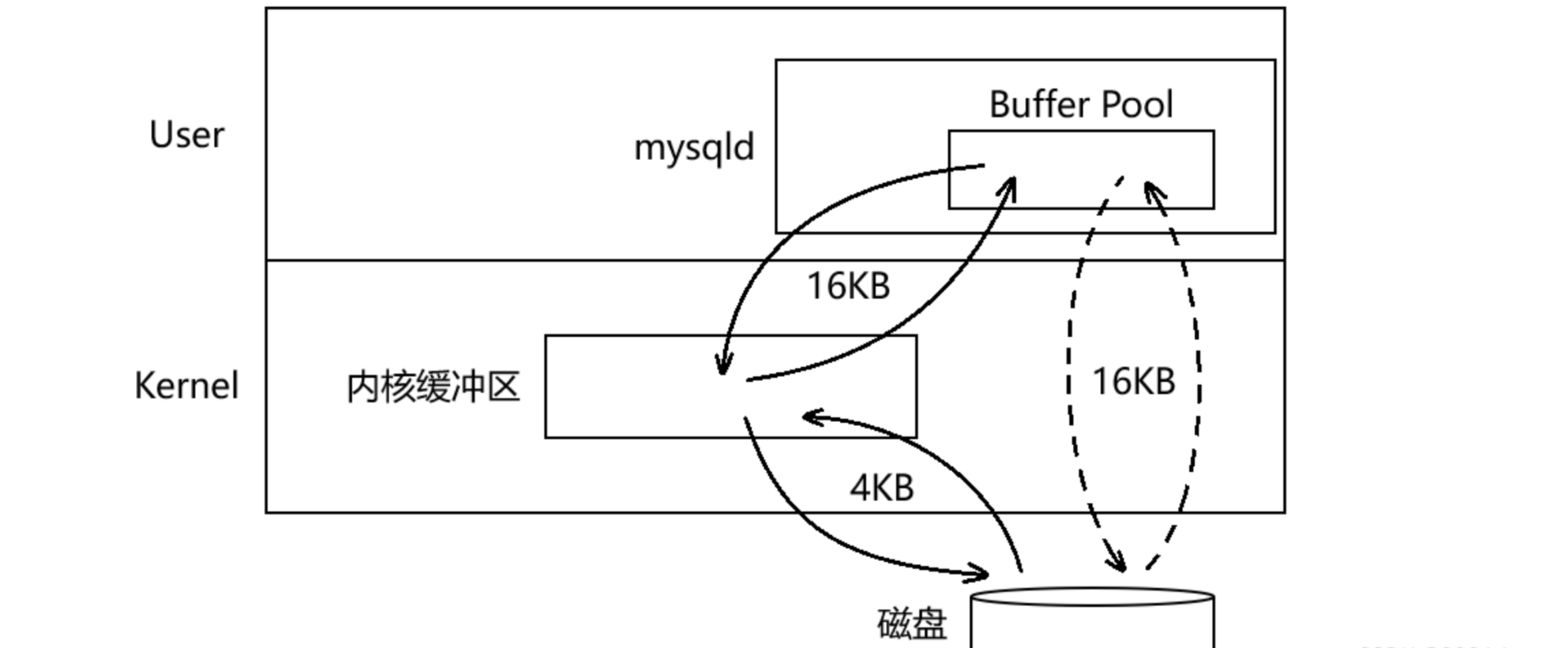
MySQL服务器在启动的时候会预先申请一块内存空间来进行各种缓存,这块内存空间叫做Buffer Pool,后续磁盘中加载的数据就会保存在Buffer Pool中,刷新数据时也就是将Buffer Pool中的数据刷新到磁盘。MySQL的Buffer Pool与内核缓冲区之间是以16KB为单位进行交互的。
MySQL与磁盘进行交互时以Page为基本单位,利用了局部性原理。可以减少与磁盘IO交互的次数,进而提高IO的效率。
当向表中插入数据时是乱序插入的,MySQL底层会自动按照主键对插入的数据进行排序。
- MySQL将内存中的每一个Page都用一个结构体描述起来,然后再将各个结构体以双链表的形式组织起来,因此一个Page结构体内部既包含数据字段,也包含属性字段。
- 此外,为了方便后续数据的插入和删除,每个Page结构体内部存储的数据记录会以单链表的形式组织起来,并且各个记录之间会按照主键进行排序。如下主键 12345
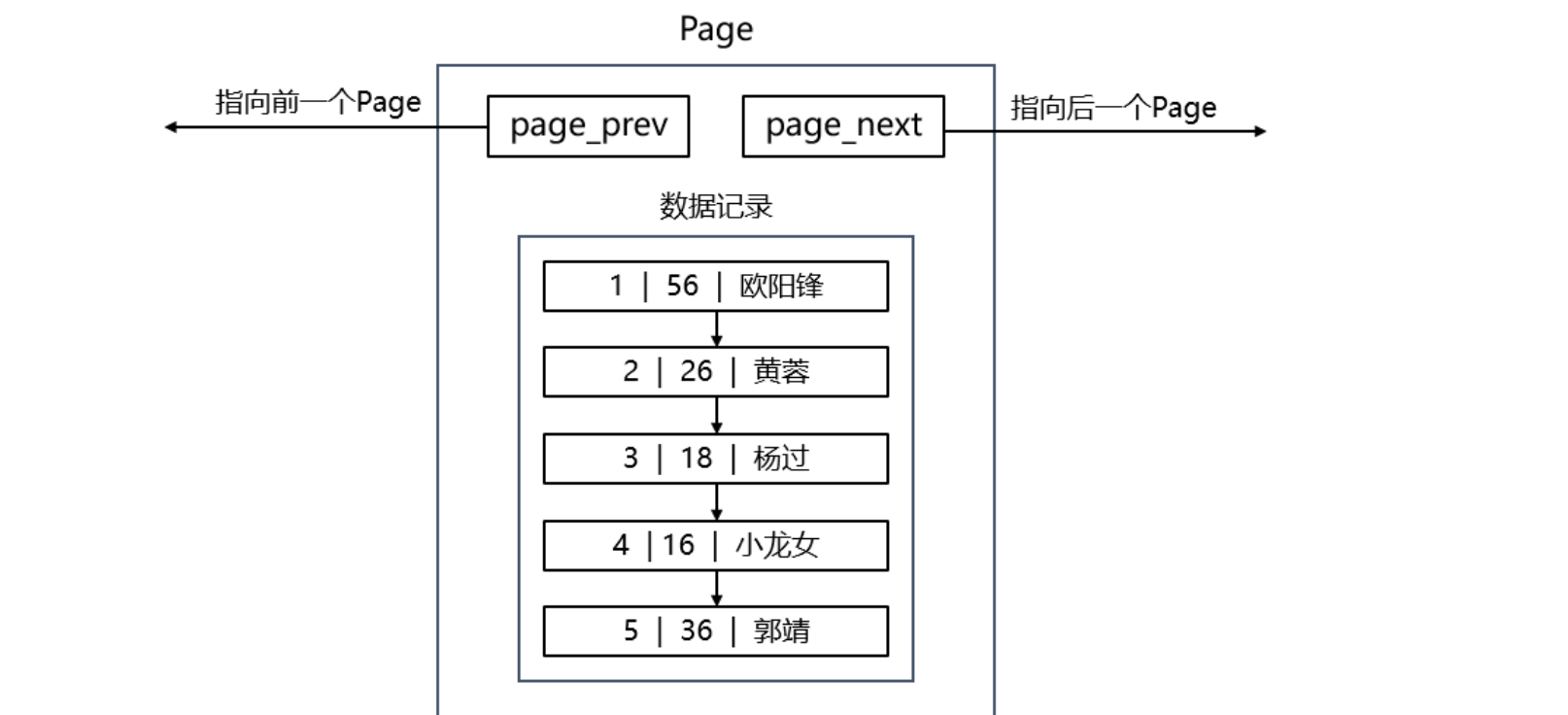
单个Page内创建页内目录
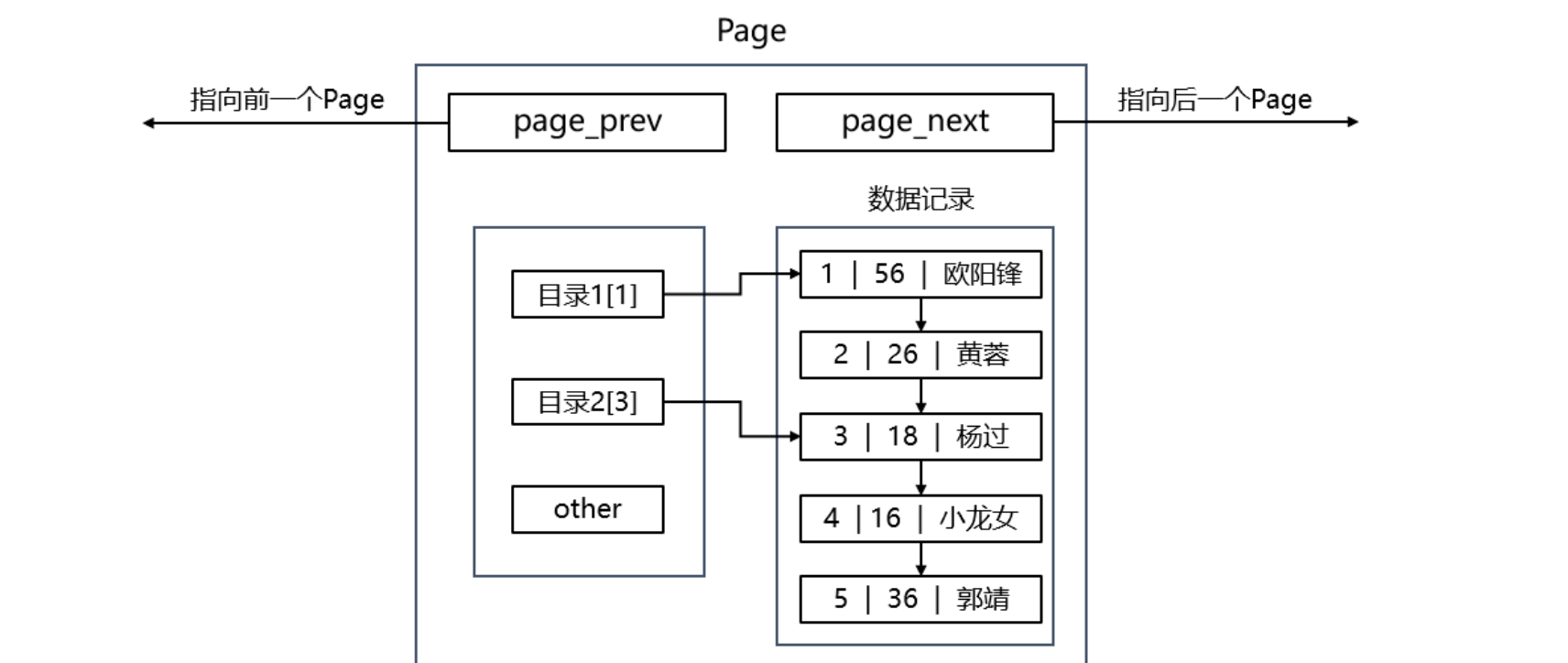
Page之上创建页目录,页目录之上再创建页目录
最终 page 构建出来的B+树 结构如下:
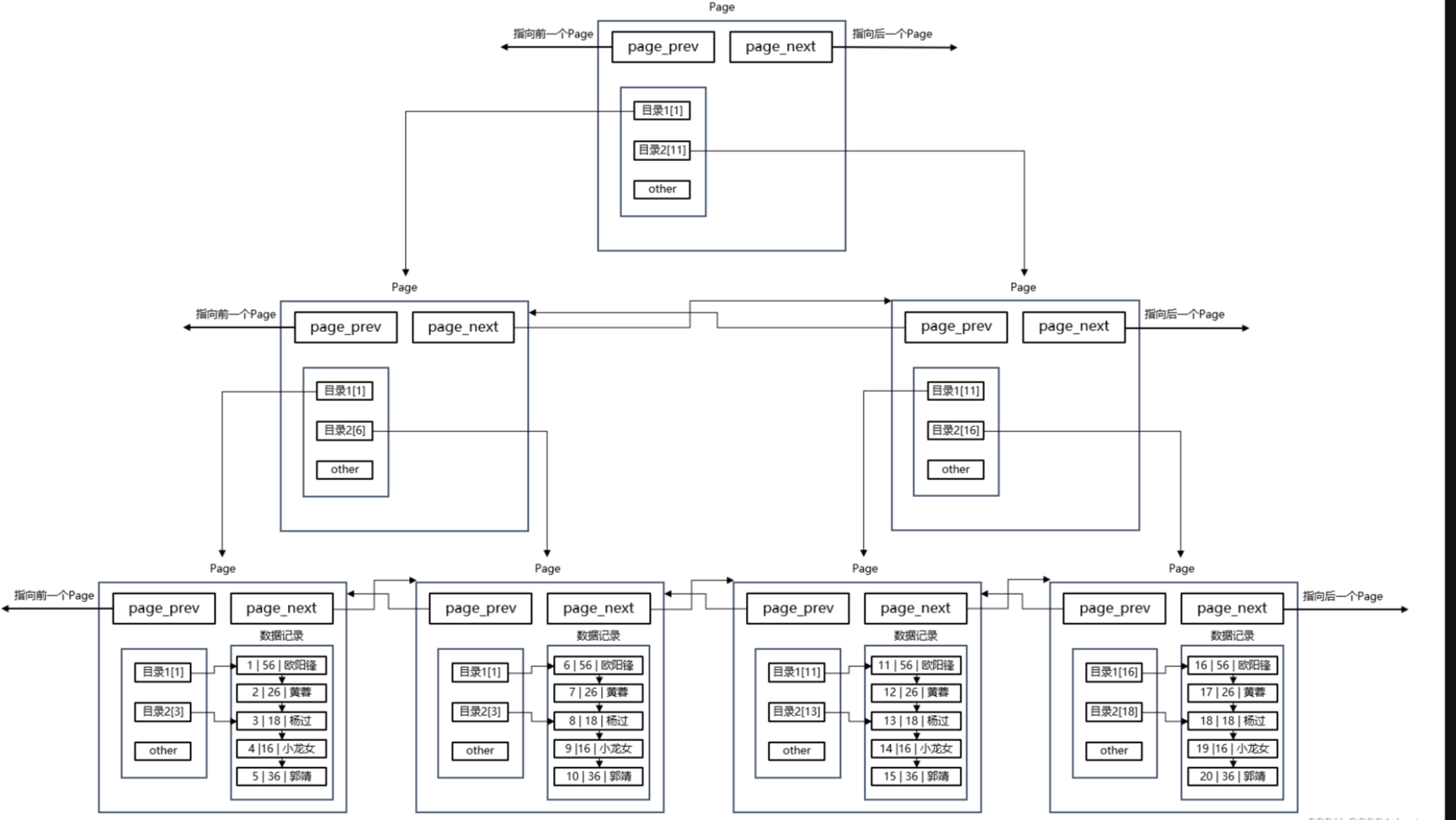
