string【下】- 补充
string的文档链接:string - C++ Reference
一、谈论swap
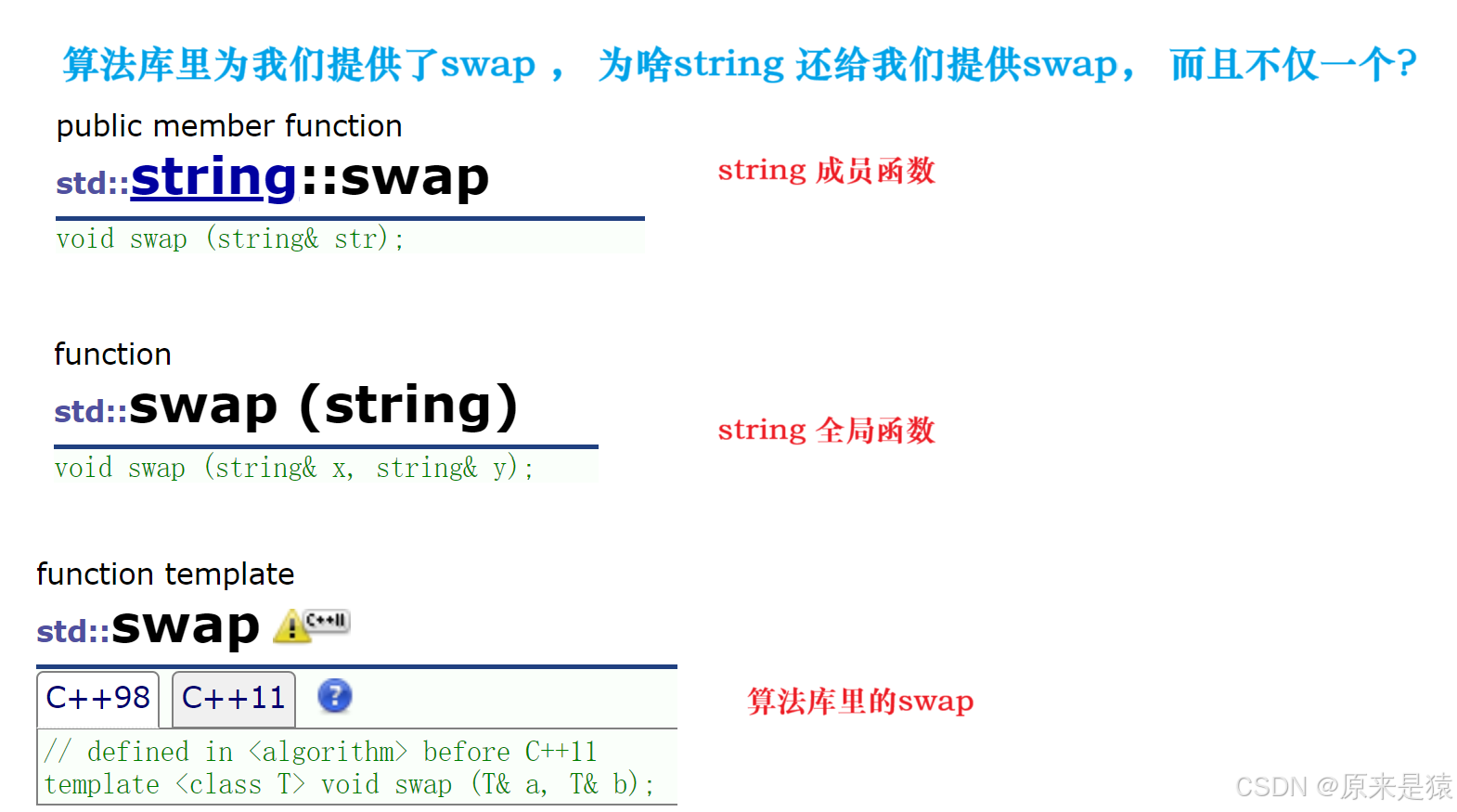
我们首先看一下 , 算法库里面的 swap :
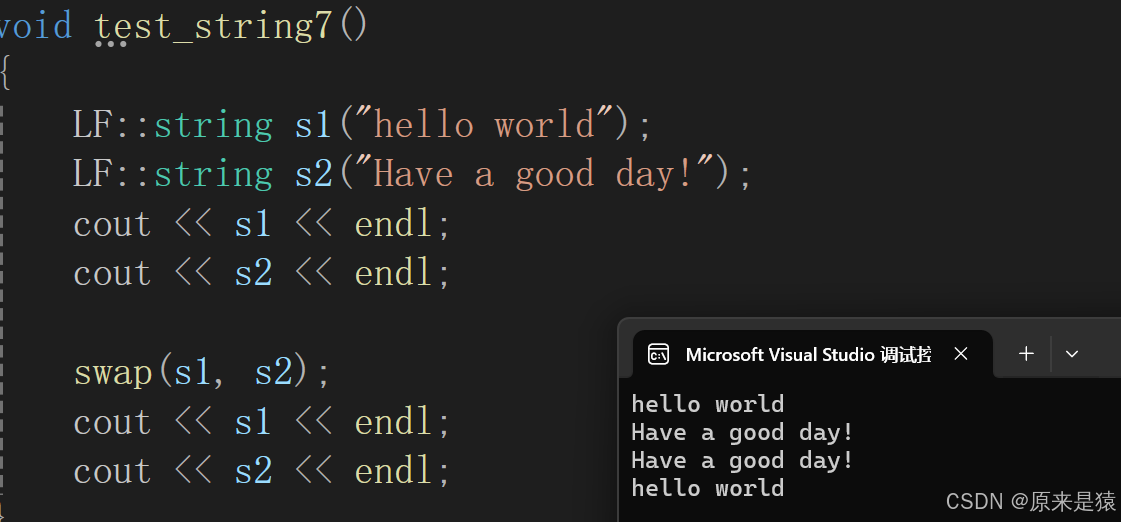

对于两个 string 对象的交换 , 仅仅改变指向 不久可以了吗 ? string 的成员函数也的确是这么做的 。(复用了算法库的swap ! 仅仅是内部指针指向的交换)
void string::swap(string& s){std::swap(_str, s._str);std::swap(_size, s._size);std::swap(_capacity, s._capacity);}既然有了成员函数 swap , 全局这块 为啥还有有一个swap , 不是浪费吗 ?
不浪费 , 但你使用 swap (s1 , s2 ) 的时候 , 编译器不会调用算法库的swap , 优先调用string 的全局函数swap !!! 而且全局函数的swap 是对成员函数 swap 的封装!!!
void swap(string& s1, string& s2)
{s1.swap(s2);
}二、对于构造的现代写法
其实下面要介绍的现代写法 , 没有效率的提升 , 只是简洁一点 ,本质是一种复用 。
