告别 Dify 工作流,让 NL2SQL 落地更直接
用过Dify的朋友都知道,基于 Dify 实现智能问数或者 NL2SQL,强依赖于工作流,存在的限制不少……
但是,我新发现了一款 AI 智能体开发平台,可以通过NL2SQL、API对接或直接上传文档表格等方式,直接实现智能问数,无需依赖工作流 ——NebulaAI。
本文就来实操练练 NebulaAI 的 NL2SQL 能力。
NebulaAI官方(免费下载):https://www.cloudtogo.cn/product-NebulaAI
什么是 NebulaAI?
一款企业级 AI Agent 开发平台,和Dify的主打场景类似,聚焦企业级应用场景,另外也具有一些独特的优势。总体来说,融合了大模型、RAG 技术、NL2SQL、工作流自动化、插件集成、低代码卡片等多项技术能力。
在智能问数方面,NebulaAI 的 NL2SQL 技术就值得另说了,用户无需再为复杂的 SQL 语法头疼,只需用自然语言描述自己的查询需求,NebulaAI 就能凭借大模型的自然语言处理和理解能力,将用户的自然语言自动精准地转换为对应的 SQL 语句,并从数据库中快速检索出所需数据。
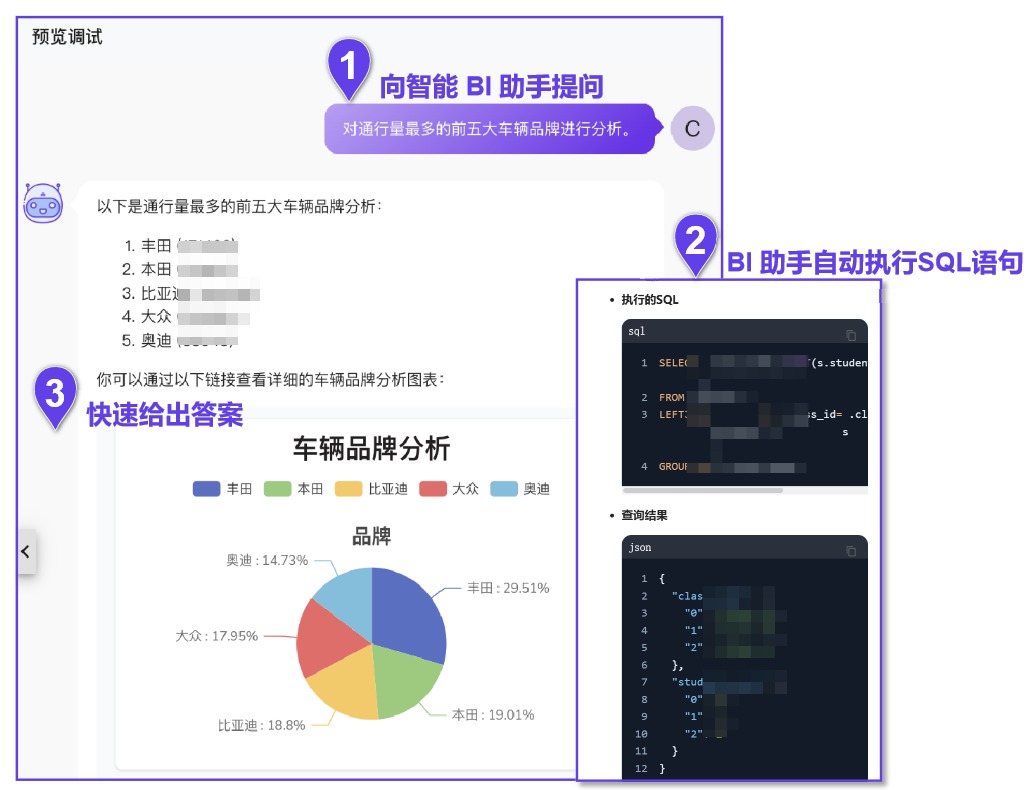
【图】NebulaAI NL2SQL 功能展示
NebulaAI NL2SQL 功能实操
NebulaAI 的数据库 NL2SQL 功能为用户提供了一种简单、高效的方式来管理和处理结构化数据.
