【论文阅读】Masked Autoencoders Are Effective Tokenizers for Diffusion Models
introduce
什么样的 latent 空间更适合用于扩散模型?作者发现:相比传统的 VAE,结构良好、判别性强的 latent 空间才是 diffusion 成功的关键。
研究动机:什么才是“好的 latent 表征”?
背景:
- Diffusion Models最初在像素空间操作,但效率低;
- 后续工作(如 Latent Diffusion Models)引入tokenizer,将图像压缩成 latent token,再在 latent 空间进行生成,提高效率;
- VAE 是常见的 tokenizer,要求 latent 遵循高斯分布(通过 KL regularization)。
问题:
- VAE 的 KL 限制损害了图像重建质量;
- 普通 AE 虽然重建质量高,但 latent 表征结构性较差,对扩散模型训练不友好;
那么问题来了:什么样的 latent 才最适合用于 diffusion?VAE 真有必要吗?
关键发现:结构良好的 latent space 才是关键,而非 VAE 的正则。拥有更少 GMM 模式(即更清晰结构、更聚类)的 latent 表征 → 扩散模型训练损失更小 → 生成效果更好
具体来说:
- 给不同类型的 tokenizer(AE / VAE / 表征对齐 VAE / MAETok)提取 latent;
- 拟合 Gaussian Mixture Model(GMM),观察模式数量(mode 数);
- 对应的扩散模型的训练损失越小、生成越好,说明 latent 更利于建模。
结论: 判别性强、结构清晰(mode 少)的 latent 比“高斯先验 + 正则”更有价值
核心方法:MAETok——用 Masked AE 做 tokenizer
总体设计: 用 MAE(Masked AutoEncoder)训练 AE,而非 VAE,使其 latent: 语义丰富、 判别性强(discriminative)、可恢复像素。
Encoder:
- transformer-based encoder;
- 随机 mask 掉输入 patch(如 50%),强迫模型从部分观察中学习全局语义;
- 得到的 latent 表征具有更高判别能力和更强结构性(类似 DINO、SimCLR)。
Decoder:
- 两个 decoder:
- Pixel decoder:恢复输入图像;
- Auxiliary decoder:恢复 DINOv2 / HOG / CLIP 特征等;
- 这两个目标并行训练,增强表征语义的泛化能力;
- 在推理时只保留 pixel decoder,几乎不增加开销。
解耦机制:
- 训练阶段:高 mask ratio(如 60%)让 encoder 学语义;
- 微调阶段:freeze encoder,fine-tune decoder,让它学会精确恢复像素;
避免语义学习与像素精度之间的冲突。
为什么判别性强、mode 少的 latent 更适合 diffusion?
从 diffusion loss 的角度推导:
- 扩散模型学习的是如何逐步去噪 latent 表征;
- 若 latent 本身是聚合性好的结构(mode 少、类内差小),就更容易建模。
- 理论上证明: GMM mode 越少 → 模型预测误差(loss)越小 → 更好的 sample quality

On the Latent Space and Diffusion Models
Empirical Analysis
目标: 探索不同 tokenizer(AE、VAE、VAVAE)生成的 latent space 结构复杂度,以及这种结构如何影响 diffusion 模型的训练和生成质量。

