简说DDPM
目录
- 1. 基础过程FP和RP
- 1.1 前向过程FP(forward process or diffusion process)
- 1.1.1 FP 概率的递归
- 1.2 逆向过程RP(reverse process)
- 2. Loss 计算
- Appendix A: 变分下界
- 1. 问题背景:为何需要变分下界?
- 2. 变分下界的推导
- 关键步骤:
- 3. 如何理解ELBO?
- 直观解释:
- 4. **与负对数似然的关系**
- 5. **总结**
- 参考
1. 基础过程FP和RP
1.1 前向过程FP(forward process or diffusion process)
以图像为例,前向过程就是从一副干净的图像,逐步加噪最后变成一副近似完全噪声的图像;
这个过程认为是符合Markov过程的,所以从概率上来讲:
q(xT,xT−1...x1∣x0)=q(xT∣xT−1)q(xT−1∣xT−2)...q(x1∣x0)=∏t=1Tq(xt∣xt−1)\begin{equation} q(x_T,x_{T-1}...x_1|x_0)=q(x_T|x_{T-1})q(x_{T-1}|x_{T-2})...q(x_1|x_0)=\prod_{t=1}^Tq(x_t|x_{t-1}) \end{equation} q(xT,xT−1...x1∣x0)=q(xT∣xT−1)q(xT−1∣xT−2)...q(x1∣x0)=t=1∏Tq(xt∣xt−1)
对于其中任意一步 q(xt∣xt−1)q(x_t|x_{t-1})q(xt∣xt−1),根据加噪的方式,可以有明确的表达;当噪声符合Gaussian时,则
Xt=1−βtXt−1+βtϵt\begin{equation} X_t=\sqrt{1-\beta_t}X_{t-1}+\sqrt\beta_t \epsilon_t \end{equation} Xt=1−βtXt−1+βtϵt
其中ϵt\epsilon_tϵt是Gaussian噪声,所以
Xt∼N(1−βtXt−1,βtI)q(xt∣xt−1)=12πβtexp(−(xt−Xt−1)22βt)X_t \sim N(\sqrt{1-\beta_t}X_{t-1}, \beta_t I) \\ q(x_t|x_{t-1})=\frac{1}{ \sqrt{2 \pi \beta_t }}exp \left(- \frac{ \left( x_t- X_{t-1} \right)^{2}}{2 \beta_t} \right) Xt∼N(1−βtXt−1,βtI)q(xt∣xt−1)=2πβt1exp(−2βt(xt−Xt−1)2)
1.1.1 FP 概率的递归
根据式(2),为了表示方便,可以令 αt=1−βt\alpha_t = 1-\beta_tαt=1−βt ,递归代入可得
Xt=αtXt−1+1−αtϵt=αt(αt−1Xt−2+1−αt−1ϵt−1)+1−αtϵt=αtαt−1Xt−2+αt(1−αt−1)ϵt−1+1−αtϵt\begin{equation} \begin{aligned} X_t&=\sqrt {\alpha_t} X_{t-1}+\sqrt{1-\alpha_t}\epsilon_t \\ &=\sqrt {\alpha_t} (\sqrt {\alpha_{t-1}} X_{t-2}+\sqrt{1-\alpha_{t-1}}\epsilon_{t-1})+\sqrt{1-\alpha_t}\epsilon_t \\ &=\sqrt {\alpha_t \alpha_{t-1}} X_{t-2}+\sqrt{\alpha_t(1-\alpha_{t-1})}\epsilon_{t-1}+\sqrt{1-\alpha_t}\epsilon_t \end{aligned} \end{equation} Xt=αtXt−1+1−αtϵt=αt(αt−1Xt−2+1−αt−1ϵt−1)+1−αtϵt=αtαt−1Xt−2+αt(1−αt−1)ϵt−1+1−αtϵt
观察公式(3)的后两项,可以令
Z=αt(1−αt−1)ϵt−1+1−αtϵt=1−αtαt−1ϵ\begin{aligned} Z&=\sqrt{\alpha_t(1-\alpha_{t-1})}\epsilon_{t-1}+\sqrt{1-\alpha_t}\epsilon_t \\ &=\sqrt{1-\alpha_t\alpha_{t-1}}\epsilon \end{aligned} Z=αt(1−αt−1)ϵt−1+1−αtϵt=1−αtαt−1ϵ
