MySQL中的索引和事务
索引
MySQL 的索引是一种数据结构,帮助数据库高效查询。
MySQL中的索引使用的数据结构
对于哈希表来说,存储的键值是无序的。这导致它不支持范围查询,也就无法支持 “大于”、“小于”、“between…and…” 等范围查询操作。
对于二叉搜索树来说,最坏时间复杂度 O (N),树高无法保证,磁盘 IO 次数多。
对于B-树/N叉搜索树来说,一次IO操作,就可以读到一个节点,也就可以拿到N个key进行比较。但仍不够优化。
MySQL中使用的数据结构是B+树
B+树
下图可以看成一棵B+树
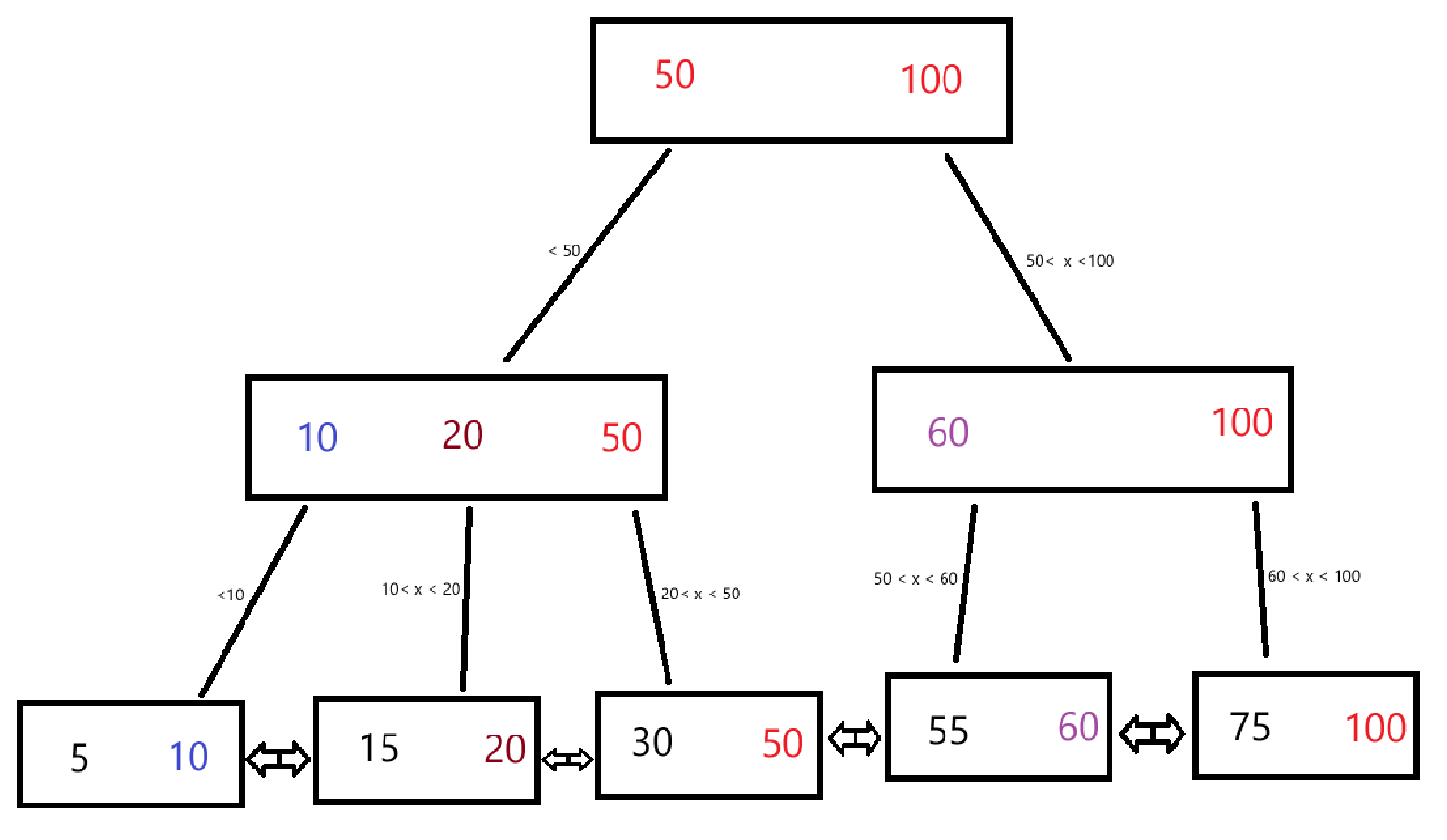
特点:
1、B+树也是一颗N叉搜索树。
2、每个节点上有N个值,划分出了N个区间(对于B-树来说,被划分出了N+1个区间),其中最后一个元素表示当前子树的最大值(或者约定,第一个元素表示当前子树的最小值)。
3、每个叶子节点中,也可以包含N个值,同时把父节点中对应的最大值(最小值)拿过来;最后叶子节点就是一个完整的数据集合
4、叶子节点通过双向链表进行连接
优势:
