xVerify:推理模型评估的革新利器,重塑LLM答案验证格局?
在大语言模型(LLM)蓬勃发展的今天,推理模型不断涌现,但如何精准评估其回答的正确性却成了难题。本文提出的xVerify或许能带来转机。它是专为推理模型评估设计的高效答案验证器,表现卓越。想知道它是如何做到的吗?让我们一探究竟。
论文标题
xVerify: Efficient Answer Verifier for Reasoning Model Evaluations
来源
arXiv:2504.10481v1 [cs.CL] 14 Apr 2025
https://arxiv.org/abs/2504.10481
代码
https://github.com/IAAR-Shanghai/xVerify
文章核心
研究背景
随着思维链(CoT)提示法的出现以及OpenAI的o1模型等推理模型的兴起,LLM在复杂任务上的表现提升,但模型输出包含冗长推理过程,这给现有评估方法带来巨大挑战。
研究问题
- 现有评估方法难以从推理模型的冗长输出中准确提取最终答案,比如面对复杂数学推理过程中的中间结果和冗余信息时,无法精准定位最终答案。
- 对于LLM输出答案与参考答案的等价判断存在困难,像不同形式但语义等价的答案(“alpha”与“α” 、“1000”与“(10^3)” )难以有效识别。
- 目前缺乏专门针对客观问题推理评估的有效自动方法,规则基评估框架和基于LLM的判断方法都存在各自的局限性。
主要贡献
