【机器学习-2】 | 决策树算法基础/信息熵
0 序言
本文将系统学习决策树算法,从决策树引入,理解信息熵、ID3与C4.5算法并剖析优缺点。
读完可初步掌握决策树核心原理及经典算法,
下篇再用一个项目实战来加深巩固知识点。
本文就先对此有个概念,理解下大概的原理就可以了,
具体从项目实战来更好去加强巩固。
以下是针对1、2章节补充数据集展示、详细计算及对比分析后的内容,更适合零基础读者理解:
1 决策树引入
1.1 案例背景
为了能更直观理解决策树的应用场景,
这边给出一个案例背景,
通过这个案例背景来更好理解。
我们先给出完整的14天气象数据集,
这里包含4个特征,
分别是outlook、temperature、humidity、windy
和1个标签,Travel决定是否适合旅游。
| 序号 | outlook(天气) | temperature(温度) | humidity(湿度) | windy(风力) | Travel(是否旅游) |
|---|---|---|---|---|---|
| 1 | sunny | hot | high | FALSE | no |
| 2 | sunny | hot | high | TRUE | no |
| 3 | overcast | hot | high | FALSE | yes |
| 4 | rainy | mild | high | FALSE | yes |
| 5 | rainy | cool | normal | FALSE | yes |
| 6 | rainy | cool | normal | TRUE | no |