MySQL中可能同时有大量的表正在被处理,因此Buffer Pool中可能会存在多个索引结构,也就是同时存在多个B+树结构,当我们查询表时访问的就是这张表对应的B+树结构。MyISAM和InnoDB存储引擎都是采用的B+树结构。
- 刚开始时只需要将B+树的根结点(page)加入到Buffer Pool中。
- 当后续访问表中的数据时,再将该数据对应路径上的结点加入到Buffer Pool中即可,对于其他不需要的结点根本不用加入到Buffer
B树的缺点:
1. 普通B树中的所有结点中都同时包括索引信息和数据信息,因此非叶子结点中如果包含了数据信息,那么这些结点中能够存储的索引信息一定会变少,这时这棵树形结构一定会变得更高更瘦
2. 其次,普通B树中的各个叶子结点之间没有连接起来,这将不利于进行数据的范围查找。hash表结构也是。
InnoDB和MyISAM索引的不同
1. MyISAM存储引擎的 任何索引的B+树的叶子结点存放的不是数据记录,而是数据记录对应的地址。它产生 .myi,.myd,.frm三个文件。
2.InnoDB存储引擎的普通索引的B+树叶子结点中没有保存整条数据记录,而是保存主键,再根据主键字段去主键B+树做回表查询。 像InnoDB存储引擎这种,将数据记录与索引结构放在一起的索引方案,叫做聚簇索引。它产生 .idb,.frm两个文件。
索引创建的原则如下:
- 比较频繁作为查询条件的字段应该创建索引。
- 唯一性太差的字段不适合单独创建索引,因为这样查询时索引只能排除很少的数据。
- 更新非常频繁的字段不适合创建索引。