1)拷贝构造 :
//传统写法string::string(const string& s){_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;

//现代写法string::string(const string& s){string tmp(s._str);swap(tmp);}2) 赋值重载 :
//传统写法string& string::operator=(const string& s){if (this != &s){delete[] _str;_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}return *this;}类似拷贝构造 :
string& string::operator=(const string& s)
{if (this != &s){string tmp(s._str);swap(tmp);}return *this;
}这里还可以更加简洁一点 !
string& string::operator=(string& s){swap(s);return *this;}三、写时拷贝与引用计数
注 : 这个方式其实现在差不多都淘汰了 ,早期的g++使用 , 了解即可 ~ 混个脸熟

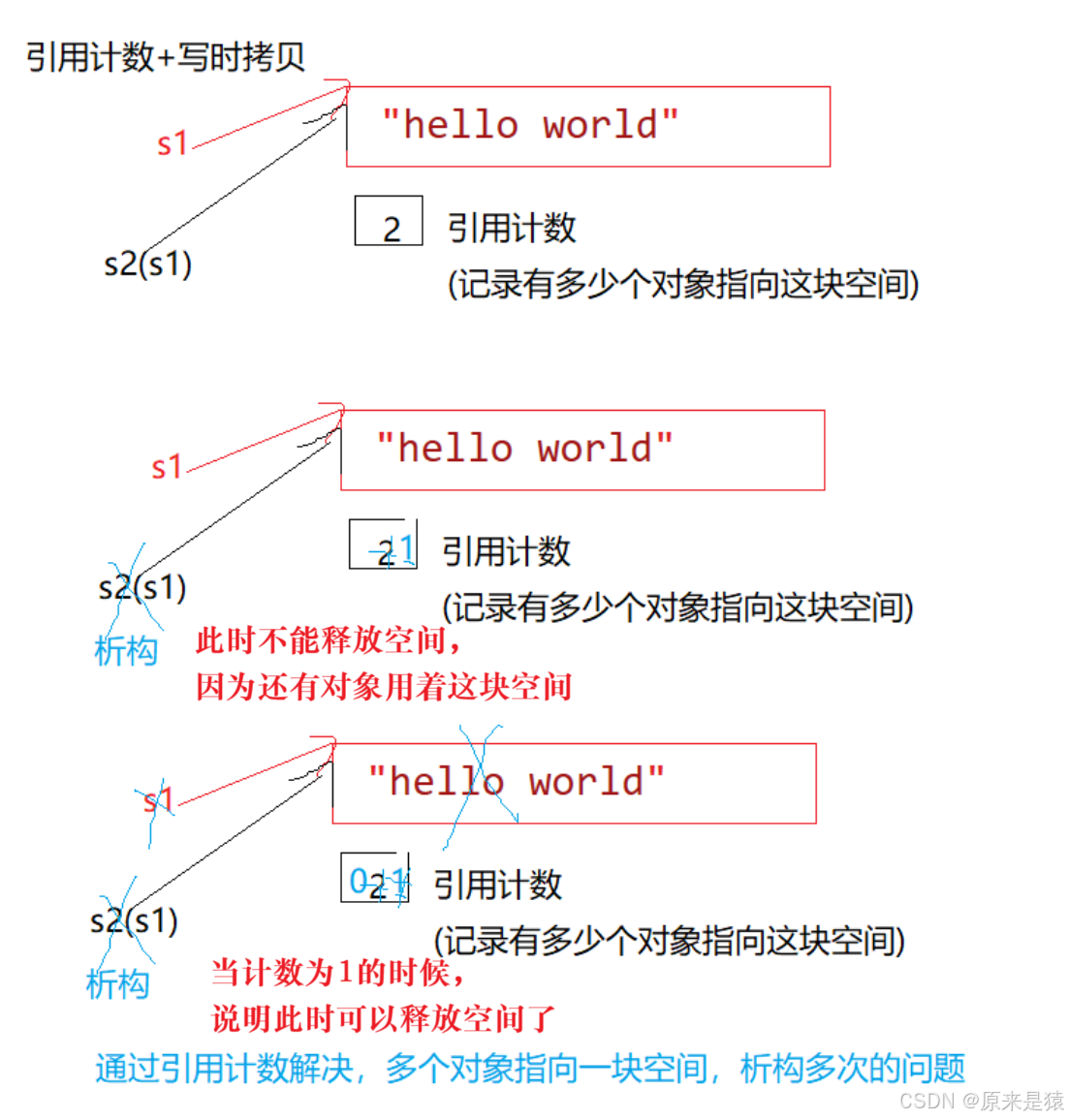
