机器学习之数据预处理学习总结
在机器学习中,数据预处理是模型训练前至关重要的环节,直接影响模型的性能和准确性。通过本次学习,我系统掌握了数据预处理的核心方法与工具,现将主要内容总结如下:
一、缺失值处理
缺失值是实际数据中常见的问题,处理方式主要包括以下几种:
Pandas 中的缺失值处理
- 识别缺失值:使用
isnull()函数判断单元格是否为空,可直观查看数据缺失情况。 - 自定义缺失值标识:通过
na_values参数指定 “n/a”“na” 等字符串作为缺失值标识,确保数据一致性。 - 删除缺失值:
dropna()函数可删除包含空字段的行,参数axis(默认 0,删除行)、how(“any” 有一个空即删除,“all” 全为空才删除)等可灵活控制删除规则。 - 填充缺失值:
fillna()函数用指定值替换空字段,常见方式包括:- 固定值填充(如用 666 填充);
- 均值填充(
mean())、中位数填充(median()),适用于数值型数据,能保留数据整体分布特征。
- 识别缺失值:使用
Scikit-learn 中的缺失值处理
SimpleImputer是处理缺失值的常用工具,支持多种策略:- 均值填补(
strategy="mean"); - 中位数填补(
strategy="median"); - 常数填补(
strategy="constant",需指定fill_value); - 众数填补(
strategy="most_frequent"),适用于分类特征(如 “Embarked” 港口信息)。
- 均值填补(