1、叶子节点是一个完整的数据集合,并用双向链表进行连接,更加进行范围查询
2、所有数据都在叶子上,叶子节点存储完整的数据行,非叶子节点只需要存储索引key值和子节点的位置
3、查询需要查询到叶子节点,从而查询开销稳定,方便进行估算
4、相较于二叉搜索树(红黑树等)来说,树的高度更低,IO次数少
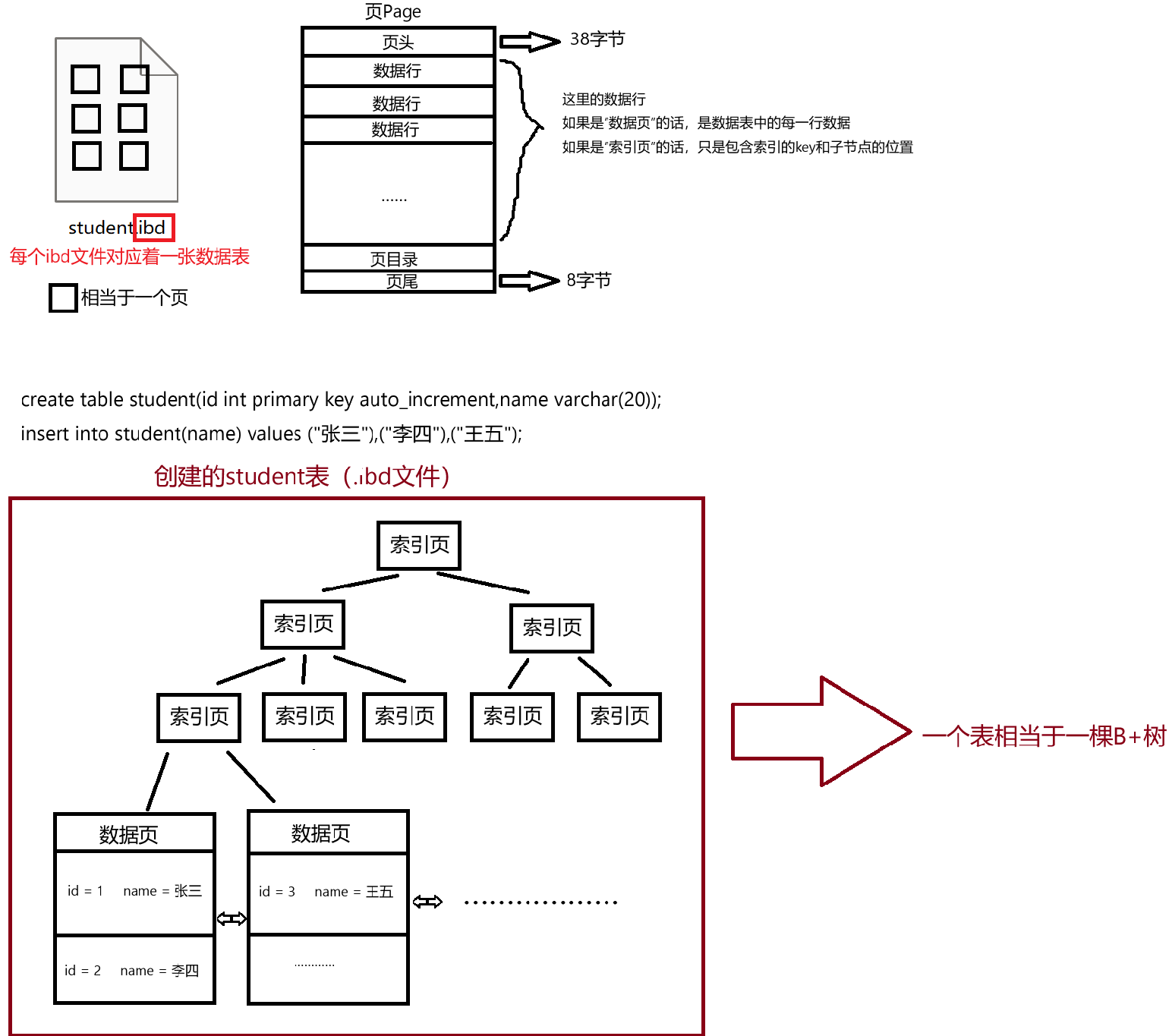
MySQL中的页
在.ibd文件中,Page(页)是内存与磁盘交互的最小单元,默认大小为 16KB(= 16 * 1024B)。可以用SQL语句查看:
show variables like 'innodb_page_size';
数据库中的数据存储到硬盘上的,数据库每次从硬盘中读取数据的时候,都是以页为单位进行读取(因为局部性原理)。“页”就是B+树上的节点。
页包括数据页和索引页。数据页就是叶子节点,存储若干个数据行;索引页就是非叶子节点,只需要存储索引key和子节点的位置(下一个页的位置)。
三层树高的B+树可以存放多少条记录
假设每个数据记录的大小为 1KB,索引键为 BIGINT 类型(8 字节),指针大小为 6 字节(也就是单个索引页的大小为14KB)。