解释:两个Gaussian分布的叠加是一个新的Gaussion分布,且生成新的分布的方差为两个分布方差的和;有严格的证明,此处略
则依次递归可得
Xt=αtXt−1+1−αtϵt=...=αtαt−1...α1Xt0+1−αtαt−1...α1ϵt\begin{aligned} X_t&=\sqrt {\alpha_t} X_{t-1}+\sqrt{1-\alpha_t}\epsilon_t \\ &=... \\ &=\sqrt {\alpha_t \alpha_{t-1}...\alpha_1} X_{t0}+\sqrt{1-\alpha_t \alpha_{t-1}...\alpha_1}\epsilon_t \end{aligned} Xt=αtXt−1+1−αtϵt=...=αtαt−1...α1Xt0+1−αtαt−1...α1ϵt
为了表示方便,我们记 αt‾=αtαt−1...α1\overline{\alpha_t}=\alpha_t \alpha_{t-1}...\alpha_1αt=αtαt−1...α1,则有
Xt=αt‾X0+1−αt‾ϵ~t\begin{equation} X_t=\sqrt {\overline{\alpha_t}} X_{0}+\sqrt{1-\overline{\alpha_t}}\tilde\epsilon_t \end{equation} Xt=αtX0+1−αtϵ~t
公式(4)表达了怎么直接获得第 t 次加噪效果的结果。
1.2 逆向过程RP(reverse process)
逆向过程表达了怎么通过去噪将一副噪声图逐步变成一副清晰的画面,类似的, 我们有以下表达:
pθ(x0,x1...xT−1∣xT)=pθ(xT−1∣xT)pθ(xT−2∣xT−1)...pθ(x0∣x1)=∏t=1Tpθ(xt−1∣xt)\begin{equation} p_\theta(x_0,x_{1}...x_{T-1}|x_T)=p_\theta(x_{T-1}|x_{T})p_\theta(x_{T-2}|x_{T-1})...p\theta(x_0|x_1)=\prod_{t=1}^Tp_\theta(x_{t-1}|x_{t}) \end{equation} pθ(x0,x1...xT−1∣xT)=pθ(xT−1∣xT)pθ(xT−2∣xT−1)...pθ(x0∣x1)=t=1∏Tpθ(xt−1∣xt)
解释:pθp_\thetapθ表达了由噪声图去噪的概率,下标θ\thetaθ是未知参数,也就是我们需要获得的参数
2. Loss 计算
2.1 去噪目标
再思考一下Denoising的目的,是为了获得清晰的图片x0x_0x0,基于MLE的理论,也就是说,需要最大化pθ(x0)p_\theta(x_0)pθ(x0)的概率。这个时候我们一般会选择使用NLL作为loss,即
L~=E[−logpθ(x0)]\mathcal{\tilde L}=\mathbb E[-log p_\theta(x_0)] L~=E[−logpθ(x0)]
由于x0x_0x0的分布依赖x1:Tx_{1:T}x1:T这些隐变量的分布,所以这里使用了常用的trick,即变分下界
L~=E[−logpθ(x0)]≤Eq[−logpθ(x0:T)q(x1:T∣x0)]=Eq[−logp(xT)−∑t≥1logpθ(xt−1∣xt)q(xt∣xt−1)]=:L\begin{aligned} \mathcal{\tilde L}&=\mathbb E[-log p_\theta(x_0)] \\ &\le \mathbb{E}_{q}\left[-\operatorname{log}\frac{p_{\theta}(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T}|\mathbf{x}_{0})}\right] \\ &=\mathbb{E}_{q}\left[-\operatorname{log}p(\mathbf{x}_{T})-\sum_{t\geq1}\operatorname{log}\frac{p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t})}{q(\mathbf{x}_{t}|\mathbf{x}_{t-1})}\right] =: \mathcal L \end{aligned} L~=E[−logpθ(x0)]≤Eq[−logq(x1:T∣x0)pθ(x0:T)]=Eq[−logp(xT)−t≥1∑logq(xt∣xt−1)pθ(xt−1∣xt)]=:L