自然语言支持:允许用户通过自然语言进行数据库查询操作。
结构化数据管理:支持多种常见的数据结构,用户可以方便地管理各种数据类型。
高效的数据处理:利用 NebulaAI 的智能引擎,保证数据库操作的高效性和准确性。
灵活的查询能力:用户可以通过简单的语言或复杂的查询需求,快速获取所需数据。
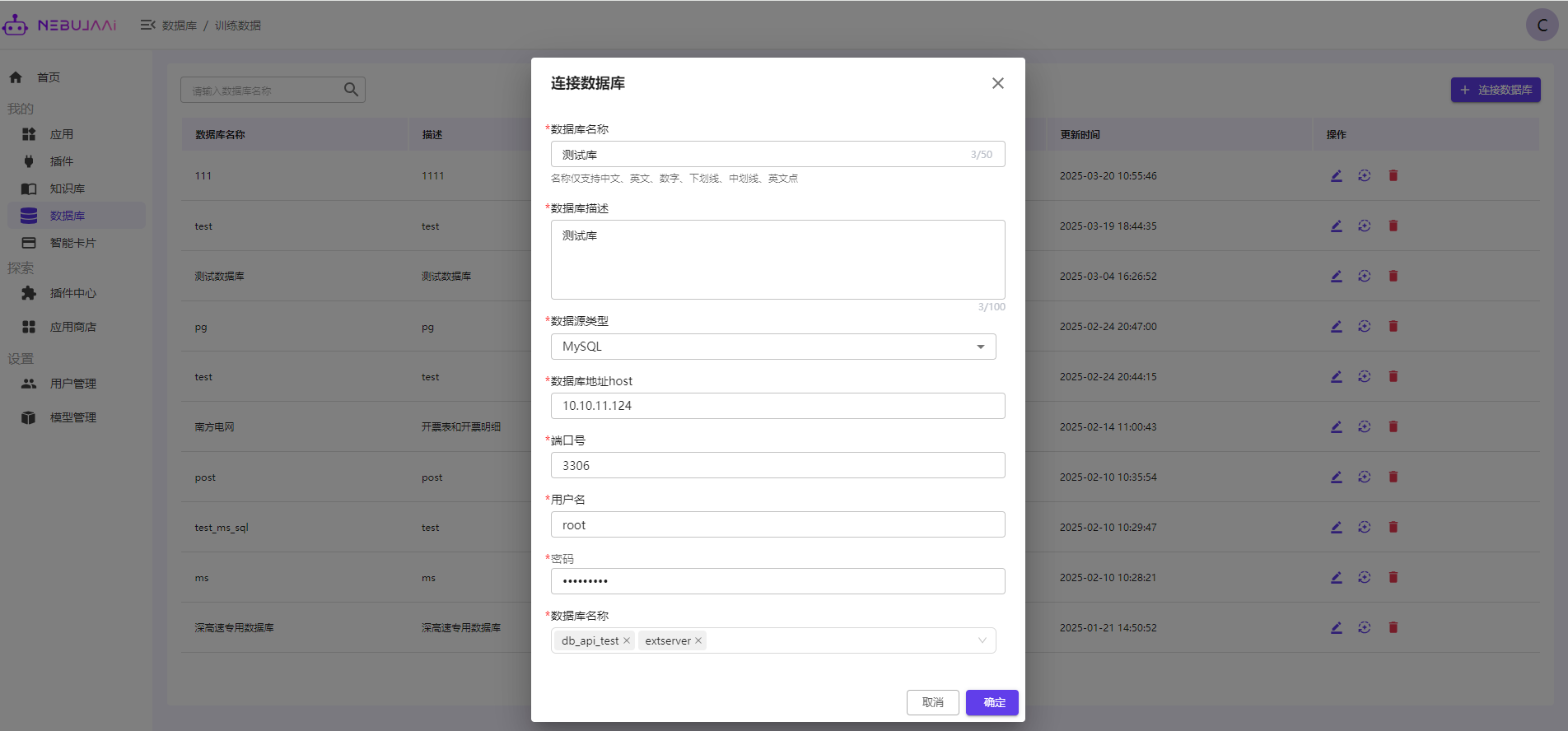
第一步、创建数据库连接
1.1 数据库连接的创建
在 NebulaAI 中,您可以创建并管理多个数据库。
数据库创建时需要提供以下信息:
数据库名称:设置数据库的名称。
数据库描述:对数据库进行简要描述。
数据源类型:目前支持 MySQL 数据库。
数据库地址:设置数据库的主机地址。
端口号:数据库连接的端口号。
用户名和密码:用于连接数据库的凭证。
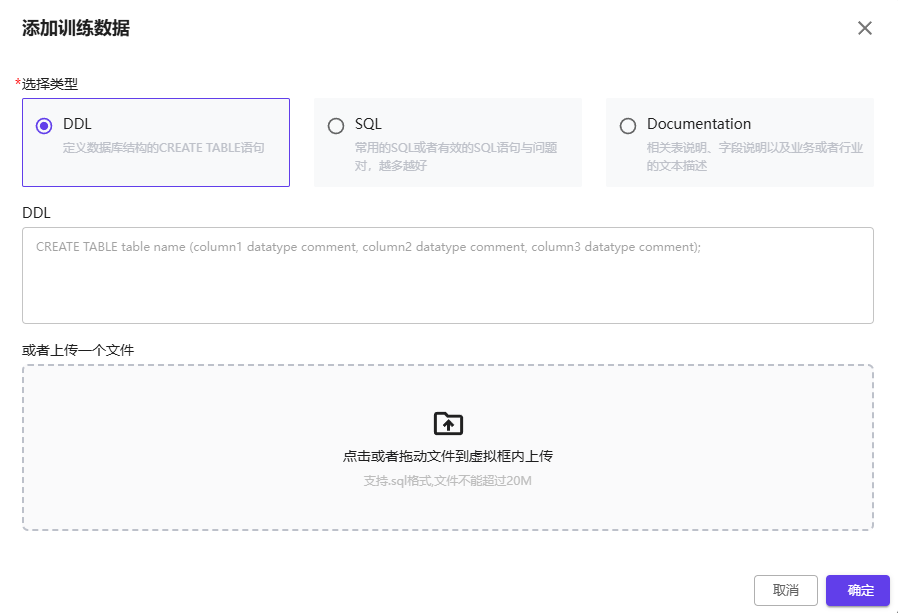
1.2 训练数据类型
