Mysql如何高效的查询数据是否存在
文章目录
- 1. 三种方法
- 2. 查询语句执行流程
- 3. 三种方式对比
1. 三种方法
在业务中,我们有时候需要查询某个数据在数据表中是否存在,常见的方式有三种
SELECT COUNT(*) FORM tb_name WHERE conditionSELECT 1 FROM tb_name WHERE conditionSELECT EXISTS (SELECT 1 FROM tb_name WHERE condition)
2. 查询语句执行流程
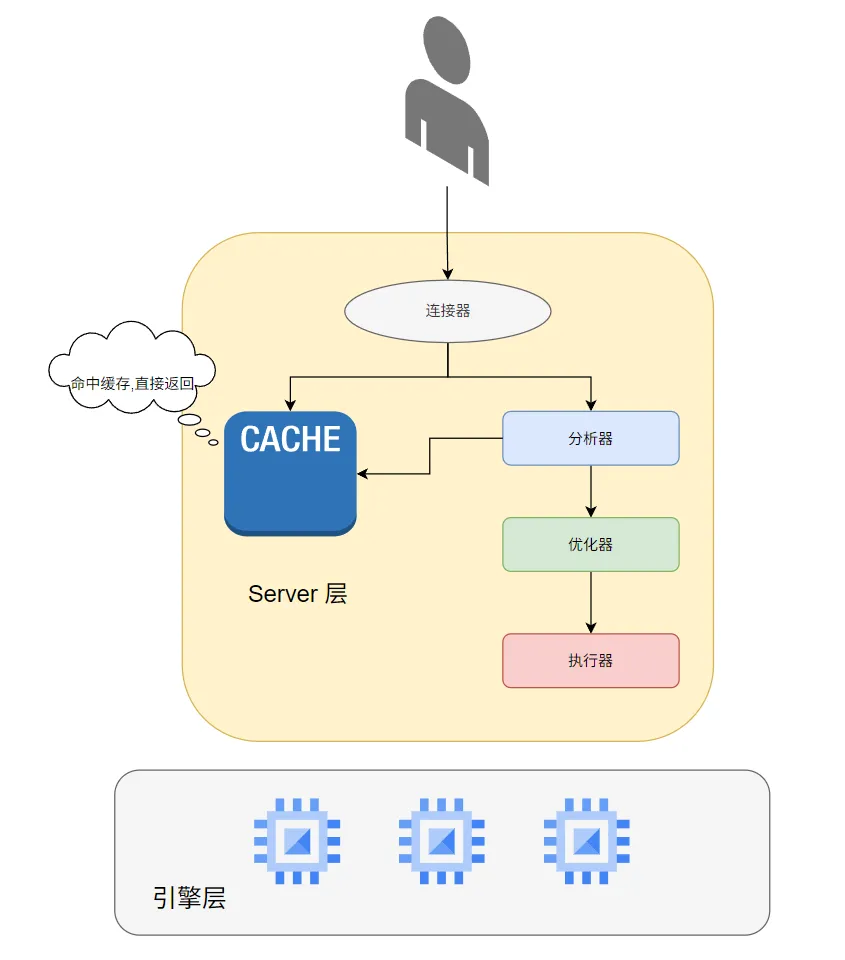
其中:查询语句的执行流程是:
分析器 -> 权限校验 -> 执行器 -> 引擎 -> redo log(prepare状态) -> binlog -> redo log(commit状态)
3. 三种方式对比
在我们没有设置索引的前提下,执行SELECT COUNT 的时候,会在存储引擎层进行全表扫描,将所有符合查询条件的数据全部都找到,返回到Server层,再到Server层进行数据统计,将结果返回给用户
但是实际上,我们的目的是查询表里面是否有我们需要的数据即可,没有必要将所有的数据都查到
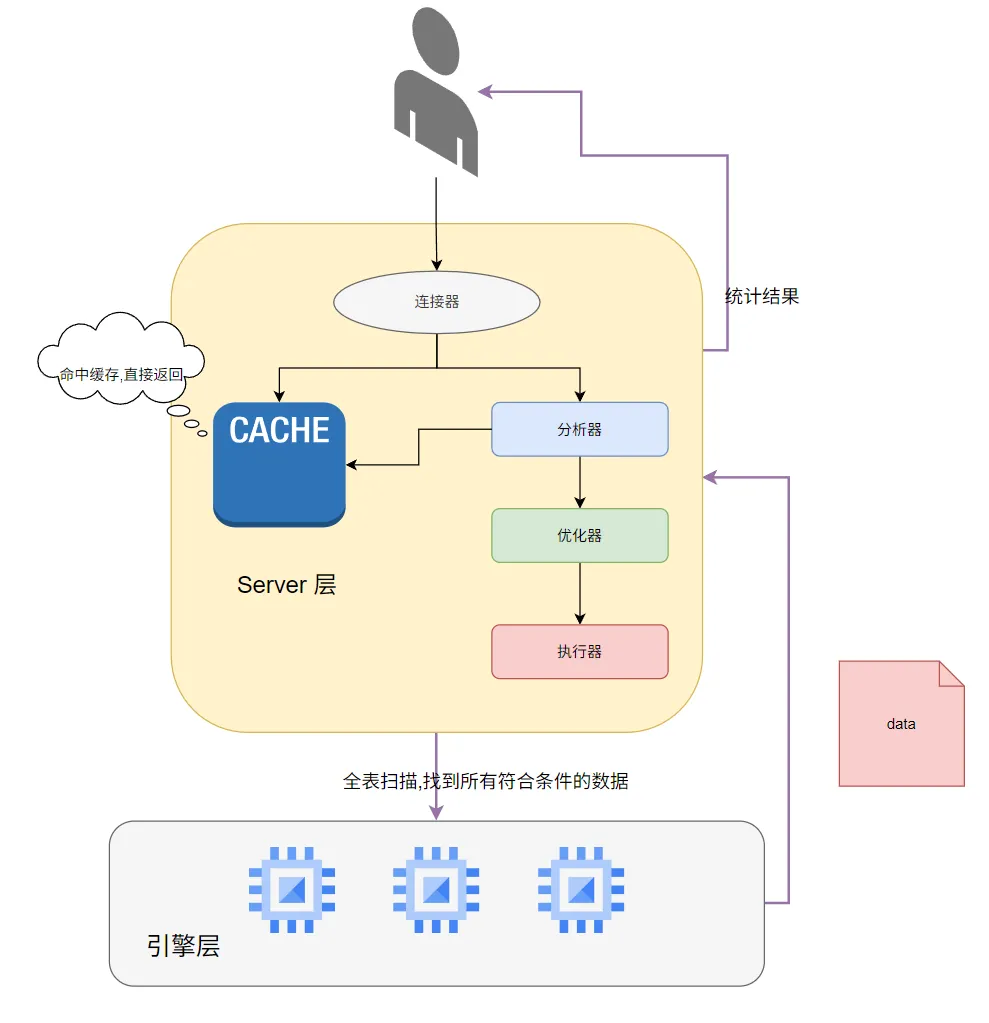
因此我们可以使用limit来进行改善
同样这种方式,在没有设置索引的情况下,也会进行全表扫描,但是通过这种方式,一旦通过条件,找到一条需要的数据,就不会再找了,将这条数据直接返回到Server层