实验设置:
- 用同样结构和训练配置分别训练 AE、VAE、VAVAE,
- 把它们当作 tokenizer,对 ImageNet 图像进行编码得到 latent;
- 用 latent 训练 DDPM 扩散模型;
- 用 GMM(高斯混合模型) 来衡量 latent 空间的复杂度:
- 模式数(mode K)越多 → 表示 latent 越复杂、结构越混乱;
- 模式数(mode K)越少 → latent 越聚合、语义更清晰,越利于建模;
图2a:GMM 拟合对比(负对数似然 NLL) ,对 AE、VAE、VAVAE 的 latent 分别进行 GMM 拟合。比较不同模式数量下的 负对数似然(NLL),即拟合误差。发现:
| 模型 | 所需 mode 数 | 拟合误差(NLL) |
|---|---|---|
| AE | 多 | 高 |
| VAE | 中 | 中 |
| VAVAE | 少 | 低 |
进一步用这些 latent 分别训练扩散模型,发现扩散模型训练 loss 与 GMM mode 数量 几乎对应:
- 模式越多 → 扩散学习更难 → loss 更高;
- 模式越少 → latent 更有语义结构 → 学习更轻松,loss 更小。
实验验证:模式少的 latent 空间能显著降低扩散模型训练难度,提高生成质量
Theoretical Analysis
目标: 从理论上解释为何“mode 少” → “训练更容易”,即模式数越多,训练样本复杂度越高。
理论设定:假设 latent 空间分布为 K 个等权高斯的混合(GMM):

扩散模型训练目标采用 score matching loss:

Theorem 2.1
为了让生成分布接近真实分布(KL误差小于 O(Tε²)),所需样本数量满足:

K = 模式数(mode 数); d = latent 维度; B = 均值向量范数的上界(大致相同); ε = 目标误差精度。
模式数越多(K ↑),样本复杂度呈 K⁴ 增长。
说明: mode 越多,越难建模,需要越多训练样本才能达到同样生成质量。在训练样本有限的现实中,mode 少(如 VAVAE / MAETok)的 latent 更利于 diffusion 学习。
Method
那么核心问题: 如何训练一个结构性更好、语义更丰富的 latent 空间,让扩散模型更高效、更强大?
答案是:通过带 Mask 的 AE(MAETok)结构 + 多目标训练 + 解耦优化 策略,构造少mode、可判别的 latent,从而提升扩散模型学习效率与生成质量。
Architecture

如图,架构组件:
1. 编码器(Encoder)

2. 解码器(Decoder)

3. 位置编码策略(RoPE)
- 对于 image patch tokens 使用 2D Rotary Position Embedding(RoPE) 保留图像结构;
- 对于 latent tokens 使用 1D 绝对位置编码,表示抽象语义;
Mask Modeling
MAETok 结构的关键设计之一:
- 对图像 patch token 施加 40%~60% 的随机掩码;
- 将被 mask 的 patch 替换为 learnable mask token;
- 让 latent tokens 学会从剩余部分恢复被遮挡部分信息 → 增强其判别能力;
- 同时,mask 的 patch 特征通过 shallow decoder 去恢复多种语义目标;
高 mask 比例训练迫使 encoder 抓住图像的全局、稳定特征,从而提升 latent 表征的“结构性”。
Auxiliary Shallow Decoders
多目标特征预测:进一步强化 latent 语义。
- 使用多个浅层解码器 D,预测如: HOG(边缘特征); DINOv2; CLIP; 文本 token(如 BPE index)等;

- 每个浅层解码器结构与主 pixel decoder 类似,但层数更少;
- 训练 loss:只在被 mask 的位置上监督,强化 latent token 对多种语义结构的恢复能力

Pixel Decoder Fine-Tuning
解码器解耦微调。由于 mask 训练主要优化 encoder,可能损失了重建精度,因此:
- 最后阶段冻结 encoder;
- 微调 pixel decoder 若干轮,仅优化重建质量;
- 不再使用 mask 或辅助解码器。loss 采用标准组合:

这一步让 encoder 保持判别性结构,同时恢复 decoder 的高保真图像输出能力。
Experiments
Setup
Tokenizer 训练设置
- 基于 XQ-GAN 框架训练;
- 编码器和主 pixel 解码器均为 ViT-Base(176M 参数);
- 设置 latent token 数量 L=128,维度 H=32;
- 三种数据集/尺寸设置: ImageNet-256 ImageNet-512 LAION-COCO-512 子集(预测图文 BPE token)
多目标重建:
- mask 比例 40~60%;
- 三个浅层解码器用于 HOG、DINO-v2、SigCLIP; LAION 加一个 BPE 文本目标;
- decoder 深度 = 3(通过消融得出);
- 损失系数:λ₁ = 1.0,λ₂ = 0.4;
- pixel 解码器微调阶段:mask 从 60% 线性下降到 0%。
Diffusion 模型训练设置:
- 用 SiT(Simple Tokenizer) 与 LightningDiT;
- patch size=1,1D Positional Embedding;
- SiT-L(458M)用于消融,SiT-XL(675M)训练 4M 步;
- LightningDiT 训练 400K 步;
- 分辨率:256×256 与 512×512;
评估指标:
- Tokenizer 评估:
- 重建质量:rFID、PSNR、SSIM
- 语义评估:Linear Probing Accuracy(LP)
- 生成评估:
- gFID(生成 FID)、IS(Inception Score)
- Precision/Recall(附录中)
- CFG 与否两种条件下(classifier-free guidance)
Design Choices of MAETok
- Mask Modeling AE 中加入 mask modeling:
- gFID 明显下降(→更好生成);
- rFID 稍升(重建质量下降),可通过 decoder 微调恢复;
- VAE 加 mask 效果小,因为 KL 抑制了 latent 学习。
结论:mask modeling 是提高 AE 表征能力、简化扩散学习的关键。
| 重建目标 | 特点 | 效果 |
|---|---|---|
| 原始像素 + HOG | 低级视觉特征 | 可学好 latent,但提升有限 |
| DINO-v2, CLIP | 语义特征 | gFID 显著下降(→更好生成) |
| 组合使用 | 同时兼顾结构和语义 | 最佳 trade-off |
结论:语义教师(CLIP/DINO)能教 AE 学习出更判别的 latent。
Mask 比例(Mask Ratio)
- 太低 → latent 太“忠实”,不判别;
- 太高 → 重建能力差;
- 40%~60% 是最优折中(参考 MAE 系列);
Auxiliary Decoder 深度
- 太浅 → 无法处理高低语义混合目标;
- 太深 → 容易记忆任务,反而不学好的 latent;
- 最优为:中等深度(3 层),效果最佳。
Latent Space Analysis
Latent 可视化(UMAP)
- AE / VAE 的 latent 分布混叠严重(类间重叠);
- MAETok latent 分布:类间分明,聚类清晰 → 判别性强;
图 4(UMAP 图)直观支持这个发现。

LP Accuracy 与 gFID 的相关性(图 5a)
- LP Acc 越高(latent 更判别)→ gFID 越低(生成越好);
- 提示 latent 表征与生成性能紧密相关。
收敛速度(图 5b)
- MAETok latent 训练更快;
- SiT-L 在使用 MAETok latent 时,gFID 下降更迅速、值更低。