二、数据标准化
标准化的核心是将数据转换为统一规格,消除量纲影响,常见方法包括:
最大最小值标准化(MinMaxScaler)
- 将数据缩放到指定范围(默认 [0,1]),公式为:Xscaled=Xmax−XminX−Xmin。
- 通过
feature_range参数可自定义缩放范围(如 [5,10])。
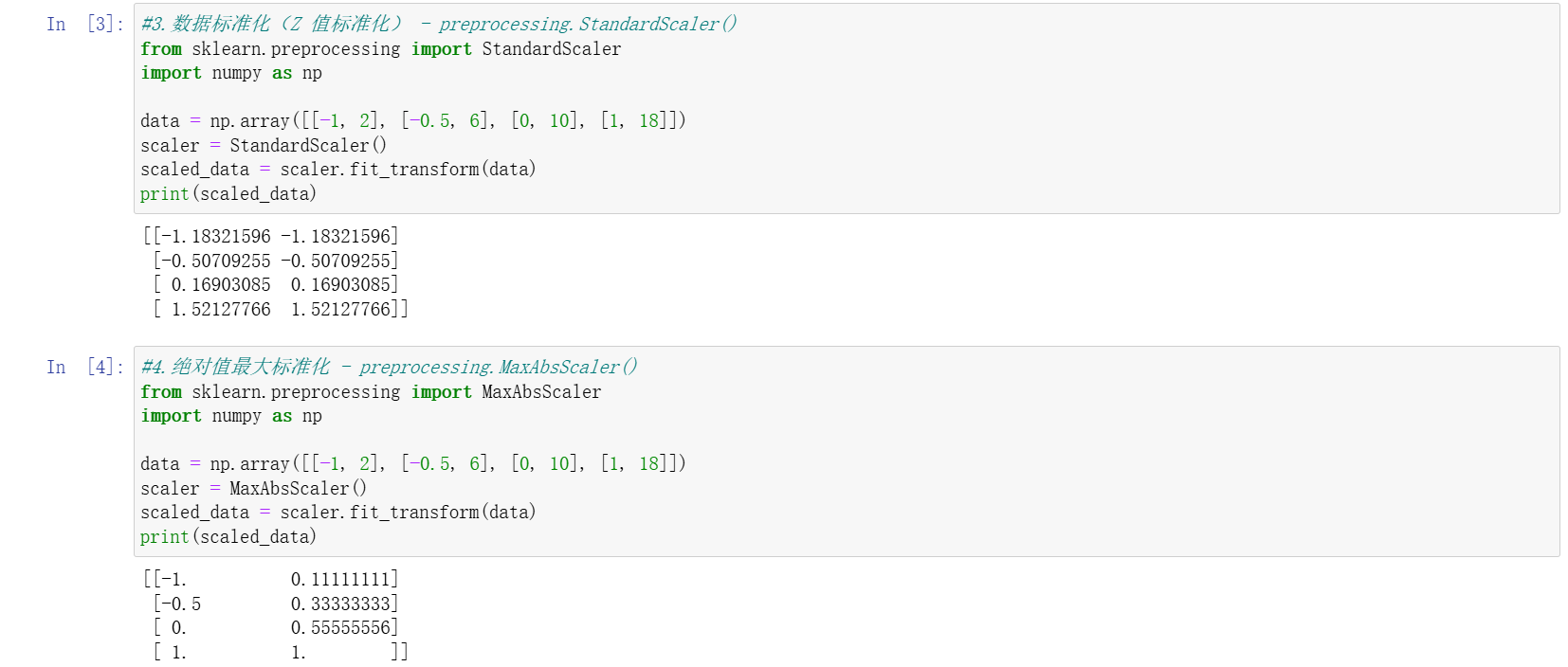
Z 值标准化(StandardScaler/scale ())
- 将数据转换为均值为 0、标准差为 1 的标准正态分布,公式为:Xscaled=σX−μ。
scale()函数直接处理数据,StandardScaler以类的形式实现,支持保存均值和标准差用于新数据转换。