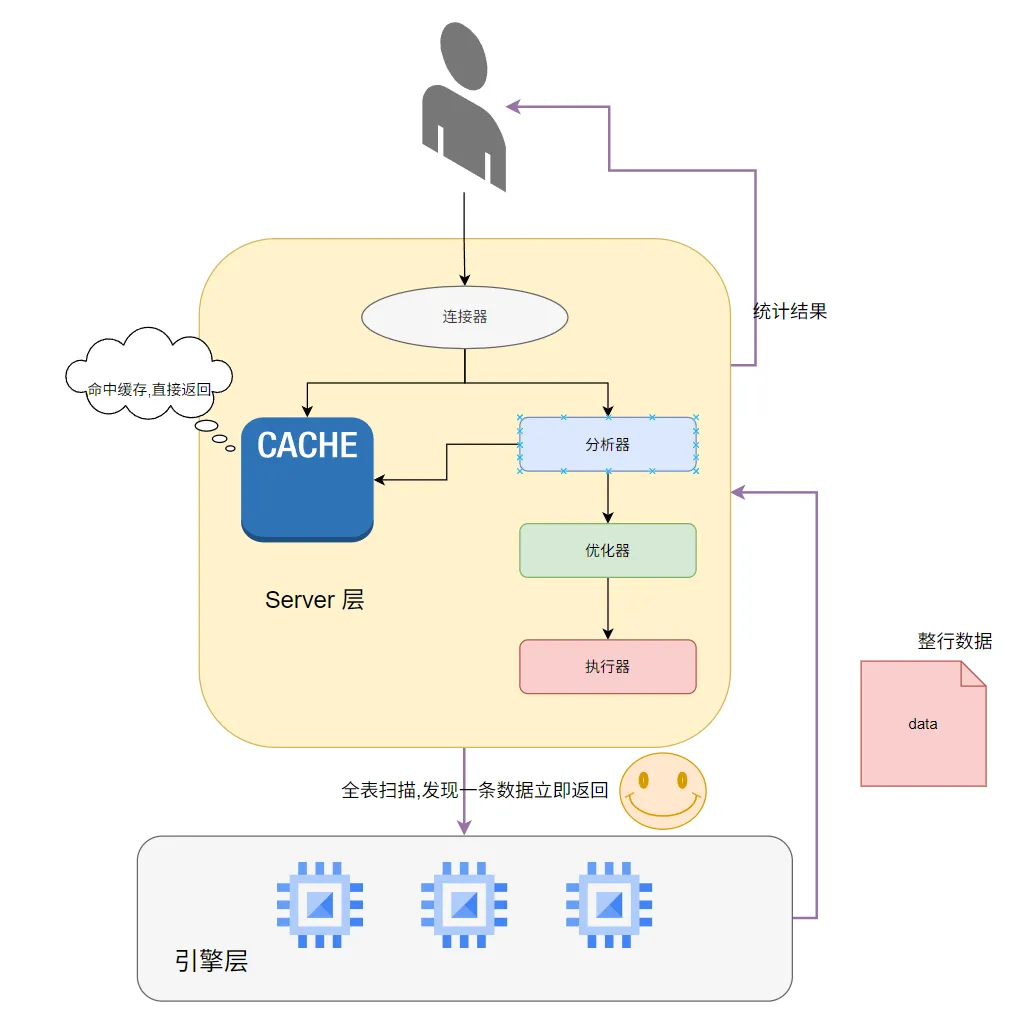
这种方式的性能肯定比直接COUNT要好,因为他只会检索到一条数据
但是实际上,我们只需要知道表里面是否存在数据,我们并不需要整行的数据,因此可以使用EXISTS来进行再次优化
通过这种方式,通过LIMIT 1在引擎层进行检索,只要发现了数据,直接返回TRUE,再到SERVER层进行处理,最终返回1 / 0,表示存在 / 不存在
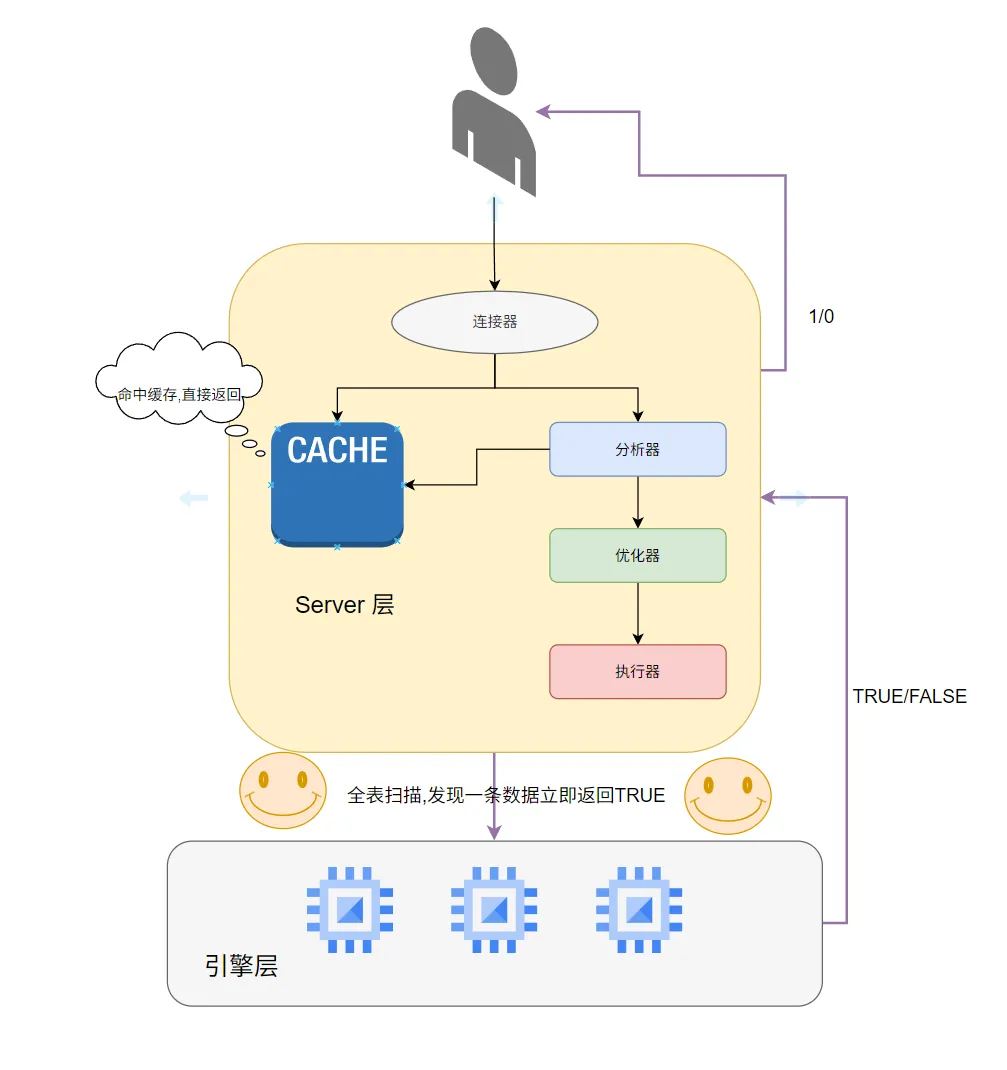
经过对比,很明显COUNT的性能是最低的,LIMIT 1和EXISTS假设在数据量很小的情况下,当然差别不大,但是假设数据行里面是大文本内容,就会影响一定的性能
因此EXISTS通常是最好的方式