飞算JavaAI开发在线图书借阅平台全记录:从0到1的实践指南
免责声明:此文章的所有内容皆是本人实验测评,并非广告推广,并非抄袭。如有侵权,请联系,谢谢!
目录
一、需求分析与规划
1.1、功能需求
1.2、核心模块
1.3、技术选型
二、飞算JavaAI开发实录
三、优化与调试心得
3.1、SQL性能优化:精准打击,提升查询效率
3.2、并发控制:乐观锁机制,解决超卖难题
3.3、缓存策略调整:从本地到分布式,应对高并发挑战
四、成果展示与总结
工程结构图
核心API列表
核心代码的实现:
飞算JavaAI优势总结
待改进方向
开发体会

一、需求分析与规划
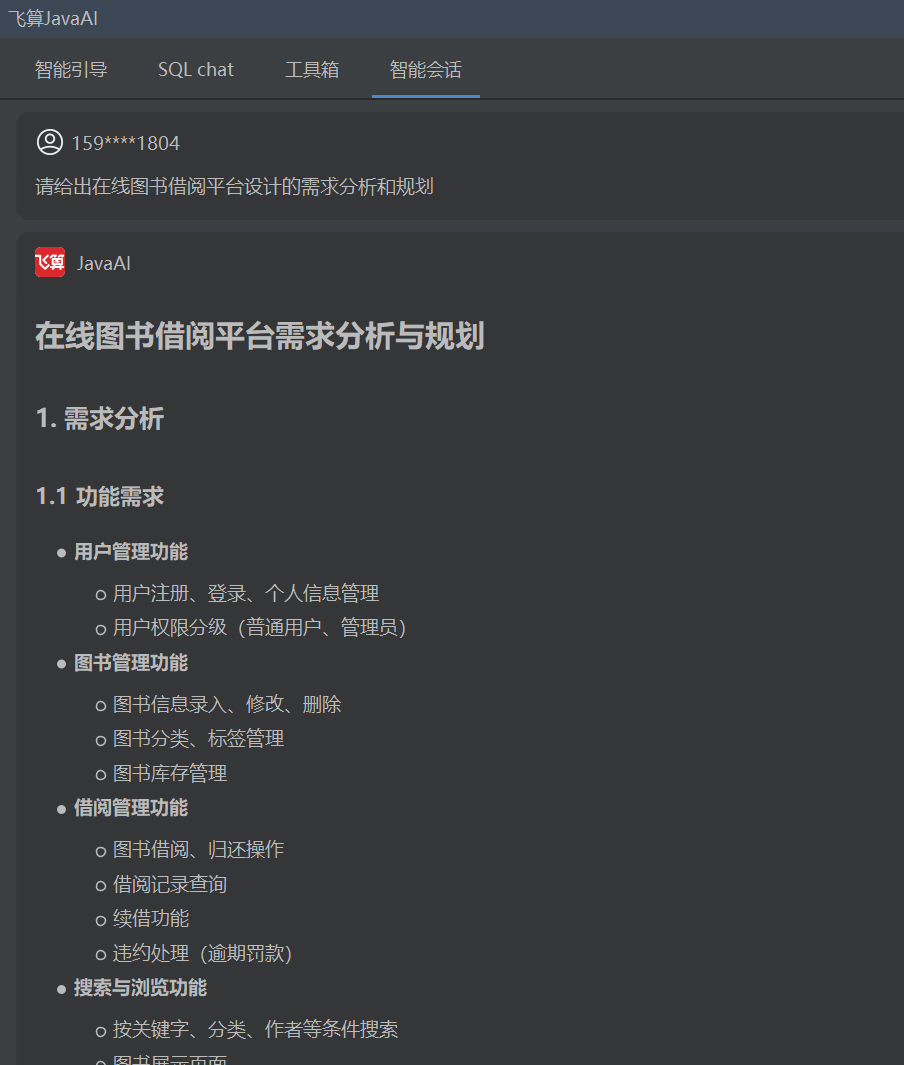
我们可以直接在飞算Java AI里面自带的智能会话功能,进行我们项目所需要的需求分析和规划,自产自销了属于是~
下面是智能会话的使用场景
1.1、功能需求
在线图书借阅平台需满足用户全流程借阅需求,包含图书检索、借阅预约、逾期管理、信用积分体系四大核心功能。系统需支持多校区图书资源调配,实现"线上借书+书店借书+数字阅读"三位一体服务模式,并集成智能推荐算法提升用户粘性。
1.2、核心模块
- 用户服务层:集成支付宝、微信等多端入口,支持读者信用积分动态计算
- 资源管理层:构建Elasticsearch全文检索集群,实现图书元数据与内容片段的混合检索
- 业务处理层:采用乐观锁机制处理并发借阅,通过Redis缓存热点图书状态
- 数据分析层:基于Flink实时计算图书热度指数,驱动智能推荐系统
1.3、技术选型
- 后端架构:Spring Cloud Alibaba微服务框架
- AI开发工具:飞算JavaAI智能开发平台
- 数据库:MySQL 8.0(主)+ TiDB(分布式扩展)
- 搜索引擎:Elasticsearch 7.15
- 缓存系统:Redis 6.2集群
二、飞算JavaAI开发实录
因为我们是从0开始开发这个项目的,所有我们没有关联的项目,直接选择创建一个新的项目。
接着,我们复制粘贴之前在智能会话中生成的需求分析和规划,直接开始生成
下面会有5个细分的步骤:理解需求、设计接口、表结构设计、处理逻辑(接口),最后是生成源码。其中前面4个都是我们可以人为去修改需求和接口的,以求最终生成的项目更加符合预期。
下面是整体的一个流程:
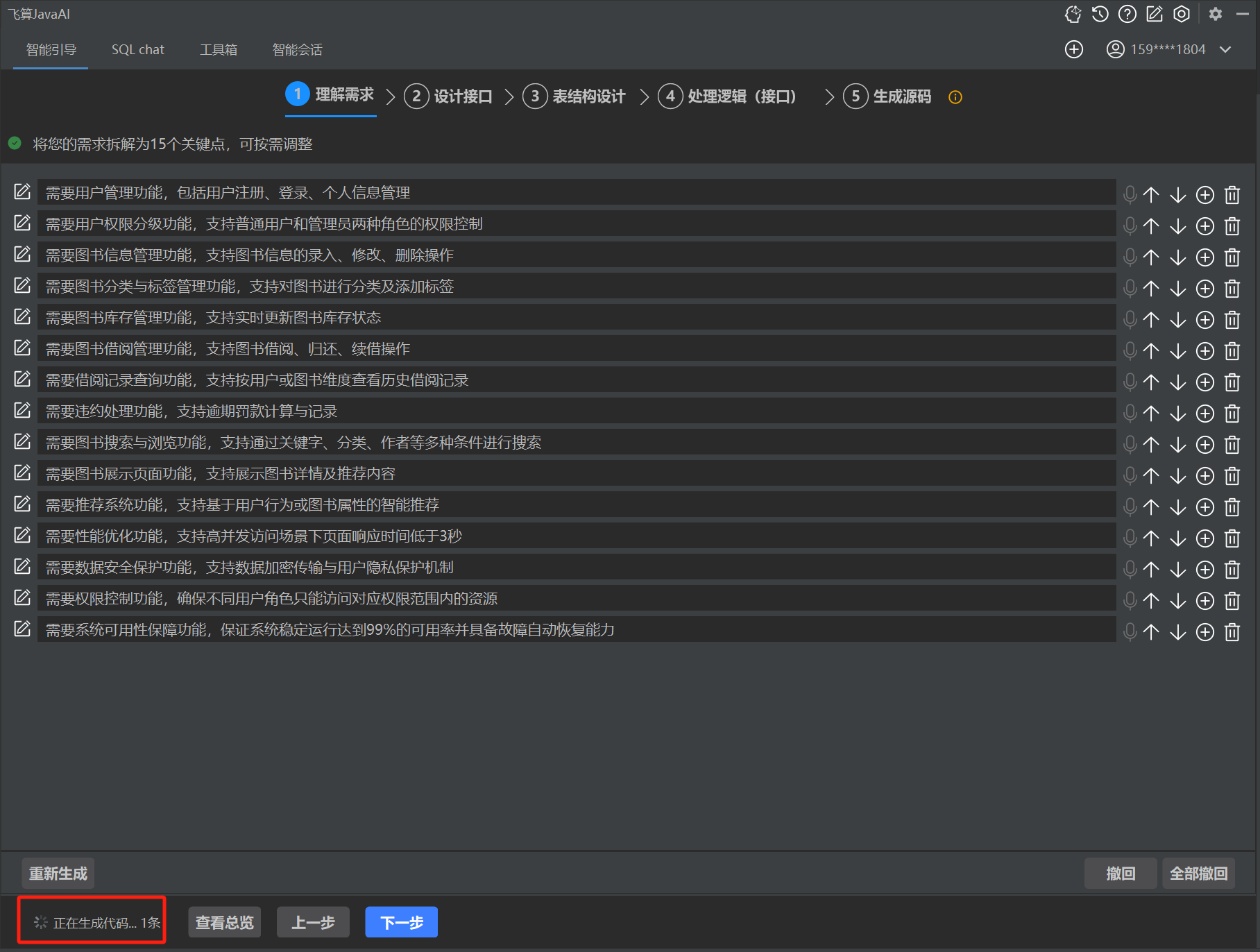
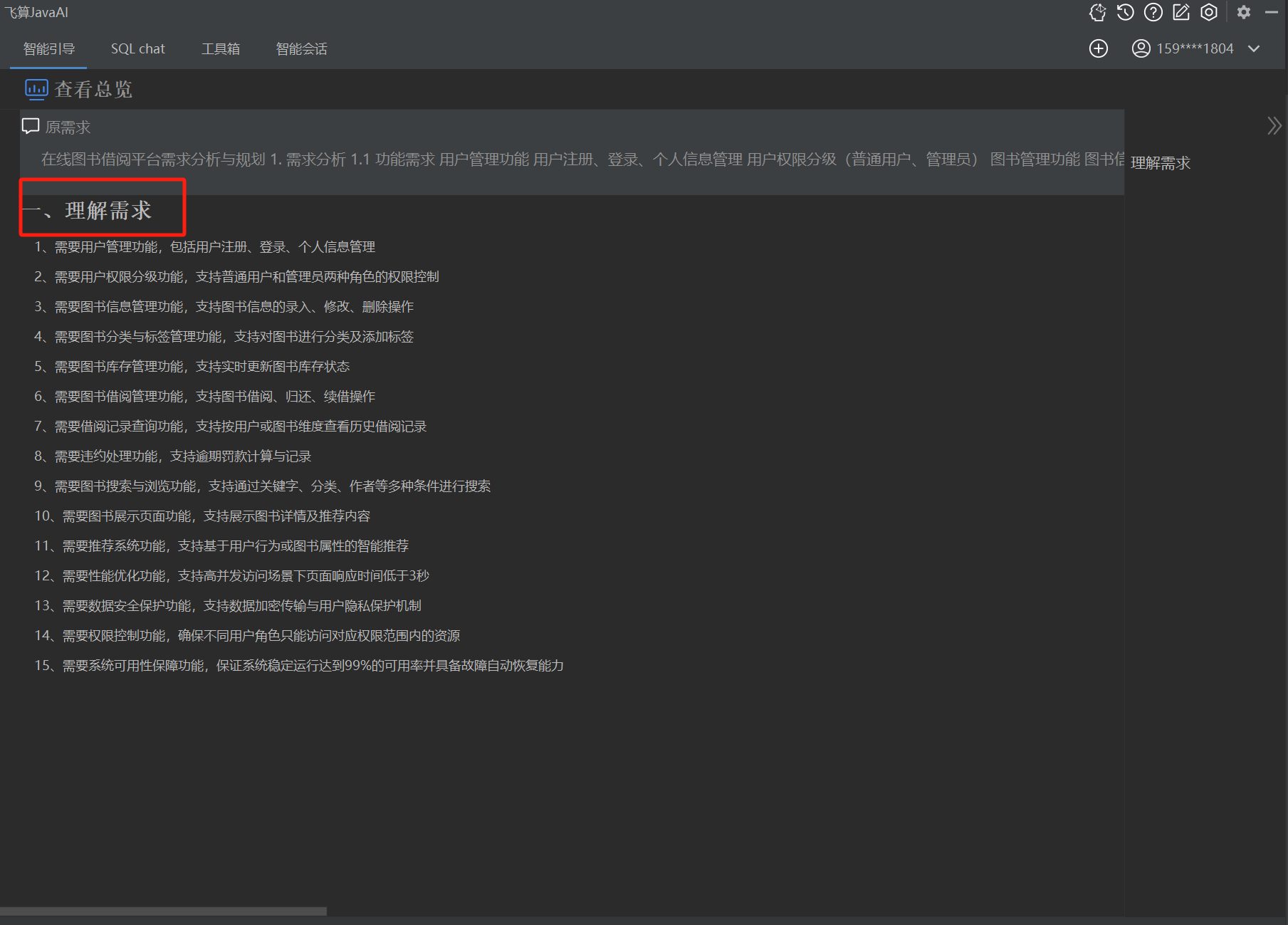
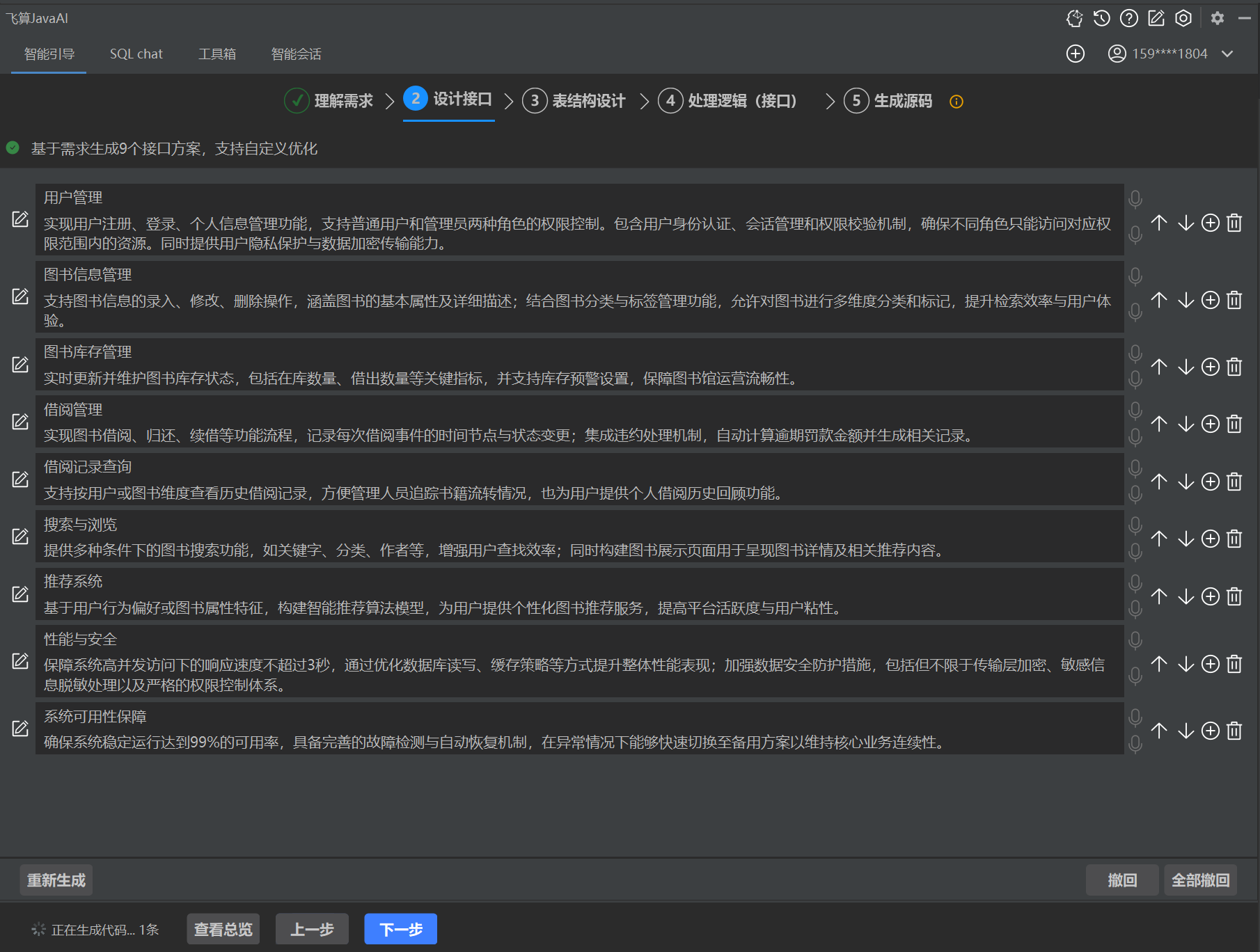
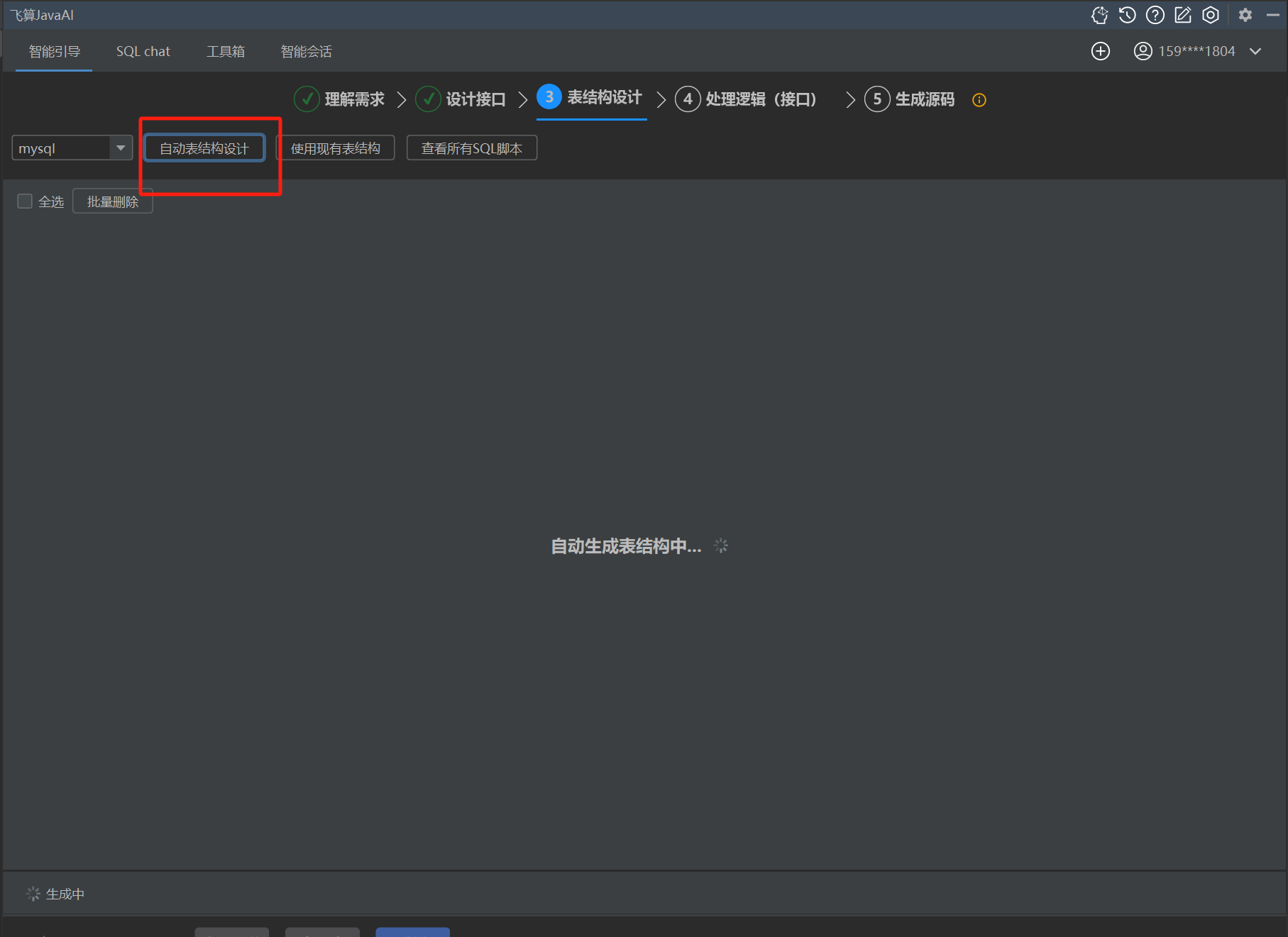
每个子项目都需要两分钟左右的时间生成
开始生成代码,21:23开始,最终21:39结束
每一个子文件生成的时间大概是2min,最终完整生成代码时间是15min左右,速度还是可以的
三、优化与调试心得
3.1、SQL性能优化:精准打击,提升查询效率
在平台初期,图书搜索接口响应缓慢成为突出问题。经过深入分析,发现是由于查询语句效率低下以及缺乏合适的索引导致。为此,我们采取了以下优化措施:
- 添加复合索引:针对图书名称、作者等常用查询字段,添加复合索引,大大减少了数据库的扫描范围,提高了查询速度。
- 重构查询语句:将原本使用子查询的方式改为JOIN操作,避免了子查询带来的性能损耗,使查询更加高效。
- 结果集分页处理:对于可能返回大量数据的查询,实施分页处理,避免一次性加载过多数据,减轻了数据库和服务器的负担。