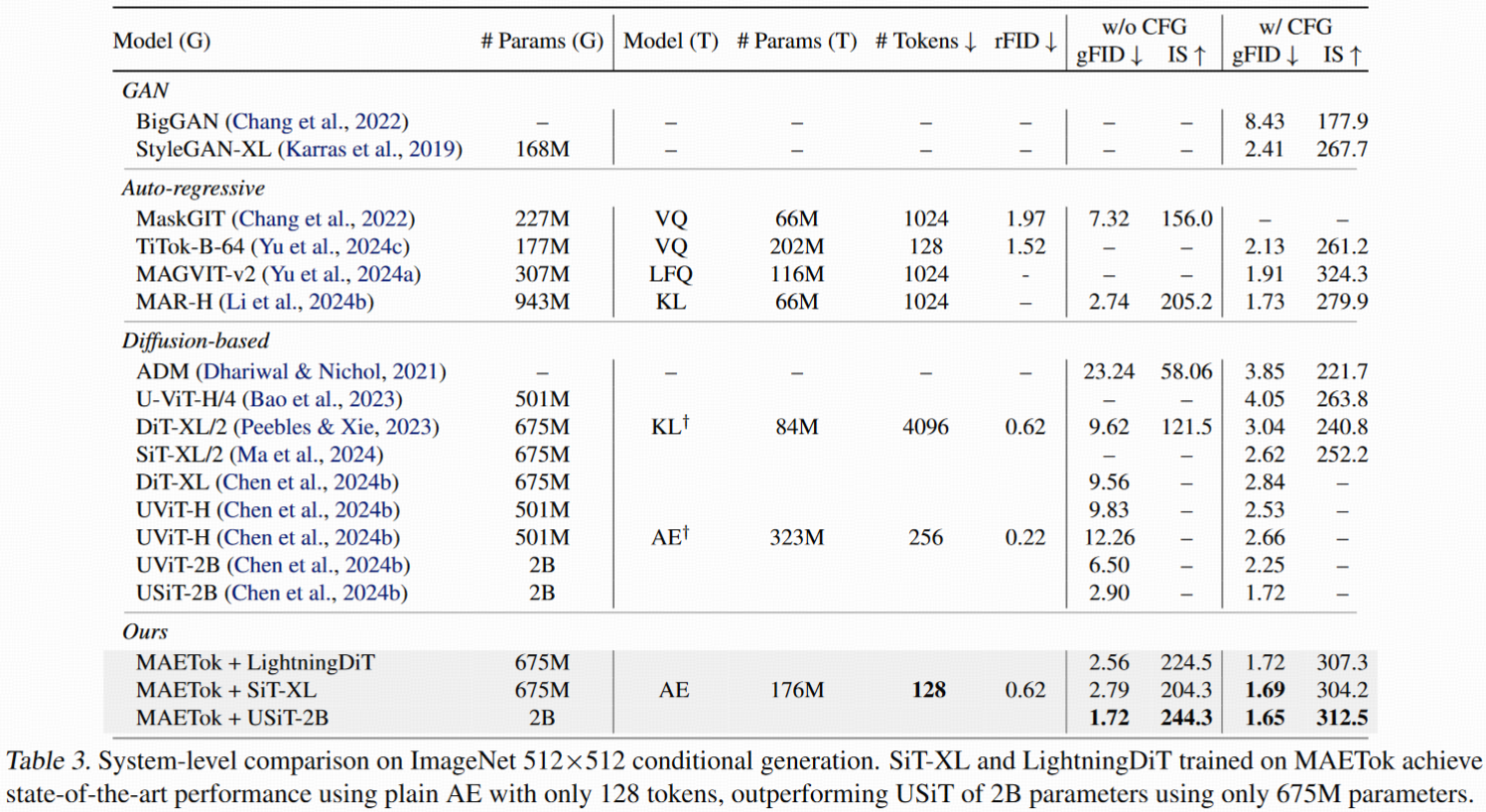
生成任务对比(表 2/3)
- MAETok + SiT-XL(128 tokens)不使用 CFG,gFID=2.79(512),击败 REPA;
- 使用 CFG 后:超越 2B USiT 模型,达到 SOTA: gFID = 1.69(SiT) gFID = 1.65(LightningDiT)
- 使用更强 CFG(如 Autoguidance): gFID 进一步降到 1.54 或 1.51
结论:结构化 latent > 更大模型/更多 token。

重建能力(表 4)
- 256 分辨率,仅用 128 token,rFID=0.48,SSIM=0.763;
- 超越 SoftVQ 和 TexTok(后者 token 数翻倍);
- MS-COCO 上未训练,仍具泛化能力;
- 在 512 resolution 下依旧保持优势。

| 模型 | Token 数 | GFlops | 推理速度(A100) |
|---|---|---|---|
| 原始 SiT-XL | 1024 | 373.3 | 0.1 img/sec |
| MAETok | 128 | 48.5 | 3.12 img/sec |