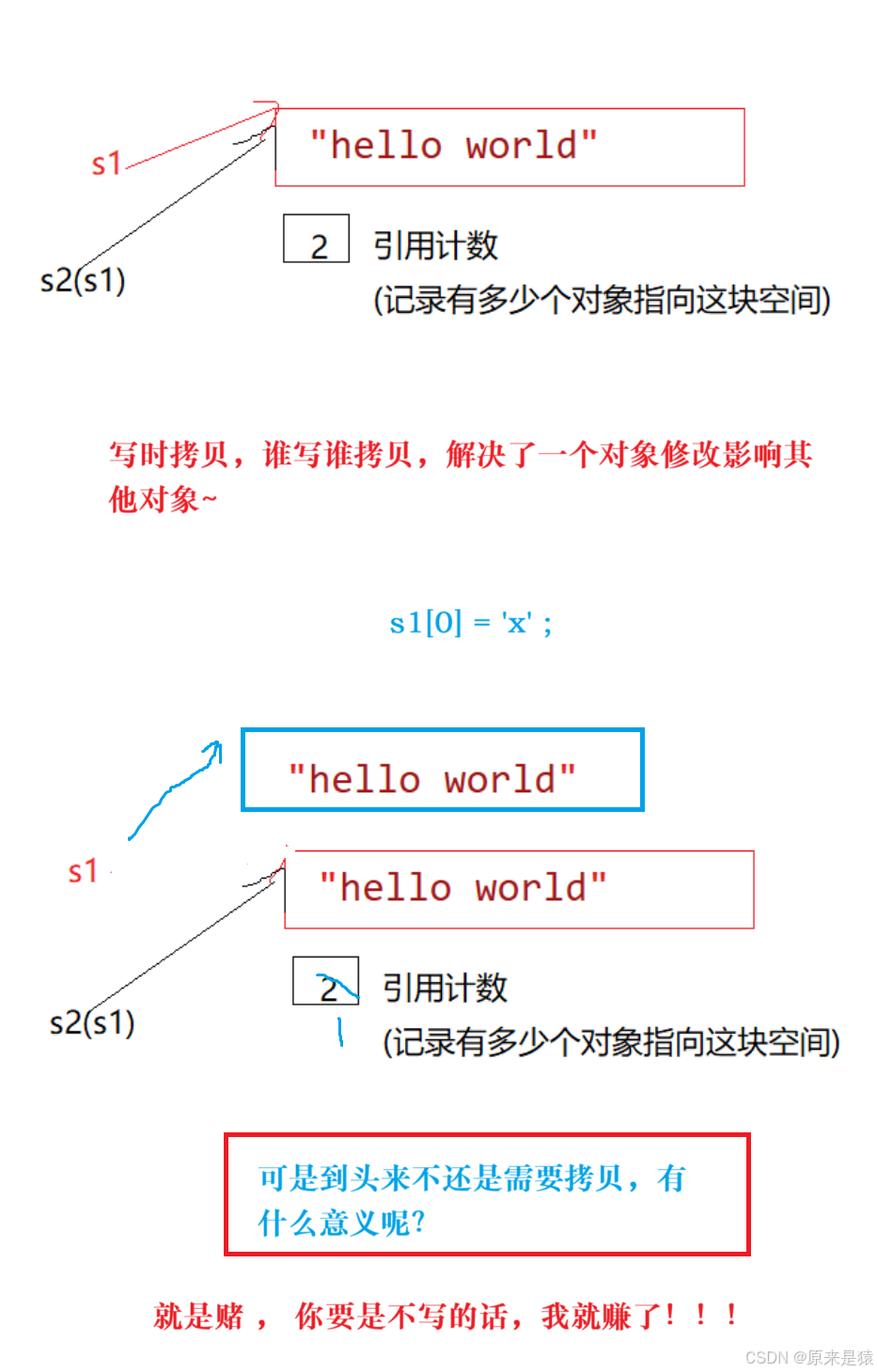
1. 写时拷贝 : 就是一种拖延症 , 是再浅拷贝的基础之上增加了引用计数的方式来实现 。
2. 引用计数 : 用来记录资源使用者的个数 , 在构造时 , 将资源的计数给成1 , 每增加一个对象使用该资源 , 就给计数增加 1 , 当某个对象被销毁时 , 先给该计数减 1 , 然后再检查是否需要释放资源 , 如果计数为 1 , 说明该对象是资源的最后一个使用者 , 将该资源释放 , 否则就不能释放 , 因为还有其他对象在使用该资源 。
其实就是为了解决浅拷贝导致的问题 (析构多次,程序崩溃; 一个对象的修改影响另一个对象)
写时拷贝的优势 : 拷贝后 , 如果不写就赚了 。
四、编码
这里做一个简单的介绍,了解即可;
编码实际上就是把 一些比特位的值 映射成 一些文字符号 。把我们自己的文字,通过一些编码方式 编译成 计算机的机器码 。
4.1 ASCII
ASCII(American Standard Code for Information Interchange,美国信息互换标准代码)是一套基于拉丁字母的字符编码,共收录了 128 个字符,用一个字节就可以存储,它等同于国际标准 ISO/IEC 646。
- 用 1 个字节(8 个 0/1 位) 表示一个字符,但实际只用了前 7 位(因为 8 位能表示 256 种可能,英语根本用不完)。