- 构建VAR数据集:收集19个LLM在24个评估基准上的答案样本,经过多轮GPT-4o和人工审核标注,为训练和评估推理任务的判断模型提供了高质量数据。
- 提出xVerify验证器:设计出xVerify这一高效答案验证器,并发布多个微调版本。它能处理复杂推理痕迹,支持多种等价检查,对格式错误有容忍性,适用于多种任务类型。
- 全面验证有效性:在测试集和泛化集上与多种现有评估框架和判断模型进行对比评估,充分验证了xVerify的有效性和适用性,即便最小版本xVerify-0.5B-I也表现出色。
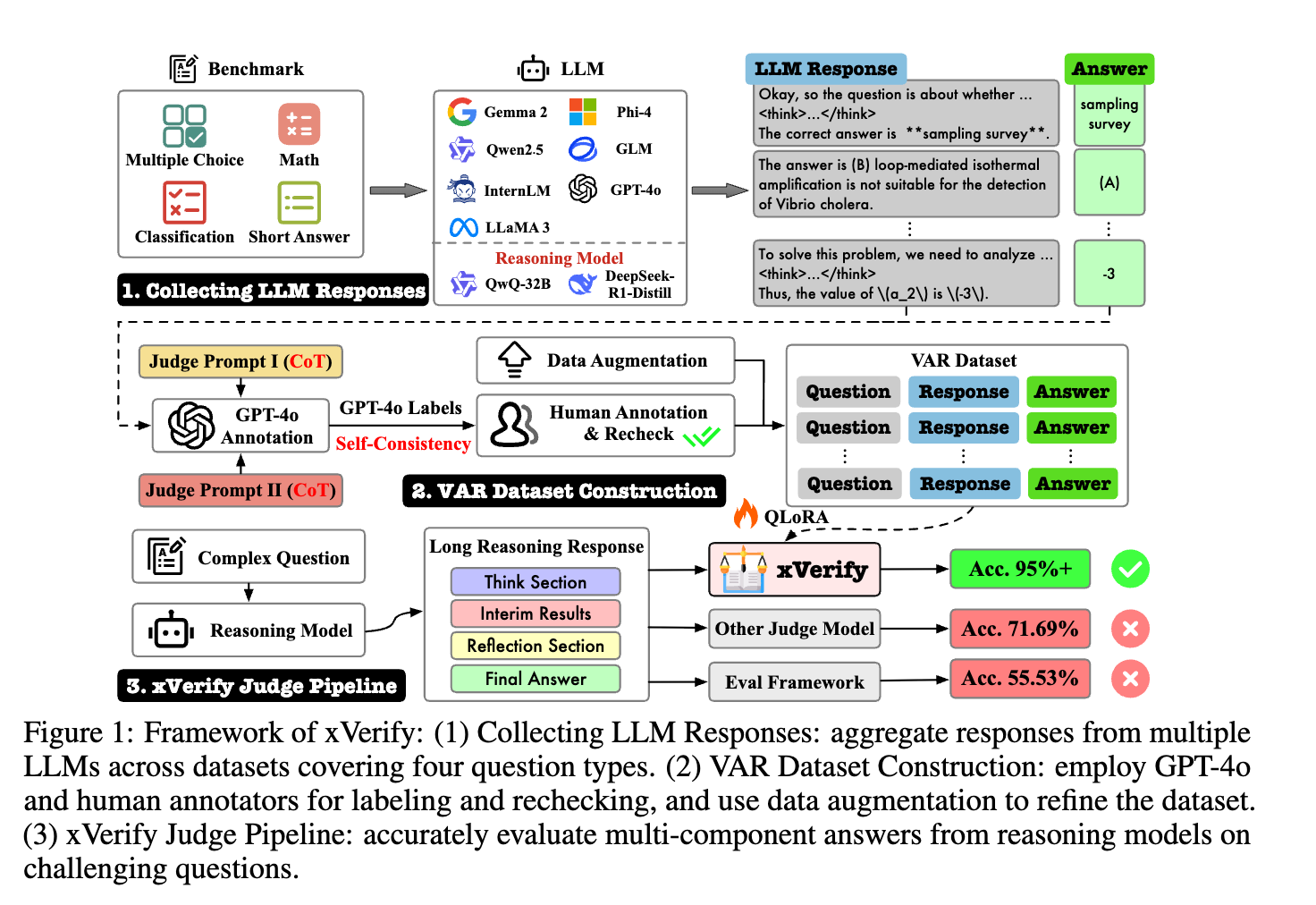
方法论精要
1. 任务形式化定义:将评估LLM对客观问题回答正确性的任务形式化为一个4元组 ( Q , R , A r e f , E ) (Q, R, A_{ref }, E) (Q,R,Aref,E)。其中 Q Q Q是问题集合, R R R是LLM生成的响应集合, A r e f A_{ref } Aref是参考答案集合, E E E是评估函数,根据最终答案与参考答案的匹配情况返回0或1。在提取最终答案时,通过定义评分函数$ S $衡量候选答案与问题的相关性,选取得分最高的候选答案作为最终答案;在等价比较阶段,针对数学表达式、自然语言答案和符号表示分别定义了归一化函数和比较函数,综合判断最终答案与参考答案是否等价。

2. VAR数据集构建
- LLM响应生成:挑选19个主流LLM和24个多语言数据集,涵盖多种难度和领域。依据问题和答案格式,将数据集分为选择题、数学题、简答题和分类题四类。设计8种不同的提示模板,生成191,600个问答样本,确保数据集的多样性和覆盖度。