单个中间节点页能指向的子节点数:16 × 1024KB ÷ 14KB ≈ 1170;
根节点(第一层)最多能指向 1170 个中间节点(第二层)。
每个中间节点(第二层)最多能指向 1170 个叶子节点(第三层)。
每个叶子节点页可存储的数据记录数为 16KB ÷1 KB = 16 条。
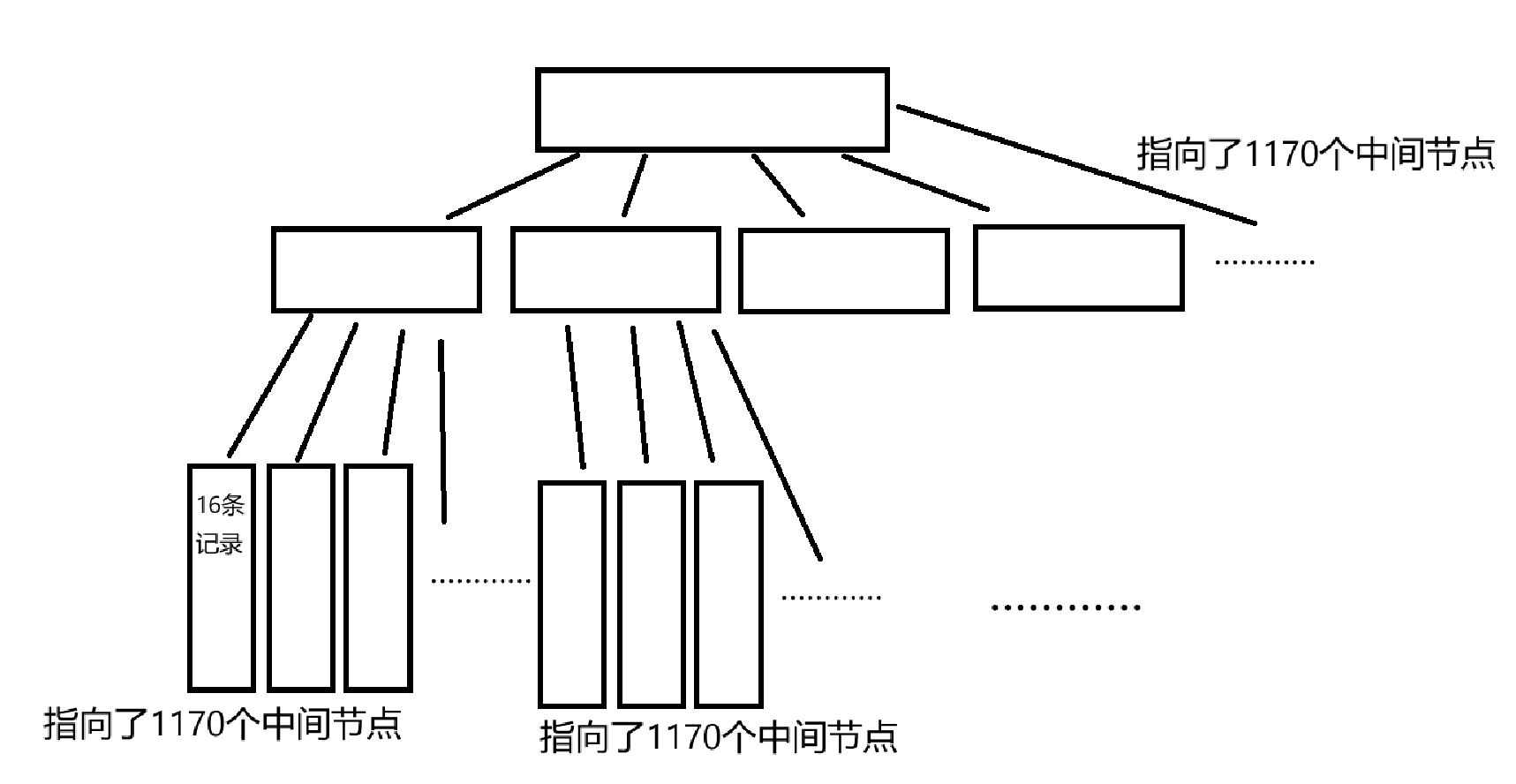
综上所述三层树高的B+树可以存放 1170 × 1170 × 16 = 21,902,400 条记录。
索引的种类
1、聚簇索引
像下图就属于聚簇索引
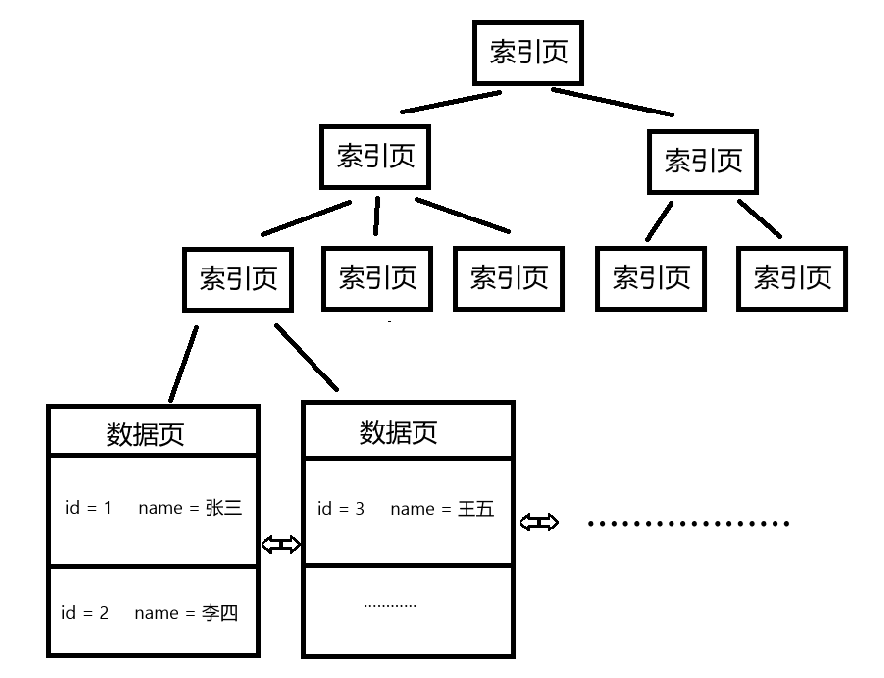
叶子节点保存了所有的数据行
2、主键索引
当创建主键的时候,数据库会自动建立索引。
当表中没有主键,数据库会自动创建“隐藏列”,作为主键,围绕隐藏列设定索引。
在InnoDB存储引擎中,主键索引就是聚簇索引。
3、非聚簇索引
对于之前的student表,针对name创建B+树索引,此时叶子节点不在保存数据行了,避免浪费空间。只需要将叶子节点指向对应聚簇索引的数据行。