- 比如:大写字母 A 是
01000001(十进制 65),小写 a 是01100001(十进制 97),数字 0 是00110000(十进制 48)。
void test8()
{char str[] = "abc0ABC";}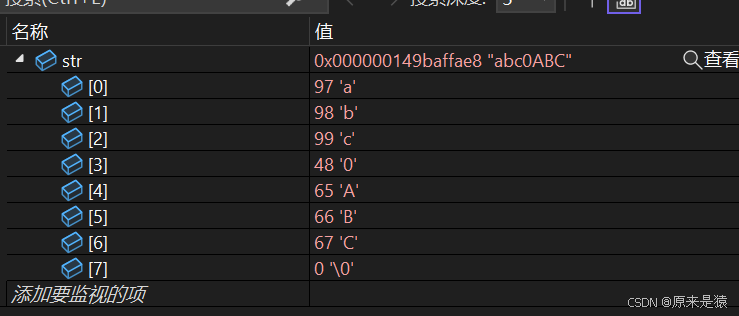
4.2 unicode
统一码(Unicode),也叫万国码、单一码,由统一码联盟开发,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。
统一码是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言,跨平台进行文本转换、处理的要求。
简单说,它是一个 超级大字典,收录了 14 万 + 字符,覆盖全球 150 + 语言,甚至包括 ** extinct languages(已灭绝的语言)** 和 emoji(😀👍)。
-
覆盖一切:
- 语言:中文(简体 + 繁体)、英文、日文、韩文、阿拉伯文、希伯来文、希腊文、俄文……
- 符号:数学符号(∑√π)、货币符号(¥€$)、箭头(→↑)、标点(!?)。
- 表情:😂👍❤️🌍✨(emoji 本质是 Unicode 字符)。
- 特殊文字:盲文、古埃及圣书体、克林贡语(《星际迷航》里的外星语)……
- 甚至有 私人使用区(PUA),你可以自己造字!