MYSQL事务
以转账为例子。一个完整的事务并不是简单的SQL集合,事务还需要满足如下四个属性:
- 原子性: 一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中如果发生错误,则会自动回滚到事务开始前的状态,就像这个事务从来没有执行过一样。
- 持久性: 事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
- 隔离性: 数据库允许多个事务同时访问同一份数据,隔离性可以保证多个事务在并发执行时,不会因为由于交叉执行而导致数据的不一致。
- 一致性: 在事务开始之前和事务结束以后,数据库的完整型没有被破坏,这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联型以及后续数据库可以自发性地完成预定的工作。
前三个保证了最后一个,最后一个是业务层面。指的是写入的资料必须完全符合所有的预设规则。事务执行的结果,必须使数据库从一个一致性状态,变到另一个一致性状态,
事务常见的提交方式有两种,分别是自动提交和手动提交。默认自动提交autocommit 是on打开的

隔离级别
读未提交

- 未提交是事务的最低隔离级别,几乎没有加锁,虽然效率高,但是问题比较多,所以严重不建议使用。
- 一个事务在执行过程中,读取到另一个执行中的事务所做的修改,但是该事务还没有进行提交,这种现象叫做脏读。
读已提交
- 一个事务在执行过程中,两个相同的select查询得到了不同的数据,这种现象叫做不可重复读。这是它的问题。
可重复读
- 一般的数据库在可重复读隔离级别下,update数据是满足可重复读的,但insert数据会存在幻读问题,因为隔离性是通过对数据加锁完成的,而新插入的数据原本是不存在的,因此一般的加锁无法屏蔽这类问题。
- 5.0之后的 MySQL是通过Next-Key锁(GAP+行锁)来解决幻读问题的。
串行化(Serializable)
- 串行化是事务的最高隔离级别,多个事务同时进行读操作时加的是共享锁,因此可以并发执行读操作,但一旦需要进行写操作,就会卡住,必须等其它事务结束。就会进行串行化,效率很低,几乎不会使用。
多版本并发控制
读-读并发不需要进行并发控制,写-写并发实际也就是对数据进行加锁,这里最值得讨论的是读-写并发,读-写并发是数据库当中最高频的场景,在解决读-写并发时不仅需要考虑线程安全问题,还需要考虑并发的性能问题。
多版本并发控制
- 多版本并发控制(Multi-Version Concurrency Control,MVCC)是一种用来解决读写冲突的无锁并发控制,主要依赖记录中的3个隐藏字段、undo日志和Read View实现。
- 为事务分配单向增长的事务ID,为每个修改保存一个版本,将版本与事务ID相关联,读操作只读该事务开始前的数据库快照。
- MVCC保证读写并发时,读操作不会阻塞写操作,写操作也不会阻塞读操作,提高了数据库并发读写的性能,同时还可以解决脏读、幻读和不可重复读等事务隔离性问题。