- 数据集划分:构建训练集、测试集和泛化集。训练集和测试集从15个LLM在17个评估集生成的样本中选取,分布相似;泛化集则来自7个未用于训练和测试的评估集,由19个LLM生成,包含4个新模型,以测试模型在不同分布数据上的泛化能力。
- 数据标注:对三个数据集进行多轮自动和手动标注。先用GPT-4o进行两轮标注,对于训练集中较难的数学问题和标注不一致的样本进行人工标注,测试集和泛化集则全部人工标注,保证标注的准确性。
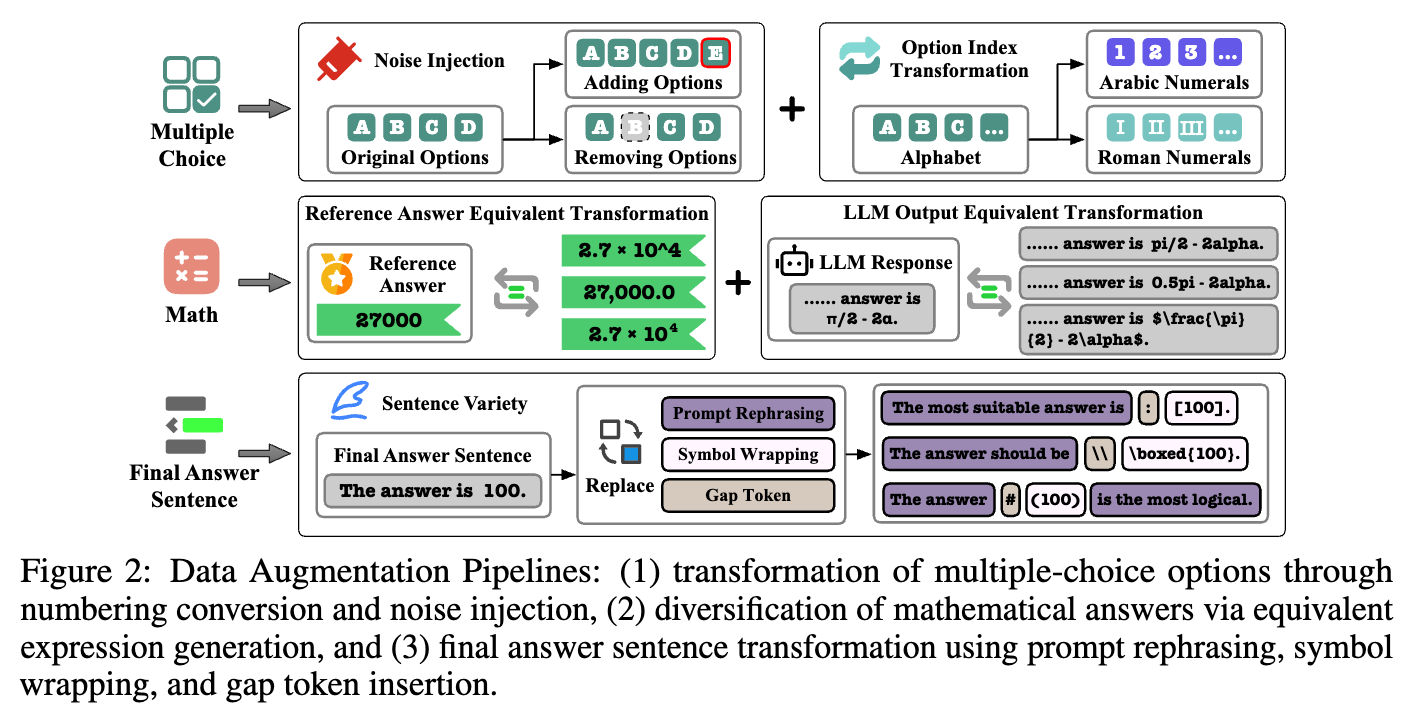
- 数据增强:针对不同题型采用不同策略。选择题进行选项索引变换和噪声注入;数学题基于参考答案和LLM响应生成等价表达式,并对最终答案语句进行多样化变换;通过这些方法,扩展了数据集的表达空间,提升了模型对不同答案格式的适应性。
3. 模型训练:利用VAR数据集的训练集,采用LLaMA-Factory框架和QLoRA技术训练14个不同参数规模和架构的模型。设置训练轮数为1,学习率为(1e - 4) 等超参数,涵盖5个不同系列的基础模型,如LLaMA 3、Qwen2.5等,以全面评估xVerify方法的泛化能力。
实验洞察
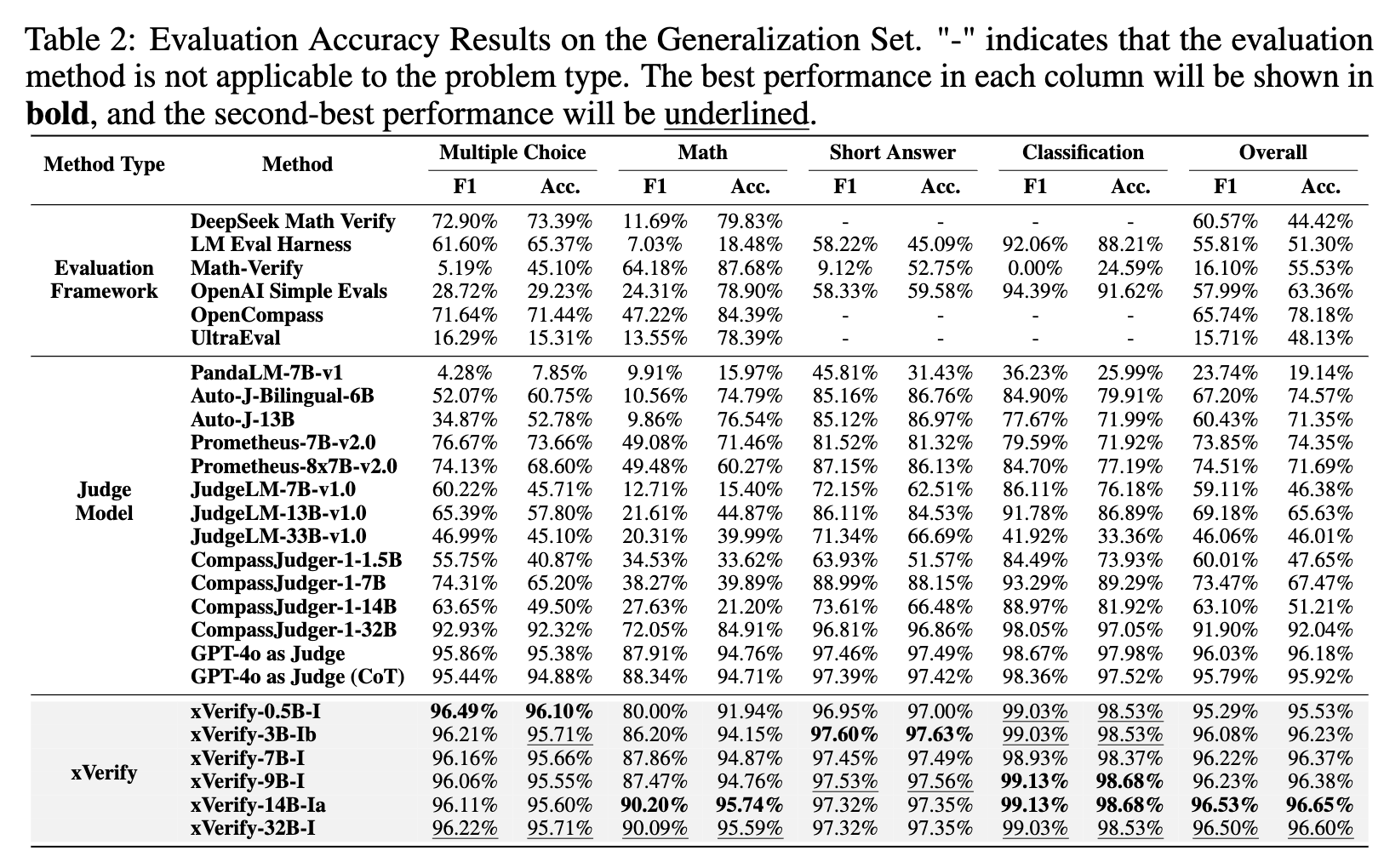
- 测试集评估结果:在VAR测试集上评估xVerify、多种评估框架和判断模型。评估框架方面,DeepSeek Math Verify和OpenCompass表现相对较好,但F1分数和准确率均未超80%,且部分框架不适用某些题型。