从指标定义到可视化:基于衡石指标平台的全链路数据治理实战
数据治理的挑战与机遇
在数字化转型浪潮中,数据已成为企业的核心资产。然而,许多企业在数据治理过程中面临着指标定义混乱、数据口径不一致、分析效率低下等痛点。这些问题不仅影响了数据驱动的决策质量,也制约了企业的业务发展。本文将详细介绍如何基于衡石指标平台构建从指标定义到可视化分析的全链路数据治理体系,帮助企业实现数据价值的最大化。
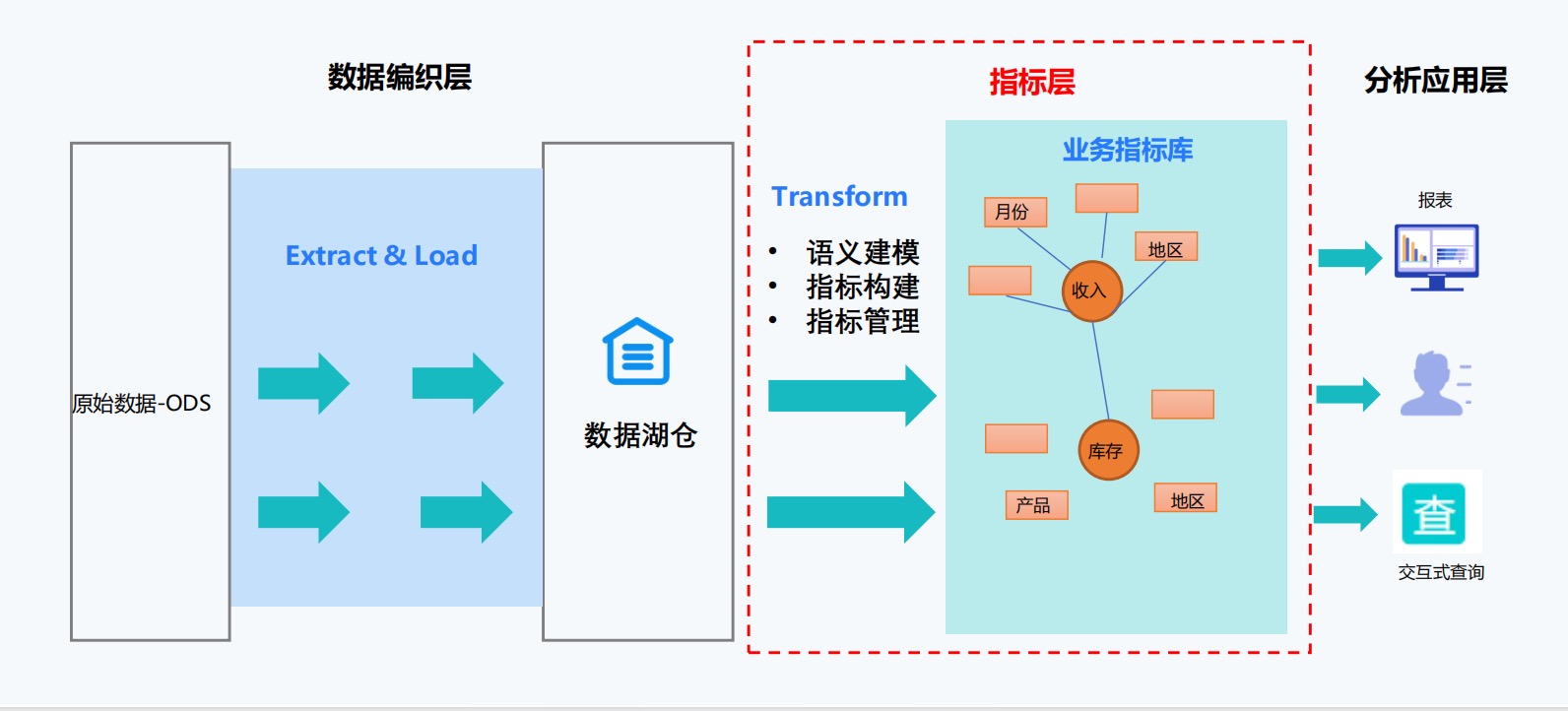
一、指标定义:数据治理的基石
1.1 指标混乱的常见问题
在实际业务场景中,我们经常会遇到以下问题:
-
同一指标在不同部门有不同的定义和计算方式
-
指标口径频繁变动导致历史数据无法对比
-
指标计算逻辑不透明,难以验证准确性
1.2 衡石指标平台的解决方案
衡石指标平台提供了统一的指标定义和管理功能:
-
语义层建模:通过业务语义层将技术性数据转化为业务人员可理解的指标
-
版本控制:记录指标定义的变更历史,支持回溯和对比
-
血缘分析:可视化展示指标的计算逻辑和数据来源
sql
-- 衡石平台中的指标定义示例 CREATE METRIC sales_amount AS SELECT SUM(amount) FROM sales WHERE status = 'completed' GROUP BY date, region;
1.3 最佳实践:构建企业指标库
-
成立跨部门的指标治理委员会
-
制定指标分类标准(基础指标、衍生指标、复合指标)
-
建立指标评审和发布流程
-
定期进行指标质量审计
二、数据加工:确保数据质量
2.1 数据质量监控
衡石平台提供全方位的数据质量保障机制:
-
数据探查:自动分析数据分布、异常值和缺失情况
-
质量规则:支持自定义数据验证规则(唯一性、一致性、准确性等)
-
异常预警:设置阈值触发告警通知
2.2 数据加工流水线
平台采用分层建模方法:
-
ODS层:保持原始数据不变
-
DWD层:进行数据清洗和标准化
-
DWS层:构建面向主题的数据集市
-
ADS层:生成可直接用于分析的聚合数据
python
# 数据清洗规则配置示例
{"rule_name": "sales_amount_validation","rule_type": "range_check","params": {"min_value": 0,"max_value": 1000000},"action": "flag_and_continue"
