Seed-Thinking-v1.5:推理模型新标杆诞生
一、推理模型新标杆诞生
4 月 17 日,字节跳动豆包团队发布了一款全新的推理模型——Seed-Thinking-v1.5。这款模型以其卓越的性能和技术突破,迅速在 AI 领域引起了广泛关注。根据技术报告,Seed-Thinking-v1.5 是一款总参数量达 200B 的混合专家(MoE)模型,仅激活 20B 参数,便在数学推理、编程竞赛、科学问答等任务中全面超越了 671B 参数的 DeepSeek-R1,甚至在非推理任务中用户反馈胜率高出 8%。这一突破性成果,无疑将改写推理模型的竞争格局,为 AI 推理领域树立新的标杆。
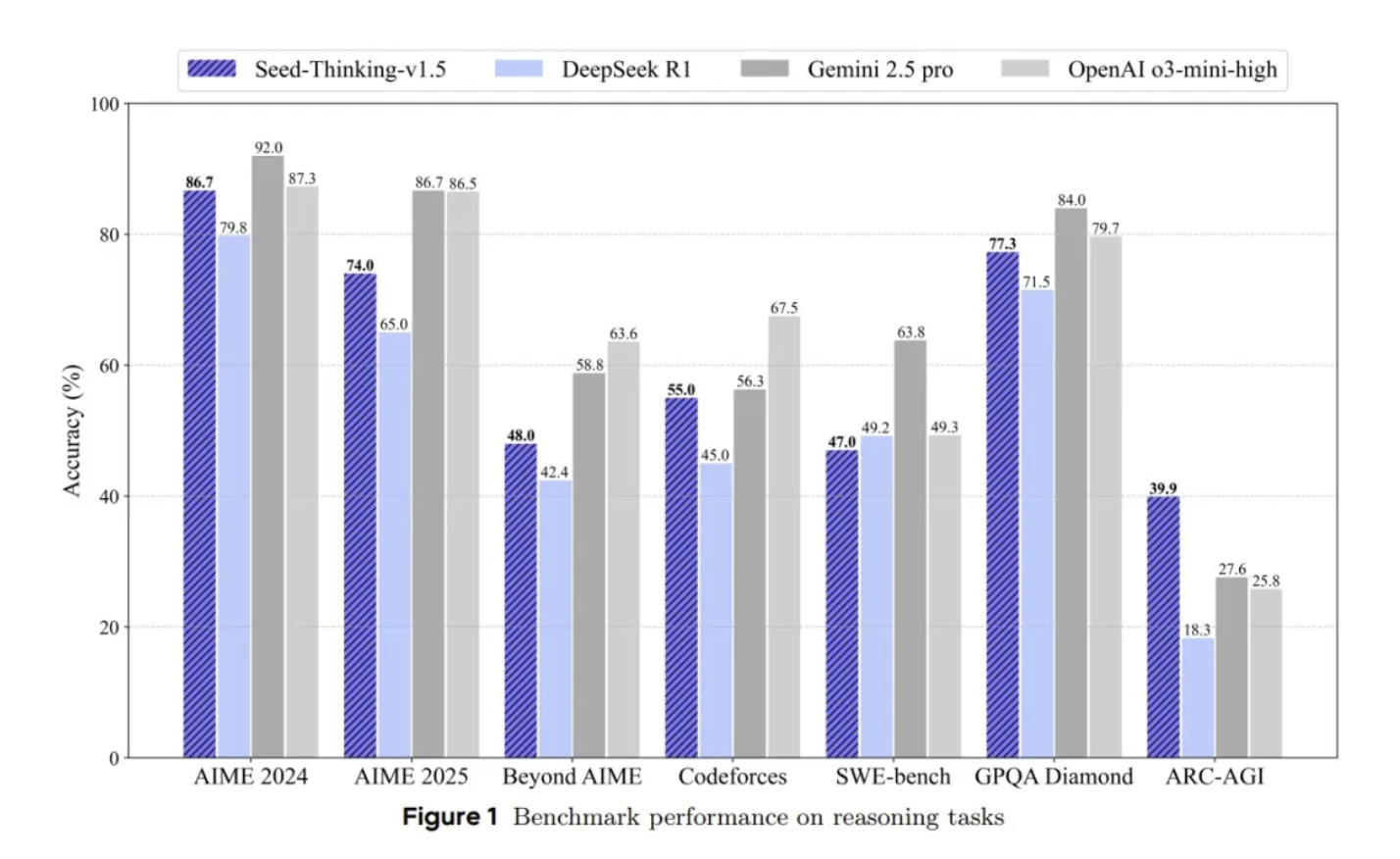 二、性能亮点:全面碾压 DeepSeek-R1
二、性能亮点:全面碾压 DeepSeek-R1
(一)数学推理:AIME 与 BeyondAIME 双冠王
在数学推理领域,Seed-Thinking-v1.5 展现出了惊人的实力。在 AIME 2024 竞赛中,该模型以 86.7 分的成绩,与顶尖闭源模型 o3-mini-high 比肩。此外,在豆包团队自研的超难基准 BeyondAIME 中,Seed-Thinking-v1.5 在 100 道专家级题目中展现了强大的泛化能力,轻松应对各种复杂问题。
(二)编程竞赛:Codeforces 实战封神
在编程竞赛领域,Seed-Thinking-v1.5 同样表现出色。基于最新 12 场 Codeforces 竞赛的真实数据评测,该模型的 Pass@1(单次提交通过率)达到了 55.0 分,Pass@8(8 次提交最佳结果)更是高达 60.1 分。这一成绩不仅在同类模型中遥遥领先,甚至接近人类顶尖选手的水平。
(三)科学问答:GPQA 接近人类专家
在科学问答领域,Seed-Thinking-v1.5 的表现也令人瞩目。在 GPQA 基准测试中,该模型得分高达 77.3,逼近闭源模型 o3 的水平。尤为值得一提的是,Seed-Thinking-v1.5 无需进行领域微调,便能将数学能力直接迁移至科学推理,展现出强大的跨领域推理能力。
三、技术架构解析:200B MoE 的高效秘诀
(一)混合专家模型设计
Seed-Thinking-v1.5 采用了混合专家(MoE)模型架构,总参数量高达 200B,但在实际推理中仅激活 20B 参数,利用率仅为 1/10。这种设计的核心在于动态路由机制,模型能够根据任务类型自动选择最合适的专家模块进行计算,从而在保证性能的同时,大幅降低了计算资源的消耗。
(二)强化学习算法创新
为了进一步提升模型的性能,Seed-Thinking-v1.5 在强化学习算法上进行了创新。该模型采用了 VAPO/DAPO 双框架,有效解决了强化学习训练过程中的不稳定性问题。此外,模型还采用了分层奖励建模设计:
-
可验证问题:Seed-Thinking-Verifier 通过思维链验证答案的本质等价性,确保模型输出的准确性和可靠性。
-
不可验证问题:生成式奖励模型能够精准捕捉语义差异,为模型的训练提供了更丰富的反馈信息。
四、使用方法:三步玩转 Seed-Thinking-v1.5
(一)快速安装
-
克隆 Git 仓库:
bashgit clone https://github.com/ByteDance-Seed/Seed-Thinking-v1.5.git cd Seed-Thinking-v1.5 -
安装依赖(需 Python 3.10+):
bashpip install -r requirements.txt -
下载预训练模型(需申请权限):
bashwget https://models.seed.com/seed-thinking-v1.5.pt
(二)基础推理示例
Python