在 NebulaAI 中,训练数据类型分为三类,分别为 DDL、SQL 和 Documentation。每一类数据类型都有其特定的用途,帮助智能体正确理解和处理数据库结构及相关业务内容。
DDL(数据库定义语言)
DDL 用于定义数据库的结构,主要包括数据库表的创建语句(CREATE TABLE)。上传 .sql 文件或手动输入相关 DDL 语句可以帮助系统理解数据库的表结构和字段信息。
功能说明:
定义数据库表的结构和字段类型。
须提供 CREATE TABLE 语句来描述表的字段、主键、外键等关系。
允许上传文件或直接输入文本内容。
SQL(结构化查询语言)
SQL 数据类型用于提供常用的 SQL 查询语句,这些语句帮助系统快速理解并执行特定的数据库查询操作。用户可以提供 SQL 查询语句和对应的问题,越多有效的 SQL 语句将有助于训练的效果。
功能说明:
提供一系列常用的 SQL 查询语句,帮助模型更好地生成和执行查询操作。
问题描述可以不提供,但必须提供有效的 SQL 查询语句。
支持各种常见的 SQL 查询操作,如 SELECT、JOIN 等。
Documentation(文档说明)
Documentation 用于提供与数据库相关的表说明、字段说明以及业务或行业的文本描述。这部分内容有助于智能体理解表结构的业务背景以及字段的具体含义。
功能说明:
提供数据库表的详细描述,解释每个字段的用途和数据类型。
允许上传相关的数据字典文件,或者直接输入文本内容,支持文件类型为 .txt、.docx、.doc 等。
该文档对训练过程非常重要,有助于提高模型对业务背景和字段含义的理解。
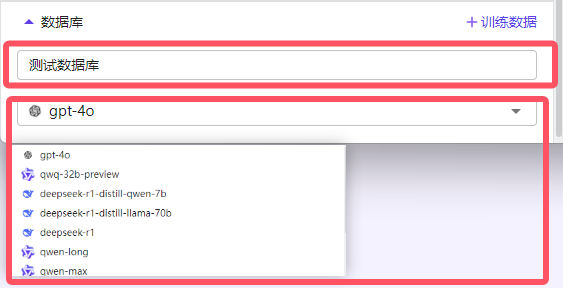
第二步、应用数据库功能使用
2.1 数据查询
应用绑定数据库后,可以在 预览调试 和 应用对话页面 中通过对话访问数据库,系统会根据用户需求智能识别并选择合适的数据库进行执行。同时用户可以切换大语言模型,不同模型在数据库语义理解上有差距,更容易找出适合该业务场景的模型。