我们对上式的Loss进行再变形,得到
L=Eq[−logpθ(x0:T)q(x1:T∣x0)]=Eq[−logp(xT)−∑t≥1logpθ(xt−1∣xt)q(xt∣xt−1)]=Eq[−logp(xT)−∑t>1logpθ(xt−1∣xt)q(xt∣xt−1)−logpθ(x0∣x1)q(x1∣x0)]=Eq[−logp(xT)−∑t>1logpθ(xt−1∣xt)q(xt−1∣xt,x0)⋅q(xt−1∣x0)q(xt∣x0)−logpθ(x0∣x1)q(x1∣x0)]=Eq[−logp(xT)q(xT∣x0)−∑t>1logpθ(xt−1∣xt)q(xt−1∣xt,x0)−logpθ(x0∣x1)]\begin{aligned} \mathcal {L} & =\mathbb{E}_q{\left[-\log{\frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T}|\mathbf{x}_0)}}\right]} \\ & =\mathbb{E}_q\left[-\log p(\mathbf{x}_T)-\sum_{t\geq1}\log\frac{p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)}{q(\mathbf{x}_t|\mathbf{x}_{t-1})}\right] \\ & =\mathbb{E}_q\left[-\log p(\mathbf{x}_T)-\sum_{t>1}\log\frac{p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)}{q(\mathbf{x}_t|\mathbf{x}_{t-1})}-\log\frac{p_\theta(\mathbf{x}_0|\mathbf{x}_1)}{q(\mathbf{x}_1|\mathbf{x}_0)}\right] \\ & =\mathbb{E}_q\left[-\log p(\mathbf{x}_T)-\sum_{t>1}\log\frac{p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)}{q(\mathbf{x}_{t-1}|\mathbf{x}_t,\mathbf{x}_0)}\cdot\frac{q(\mathbf{x}_{t-1}|\mathbf{x}_0)}{q(\mathbf{x}_t|\mathbf{x}_0)}-\log\frac{p_\theta(\mathbf{x}_0|\mathbf{x}_1)}{q(\mathbf{x}_1|\mathbf{x}_0)}\right] \\ & =\mathbb{E}_q\left[-\log\frac{p(\mathbf{x}_T)}{q(\mathbf{x}_T|\mathbf{x}_0)}-\sum_{t>1}\log\frac{p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)}{q(\mathbf{x}_{t-1}|\mathbf{x}_t,\mathbf{x}_0)}-\log p_\theta(\mathbf{x}_0|\mathbf{x}_1)\right] \end{aligned} L=Eq[−logq(x1:T∣x0)pθ(x0:T)]=Eq[−logp(xT)−t≥1∑logq(xt∣xt−1)pθ(xt−1∣xt)]=Eq[−logp(xT)−t>1∑logq(xt∣xt−1)pθ(xt−1∣xt)−logq(x1∣x0)pθ(x0∣x1)]=Eq[−logp(xT)−t>1∑logq(xt−1∣xt,x0)pθ(xt−1∣xt)⋅q(xt∣x0)q(xt−1∣x0)−logq(x1∣x0)pθ(x0∣x1)]=Eq[−logq(xT∣x0)p(xT)−t>1∑logq(xt−1∣xt,x0)pθ(xt−1∣xt)−logpθ(x0∣x1)]
再根据KL散度的定义,可以转化成