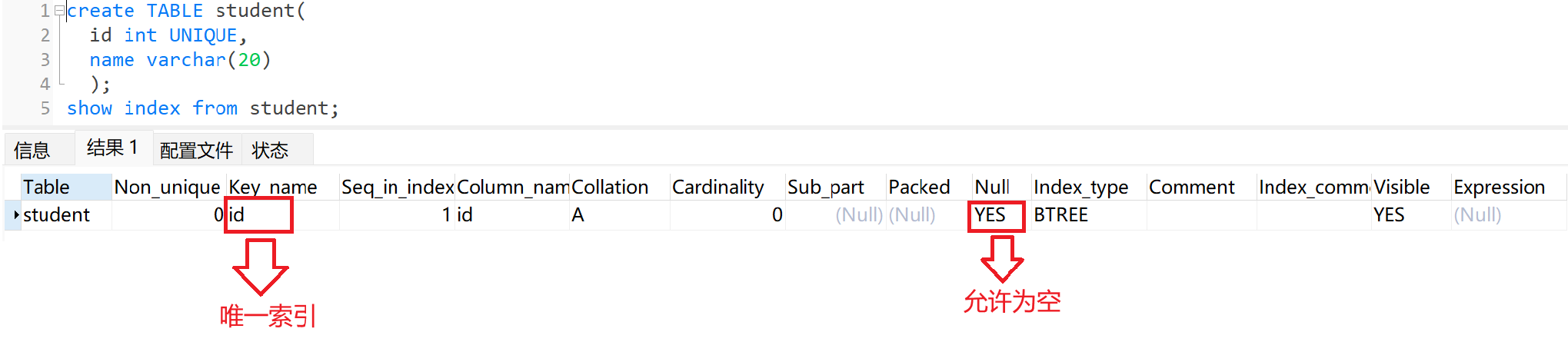
4、唯一索引
当列是唯一约束时,自动创建唯一索引
5、全文索引
针对字符串类型(char、varchar、text)的列进行的创建
6、普通索引
需要手动创建索引
create index 索引名 on 表名(列名……);
create table student(id int primary key auto_increment,name varchar(20),classId int
);create index index_classId on student(classId);
create table student2(id int primary key auto_increment,name varchar(20),classId int
);create index index_name on student(name,classId);
需要注意的是当在一张大表上创建索引就会很多问题,属于危险操作。
索引的删除和查看
查看