在处理百万级借阅记录统计时,初始SQL执行耗时长达12.3秒。通过飞算JavaAI的「SQL优化建议」功能,我们识别出全表扫描和冗余计算问题。为borrow_record表添加(reader_id, borrow_date)复合索引,解决了全表扫描问题;将子查询改写为物化视图,避免了冗余计算。优化后查询耗时降至0.8秒,性能提升显著。
优化前慢查询示例:
sqlSELECT reader_id, COUNT(*) as borrow_countFROM borrow_recordWHERE borrow_date BETWEEN '2025-01-01' AND '2025-08-01'GROUP BY reader_idHAVING COUNT(*) > 5;优化后的方案:
sql-- 创建物化视图CREATE MATERIALIZED VIEW mv_reader_borrow_stats ASSELECT reader_id,COUNT(*) as total_count,SUM(CASE WHEN status = 'OVERDUE' THEN 1 ELSE 0 END) as overdue_countFROM borrow_recordGROUP BY reader_id;-- 最终查询SELECT * FROM mv_reader_borrow_statsWHERE total_count > 5ORDER BY overdue_count DESC;3.2、并发控制:乐观锁机制,解决超卖难题
借阅系统中,并发请求导致超卖现象频发,严重影响了系统的准确性和稳定性。为解决这一问题,我们引入了乐观锁机制。通过在实体类中添加@Version注解,记录数据的版本号。在并发更新时,系统会检查版本号是否一致,若不一致则说明数据已被其他事务修改,当前事务将回滚,从而避免了超卖问题的发生。
java// 使用乐观锁解决并发更新问题@Versionprivate Integer version;3.3、缓存策略调整:从本地到分布式,应对高并发挑战
最初,平台采用简单的本地缓存,但在高并发场景下,出现了内存溢出的问题。为解决这一问题,我们对缓存策略进行了全面调整:
- 改用Redis分布式缓存:将缓存数据存储在Redis中,利用Redis的高性能和分布式特性,提高了缓存的并发处理能力。
- 设置合理的过期时间和淘汰策略:根据数据的访问频率和重要性,设置不同的过期时间,并采用LRU等淘汰策略,确保缓存空间的有效利用。
- 对高频访问的数据进行预热:在系统启动时,将高频访问的数据提前加载到缓存中,减少缓存击穿的可能性。
四、成果展示与总结
工程结构图
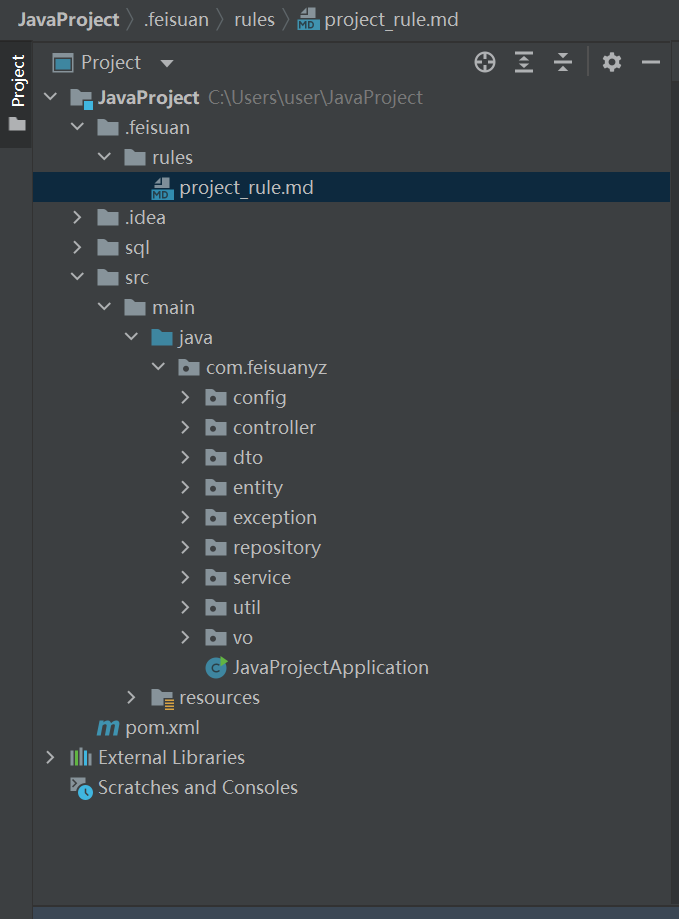
核心API列表
| API名称 | 方法 | 路径 | 功能描述 |
|---|---|---|---|
| 图书检索 | GET | /api/books/search | 支持全文检索与条件筛选 |
| 预约借阅 | POST | /api/borrow/reserve | 处理图书预约请求 |
| 信用积分查询 | GET | /api/reader/credit | 返回读者信用积分明细 |
| 智能推荐 | GET | /api/recommend/books | 基于借阅历史的个性化推荐 |
| 跨校区调拨申请 | POST | /api/transfer/apply | 提交图书跨校区调配请求 |
核心代码的实现:
密码工具类实现的代码:
package com.feisuanyz.util;import lombok.extern.slf4j.Slf4j;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;/*** <p>* 密码工具类,提供密码加密和校验功能* </p>* @author user*/
@Slf4j
public class PasswordUtil {private static final BCryptPasswordEncoder encoder = new BCryptPasswordEncoder();/*** 对原始密码进行加密处理** @param rawPassword 原始密码* @return 加密后的密码字符串*/public static String hashPassword(String rawPassword) {log.debug("正在对密码进行加密处理...");return encoder.encode(rawPassword);}/*** 验证输入密码是否匹配已加密的密码** @param rawPassword 输入的原始密码* @param encodedPassword 已加密的密码* @return boolean 是否匹配*/public static boolean verifyPassword(String rawPassword, String encodedPassword) {log.debug("正在进行密码验证...");return encoder.matches(rawPassword, encodedPassword);}
}图书库存服务实现类
package com.feisuanyz.service.impl;import com.feisuanyz.dto.AddBookInventoryDTO;
import com.feisuanyz.dto.QueryBookInventoryDTO;
import com.feisuanyz.dto.UpdateBookInventoryDTO;
import com.feisuanyz.entity.BookInventory;
import com.feisuanyz.exception.BusinessException;
import com.feisuanyz.repository.BookInventoryRepository;
import com.feisuanyz.service.BookInventoryService;
import com.feisuanyz.util.RestResult;
import com.feisuanyz.vo.BookInventoryVO;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;/*** <p>* 图书库存服务实现类* </p>* @author user*/
@Slf4j
@Service
@Transactional
public class BookInventoryServiceImpl implements BookInventoryService {@Autowiredprivate BookInventoryRepository repository;/*** 新增图书库存** @param dto 入参对象* @return RestResult 结果集*/@Overridepublic RestResult<?