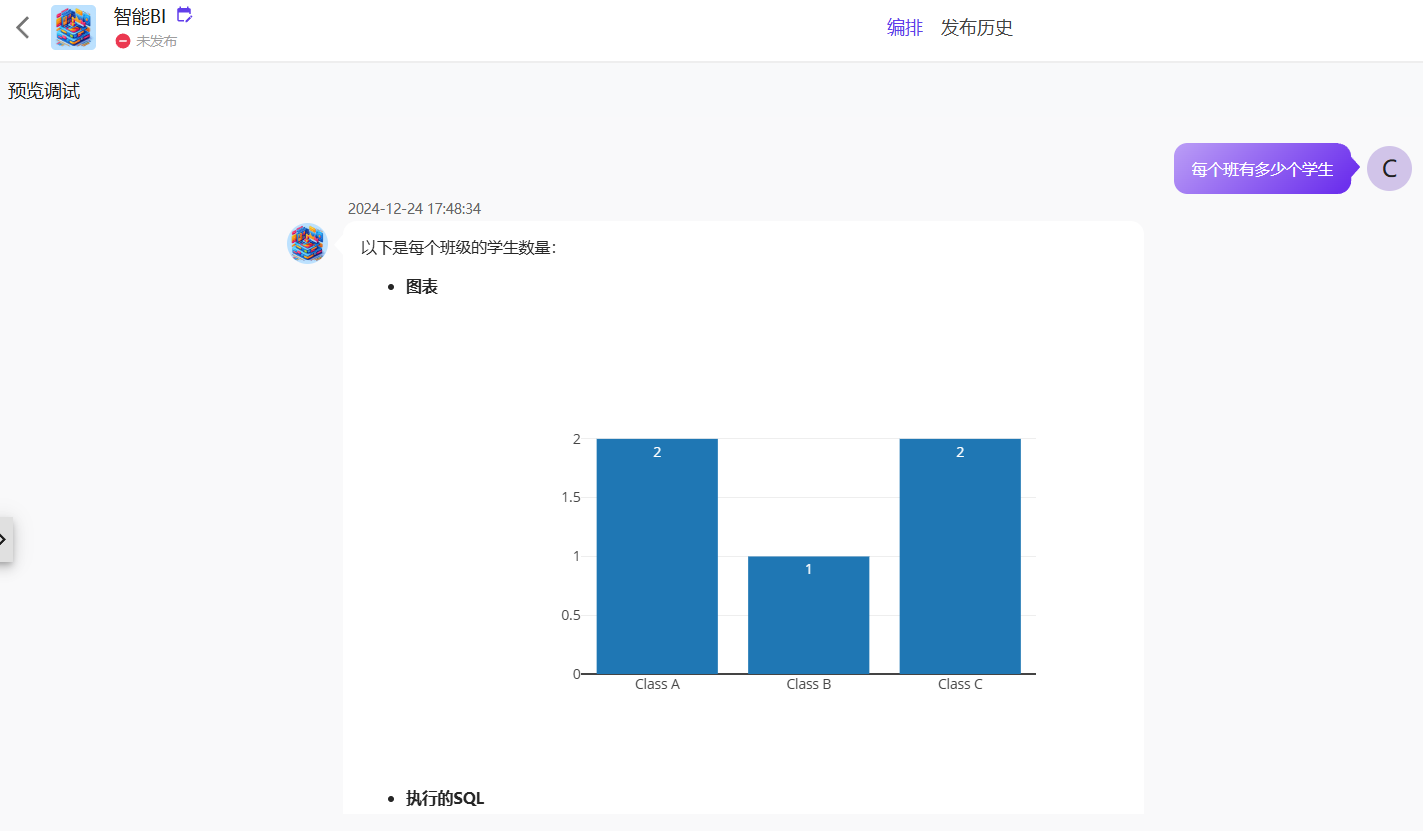
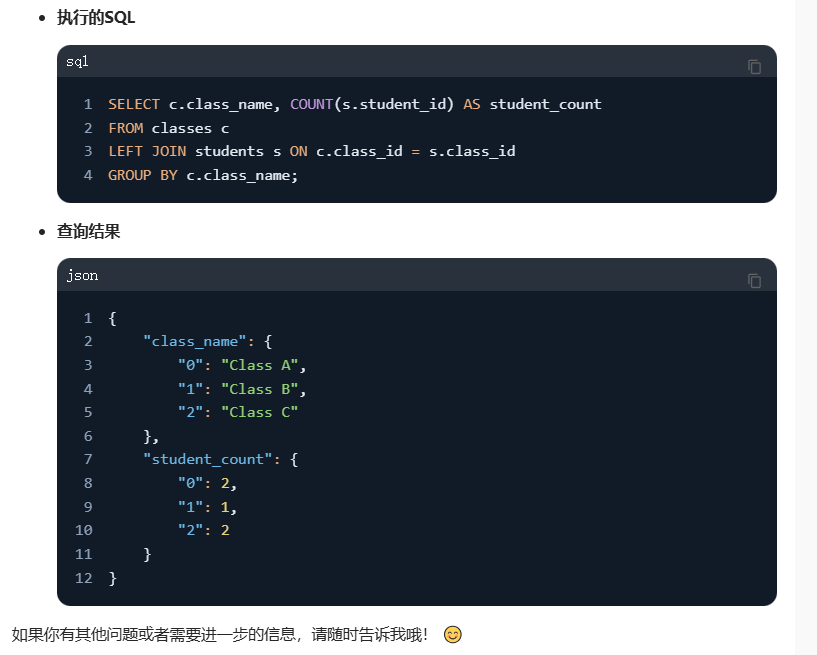
数据库查询功能支持用户通过自然语言获取所需数据。用户可以直接描述查询信息,智能体会根据描述生成图表、SQL 查询语句以及查询结果。
通过简单的自然语言描述,您可以快速获取数据查询结果。
智能体会自动识别并执行相应的 SQL 查询。
第三步、优化与注意事项
性能优化:根据业务需求和数据量大小,合理设置数据库的参数和索引,以提高查询性能和系统稳定性。确保数据库设计合理,避免性能瓶颈。
安全性:保护数据库的安全至关重要。请设置合理的用户权限、密码策略,并确保网络连接的安全性,以防止未经授权的访问和数据泄露。
数据一致性:保证数据库中数据的一致性和完整性,避免出现数据冗余或不一致的情况。