CLIP与SIGLIP对比浅析
CLIP 和 SIGLIP 的核心区别在于损失函数的设计:CLIP 使用基于 softmax 的对比损失(InfoNCE),强制正样本在全局对比中压倒所有负样本,计算成本高且受限于负样本数量;SIGLIP 改用基于 sigmoid 的二元分类损失,独立判断每个样本对的匹配概率,无需全局归一化,计算更高效、内存占用低,尤其适合超大规模负采样(如百万级)和多标签场景。简言之,CLIP 强调“最优匹配”,适合小规模精准检索;SIGLIP 侧重“灵活匹配”,更适合开放域、大规模数据下的高效训练。
CLIP(Softmax + 对比损失)
CLIP 使用 对称对比学习损失(InfoNCE loss),通过 softmax 计算概率分布,强制正样本对的相似度远高于所有负样本对。CLIP的损失函数为
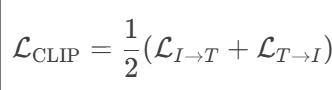
其中,
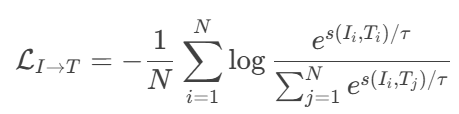 为图像到文本的损失
为图像到文本的损失
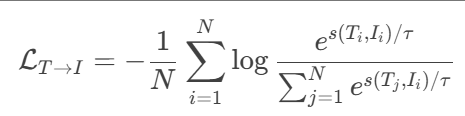 为文本到图像的损失
为文本到图像的损失
为什么使用两种损失:
增强模型的双向对齐能力
单一损失的局限性:如果仅用
I→T损失(例如仅让图像匹配正确文本),模型可能忽略反向的文本特征优化(如文本编码器未充分学习区分图像)。对称损失的作用:
I→T损失:强制图像特征靠近对应文本特征。T→I损失:强制文本特征靠近对应图像特征。双向约束 确保视觉和语言特征在共享嵌入空间中全面对齐。
避免模态偏差(Modality Bias)
问题:若仅用单向损失,模型可能偏向某一模态(例如图像编码器主导,文本编码器弱化),导致跨模态检索时性能不均衡。
对称损失的平衡性:
例如,在图文搜索中,用户可能输入文本搜图(T→I),也可能上传图搜文(I→T),双向训练保证两种任务均表现良好。
SigLIP
SIGLIP 将图文匹配视为 二元分类问题,采用成对Sigmoid损失,允许模型独立地对每个图像-文本对进行操作,而无需对批次中的所有对进行全局查看,独立判断每个图像-文本对是否匹配。损失函数为
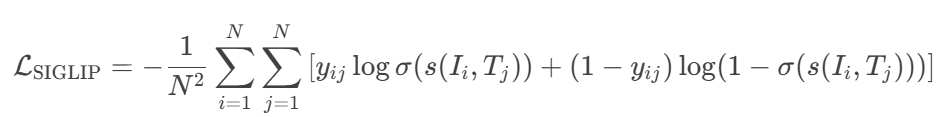
其中,
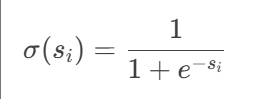 代表图像与文本匹配使用sigmod函数
代表图像与文本匹配使用sigmod函数
CLIP 的损失函数基于 softmax + 对比损失(InfoNCE),其计算效率受限于以下问题:
(1) 分母的全局求和:softmax 的分母需要对所有负样本的指数项求和,损失需要一个全局归一化因子(突出显示的分母),这会引入二次内存复杂性。
(2) 梯度计算的依赖性:softmax 的梯度依赖于所有样本的 logits,导致反向传播时必须维护整个相似度矩阵。
(3) 内存消耗高:存储所有负样本的 logits 和中间结果(如 esjesj)需要大量 GPU 内存,限制 batch size。
SIGLIP 使用 sigmoid + 二元交叉熵损失,其优势在于:
(1) 独立计算,无需全局归一化:Sigmoid 对每个 logit 独立计算,不需要计算所有样本的和,每个样本的处理是独立的。
(2) 损失函数的分解性:二元交叉熵损失对每个样本单独计算,仅依赖当前样本的 logit 和标签,无需其他样本参与。
(3) 内存友好:只需存储当前样本的 logit 和标签,每个图像-文本对(正或负)都单独评估,无需维护全局归一化相似度矩阵。适合分布式训练,可轻松扩展到超大规模负采样(如百万级)。
总结
CLIP:
使用 softmax + 对比损失,强调 全局最优匹配。
适合小规模负样本(如 batch size=512),但对超参数敏感。
SIGLIP:
使用 sigmoid + 二元分类损失,独立判断每个样本。
优势:
计算高效(适合超大规模负采样,如 1M)。
梯度稳定(不受负样本数量影响)。
支持多标签(如一张图对应多个描述)。
训练更鲁棒(对超参数不敏感)。