-
版本更新:每年新增字符(比如 2023 年加入了 🩷🤌🦖),跟上时代。
-
跨平台兼容:所有现代系统(Windows、macOS、Linux)、编程语言(Python、Java、JavaScript)都默认支持 Unicode。
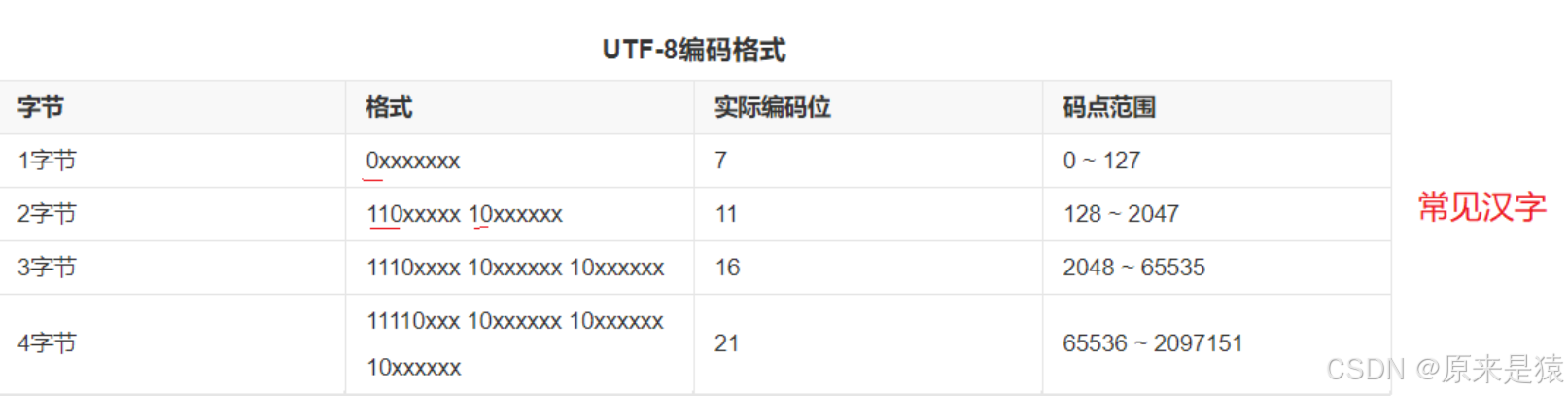
4.3 utf-8
Unicode 给每个字符发了 “身份证”(码点),但直接存身份证号太浪费空间(比如英语字母本来 1 字节够,硬存成 4 字节纯纯浪费)。而utf-8 , 变长编码 , 而且还兼容 ASCII 码 。
核心优点:省空间 + 兼容 ASCII + 无乱码,所以现在几乎所有系统、网页、编程语言都默认用它(比如你现在看的这行字,大概率就是 UTF-8 编码的)。
4.4 常见问题
为什么文本乱码?
可能是文件保存时用了错误的编码(比如用 GBK 存,用 UTF-8 打开)。解决办法:统一用 UTF-8 编码保存和读取。
UTF-8 和 UTF-16 选哪个?
- 文本以英语为主:选 UTF-8(省空间)。
- 文本以中文 / 日文为主:选 UTF-16(省 1/3 空间,但兼容性略差)。
- 编程推荐用 UTF-8(几乎所有工具默认支持)。
BOM 是什么鬼?
UTF-16 文件开头可能有
FF FE或FE FF,用来标记 “大端序” 或 “小端序”(类似告诉电脑 “先读左边还是右边”)。UTF-8 一般不需要 BOM。
4.5 string 的不同编码
在编程中,
string以及后面的u16string(对应char16)、u32string(对应char32)、wstring(对应wchar) 存在 , 主要是为了适应不同的字符编码需求以及处理不同特性的文本 。
void test8()
{char arr1[] = "types";char16_t arr2[] = u"types";char32_t arr3[] = U"types";wchar_t arr4[] = L"types";cout << sizeof(arr1) << endl;cout << sizeof(arr2) << endl;cout << sizeof(arr3) << endl;cout << sizeof(arr4) << endl;char arr5[] = "苹果 apple";cout << sizeof(arr5) << endl;arr5[1]++;arr5[1]++;arr5[1]--;arr5[1]--;arr5[1]--;arr5[1]--;arr5[3]--;arr5[3]--;arr5[3]--;
}