| 7 | overcast | cool | normal | TRUE | yes |
| 8 | sunny | mild | high | FALSE | no |
| 9 | sunny | cool | normal | FALSE | yes |
| 10 | rainy | mild | normal | FALSE | yes |
| 11 | sunny | mild | normal | TRUE | yes |
| 12 | overcast | mild | high | TRUE | yes |
| 13 | overcast | hot | normal | FALSE | yes |
| 14 | rainy | mild | high | TRUE | no |
我们的目标是:根据新的气象指标,通过决策树模型预测是否适合出行旅游!!!
1.2 问题本质
决策树的核心实际上就是通过如果……就……的规则拆分数据。
例如,从14天气象数据集中可能提炼出规则:
- 如果
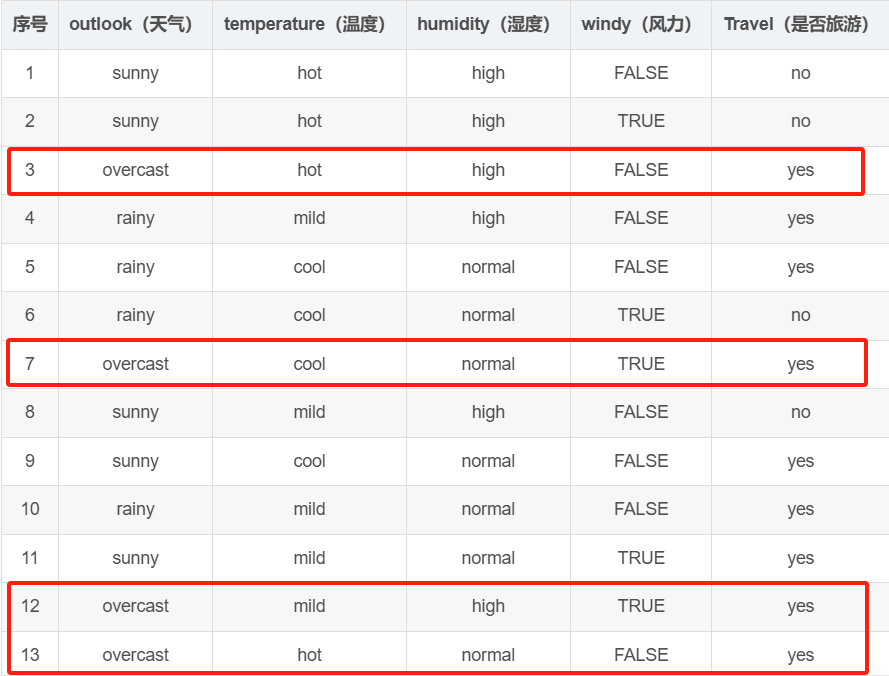
outlook=overcast,那么Travel=yes;
如下图红圈圈出来的就是符合要求的。
- 如果
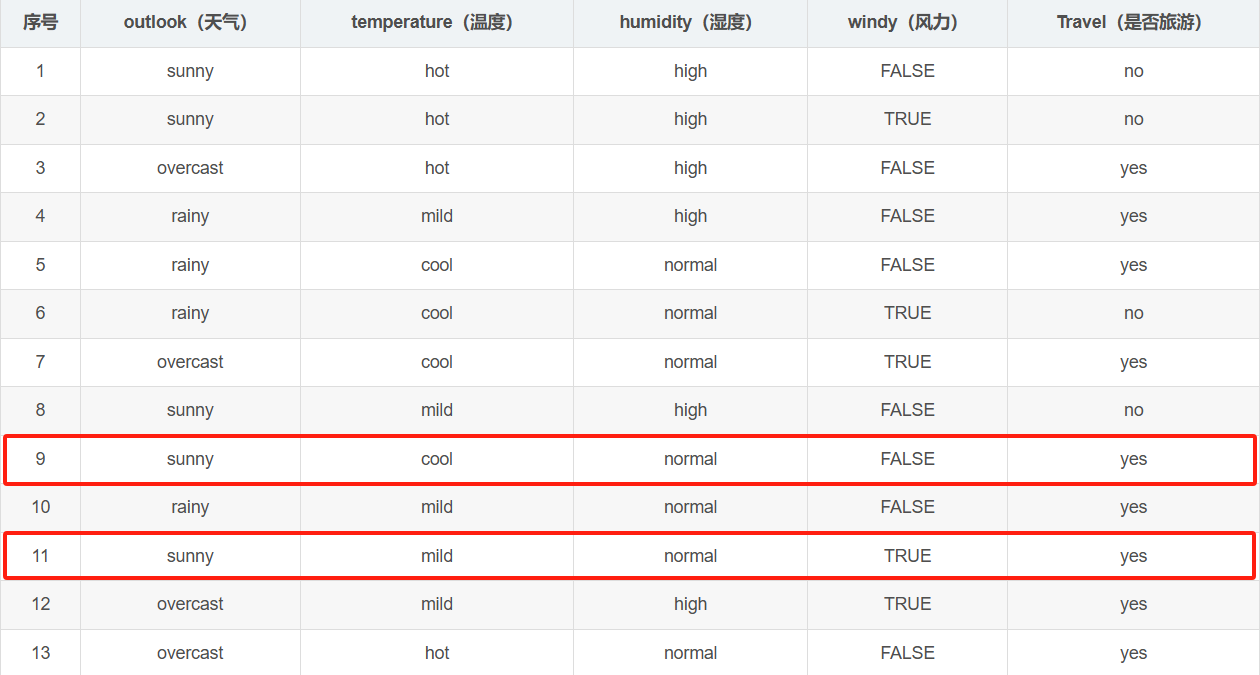
outlook=sunny且humidity=normal,那么Travel=yes。
如下图中9、11行均符合要求。
这些规则的构建依赖于对特征的优先级判断
先按哪个特征拆分数据更能降低分类的不确定性?