}
三、指标计算:高性能处理引擎
3.1 计算架构设计
衡石平台采用混合计算架构:
-
预计算:对高频访问的指标进行预先聚合
-
实时计算:支持流式数据的即时分析
-
缓存机制:智能缓存热门查询结果
3.2 优化策略
-
分区裁剪:基于查询条件自动选择相关数据分区
-
列式存储:减少I/O开销
-
向量化执行:提升CPU利用率
-
分布式计算:水平扩展处理能力
四、可视化分析:释放数据价值
4.1 自助式分析平台
衡石平台提供:
-
拖拽式报表构建
-
交互式分析功能(下钻、筛选、联动)
-
多终端适配(PC、移动、大屏)
4.2 典型可视化场景
-
实时业务监控看板
-
关键指标趋势图
-
异常状态预警
-
地理分布热力图
-
-
深度分析报告
-
多维度对比分析
-
漏斗转化分析
-
用户行为路径分析
-
javascript
// 可视化配置示例
{"chartType": "line","metrics": ["sales_amount", "order_count"],"dimensions": ["date"],"filters": ["region = 'East'"],"options": {"title": "Daily Sales Trend","yAxis": [{"name": "Amount"}, {"name": "Count"}]}
}
五、全链路治理实践案例
5.1 某零售企业案例
挑战:
-
2000+SKU的销售数据分散在多个系统
-
促销活动效果评估滞后
-
库存周转率计算不一致
解决方案:
-
统一商品、门店、会员主数据
-
建立标准化的销售指标体系
-
实现T+1的销售数据更新
-
构建总部到门店的多级数据看板
成效:
-
报表开发周期缩短70%
-
数据争议减少90%
-
促销调整响应时间从3天缩短至4小时
六、未来展望:AI增强的数据治理
-
智能指标推荐:基于业务场景自动建议相关指标
-
异常检测:利用机器学习识别数据异常模式
-
自然语言查询:通过对话方式获取数据分析结果
-
自动化文档:根据数据血缘生成技术文档
结语
通过衡石指标平台实现从指标定义到可视化的全链路数据治理,企业能够建立统一的数据语言,提升数据质量,加速分析洞察。这不仅解决了当前的数据管理难题,更为未来的数据智能应用奠定了坚实基础。数据治理是一项持续的工作,需要技术工具、组织流程和人员能力的协同推进。希望本文的实战经验能为您的数据治理之旅提供有价值的参考。