在Electron中爬取CSDN首页的文章信息
背景
之前分享了Electron入门的相关文章:https://gitee.com/ruirui-study/electron-demo
后来,我就想在里面多做一些演示给大家看,集成了以下功能及演示:
- 窗口管理、各种方法封装
- 托盘管理
- 菜单管理
- 获取屏幕演示
- 多窗口及通信演示
- 等等……
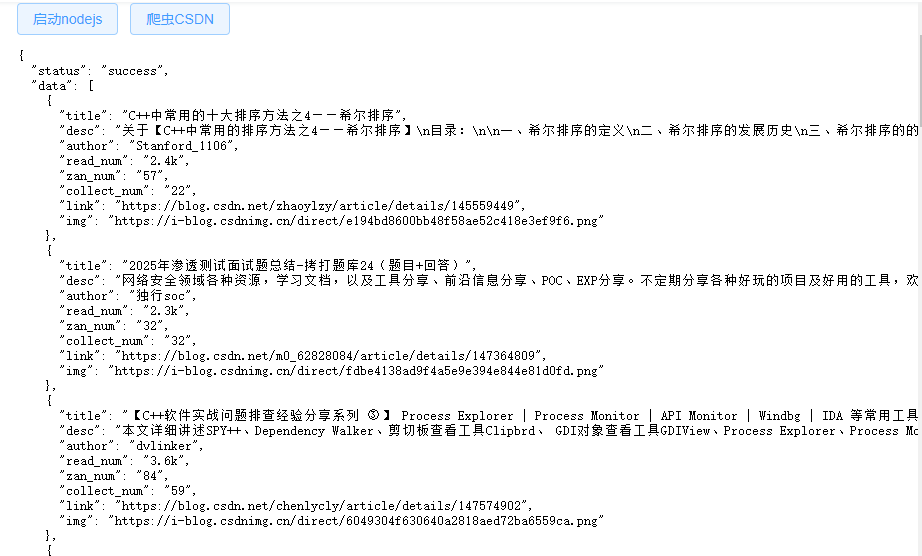
然后,我就想着把之前的nodejs爬虫也集成进来演示,在Electron中做一些结合。先上效果图,这是爬取CSDN首页的数据。
选框架
nodejs的爬虫框架主要有2个
Puppeteer
- 简介:Puppeteer 是由 Google 开发的 Node.js 库,它提供了一个高级 API 来控制 Chrome 或 Chromium 浏览器。通过 Puppeteer,你可以模拟用户在浏览器中的各种操作,如点击、滚动、输入等,从而可以处理动态渲染的页面。
- 优点:能处理复杂的动态网页,支持截图、生成 PDF 等功能。
- 适用场景:适用于需要处理动态内容、模拟用户交互的场景,例如爬取需要登录才能访问的页面、处理包含大量 JavaScript 渲染的页面。
Cheerio
- 简介:Cheerio 本身并非完整的爬虫框架,但它是处理 HTML 和 XML 数据的强大工具,常与其他 HTTP 请求库搭配使用来构建爬虫。它仿照 jQuery 的 API 设计,使得开发者可以像在浏览器中操作 DOM 一样方便地解析和操作抓取到的 HTML 内容。
- 优点:轻量级,学习成本低,对 DOM 操作支持友好。
- 适用场景:适用于需要从 HTML 页面中提取特定数据的场景,例如提取网页中的标题、链接、图片等信息。
开始
由于不涉及复杂的场景,所以本实例选择轻量型的Cheerio框架,主要代码如下:
import axios from "axios";
import * as cheerio from "cheerio";// 目标网页的URL,这里使用 CSDN网站 作为测试,爬取主要文章标题等内容
const targetUrl = "https://www.csdn.net";// 请求目标网页,获取HTML内容
const getHtml = async () => {const response = await axios.get(targetUrl);if (response.status !== 200) {throw new Error("请求失败");}return response.data;
};// 解析HTML内容,获取菜品的标题和图片链接
const getData = async (html) => {const $ = cheerio.load(html);const list = [];$(".article-item").each((i, item) => {// 标题const title = $(item).find(".article-title").text().trim();// 简介const desc = $(item).find(".article-desc").text().trim();// 作者const author = $(item).find(".user-info").text().trim();// 阅读量、点赞量、收藏量const read_num = $(item).find(".article-bottom > div:nth-child(1) .num").text().replace('阅读 ', '');const zan_num = $(item).find(".article-bottom > div:nth-child(2) .num").text().replace('赞', '');const collect_num = $(item).find(".article-bottom > div:nth-child(3) .num").text().replace('收藏 ', '');// 文章链接const link = $(item).find(".article-title").attr("href");// 封面图片const imgStyle = $(item).find(".back-img-banner").attr("style");const img = imgStyle? imgStyle.replace(/\s+/g, '').match(/url\(["']?(.*?)["']?\)/i)?.[1]: ''; // 可设置默认图片list.push({title,desc,author,read_num,zan_num,collect_num,link,img});});return list;
};启动方式
直接启动
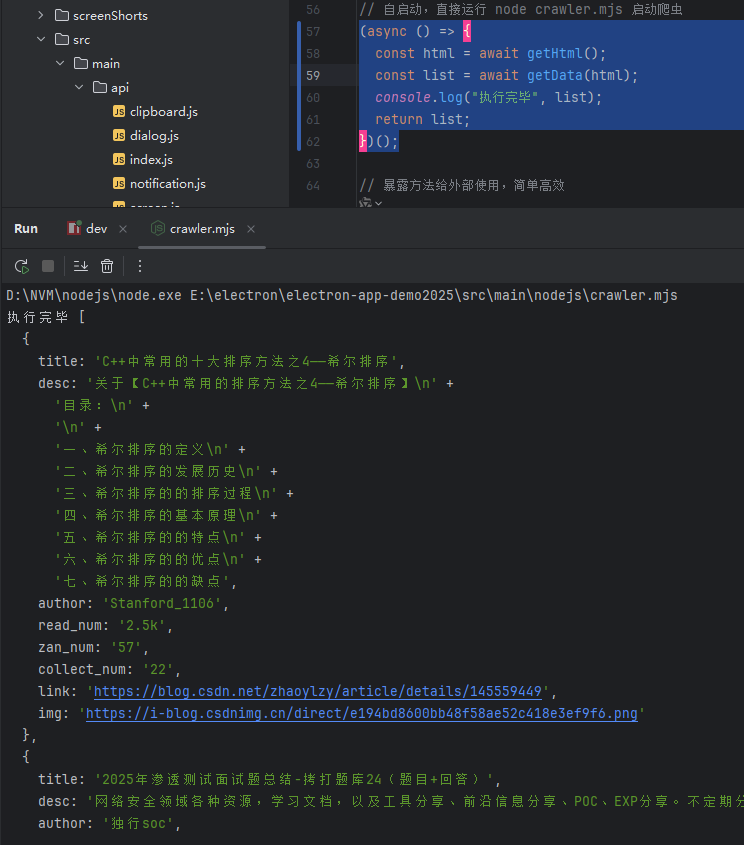
如果你想直接启动,如执行node test.js,可以在末尾加下面的代码:
(async () => {const html = await getHtml();const list = await getData(html);console.log("执行完毕", list);return list;
})();
暴露给主进程
你可以把爬取的结果返回给主进程,主进程再把结果发送给渲染进程,这样就能直接展示在前端界面了:
// 暴露方法给外部使用,简单高效
export async function crawlCSDN() {try {const html = await getHtml();const list = await getData(html);return list;} catch (error) {throw new Error(`爬取失败: ${error.message}`);}
}
然后,你可以在主进程暴露方法给渲染进程,示例如下:
import { crawlCSDN } from '@main/nodejs/crawler.mjs'// CSDN爬虫
ipcMain.handle('crawler-csdn', async () => {try {const data = await crawlCSDN();return { status: 'success', data };} catch (error) {return { status: 'error', message: error.message };}
});
这样,你就可以直接在渲染进程中使用了:
const crawlerCDN = async () => {try {const result = await window.electron.ipcRenderer.invoke('crawler-csdn');console.log('crawler-csdn - result', result)crawlerInfo.value = result;} catch (error) {console.error('Error crawler-csdn:', error);}
};