记录中的3个隐藏字段
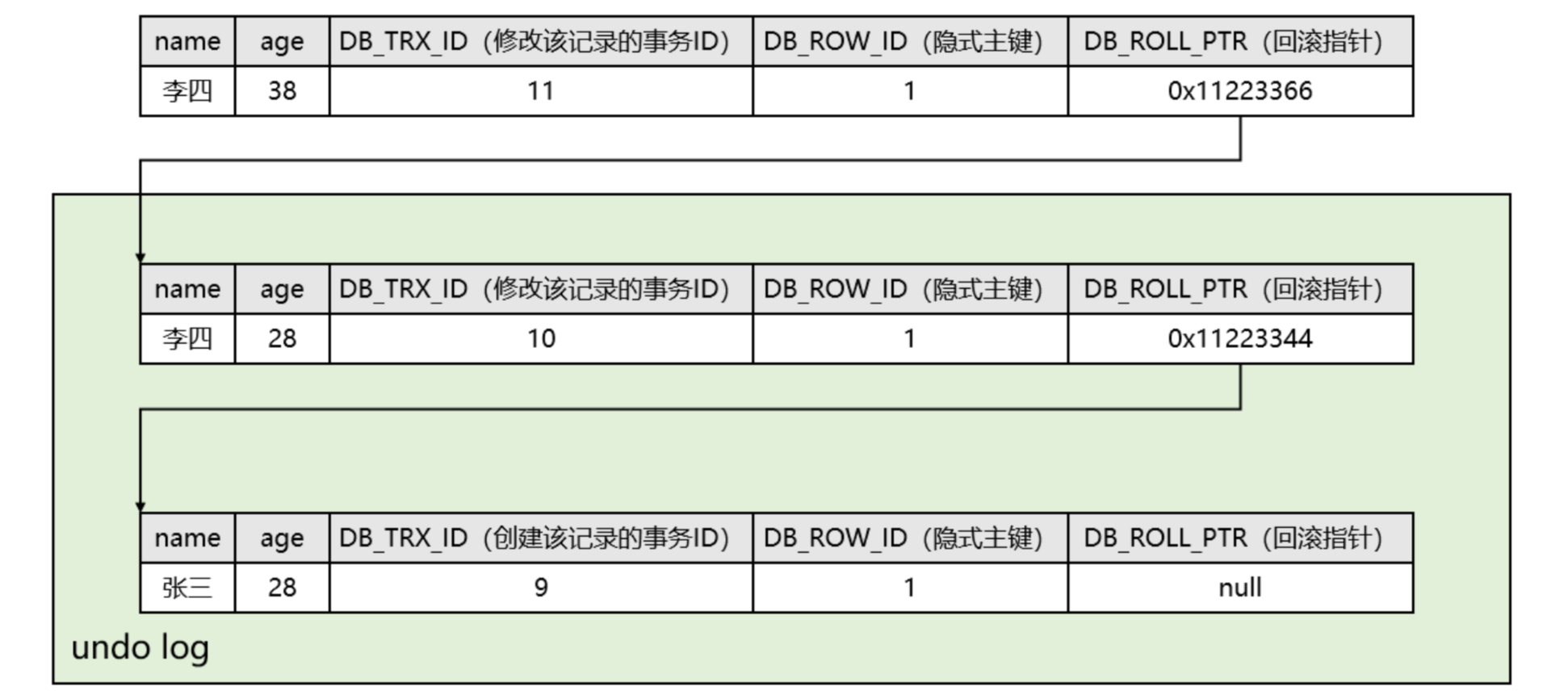
当向 学生表中插入一条记录后,该记录不仅包含name和age字段,还包含三个隐藏字段。如下:

undo日志
维护一个个版本链,由事务id和回滚指针连接。
MySQL的三大日志如下:
- redo log:重做日志,用于MySQL崩溃后进行数据恢复,保证数据的持久性。
- bin log:逻辑日志,用于主从数据备份时进行数据同步,保证数据的一致性。
- undo log:回滚日志,用于对已经执行的操作进行回滚,保证事务的原子性。
快照的概念
现在有一个事务ID为10的事务,要将刚才插入学生表中的记录的学生姓名改为“李四”:
- 因为是要进行写操作,所以需要先给该记录加行锁。
- 修改前,先将该行记录拷贝到undo log中,此时undo log中就有了一行副本数据。
- 然后再将原始记录中的学生姓名改为“李四”,并将该记录的DB_TRX_ID改为10,回滚指针DB_ROLL_PTR设置成undo log中副本数据的地址,从而指向该记录的上一个版本。
- 最后当事务10提交后释放锁,这时最新的记录就是学生姓名为“李四”的那条记录。
insert和delete的记录如何维护版本链?
删除记录并不是真的把数据删除了,而是先将该记录拷贝一份放入undo log中,然后将该记录的删除flag隐藏字段设置为1,这样回滚后该记录的删除flag隐藏字段就又变回0了,相当于删除的数据又恢复了。 插入删除时利用flag隐藏字段来记录相反的操作即可。