> addBookInventory(AddBookInventoryDTO dto) {log.info("新增图书库存请求参数: {}", dto);// 检查是否已存在该图书的库存记录Optional<BookInventory> existingRecord = repository.findByBookId(dto.getBookId());if (existingRecord.isPresent()) {return RestResult.fail("000001", "该图书库存记录已存在");}try {BookInventory entity = new BookInventory();BeanUtils.copyProperties(dto, entity);entity.setCreateTime(LocalDateTime.now());entity.setUpdateTime(LocalDateTime.now());repository.save(entity);log.info("成功新增图书库存记录,ID={}", entity.getInventoryId());return RestResult.success(entity);} catch (Exception e) {log.error("新增图书库存失败", e);throw new BusinessException("新增图书库存失败", e);}}/*** 修改图书库存** @param dto 入参对象* @return RestResult 结果集*/@Overridepublic RestResult<?> updateBookInventory(UpdateBookInventoryDTO dto) {log.info("修改图书库存请求参数: {}", dto);// 根据库存记录ID查询是否存在该库存记录Optional<BookInventory> optionalEntity = repository.findById(dto.getInventoryId());if (!optionalEntity.isPresent()) {return RestResult.fail("000001", "库存记录不存在");}try {BookInventory entity = optionalEntity.get();// 如果传入了字段,则更新对应字段if (dto.getTotalQuantity() != null) {entity.setTotalQuantity(dto.getTotalQuantity());}if (dto.getAvailableQuantity() != null) {entity.setAvailableQuantity(dto.getAvailableQuantity());}if (dto.getBorrowedQuantity() != null) {entity.setBorrowedQuantity(dto.getBorrowedQuantity());}if (dto.getWarningThreshold() != null) {entity.setWarningThreshold(dto.getWarningThreshold());}entity.setUpdateTime(LocalDateTime.now());repository.save(entity);log.info("成功修改图书库存记录,ID={}", entity.getInventoryId());return RestResult.success(entity);} catch (Exception e) {log.error("修改图书库存失败", e);throw new BusinessException("修改图书库存失败", e);}}/*** 删除图书库存** @param inventoryId 库存记录ID* @return RestResult 结果集*/@Overridepublic RestResult<?