from seed_thinking import SeedModel# 加载模型(默认激活 20B 参数)
model = SeedModel.from_pretrained("seed-thinking-v1.5.pt")# 数学问题推理
question = "已知 x² + y² = 25,x + y = 7,求 x 和 y 的值"
response = model.generate(question, max_length=200)
print(f"解答过程:\n{response}")(三)进阶功能
微调训练
-
使用自定义数据集(需 JSON 格式):
bashpython train.py \--model_path seed-thinking-v1.5.pt \--train_data math_problems.json \--batch_size 8 \--lr 1e-5
高级配置
-
并行策略:支持 TP(张量并行)+EP(专家并行)混合加速。
-
精度控制:FP8 推理模式可降低 30% 显存消耗。
Python
# 启用 FP8 混合精度
model.set_precision('fp8')# 自定义激活专家数量(默认 8 个)
model.set_experts(num_experts=12)五、训练方法论:数据、算法、工程三位一体
(一)数据策略
Seed-Thinking-v1.5 的训练数据涵盖了 STEM 问题、代码任务、逻辑推理和非推理数据四大类。其中,数学数据的引入显著提升了模型的泛化能力,特别是在 ARC-AGI 测试中表现突出。
(二)基础设施突破
-
流式推演架构:迭代速度提升 3 倍。
-
三层并行计算:TP(张量并行)+EP(专家并行)+SP(序列并行)。
-
FP8 动态精度调度:最大化 GPU 利用率,显著提升训练效率。
六、开源与评测:推动行业研究
Seed-Thinking-v1.5 的开源地址为 GitHub 项目,技术报告也已同步发布。此外,豆包团队还开放了自研评测集,包括 BeyondAIME(超难数学题)和 Codeforces 实战编程集,为研究人员提供了丰富的研究资源。
七、API 服务部署
(一)启动服务
bash
# 启动 API 服务(支持多卡部署)
python api_server.py \--model_path seed-thinking-v1.5.pt \--port 8080 \--gpus 0,1(二)调用示例
Python
import requestspayload = {"prompt": "用 Python 实现快速排序算法","max_length": 500,"temperature": 0.7
}response = requests.post("http://localhost:8080/generate", json=payload)
print(response.json()["result"])八、行业影响与未来展望
(一)参数效率革命
Seed-Thinking-v1.5 仅用 20B 激活参数便实现了 SOTA(State-of-the-Art)性能,大幅降低了推理成本。这一成果不仅为推理模型的发展提供了新的思路,也为 AI 模型的商业化应用带来了新的可能性。
(二)MoE 架构新范式
Seed-Thinking-v1.5 的成功,证明了 MoE 架构在推理任务中的巨大潜力。动态路由机制和分层奖励模型的设计,为行业树立了新的标杆,有望推动更多类似架构的出现。
(三)应用场景扩展
Seed-Thinking-v1.5 的应用场景不仅限于 STEM 领域,还能广泛应用于创意写作等非推理任务。其强大的泛化能力和跨领域推理能力,使其在多个领域都能发挥重要作用。
欢迎留言、一键三连!BuluAI 算力平台新上线通义推理模型QwQ-32B,也可一键部署deepseek!!再也不用为算力发愁嘞, 点击官网了解吧!