L=Eq[DKL(q(xT∣x0)∥p(xT))⏟LT+∑t>1DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))⏟Lt−1−logpθ(x0∣x1)⏟L0]\begin{equation} \mathcal {L} =\mathbb{E}_q\left[\underbrace{D_{\mathrm{KL}}(q(\mathbf{x}_T|\mathbf{x}_0)\parallel p(\mathbf{x}_T))}_{L_T}+\sum_{t>1}\underbrace{D_{\mathrm{KL}}(q(\mathbf{x}_{t-1}|\mathbf{x}_t,\mathbf{x}_0)\parallel p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t))}_{L_{t-1}}\underbrace{-\log p_\theta(\mathbf{x}_0|\mathbf{x}_1)}_{L_0}\right] \end{equation} L=EqLTDKL(q(xT∣x0)∥p(xT))+t>1∑Lt−1DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))L0−logpθ(x0∣x1)
对于式(6)的通俗理解:
- q(xT∣x0)q(\mathbf{x}_T|\mathbf{x}_0)q(xT∣x0) 代表了已知的FP加噪过程,表示已知x0x_0x0得到xTx_TxT;
- 我们的目的是希望网络参数得到的概率分布 pθ(xT)p_\theta(\mathbf{x_T})pθ(xT)在未知x0\mathbf{x_0}x0的条件下,与q(xT∣x0)q(\mathbf{x}_T|\mathbf{x}_0)q(xT∣x0)尽可能接近
- 同理,q(xt−1∣xt,x0)q(\mathbf{x}_{t-1}|\mathbf{x}_t,\mathbf{x}_0)q(xt−1∣xt,x0)和pθ(xt−1∣xt)p_\theta(\mathbf{x}_{t-1}|\mathbf{x}_t)pθ(xt−1∣xt)也要尽可能接近;都表达了网络要学会在不知道x0x_0x0的前提下,学会估计出噪声分布
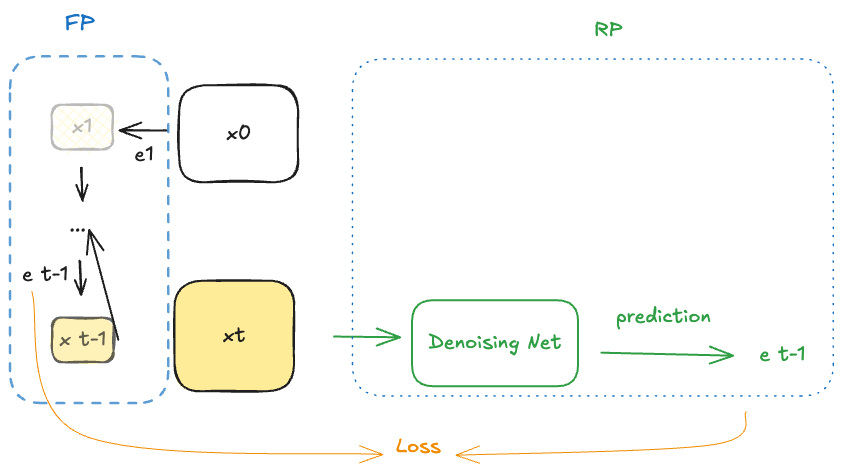
2.2 关键过程 Lt−1L_{t-1}Lt−1
在RP过程中,我们的重点是计算后验概率
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t})=\mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_{\theta}(\mathbf{x}_{t},t),\boldsymbol{\Sigma}_{\theta}( \mathbf{x}_{t},t)) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
其中的均值和方差是我们需要进行学习的,这里先忽略掉方差,先考虑均值。
令Σθ(xt,t)=σt2\boldsymbol{\Sigma}_{\theta}( \mathbf{x}_{t},t)=\sigma_t^2Σθ(xt,t)=σt2,则可以重写
Lt−1=Eq[12σt2∥μ~t(xt,x0)−μθ(xt,t)∥2]+C\begin{equation} L_{t-1}=\mathbb{E}_q\left[\frac{1}{2\sigma_t^2}\|\tilde{\boldsymbol{\mu}}_t(\mathbf{x}_t,\mathbf{x}_0)-\boldsymbol{\mu}_\theta(\mathbf{x}_t,t)\|^2\right]+C \end{equation} Lt−1=Eq[2σt21∥μ~t(xt,x0)−μθ(xt,t)∥2]+C
从上式可以看出一个基本点,就是我们的网络用来估计的均值μθ(xt,t)\boldsymbol{\mu}_\theta(\mathbf{x}_t,t)μθ(xt,t)的目标是尽可能的接近 μ~t(xt,x0)\tilde{\boldsymbol{\mu}}_t(\mathbf{x}_t,\mathbf{x}_0)μ~t(xt,x0),所以这个目标就是我们实际训练时的真值
继续,根据式(4),可以将x0x_0x0替换为xtx_txt的表达,即