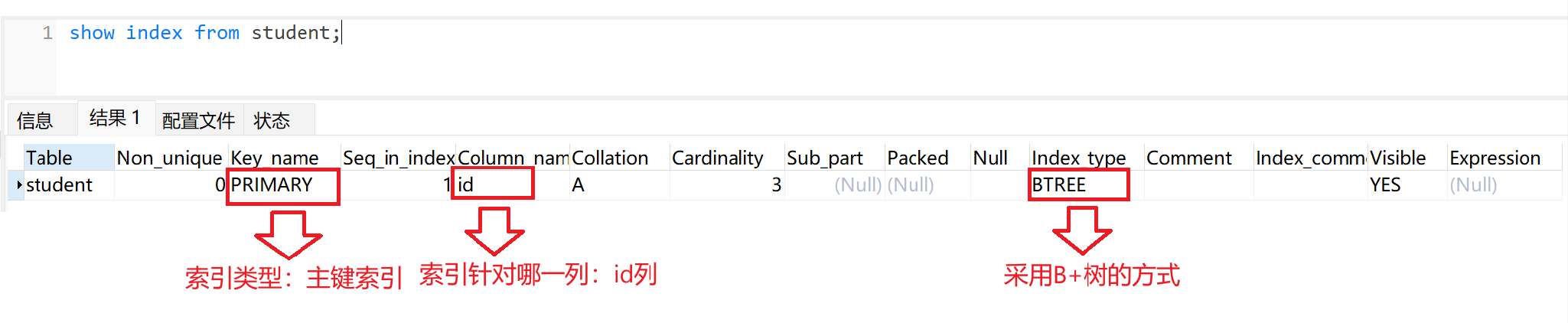
show index from 表名;
主键索引:
唯一索引:
外键索引:
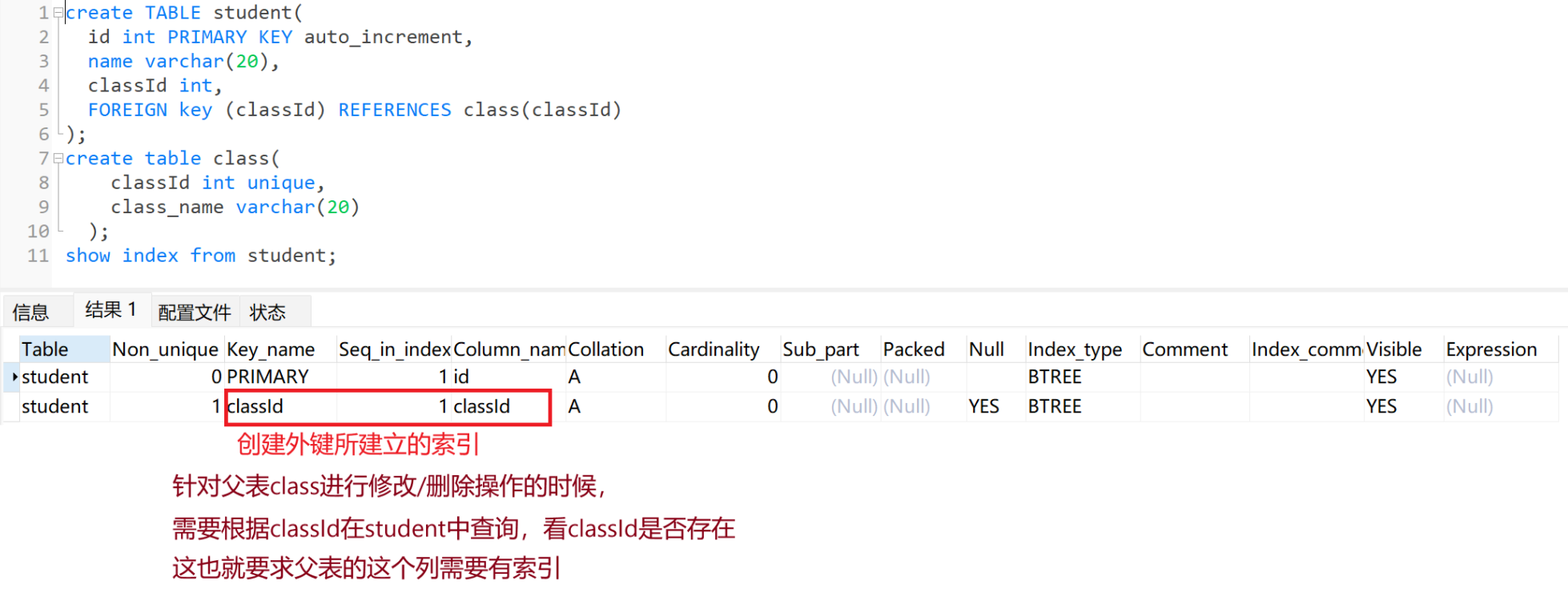
删除
#删除主键
alter table 表名 drop primary key;
#删除普通索引
alter table 表名 drop index 索引名;
事务
事务是一组不可分割的 SQL 操作序列,这些操作要么全部成功执行,要么全部失败回滚。
例如:在购物系统中,有商品表和订单表。当产生新的订单,商品表中的库存状态就会发生变化,这是一组不可分割的操作。银行转账同样如此。
事务的四大特性(ACID)(重要)
原子性
由于是一组不可分割的SQL,已经是最小单位了,不可再细分。要么整个SQL语句都执行,要么都不执行。对于“都不执行”的意思是通过回滚的机制实现,还原成最初的状态了。
回滚
用于撤销事务中已经执行的部分或全部操作,确保数据恢复到事务开始前的状态。
事务的SQL语法
#创建账户表
create table account(id int PRIMARY KEY auto_increment,name varchar(20),balance int
);
insert into account values (null,"张三",1000),(null,"李四",2000),(null,"王五",3000);
SELECT*from account;
#开启事务
start transaction;#或者使用 begin;#执行事务的语句
update account set balance = balance - 200 where name = "张三";
update account set balance = balance + 200 where name = "李四";
select * from account;#第一次查询# 提交当前事务,并对更改持久化保存
commit;
select * from account;#第二次查询
此时两次查询都是
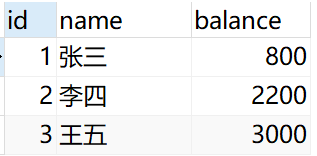
说明对数据进行了持久化保存。
进行回滚操作会有不一样的地方吗?