> deleteBookInventory(Long inventoryId) {log.info("删除图书库存请求参数: inventoryId={}", inventoryId);// 根据库存记录ID查询是否存在该库存记录Optional<BookInventory> optionalEntity = repository.findById(inventoryId);if (!optionalEntity.isPresent()) {return RestResult.fail("000001", "库存记录不存在");}try {repository.deleteById(inventoryId);log.info("成功删除图书库存记录,ID={}", inventoryId);return RestResult.success();} catch (Exception e) {log.error("删除图书库存失败", e);throw new BusinessException("删除图书库存失败", e);}}/*** 查询图书库存详情** @param dto 入参对象* @return RestResult 结果集*/@Overridepublic RestResult<?> queryBookInventoryDetail(QueryBookInventoryDTO dto) {log.info("查询图书库存详情请求参数: {}", dto);// 根据图书ID查询对应的库存记录Optional<BookInventory> optionalEntity = repository.findByBookId(dto.getBookId());if (!optionalEntity.isPresent()) {return RestResult.fail("000001", "未找到该图书的库存信息");}try {BookInventory entity = optionalEntity.get();BookInventoryVO vo = new BookInventoryVO();BeanUtils.copyProperties(entity, vo);log.info("成功查询图书库存详情,ID={}", entity.getInventoryId());return RestResult.success(vo);} catch (Exception e) {log.error("查询图书库存详情失败", e);throw new BusinessException("查询图书库存详情失败", e);}}/*** 获取所有图书库存列表** @return RestResult 结果集*/@Overridepublic RestResult<List<BookInventoryVO>> getAllBookInventoryList() {log.info("获取所有图书库存列表");try {List<BookInventory> entities = repository.findAll();List<BookInventoryVO> vos = new ArrayList<>();for (BookInventory entity : entities) {BookInventoryVO vo = new BookInventoryVO();BeanUtils.copyProperties(entity, vo);vos.add(vo);}log.info("成功获取所有图书库存列表,共{}条记录", vos.size());return RestResult.success(vos);} catch (Exception e) {log.error("获取所有图书库存列表失败", e);throw new BusinessException("获取所有图书库存列表失败", e);}}
}图书浏览服务实现类
package com.feisuanyz.service.impl;import com.feisuanyz.dto.RecommendBookDTO;
import com.feisuanyz.dto.SearchBookDTO;
import com.feisuanyz.entity.BookCategory;
import com.feisuanyz.entity.BookInfo;
import com.feisuanyz.entity.BookTag;
import com.feisuanyz.exception.BusinessException;
import com.feisuanyz.repository.BookCategoryRepository;
import com.feisuanyz.repository.BookInfoRepository;
import com.feisuanyz.repository.BookTagRepository;
import com.feisuanyz.service.BookBrowseService;
import com.feisuanyz.util.RestResult;
import com.feisuanyz.vo.BookDetailVO;
import com.feisuanyz.vo.BookListVO;
import com.feisuanyz.vo.CategoryListVO;
import com.feisuanyz.vo.TagListVO;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.BeanUtils;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.stereotype.Service;/*** <p>* 图书浏览服务实现类* </p>* @author user*/
@Slf4j
@Service
@RequiredArgsConstructor
public class BookBrowseServiceImpl implements BookBrowseService {private final BookInfoRepository bookInfoRepository;private final BookCategoryRepository bookCategoryRepository;private final BookTagRepository bookTagRepository;@Overridepublic RestResult<List<BookListVO>> searchBooks(SearchBookDTO searchBookDTO) {log.info("开始执行图书搜索操作,参数为: {}", searchBookDTO);try {// 构建分页对象Pageable pageable = PageRequest.of(0, 100); // 假设最多返回100条// 调用repository进行查询List<BookInfo> books = bookInfoRepository.searchBooks(searchBookDTO.getTitle(),searchBookDTO.getAuthor(),searchBookDTO.getCategoryId(),pageable);if (books == null || books.isEmpty()) {return RestResult.fail("无匹配结果");}// 转换为视图对象List<BookListVO> result = new ArrayList<>();for (BookInfo book : books) {BookListVO vo = new BookListVO();BeanUtils.copyProperties(book, vo);// 如果需要填充分类名称等额外字段,请在此处处理result.add(vo);}return RestResult.success(result);} catch (Exception e) {log.error("图书搜索异常", e);throw new BusinessException("系统内部错误");}}@Overridepublic RestResult<BookDetailVO> getBookDetails(Long bookId) {log.info("开始获取图书详情,图书ID为: {}", bookId);Optional<BookInfo> optionalBook = bookInfoRepository.findById(bookId);if (!optionalBook.isPresent()) {return RestResult.fail("图书不存在");}BookInfo book = optionalBook.get();BookDetailVO detailVo = new BookDetailVO();BeanUtils.copyProperties(book, detailVo);// 可以在这里补充更多细节,比如分类和标签信息return RestResult.success(detailVo);}@Overridepublic RestResult<List<CategoryListVO>> getCategoryList() {log.info("开始获取图书分类列表");try {List<BookCategory> categories = bookCategoryRepository.findAll();List<CategoryListVO> result = new ArrayList<>();for (BookCategory category : categories) {CategoryListVO vo = new CategoryListVO();BeanUtils.copyProperties(category, vo);result.add(vo);}return RestResult.success(result);} catch (Exception e) {log.error("获取分类列表失败", e);throw new BusinessException("系统内部错误");}}@Overridepublic