这就需要引入信息熵来量化不确定性。
2 信息熵基础
2.1 信息熵定义
熵是无序性(不确定性)的度量指标。
对于一个事件的所有可能结果(如旅游的结果为yes或no),
若各结果的概率为p1,p2,...,pnp_1, p_2, ..., p_np1,p2,...,pn,
则信息熵公式为:
entropy(p1,p2,⋯ ,pn)=−p1log2p1−p2log2p2−⋯−pnlog2pnentropy(p_1,p_2,\cdots,p_n) = -p_1\log_2 p_1 - p_2\log_2 p_2 - \cdots - p_n\log_2 p_nentropy(p1,p2,⋯,pn)=−p1log2p1−p2log2p2−⋯−pnlog2pn
- 概率分布越均匀,熵越大(不确定性越高);
- 概率分布越集中(某一结果概率接近1),熵越小(不确定性越低)。
2.2 案例计算(基于前面的数据集)
我们以该表1的Travel标签为例,计算初始信息熵,
再对比不同特征分组后的熵,理解熵的变化规律。
步骤1:计算总熵(初始不确定性)
表中共有14条数据,其中:
- Travel=yes的样本数:9(序号3、4、5、7、9、10、11、12、13)
- Travel=no的样本数:5(序号1、2、6、8、14)
因此,yes的概率pyes=9/14p_{yes} = 9/14pyes=9/14,no的概率pno=5/14p_{no} = 5/14pno=5/14,
总熵为:
entropy总=−914log2914−514log2514
entropy_{总} = -\frac{9}{14}\log_2\frac{9}{14} - \frac{5}{14}\log_2\frac{5}{14}
entropy总=−149log2149−145log2145
代入计算:
log2(9/14)≈−0.609log_2(9/14) \approx -0.609log2(9/14)≈−0.609,log2(5/14)≈−1.485log_2(5/14) \approx -1.485log2(5/14)≈−1.485
因此有,
entropy总≈−914×(−0.609)−514×(−1.485)≈0.940 entropy_{总} \approx -\frac{9}{14} \times (-0.609) - \frac{5}{14} \times (-1.485) \approx 0.940 entropy总≈−149×(−0.609)−145×(−1.485)≈0.940
步骤2:按特征分组计算熵(以outlook为例)
outlook有3个取值:sunny、overcast、rainy,
先统计各组中Travel的分布:
- sunny(共5条):
yes=2(序号9、11),no=3(序号1、2、8)→ pyes=2/5p_{yes}=2/5pyes=2/5,pno=3/5p_{no}=3/5pno=3/5
- overcast(共4条):
yes=4(全为yes)→ pyes=1p_{yes}=1pyes=1,pno=0p_{no}=0pno=0
- rainy(共5条):
yes=3(序号4、5、10),no=2(序号6、14)→pyes=3/5p_{yes}=3/5pyes=3/5,pno=2/5p_{no}=2/5pno=2/5
分别计算各组的熵:
entropysunny=−25log225−35log235≈0.971entropyovercast=−1×log21−0×log20=0(因结果确定)entropyrainy=−35log235−25log225≈0.971
\begin{align*}
entropy_{sunny} &= -\frac{2}{5}\log_2\frac{2}{5} - \frac{3}{5}\log_2\frac{3}{5} \approx 0.971 \\
entropy_{overcast} &= -1 \times \log_2 1 - 0 \times \log_2 0 = 0 \quad (\text{因结果确定}) \\
entropy_{rainy} &= -\frac{3}{5}\log_2\frac{3}{5} - \frac{2}{5}\log_2\frac{2}{5} \approx 0.971 \\
\end{align*}
entropysunnyentropyovercastentropyrainy=−52log252−53log253≈0.971=−1×log21−0×log20=0(因结果确定)=−53log253−52log252≈0.971
步骤3:对比总熵与分组熵
总熵为0.940,
而按outlook分组后,各组的加权平均熵为:
0.971×514+0×414+0.971×514≈0.694 0.971 \times \frac{5}{14} + 0 \times \frac{4}{14} + 0.971 \times \frac{5}{14} \approx 0.694 0.971×145+0×144+0.971×145≈0.694
显然,分组后的平均熵(0.694)低于总熵(0.940),
说明按outlook拆分后,不确定性降低了
这正是决策树选择特征的核心逻辑!!!