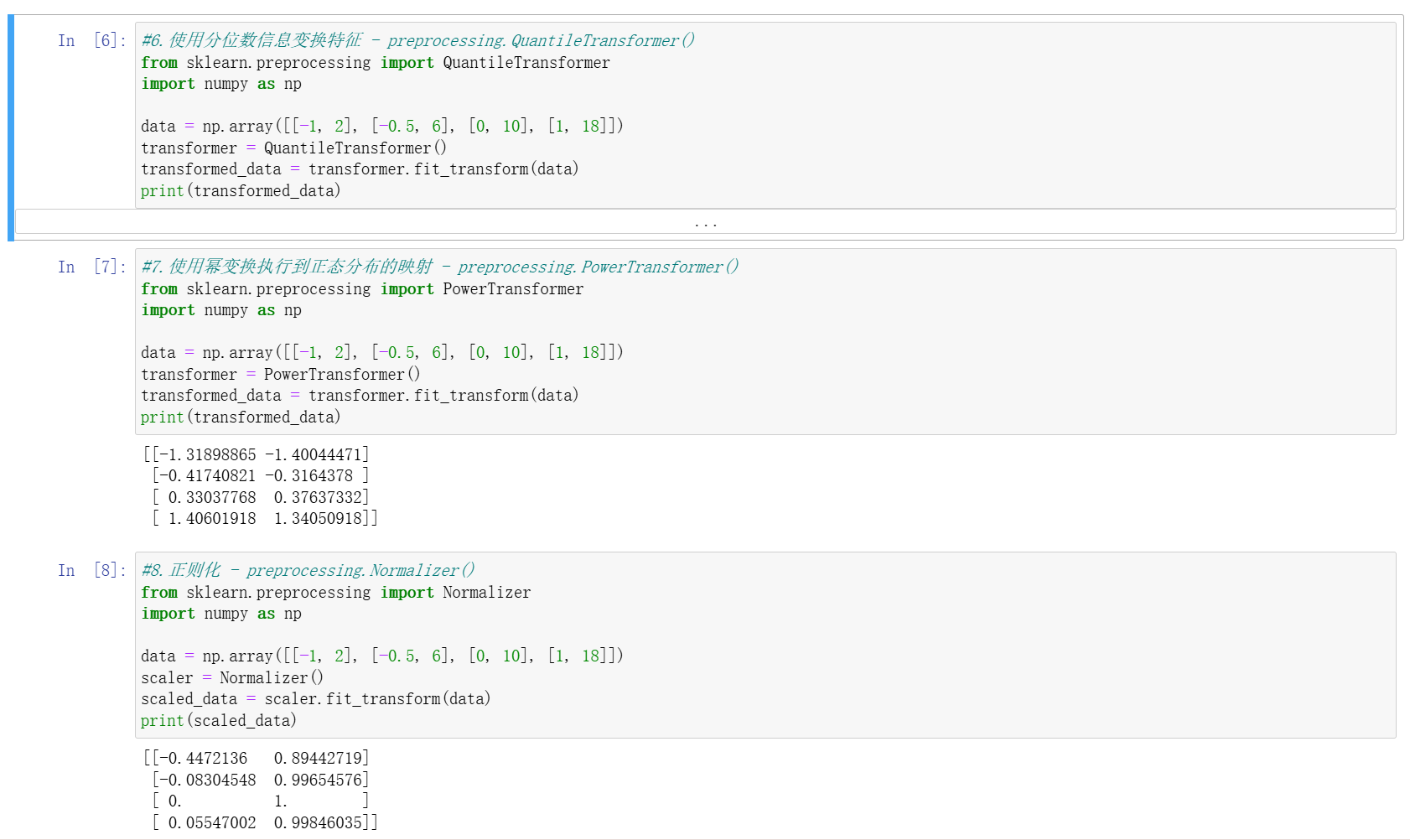
其他标准化方法
MaxAbsScaler:按绝对值最大值缩放,使数据落在 [-1,1] 区间,适用于稀疏数据。RobustScaler:基于中位数和四分位距处理,抗离群值能力强。QuantileTransformer:通过分位数信息将数据映射为均匀或正态分布,适用于偏态数据。PowerTransformer:通过幂变换(如 Box-Cox 变换)将数据映射为近似正态分布,适合需正态假设的模型。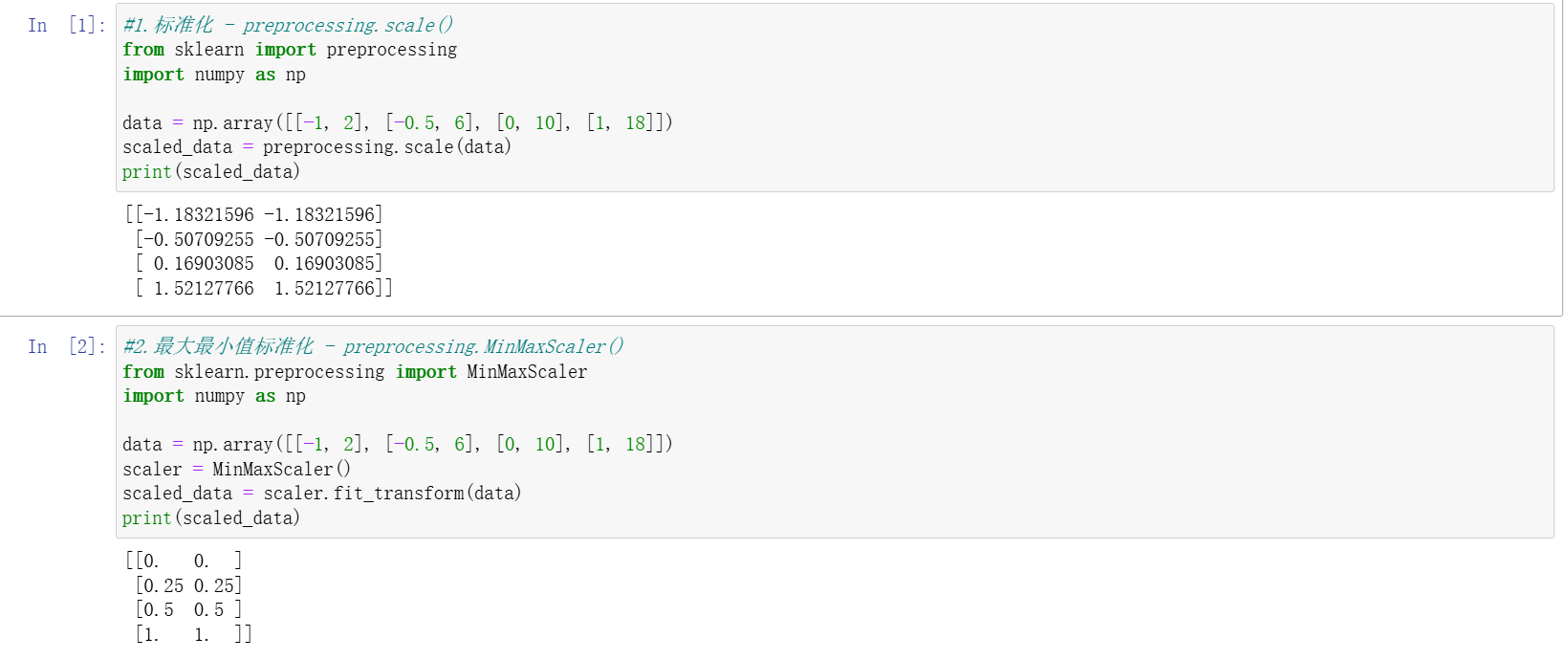

三、特征编码
将分类特征转换为数值形式是预处理的关键步骤,根据特征类型可分为:
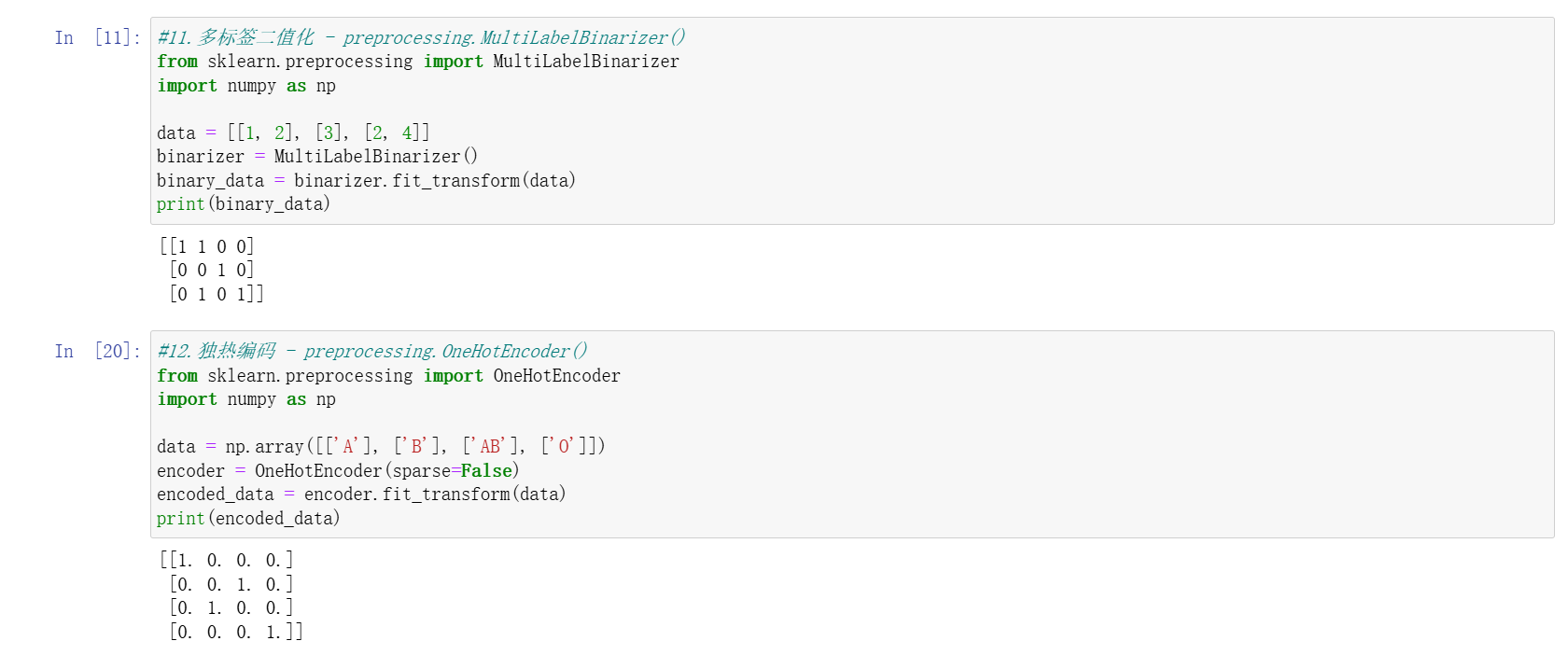