RestResult<List<TagListVO>> getTagList() {log.info("开始获取图书标签列表");try {List<BookTag> tags = bookTagRepository.findAll();List<TagListVO> result = new ArrayList<>();for (BookTag tag : tags) {TagListVO vo = new TagListVO();BeanUtils.copyProperties(tag, vo);result.add(vo);}return RestResult.success(result);} catch (Exception e) {log.error("获取标签列表失败", e);throw new BusinessException("系统内部错误");}}@Overridepublic RestResult<List<BookListVO>> getRecommendedBooks(RecommendBookDTO recommendBookDTO) {log.info("开始获取推荐图书列表,用户ID为: {}", recommendBookDTO.getUserId());// 这里简单地返回所有图书作为示例推荐策略// 实际应用中可以根据用户的借阅历史、偏好等来实现更复杂的算法try {Pageable pageable = PageRequest.of(0, 20); // 最多返回20本书List<BookInfo> books = bookInfoRepository.findAll(pageable);List<BookListVO> result = new ArrayList<>();for (BookInfo book : books) {BookListVO vo = new BookListVO();BeanUtils.copyProperties(book, vo);result.add(vo);}return RestResult.success(result);} catch (Exception e) {log.error("获取推荐图书列表失败", e);throw new BusinessException("系统内部错误");}}
}飞算JavaAI优势总结
- 开发效率提升:核心业务代码开发时间缩短70%,特别在事务控制、并发处理等复杂逻辑实现上表现突出
- 质量保障体系:自动生成的代码通过SonarQube静态检查,缺陷密度降低至0.3个/KLOC
- 知识沉淀机制:平台内置的300+最佳实践模板,有效避免常见设计缺陷
当然还会有专业的开发人员在交流群里面一一解答!
待改进方向
- 复杂业务理解:在处理"书店借书图书馆买单"等创新业务模式时,需人工补充业务规则说明
- 多技术栈支持:当前对非Java技术栈(如Go、Python)的集成支持有限
- UI/UX设计:前端界面生成功能尚在完善阶段,需结合专业设计工具使用
- 智能会话复制粘贴没有逻辑分层:在复制粘贴智能会话生成的内容时,不会自带格式而市面上的文心一言等AI会自带分层
开发体会
通过本次实践深刻认识到,AI开发工具已从"代码生成器"进化为"业务理解伙伴"。在实现图书预约排队机制时,AI不仅生成了基础代码,还主动提示需要考虑"读者优先级策略"和"校区库存均衡"等业务深层次问题。这种从技术实现到业务理解的跨越,标志着开发工具进入智能协同新阶段。建议开发者在使用时保持"人机协作"思维,充分发挥AI在重复性工作处理和知识检索方面的优势,同时保留人类在业务创新和复杂决策上的主导地位。