#开启事务
start transaction;#执行事务的语句
update account set balance = balance - 200 where name = "张三";
update account set balance = balance + 200 where name = "李四";
select * from account;#第一次查询#回滚
rollback
select * from account;#第二次查询
第一次查询的结果为:
第二次查询的结果为:
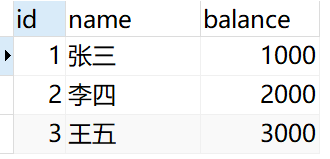
在开启事务的时候,数据库会使用专门的日志,记录事务的执行过程。像上述事务在硬盘中修改了两条数据,同时在日志中也记录了这两个动作。在rollback的时候会还原这操作使其变成原来的数据。无论是commit还是rollback,在执行完毕后刚才产生的日志也将会被删除。
还可以在回滚到指定位置:
start transaction;update account set balance = balance - 200 where name = "张三";
savepoint savepoint1;
update account set balance = balance + 100 where name = "李四";
savepoint savepoint2;
update account set balance = balance + 100 where name = "王五";
SELECT*from account;#第一次查询rollback to savepoint2;
SELECT*from account;#第二次查询
rollback to savepoint1;
SELECT*from account;#第三次查询
rollback;
SELECT*from account;#第四次查询

自动/手动提交事务
在默认情况下,MySQL是自动提交事务的。当我们执行的每个修改操作都会自动开启一个事务并在语句执行完成之后自动提交,发生异常时自动回滚。
查看是否自动提交:
show variables like 'autocommit';
设置是否自动提交:
#自动提交事务
set autocommit = 1;
set autocommit = ON; #手动提交事务
set autocommit = 0;
set autocommit = OFF;
一致性
一个事务的执行前后,数据得合理有效。
例如:在转账过程中,要有加有减,不能只有钱进账户或只有钱出账户。
回滚机制也保护了事务的一致性。
隔离性(重点)
当多个客户端提交多个事务的时候,数据库服务器就要“并发”的处理这些事务。当处理并发操作来说,容易出现一些问题,造成准确性下降等。但当完全分开处理事务的时候会造成效率降低。
提升并发性 => 提升数据库处理事务的效率 => 但也会导致数据的准确性下降
降低并发性 => 数据的准确性提高 => 但也会导致降低数据库处理事务的效率
对于事务不同的隔离进行了划分,不同的隔离级别有着不同的侧重点。
我们需要根据具体情况来采用合适的隔离级别。
MySQL中有四种隔离级别:
READ UNCOMMITTED,读未提交
READ COMMITTED,读已提交
REPEATABLE READ,可重复读(数据库默认这个隔离级别)
SERIALIZABLE,串行化
隔离性由上到下越来越强。READ UNCOMMITTED隔离性最弱,SERIALIZABLE隔离性最强。
查看数据库隔离级别
# 全局作用域
SELECT @@GLOBAL.transaction_isolation;
# 会话作用域
SELECT @@SESSION.transaction_isolation;
设置数据库隔离级别
#方法一
SET GLOBAL TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ
#方法二
SET GLOBAL transaction_isolation = 'SERIALIZABLE';
# 注意使用SET语法时有空格要用"-"代替
SET GLOBAL transaction_isolation = 'REPEATABLE-READ';
#方法三
SET @@GLOBAL.transaction_isolation ='SERIALIZABLE';
# 注意使用SET语法时有空格要用"-"代替
SET @@GLOBAL.transaction_isolation ='REPEATABLE-READ';
数据不准确的情况以及如何解决
1)数据脏读
使用READ UNCOMMITTED隔离级别导致数据脏读

使用READ COMMITTED隔离级别来解决脏读的问题
READ COMMITTED隔离级别要求读取同一个数据的时候,只能读到commit之后的数据。
但也出现了新的问题:不可重复读
2)不可重复读

使用REPEATABLE READ隔离级别来解决不可重复读的问题,此时张三的账户余额都是900
但也出现了新的问题:幻读
3)幻读

使用SERIALIZABLE隔离级别来解决幻读的问题,每个事务都分开执行。当然这会导致效率降低,但准确性得到提升。

持久性
一旦事务提交,其结果将永久保存在数据库中。数据保存在硬盘上,重启服务器/数据库都不会导致数据消失。