由此,我们结合案例验证分析后可以知道熵的特性。
2.3 熵的特性
-
极端概率下熵为0:
如
outlook=overcast时,所有样本都为yes(概率1),熵=0(结果完全确定)。 -
概率均等时熵最大:
若某特征分组中yes和no的比例为1:1(如10个样本中5个yes、5个no),则:
entropy=−0.5log20.5−0.5log20.5=1(此时熵最大)entropy = -0.5\log_2 0.5 - 0.5\log_2 0.5 = 1 \quad (\text{此时熵最大}) entropy=−0.5log20.5−0.5log20.5=1(此时熵最大)
对比表中sunny组(2yes、3no)的熵≈0.971,接近最大值1,说明该组不确定性较高。
- 决策的本质是降低熵:
从总熵(0.940)到分组熵(0.694)的下降,体现了按outlook拆分这一决策降低了不确定性。
后续章节的ID3算法,正是通过计算熵的下降幅度(信息增益)来选择最优特征。
通过计算能更清晰地展示熵的含义及决策树拆分的逻辑
那就是从初始的不确定性(总熵),到按特征分组后的不确定性降低。
3 ID3与C4.5算法
3.1 ID3算法
3.1.1 原理核心
利用信息增益选择分裂特征,不断分裂节点,直到特征信息增益很小或无特征可选。
信息增益是考虑某因素后熵的减少值,公式为:
Gain(Feature)=I(p,n)−E(Feature)Gain(Feature) = I(p,n) - E(Feature)Gain(Feature)=I(p,n)−E(Feature)
其中I(p,n)I(p,n)I(p,n)是初始总熵,E(Feature)E(Feature)E(Feature)是该特征的条件熵。
计算各特征信息增益,选最大的作为分裂标准。
以天气数据为例,计算outlook、temperature等特征的信息增益,
outlook信息增益Gain(Outlook)=0.940−0.694=0.246Gain(Outlook)=0.940 - 0.694 = 0.246Gain(Outlook)=0.940−0.694=0.246
由于其他特征增益更小,故先按outlook分裂。
3.1.2 缺点
优先选属性值多的特征,因这类特征易有更大信息增益,
但可能无实际业务意义
比方说用唯一ID做特征,虽增益大,但是却无法挖掘有效规律。
3.2 C4.5算法
3.2.1 改进思路
为解决ID3问题,引入信息增益比选特征。
先计算特征的内在信息,衡量特征自身不确定性
以outlook为例 ,公式为:
I(outlook)=−514log2514−514log2514−414log2414=1.577I(outlook) = -\frac{5}{14}\log_2 \frac{5}{14} - \frac{5}{14}\log_2 \frac{5}{14} - \frac{4}{14}\log_2 \frac{4}{14} = 1.577I(outlook)=−145log2145−145log2145−144log2144=1.577
再用信息增益比作为分裂依据,公式:
GainRatio(Feature)=Gain(Feature)I(Feature)GainRatio(Feature) = \frac{Gain(Feature)}{I(Feature)}GainRatio(Feature)=I(Feature)Gain(Feature)
通过除以内在信息,平衡多值特征的影响,优先选更具业务价值的特征 。
4 决策树算法的优缺点
4.1 优点
- 直观易懂:以
如果……就……规则呈现,像流程图,人类易理解、解释,规则清晰; - 无需数据预处理:不要求
数据归一化、标准化,可直接处理类别型、数值型数据; - 处理多分类问题:自然适配多分类场景,能
有效拆分数据到不同类别。
4.2 缺点
- 过拟合风险:模型易对训练数据细节
过度学习,泛化能力差(如果训练数据有噪声,决策树会学习噪声规律,导致新数据预测不准); - 稳定性差:数据微小变化,可能导致树结构大幅改变,影响预测结果;
- 类别不平衡敏感:少数类易被多数类
淹没,分裂时可能优先满足多数类规则。
5 小结
决策树算法以如果……就……规则拆分数据做分类,
核心依托信息熵衡量不确定性,ID3用信息增益、C4.5用信息增益比选特征优化。
它直观易懂、适配多场景,但存在过拟合等问题。
下一篇文章就通过Python具体的项目来加深理解,
从而将本文的理论落地以此来解决实际分类任务,
打好基础后,后续可以进一步探索提升模型泛化能力的方法。