判断模型中,GPT-4o和CompassJudger总体表现出色,但CompassJudger-1-32B在数学题上表现不佳,较小版本的模型性能更低。相比之下,xVerify表现卓越,xVerify-0.5B-I除了在与GPT-4o as Judge (CoT)的比较中稍逊一筹外,在总体性能上超越其他所有方法;xVerify-3B-Ib在各项评估指标上均超越其他所有方法。
- 泛化集评估结果:在VAR泛化集上,xVerify模型总体性能略有下降,但F1分数和准确率下降均小于1.5%,仍优于其他所有方法。评估框架的总体F1分数和准确率大多低于80%,OpenCompass的总体准确率最高,为70%以上。判断模型中,除GPT-4o外,其他模型在数学题上F1分数大多低于50%,GPT-4o在数学题上F1分数也未超90%,且使用CoT后性能未提升。xVerify-0.5B-I超越除GPT-4o外的所有评估方法,xVerify-3B-Ib超越基于CoT的GPT-4o方法,且较大参数规模的xVerify模型在泛化集上性能下降更少,泛化性能更强。
- 综合评估:全面评估14个xVerify模型在测试集和泛化集上的性能,测试xVerify和其他判断模型的计算效率以及GPT-4o作为判断模型的评估成本。结果显示,xVerify模型在使用成本和评估效率上均优于其他判断模型,所有xVerify模型的总体平均运行时间在100秒以内,而其他判断模型大多超过100秒;xVerify模型的评估成本也显著低于GPT-4o。
本文由AI辅助完成。