μ~t(xt,x0)=μ~t(xt,1αˉt(xt−1−αˉtϵ))=1αt(xt−βt1−αˉtϵθ(xt,t))\tilde{\boldsymbol{\mu}}_t(\mathbf{x}_t,\mathbf{x}_0)=\tilde{\boldsymbol{\mu}}_t\left(\mathbf{x}_t,\frac{1}{\sqrt{\bar{\alpha}_t}}(\mathbf{x}_t-\sqrt{1-\bar{\alpha}_t}\boldsymbol{\epsilon})\right)=\frac{1}{\sqrt{\alpha_t}}\left(\mathbf{x}_t-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}\boldsymbol{\epsilon}_\theta(\mathbf{x}_t,t)\right) μ~t(xt,x0)=μ~t(xt,αˉt1(xt−1−αˉtϵ))=αt1(xt−1−αˉtβtϵθ(xt,t))
推导过程如下:
首先,μ~\tilde \muμ~表示在已知xt,x0x_t, x_0xt,x0的情况下,xt−1x_{t-1}xt−1的分布或者概率,根据贝叶斯公式,有
q(xt−1∣xt,x0)=q(xt,xt−1,x0)q(xt,x0)=q(xt∣xt−1)q(xt−1∣x0)q(x0)q(xt∣x0)q(x0)=q(xt∣xt−1)q(xt−1∣x0)q(xt∣x0)q(x_{t-1}|x_t, x_0)=\frac{q(x_t,x_{t-1},x_0)}{q(x_t, x_0)}=\frac{q(x_t|x_{t-1})q(x_{t-1}|x_0)\cancel{q(x_0)}}{q(x_t|x_0)\cancel{q(x_0)}}=\frac{q(x_t|x_{t-1})q(x_{t-1}|x_0)}{q(x_t|x_0)} q(xt−1∣xt,x0)=q(xt,x0)q(xt,xt−1,x0)=q(xt∣x0)q(x0)q(xt∣xt−1)q(xt−1∣x0)q(x0)=q(xt∣x0)q(xt∣xt−1)q(xt−1∣x0)
而上式中的分子和分母都是已知的,并且根据加噪的假设,都是符合Gaussain分布的,以其中某一项举例
q(xt∣xt−1)=12πβtexp(−(xt−Xt−1)22βt)q(x_t|x_{t-1})=\frac{1}{ \sqrt{2 \pi \beta_t }}exp \left(- \frac{ \left( x_t- X_{t-1} \right)^{2}}{2 \beta_t} \right) q(xt∣xt−1)=2πβt1exp(−2βt(xt−Xt−1)2)
代入化简,可得均值即为
μ~t(xt,x0)=αt(1−αˉt−1)1−αˉtxt+βtαˉt−11−αˉtx0\tilde{\mu}_t(x_t,x_0) =\frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}x_t+\frac{\beta_t\sqrt{\bar{\alpha}_{t-1}}}{1-\bar{\alpha}_t}x_0 μ~t(xt,x0)=1−αˉtαt(1−αˉt−1)xt+1−αˉtβtαˉt−1x0
所以,可有
μ~t(xt,x0)=μ~(xt(x0,ϵ),1αˉt(xt(x0,ϵ)−1−αˉtϵ))=αt(1−αˉt−1)1−αˉtxt(x0,ϵ)+βtαˉt−11−αˉt1αˉt(xt(x0,ϵ)−1−αˉtϵ)=αt(1−αˉt−1)αt(1−αˉt)xt(x0,ϵ)+βt(xt(x0,ϵ)−1−αˉtϵ)αt(1−αˉt)=1αt[(αt−αˉt+βt)xt(x0,ϵ)1−αˉt−βt1−αˉtϵ]=1αt[xt(x0,ϵ)−βt1−αˉtϵ]\begin{aligned} \tilde{\mu}_t(x_t,x_0) & =\tilde{\mu}\left(x_t\left(x_0,\epsilon\right),\frac{1}{\sqrt{\bar{\alpha}_t}}(x_t(x_0,\epsilon)-\sqrt{1-\bar{\alpha}_t}\epsilon)\right) \\ & =\frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t}x_t\left(x_0,\epsilon\right)+\frac{\beta_t\sqrt{\bar{\alpha}_{t-1}}}{1-\bar{\alpha}_t}\frac{1}{\sqrt{\bar{\alpha}_t}}(x_t\left(x_0,\epsilon\right)-\sqrt{1-\bar{\alpha}_t}\epsilon) \\ & =\frac{\alpha_t(1-\bar{\alpha}_{t-1})}{\sqrt{\alpha_t}(1-\bar{\alpha}_t)}x_t\left(x_0,\epsilon\right)+\frac{\beta_t(x_t\left(x_0,\epsilon\right)-\sqrt{1-\bar{\alpha}_t}\epsilon)}{\sqrt{\alpha_t}(1-\bar{\alpha}_t)} \\ & =\frac{1}{\sqrt{\alpha_t}}{\left[\frac{(\alpha_t-\bar{\alpha}_t+\beta_t)x_t\left(x_0,\epsilon\right)}{1-\bar{\alpha}_t}-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon\right]} \\ & =\frac{1}{\sqrt{\alpha_t}}{\left[x_t\left(x_0,\epsilon\right)-\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon\right]} \end{aligned} μ~t(xt,x0)=μ~(xt(x0,ϵ),αˉt1(xt(x0,ϵ)−1−αˉtϵ))=1−αˉtαt(1−αˉt−1)xt(x0,ϵ)+1−αˉtβtαˉt−1αˉt1(xt(x0,ϵ)−1−αˉtϵ)=αt(1−αˉt)αt(1−αˉt−1)xt(x0,ϵ)+αt(1−αˉt)βt(xt(x0,ϵ)−1−αˉtϵ)=αt1[1−αˉt(αt−αˉt+βt)xt(x0,ϵ)−1−αˉtβtϵ]=αt1[xt(x0,ϵ)−1−αˉtβtϵ]
经过以上的推导,我们的训练过程就可以表述为

2.3 深入理解LTL_TLT和L0L_0L0
(待完善)
Appendix A: 变分下界
可参考 变分下界
负对数似然(Negative Log-Likelihood, NLL)的变分下界(Variational Lower Bound),通常指的是证据下界(Evidence Lower BOund, ELBO)。它在变分推断(Variational Inference)中扮演着核心角色,用于近似复杂的概率分布。下面我将分步骤解释其概念、推导过程及直观理解。
1. 问题背景:为何需要变分下界?
假设我们有一个隐变量模型(如变分自编码器VAE),包含:
- 观测数据 xxx
- 隐变量 zzz(无法直接观测,如VAE中的潜在编码)
目标是最大化观测数据的对数似然 logp(x)\log p(x)logp(x),但直接计算它通常不可行(因为需要积分:p(x)=∫p(x∣z)p(z)dzp(x) = \int p(x|z)p(z)dzp(x)=∫p(x∣z)p(z)dz)。因此,引入变分推断。
2. 变分下界的推导
为了近似真实的后验分布 p(z∣x)p(z|x)p(z∣x),引入一个简单的可优化分布 qϕ(z∣x)q_\phi(z|x)qϕ(z∣x)(如高斯分布),通过最小化两者的KL散度(KL(qϕ(z∣x)∥p(z∣x))\text{KL}(q_\phi(z|x) \| p(z|x))KL(qϕ(z∣x)∥p(z∣x)))来逼近。
关键步骤:
从KL散度的定义出发:
KL(qϕ(z∣x)∥p(z∣x))=Eqϕ(z∣x)[logqϕ(z∣x)−logp(z∣x)]\text{KL}(q_\phi(z|x) \| p(z|x)) = \mathbb{E}_{q_\phi(z|x)} \left[ \log q_\phi(z|x) - \log p(z|x) \right] KL(qϕ(z∣x)∥p(z∣x))=Eqϕ(z∣x)[logqϕ(z∣x)−logp(z∣x)]
利用贝叶斯定理 p(z∣x)=p(x∣z)p(z)p(x)p(z|x) = \frac{p(x|z)p(z)}{p(x)}p(z∣x)=p(x)p(x∣z)p(z),代入上式:
KL(qϕ(z∣x)∥p(z∣x))=Eqϕ[logqϕ(z∣x)−logp(x∣z)−logp(z)+logp(x)]=Eqϕ[logqϕ(z∣x)−logp(x∣z)−logp(z)]+logp(x)\begin{align*} \text{KL}(q_\phi(z|x) \| p(z|x)) &= \mathbb{E}_{q_\phi} \left[ \log q_\phi(z|x) - \log p(x|z) - \log p(z) + \log p(x) \right] \\ &= \mathbb{E}_{q_\phi} \left[ \log q_\phi(z|x) - \log p(x|z) - \log p(z) \right] + \log p(x) \end{align*} KL(qϕ(z∣x)∥p(z∣x))=Eqϕ[logqϕ(z∣x)−logp(x∣z)−logp(z)+logp(x)]=Eqϕ[logqϕ(z∣x)−logp(x∣z)−logp(z)]+logp(x)
整理后得到:
logp(x)−KL(qϕ(z∣x)∥p(z∣x))=Eqϕ[logp(x∣z)+logp(z)−logqϕ(z∣x)]\log p(x) - \text{KL}(q_\phi(z|x) \| p(z|x)) = \mathbb{E}_{q_\phi} \left[ \log p(x|z) + \log p(z) - \log q_\phi(z|x) \right] logp(x)−KL(qϕ(z∣x)∥p(z∣x))=Eqϕ[logp(x∣z)+logp(z)−logqϕ(z∣x)]
由于KL散度非负(KL≥0\text{KL} \geq 0KL≥0),因此:
logp(x)≥Eqϕ[logp(x∣z)+logp(z)−logqϕ(z∣x)]⏟ELBO\log p(x) \geq \underbrace{\mathbb{E}_{q_\phi} \left[ \log p(x|z) + \log p(z) - \log q_\phi(z|x) \right]}_{\text{ELBO}} logp(x)≥ELBOEqϕ[logp(x∣z)+logp(z)−logqϕ(z∣x)]
这个下界就是ELBO(变分下界),即:
ELBO=Eqϕ(z∣x)[logp(x∣z)]−KL(qϕ(z∣x)∥p(z))\text{ELBO} = \mathbb{E}_{q_\phi(z|x)} \left[ \log p(x|z) \right] - \text{KL}(q_\phi(z|x) \| p(z)) ELBO=Eqϕ(z∣x)[logp(x∣z)]−KL(qϕ(z∣x)∥p(z))
3. 如何理解ELBO?
ELBO由两部分组成:
- 重构项 Eqϕ[logp(x∣z)]\mathbb{E}_{q_\phi}[\log p(x|z)]Eqϕ[logp(x∣z)]:
衡量从隐变量 zzz 重构数据 xxx 的质量(类似VAE中的解码器损失)。 - KL正则项 −KL(qϕ(z∣x)∥p(z))-\text{KL}(q_\phi(z|x) \| p(z))−KL(qϕ(z∣x)∥p(z)):
迫使变分分布 qϕ(z∣x)q_\phi(z|x)qϕ(z∣x) 接近先验 p(z)p(z)p(z)(如标准高斯),防止过拟合。
直观解释:
- 最大化ELBO 等价于 最小化 −ELBO-\text{ELBO}−ELBO(即负对数似然的变分上界)。
- 由于 logp(x)≥ELBO\log p(x) \geq \text{ELBO}logp(x)≥ELBO,优化ELBO间接优化了真实的对数似然。
4. 与负对数似然的关系
- 直接最小化负对数似然 −logp(x)-\log p(x)−logp(x) 不可行时,通过最大化ELBO来逼近。
- 在VAE中,损失函数 L=−ELBO\mathcal{L} = -\text{ELBO}L=−ELBO 就是重构误差 + KL散度。
5. 总结
负对数似然的变分下界(ELBO)是一个可优化的目标函数,通过引入简单的分布 qϕ(z∣x)q_\phi(z|x)qϕ(z∣x) 来近似复杂后验,从而解决隐变量模型的学习问题。其核心思想是用可计算的ELBO代替不可计算的对数似然,并通过优化ELBO平衡数据拟合(重构)和模型复杂度(KL正则)。
参考
- 狗都能看懂的DDPM论文
- DDPM论文解读1
- DDPM论文解读2