Theoretical Analysis
- Step 1:从 latent 的 GMM 模式数 K 推导训练误差上限
- Step 2:从训练误差推导采样误差(KL/采样分布和真实分布差异)
核心目标是推导:
- 生成误差 ∝ 模式数 K⁴ → 模式多训练难度大
- MAETok 的 latent 空间更“判别”(K 少),所以训练快、生成质量高
Preliminaries
输入数据建模为 GMM 分布: latent 空间数据是一个等权重、单位协方差的高斯混合模型

DDPM 的目标函数(Score Matching):
在 GMM 下的解析 score:

即 GMM 分布的 score 函数是“softmax 加权的类中心差值”。
模拟网络预测的 score: 训练模型 sθ(x) 采用相同结构假设:


推论 A.4:数据二阶矩上界为:![]()
Step 1:从模式数到训练误差(估计 score 的误差)
Theorem A.5:DDPM 的收敛误差界

结论:K 越大 → 所需样本数量越多 → 难训练
推导 Score Estimation Error :用真实 score 和模型输出之间的距离展开:


Step 2:从训练误差到采样误差(生成质量)
Theorem A.6(Early Stopping)

最终结论 Theorem A.7:完整误差界
训练 DDPM 时:

- 结论 1:模式数 K↑ → 样本数 n↑↑↑ → 难训练
- 结论 2:KL 越小 → 分布越相似 → FID 越低(在高斯假设下)