独热编码(OneHotEncoder)
- 为每个类别创建二进制特征,适用于无顺序关系的名义变量(如血型 “A/B/AB/O”)。
- 避免模型误解类别间的数值关联,如将 “A” 编码为 (1,0,0,0),“B” 编码为 (0,1,0,0) 等。
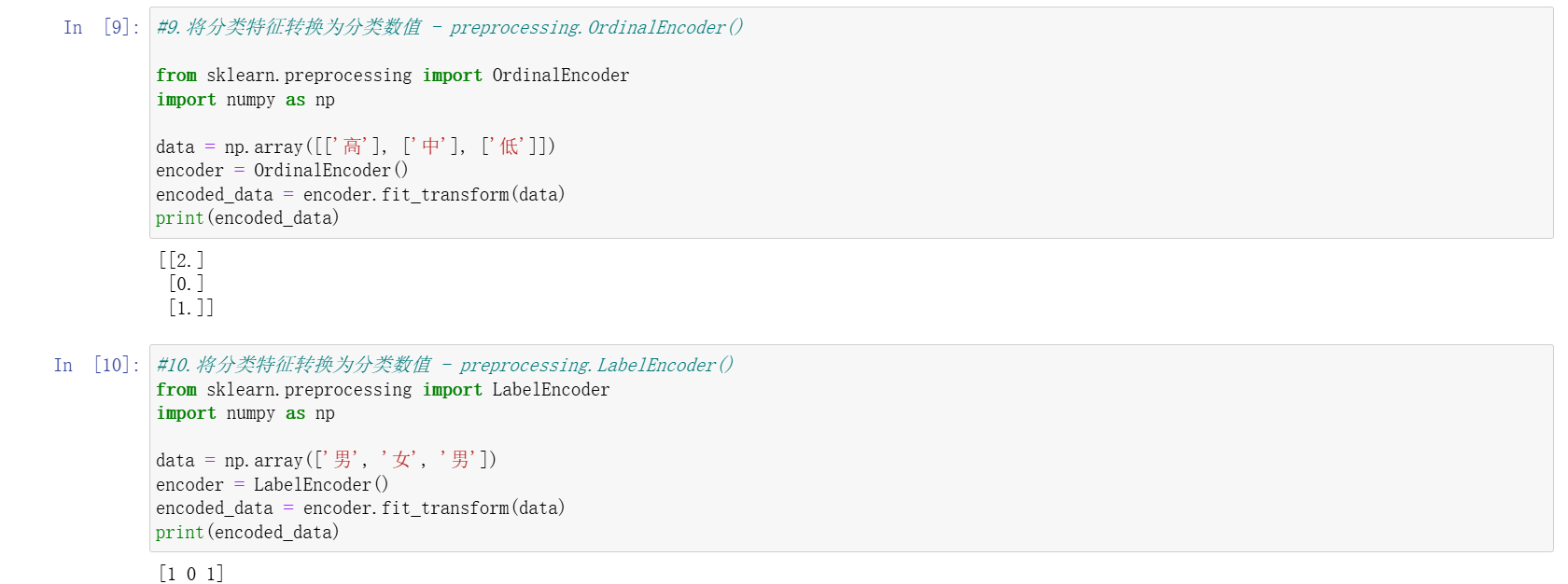
序号编码(OrdinalEncoder)
- 将有序分类特征转换为有序整数(如 “高 / 中 / 低” 编码为 3/2/1),保留类别间的顺序关系。
标签编码(LabelEncoder)
- 用于一维目标标签(如 “男 / 女”),转换为 0/1 等整数,不建议用于输入特征。
其他编码方式