当前读 VS 快照读
- 当前读:读取最新的记录,就叫做当前读。
- 快照读:读取历史版本,就叫做快照读。
事务在进行增删查改的时候,并不是都需要进行加锁保护:
- 事务对数据进行增删改的时候,操作的都是最新记录,即当前读,需要进行加锁保护。
- 事务在进行select查询的时候,既可能是当前读也可能是快照读,如果是当前读,那也需要进行加锁保护,但如果是快照读,那就不需要加锁,因为历史版本不会被修改,也就是可以并发执行,提高了效率,这也就是MVCC的意义所在。读已提交和可重复读两种隔离级别 下会出现快照读。
快照读读哪个由 生成的 Read View判断
事务在进行快照读操作时会生成读视图Read View,在该事务执行快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃的事务ID。据这个Read View来判断,当前事务能够看到该记录的哪个版本的数据。
RR与RC的本质区别
- 在RR级别下,事务第一次进行快照读时会创建一个Read View,将当前系统中活跃的事务记录下来,此后再进行快照读时就会直接使用这个Read View进行可见性判断,因此当前事务看不到第一次快照读之后其他事务所作的修改,所以RR级别是可重复读的。
- 而在RC级别下,事务每次select 都会进行快照读时都会创建一个Read View,然后根据这个Read View进行可见性判断,因此每次快照读时都能读取到被提交了的最新的数据。