| 推理链条 | 对 MAETok 的意义 |
|---|---|
| 高模式数 K → 训练样本要求高 | AE latent 太 entangled → 训练慢 |
| 判别性强 latent(K 小) → 更快收敛 | MAETok 显著加快 gFID 下降(图5b) |
| 分布判别性高 → gFID 更低 | LP Acc ↑ → gFID ↓(图5a) |
| Score loss 越小 → KL 越小 → FID 越低 | MAETok 结构性 latent 直接提升生成质量 |
Experiments Setup
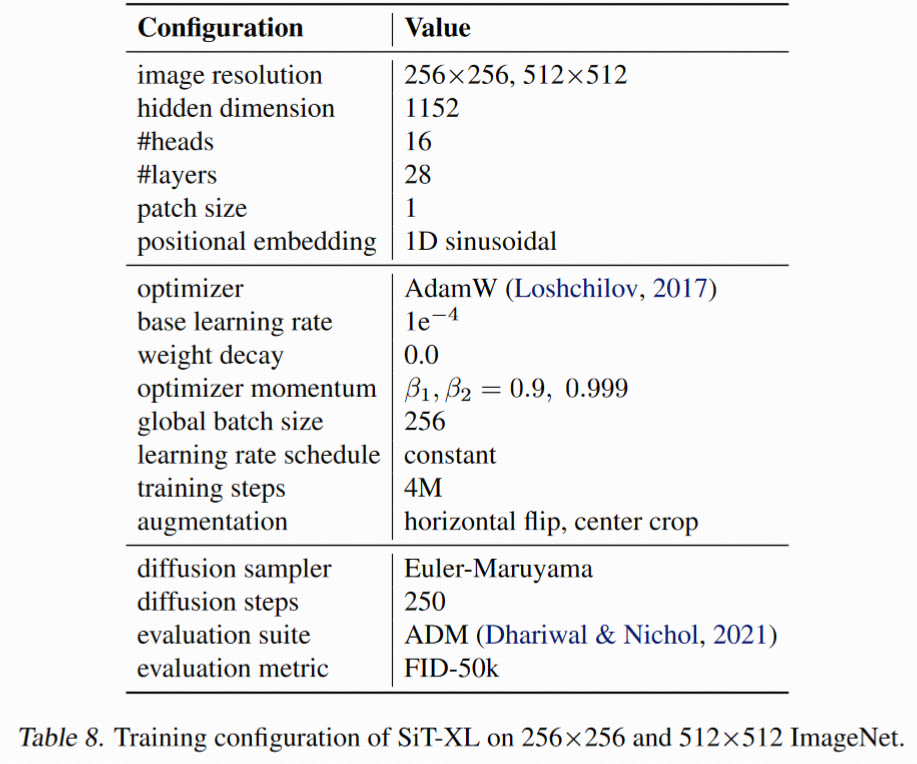
B.1. Training Details of AEs(自编码器训练细节)
MAETok 和其他 AE 对比模型(如 AE、KL-VAE、VAVAE)在完全相同的设置下训练
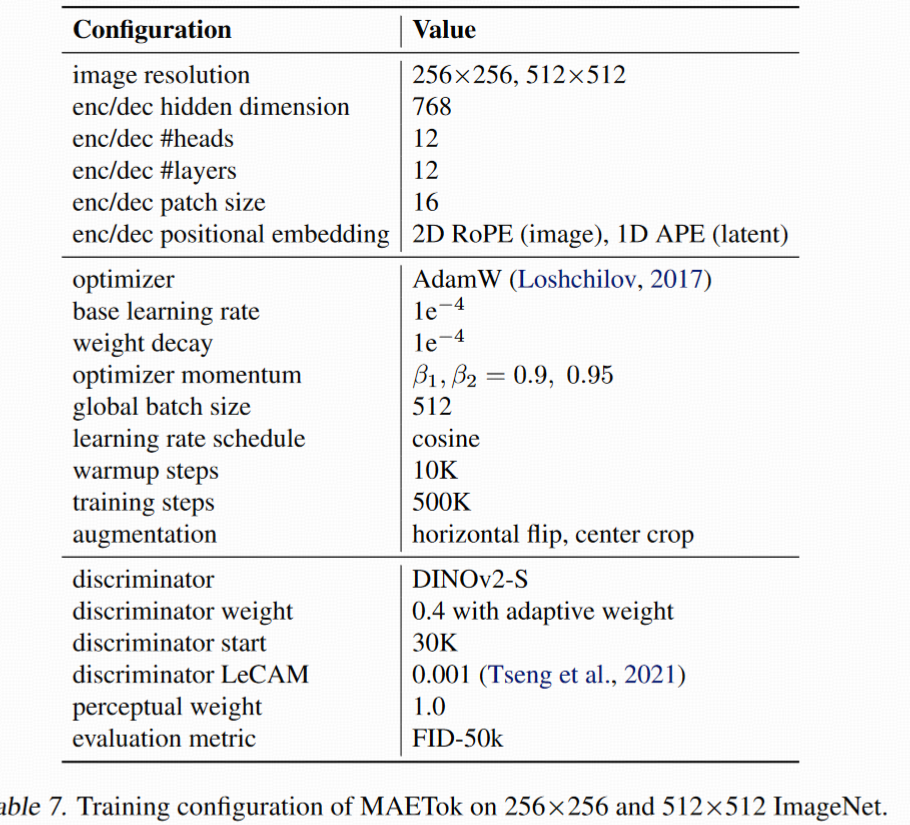
B.2. Training Details of Diffusion Models(扩散模型训练细节)
用两个 backbone:
- SiT-XL(强表征能力)
- LightningDiT(轻量加速)
训练设置遵循各自原始论文的配置,见 Tables 8、9;
与 AE 模块解耦,主要对比 latent 空间设计对扩散模型训练效果的影响。

B.3. Training Details of GMM Models(高斯混合建模的细节)
对应于 Fig. 2a 中对 latent 分布的可分性度量:

实验流程:
- Flatten Latents :把原始 AE 输出的 latent 表示 (N,H,C) reshape 为 (N,H×C)
- Dimensionality Reduction(PCA降维) :降维到维度 K,保留>90%方差,保证所有模型输出 latent 都变为统一维度 (N,K) ,避免“维度诅咒”
- Normalization(标准化):保证不同模型输出分布一致,避免尺度差异
- GMM Fitting + NLL 评估:拟合 GMM,输出 NLL loss 衡量 latent 空间是否“结构清晰”(mode 少/可分性强)
训练配置:
- 所有模型在 ImageNet 全量数据上训练
- GMM 模型数量:50、100、200,对应训练时间约为 3/8/11 小时
- 使用单卡 NVIDIA A8000(分布式训练可提速)
Experiments Results
C.1. More Quantitative Generation Results
在 256×256 和 512×512 分辨率上提供了 Precision / Recall 的补充评估(Table 10, 11);
与 gFID 等指标互补,更全面评估生成质量与多样性。
C.2. Classifier-free Guidance Tuning Results(CFG 调参结果)
CFG 是无条件扩散模型的关键组件,但:
- 即使是微小的 CFG scale 变化,gFID 也会明显变化;
- 即使用 “CFG Interval” 技术(如 [0, 0.75])跳过高步数时间段,也很难稳定控制;
- 根本原因在于 unconditional class 的语义空间不稳定
实际使用的 CFG 设置:
| 分辨率 | 模型 | CFG Scale | Interval |
|---|---|---|---|
| 256×256 | SiT-XL | 1.9 | [0, 0.75] |
| 256×256 | LightningDiT | 1.8 | [0, 0.75] |
| 512×512 | SiT-XL | 1.5 | [0, 0.7] |
| 512×512 | LightningDiT | 1.6 | [0, 0.65] |
结论与未来方向:
- 当前线性 CFG 无法有效控制 MAETok 的强语义 latent;
- 可尝试采用更高级的 CFG 设计
C.3. Latent Space Visualization(可视化结果)
图 9 展示了 MAETok 及其变体在不同重建目标下的 latent 分布,显示出明显的 分布清晰、聚类可分、mode 少 的特点; 理论分析中的 GMM 模型假设与实验中图像结果高度一致。

C.4. More Ablation Results
见 Table 13,主要关注两个因素:
| Token Type | 效果 |
|---|---|
| 图像 patch tokens | 表现普通 |
| 可学习 latent tokens | 效果显著更好 |
结论:使用 learnable latent token 更高效,128 个就能达成与 256 个相当效果
2. 2D RoPE(二维相对位置编码):
- 帮助模型在 混合分辨率训练场景中泛化更好;
- 对比无位置编码或1D编码的模型有更强的空间建模能力。
| 模块 | 要点 | 启发 |
|---|---|---|
| AE 训练 | 使用统一设置进行公平比较 | 可复现、可对比 |
| GMM 分析 | PCA 降维+标准化+NLL度量 | 量化 latent 可分性(mode 越少越好) |
| CFG 调参 | 变化剧烈,调优困难 | MAETok latent 空间语义稳定但不适于线性 CFG |
| 可视化 | 显示 clear clustering | 理论假设与实际分布一致 |
| Ablation | 128 latent token+2D RoPE 最优 | 更高效、分辨率稳健泛化 |
问题
K(模式数)和样本量(components)指什么?
作者用 GMM(Gaussian Mixture Model) 去拟合 autoencoder 的 latent space:
- 每一个 mode K,就是一个高斯分布中心(Gaussian Component),代表 latent 中聚集的一群数据。
- K 越大,说明 latent 空间越“离散化、碎片化”,分布不集中。
- GMM 会估计出每个分布的均值 μ 和权重 w,用于刻画 latent 的整体形状。
核心直觉:一个“好”的 latent 空间,应该是几个“集中的簇”,而不是碎片化、重叠、高维扩散。
分析得出: 为了学习一个含 K 个模式的 GMM,score-based 模型训练所需的样本量为:![]()
这意味着:K 越大 → 模型越难训练、样本需求呈指数增长。
为什么要最小化score matching loss ?
DDPM 训练函数:

目标:让模型输出的去噪方向尽量接近真实的概率梯度方向,从而逐步反扩散、重建图像。