MultiLabelBinarizer:对多标签数据(如一篇文章的多个类别)进行二值化编码。- 目标标签编码:处理无大小关系的目标值,用 0 到 n_classes-1 编码,但数值本身无实际含义。
四、数据转换与离散化
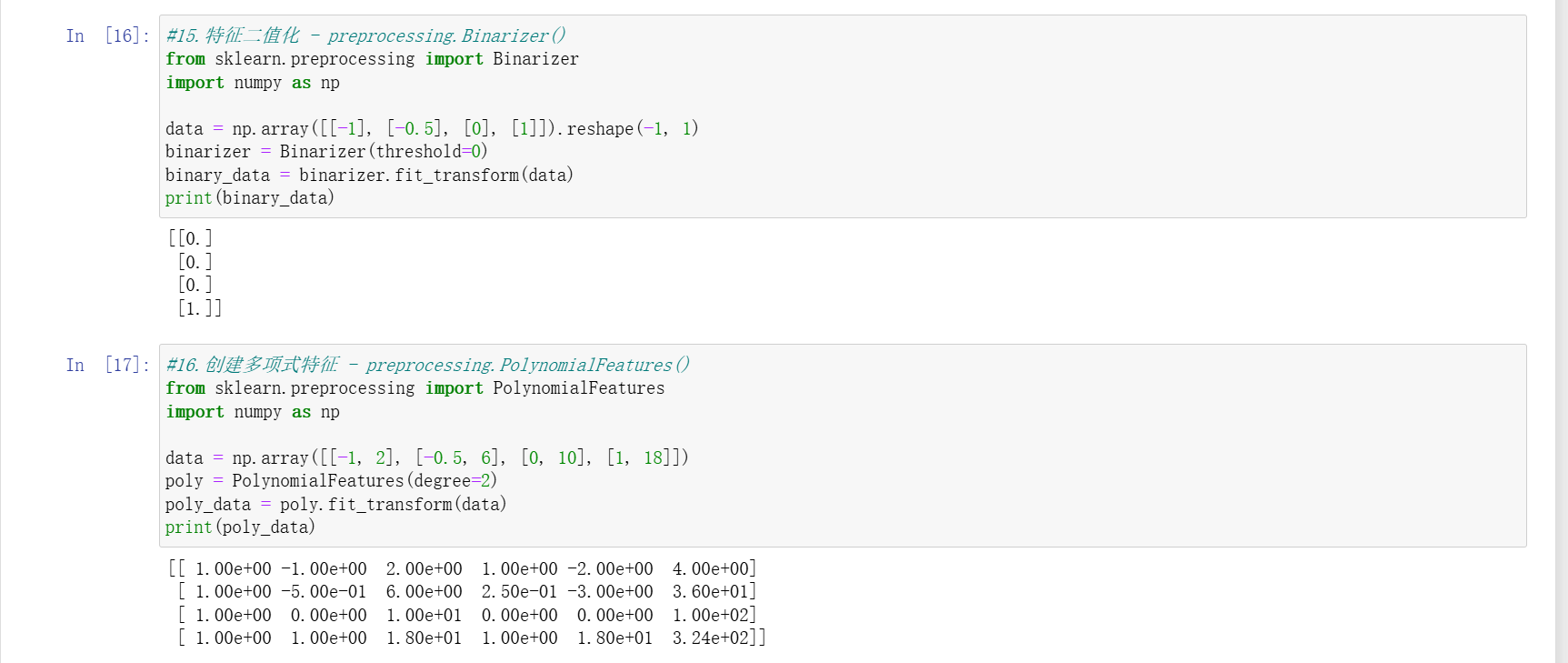
数据二值化(Binarizer)
- 根据阈值将数据分为 0 或 1(如年龄 > 30 为 1,否则为 0),简化特征表示。
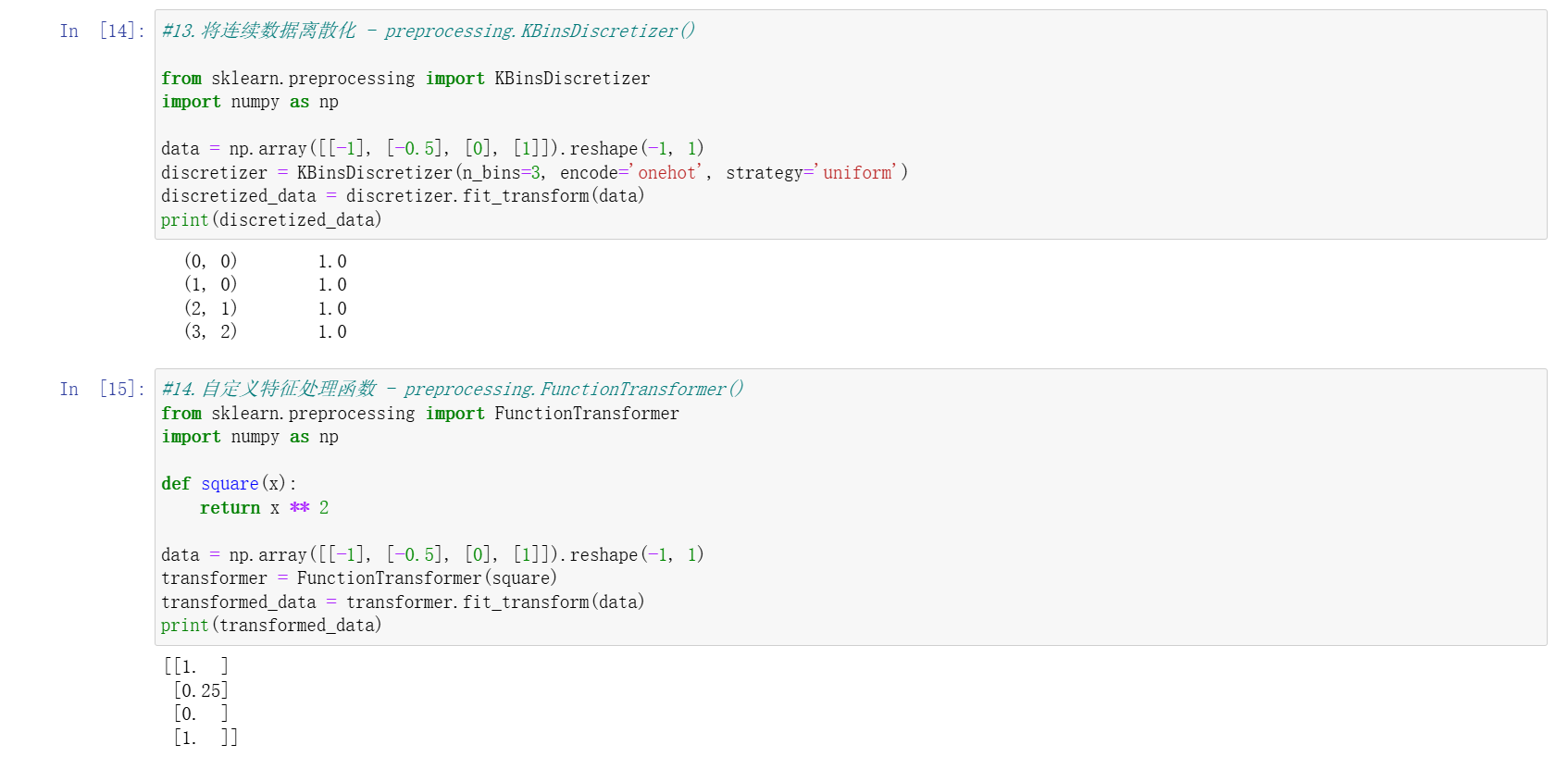
连续数据离散化(KBinsDiscretizer)
- 将连续特征划分为多个区间(分箱),支持均匀分箱、分位数分箱等策略,可转换为整数或独热编码。
多项式特征生成(PolynomialFeatures)
- 生成特征的平方项、交叉项等,捕捉特征间的非线性关系,如将 (x1, x2) 扩展为 (1, x1, x2, x1², x1x2, x2²)。
自定义特征处理(FunctionTransformer)
- 将自定义函数(如对数变换、平方运算)封装为转换器,灵活满足特定处理需求。

五、总结与应用
数据预处理的核心目标是提升数据质量,使数据更适合模型输入。实际应用中需根据数据特点选择合适方法:
- 数值型数据常需标准化或归一化;
- 分类特征需根据是否有序选择编码方式;
- 缺失值和离群值需针对性处理,避免影响模型学习。
掌握scikit-learn的preprocessing模块和pandas的相关工具,能高效完成预处理流程,为后续模型训练奠定坚实基础。