基于RAG实现下一代的企业智能客服系统
以下网站是某企业国内机票当中的常见问题:某企业-国内机票-退票、更改和签转,我们希望利用它和大模型的自然语言理解能力来打造一套企业智能客服系统。
首先,我们如果直接在DeepSeek中问:xxx中我想取消预订的机票,需要支付费用吗?

我们如果直接在ChatGpt中问:xxx中我想取消预订的机票,需要支付费用吗?

而网站中的答案为:

所以,直接利用AI来作为智能客服系统行不通,它能够理解你的问题,但是它并不能给你确切的答案,因为对于AI来说,它并不知道企业内部的专有数据,具体政策,而这个时候,我们就可以利用langchain4j来给企业内部搭一套智能客服系统。
整理数据
首先,我们需要把现有的常见文件整理成文档,可以是txt、pdf、xlsx、markdown等格式都可以,我们这里将某企业-国内机票-退票、更改和签转网页中的问题和答案转成txt文件

功能实现
创建一个工程
直接创建一个普通的Maven工程就可以了,然后引入langchain4j的依赖和你选择的大模型依赖,我这里使用open-ai和deepseek:
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-redis</artifactId><version>${langchain4j.version}</version>
</dependency><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-open-ai</artifactId><version>${langchain4j.version}</version>
</dependency><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-spring-boot-starter</artifactId><version>${langchain4j.version}</version> <!-- 使用最新版本 -->
</dependency>
以及slf4j的依赖:
<dependency><groupId>org.tinylog</groupId><artifactId>slf4j-tinylog</artifactId><version>${tinylog.version}</version>
</dependency>
<dependency><groupId>org.tinylog</groupId><artifactId>tinylog-impl</artifactId><version>${tinylog.version}</version>
</dependency>
在main方法中进行简单测试

定义Agent
我们可以定义一个智能客服专门的Agent,比如CustomerServiceAgent,后续就可以直接这个Agent来充当客服回答问题了,比如:
package com.example.agent;import dev.langchain4j.service.spring.AiService;import static dev.langchain4j.service.spring.AiServiceWiringMode.EXPLICIT;/*** @author Administrator*/
@AiService(wiringMode = EXPLICIT, chatModel="deepSeekChatModel")
public interface CustomerServiceAgent {// 用来回答问题的方案String answer(String question);}我这里配置了open-ai 和deepseek
package com.example.config;import com.example.record.DeepSeekConfig;
import com.example.record.OpenAiConfig;
import dev.langchain4j.model.openai.OpenAiChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** @author Administrator*/
@Configuration
public class AiModelConfiguration {@Beanpublic OpenAiChatModel openAiChatModel(OpenAiConfig openAiConfig){return OpenAiChatModel.builder().baseUrl(openAiConfig.baseUrl()).apiKey(openAiConfig.apiKey()).modelName(openAiConfig.modelName())// .httpClientBuilder(new SpringRestClientBuilder()).logRequests(true).logResponses(true).build();}@Beanpublic OpenAiChatModel deepSeekChatModel(DeepSeekConfig deepSeekConfig){return OpenAiChatModel.builder().baseUrl(deepSeekConfig.baseUrl()).apiKey(deepSeekConfig.apiKey()).modelName(deepSeekConfig.modelName())// .httpClientBuilder(new SpringRestClientBuilder()).logRequests(true).logResponses(true).build();}}以上CustomerServiceAgent接口,提供了一个answer方法用来回答问题,同时提供了配置类AiModelConfiguration 来利用@Bean返回两个注册为Spring应用上下文中的bean的对象 ,然后在注解@AiService(wiringMode = EXPLICIT, chatModel=“deepSeekChatModel”)上使用,这样我们可以直接这么来创建并使用CustomerServiceAgent:

换一个模型

导入知识库
上面方法创建出来的CustomerServiceAgent目前来说只拥有普通大模型的功能,此时的它还没有企业内部的信息,要想让它成为一个智能客服系统,需要将前面整理出来的问答数据送给CustomerServiceAgent。
加载并解析文件
我们需要这么来做,首先加载并解析问答txt文件
// 加载并解析文件
Document document;
try {Path documentPath = Paths.get(CustomerServiceAgent.class.getClassLoader().getResource("ctrip-qa.txt").toURI());DocumentParser documentParser = new TextDocumentParser();document = FileSystemDocumentLoader.loadDocument(documentPath, documentParser);
} catch (URISyntaxException e) {throw new RuntimeException(e);
}
以上代码我们使用FileSystemDocumentLoader来加载本地文件,利用TextDocumentParser来解析txt文件,最终得到"ctrip-qa.txt"文件所对应的Document对象
切分文件
然后需要对文件进行切分,把"ctrip-qa.txt"文件中的内容切分成问答对,"ctrip-qa.txt"文件内容格式已经被我整理好了,比如:

所以我们可以使用正则表达式Pattern.compile("(\\R{2,})", Pattern.MULTILINE)来进行切分,我们自定义一个DocumentSplitter来实现:
@Override
public List<TextSegment> split(Document document) {List<TextSegment> segments = new ArrayList<>();String[] parts = split(document.text());for (String part : parts) {segments.add(TextSegment.from(part));}return segments;
}public String[] split(String text) {Pattern pattern = Pattern.compile("(\\R{2,})", Pattern.MULTILINE);return pattern.split(text);
}
然后使用以下代码对Document对象进行加载和切分就可以了:

其中每个TextSegment对象就表示切分之后的一段文本,在本项目中就是一个问答对。
文本向量化
得到切分之后的文本后,就可以对文本进行向量化处理了,比如你可以直接使用open-ai的向量化模型接口来进行向量化:
package com.example.record;import org.springframework.boot.context.properties.ConfigurationProperties;
@ConfigurationProperties(prefix = OpenAiEmbeddingConfig.PREFIX)
public record OpenAiEmbeddingConfig(String baseUrl, String apiKey, String modelName,int dimension) {public static final String PREFIX = "langchain4j.open-ai.embedding-model";public OpenAiEmbeddingConfig(String baseUrl, String apiKey, String modelName,int dimension) {this.baseUrl = baseUrl;this.apiKey = apiKey;this.modelName = modelName;this.dimension=dimension;}@Overridepublic int dimension() {return dimension;}@Overridepublic String baseUrl() {return baseUrl;}@Overridepublic String apiKey() {return apiKey;}@Overridepublic String modelName() {return modelName;}
}@Bean
public OpenAiEmbeddingModel openAiEmbeddingModel(OpenAiEmbeddingConfig openAiEmbeddingConfig){return OpenAiEmbeddingModel.builder().baseUrl(openAiEmbeddingConfig.baseUrl()).apiKey(openAiEmbeddingConfig.apiKey()).modelName(openAiEmbeddingConfig.modelName())// .httpClientBuilder(new SpringRestClientBuilder()).logRequests(true).logResponses(true).build();
}
准备工作做好后,进行向量化
List<TextSegment> textSegments = documentSplitter.split(documentSplitter.load(""));Response<List<Embedding>> resp = openAiEmbeddingModel.embedAll(textSegments);redisEmbeddingStore.addAll(resp.content());
运行结果:

每个TextSegment,也就是每个问答对,对应了一个向量,而向量就是一个数字数组,如果简化一下数组的大小,比如大小为2,那么一个向量相当于一个(x,y)坐标点,放在坐标中就可以两个坐标点的距离,距离越近就表示坐标点越相似,也就是表示两个向量越相似。
当然,我们也可以使用其他的向量模型来对文本进行向量化,比如使用AllMiniLmL6V2QuantizedEmbeddingModel这个向量化模型,使用它就需要通过网络请求去进行向量化了,因为这个模型可以直接部署在你当前的应用进程内,不过需要额外添加依赖:
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-embeddings-all-minilm-l6-v2-q</artifactId><version>${langchain4j.version}</version>
</dependency>
然后使用以下代码即可得到文本的向量:
AllMiniLmL6V2QuantizedEmbeddingModel allMiniLmL6V2QuantizedEmbeddingModel1 = new AllMiniLmL6V2QuantizedEmbeddingModel();
List<TextSegment> textSegments = documentSplitter.split(documentSplitter.load("ctrip-qa.txt"));
Response<List<Embedding>> resp = allMiniLmL6V2QuantizedEmbeddingModel1.embedAll(textSegments);
redisEmbeddingStore.addAll(resp.content()); 不同的向量化模型效果肯定是有区别,比如A1、A2两个文本,open-ai计算出来的向量可能是比较相似的,而AllMiniLmL6V2QuantizedEmbeddingModel则可能计算出来的向量之间差别较大,所以在实际工作中还是建议使用效果更好的向量化模型。
不同的向量化模型效果肯定是有区别,比如A1、A2两个文本,open-ai计算出来的向量可能是比较相似的,而AllMiniLmL6V2QuantizedEmbeddingModel则可能计算出来的向量之间差别较大,所以在实际工作中还是建议使用效果更好的向量化模型。
向量存储
正对拆分后的文本得到向量后,就需要把文本和向量之间的映射关系存储下来,使用CustomerServiceAgent在回答问题时,能够根据向量相似度找到和用户问题相似的知识库问题。
存储向量的代码大致为
Response<List<Embedding>> resp = allMiniLmL6V2QuantizedEmbeddingModel1.embedAll(textSegments);
redisEmbeddingStore.addAll(resp.content(),textSegments);
这是把向量和文本数据直接存在了redis中,本质上就是一个CopyOnWriteArrayList,该List中存储的是Entry对象,而Entry对象则分别存储了文本和向量。
实际工作中,我们肯定也需要文本和向量存储可持久化的向量数据库中,你可以选择Chroma、Milvus这种专门的向量数据库,也可以使用Elasticsearch、Redis、PostgreSQL、MongoDb来存储。
redis 持久化案例看上一篇
组装ContentRetriever
当把向量存入向量数据库后,就可以组装一个ContentRetriever用来后续进行内容查找了,组装代码为:
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder().embeddingStore(embeddingStore).embeddingModel(embeddingModel).maxResults(5) // 最相似的5个结果.minScore(0.8) // 只找相似度在0.8以上的内容.build();
以上代码将向量数据库和向量模型组装成了一个ContentRetriever,并指定ContentRetriever后续查找内容时,只返回相似度在0.8以上的前5个结果。
我现在针对以下原始问题来进行提问:
Q:电子机票如何签转?
电子机票签转按航空公司规定操作。折扣票不能签转。
我的问题和原始问题并不完全相同,但是我希望ContentRetriever能根据我的问题找到和问题相似的原始问题和答案:
Query query = new Query("机票如何签转?");List<Content> retrieve = contentRetriever.retrieve(query);运行结果如下:

发现答案就比较理想了,"机票如何签转?"排在了第一个,说明和原始问题最匹配。
当然,我们也可以从另外一个角度来进行优化,由于我们在做文本向量化时,使用的是“问题+答案”一起做的向量化,而查询的时候只使用了“问题”做向量化,由于两者不一致,可能导致某些较弱的向量化模型生成出来的向量偏离的更远,导致在做向量匹配时出现了差距,那能不能在做文本向量化时,也只使用“问题”来做向量化呢?
List<TextSegment> textSegments = documentSplitter.split(documentSplitter.load("ctrip-qa.txt"));
// 将问题抽取出来单独进行向量化
List<TextSegment> questions = new ArrayList<>();
for (TextSegment segment : textSegments) {questions.add(TextSegment.from(segment.text().split("\r\n")[0]));
}
Response<List<Embedding>> resp = openAiEmbeddingModel.embedAll(questions);
redisEmbeddingStore.addAll(resp.content(),textSegments);
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder().embeddingStore(redisEmbeddingStore).embeddingModel(openAiEmbeddingModel).maxResults(5) // 最相似的5个结果.minScore(0.8) // 只找相似度在0.8以上的内容.build();Query query = new Query("机票如何签转?");
List<Content> retrieve = contentRetriever.retrieve(query);
运行结果如下:

效果比上一次提升了,只显示了我们想要的
整合大模型
当我们能根据用户问题匹配到原始问题和答案后,该如何将问题的答案返回给用户呢?
现在我们再调用下CustomerServiceAgent:
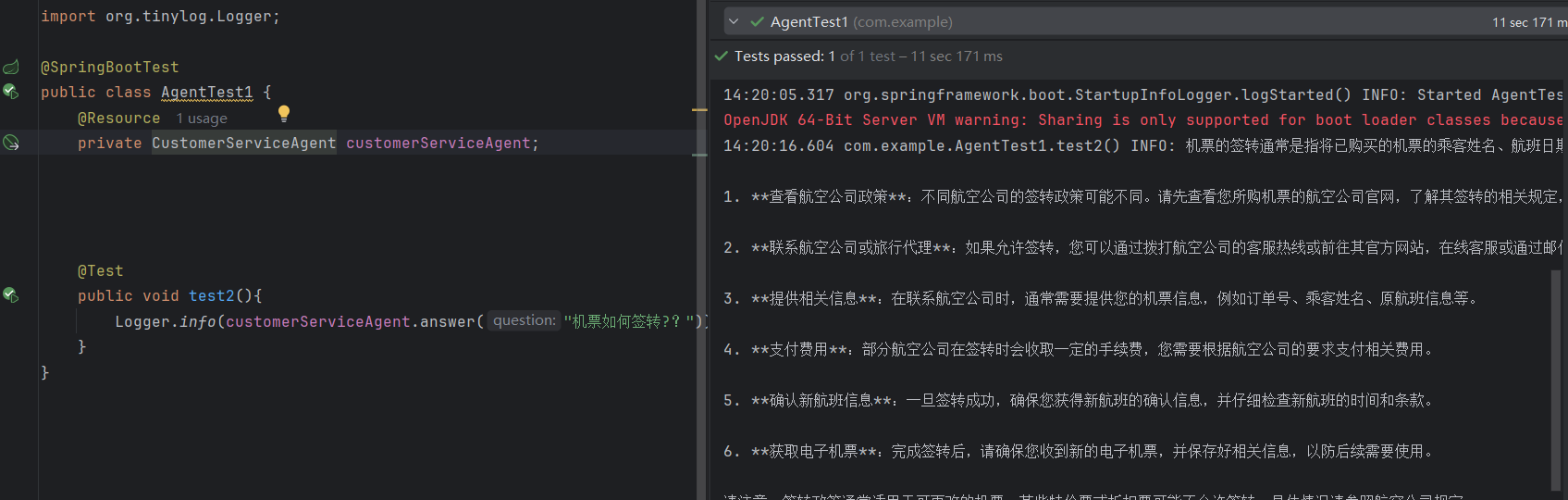
发现内容根本就不是ContentRetriever返回的内容
所以在创建了ContentRetriever之后,我们可以通过AiServices来整合它与大模型:
@Bean
public ContentRetriever contentRetriever(OpenAiEmbeddingModel openAiEmbeddingModel,RedisEmbeddingStore redisEmbeddingStore){return EmbeddingStoreContentRetriever.builder().embeddingStore(redisEmbeddingStore).embeddingModel(openAiEmbeddingModel).maxResults(5) // 最相似的5个结果.minScore(0.8) // 只找相似度在0.8以上的内容.build();
}
@Bean
public ChatMemory chatMemory(){return MessageWindowChatMemory.withMaxMessages(100);
}
把bean注入给AiService 生成CustomerServiceAgent的代理对象
package com.example.agent;import dev.langchain4j.service.spring.AiService;import static dev.langchain4j.service.spring.AiServiceWiringMode.EXPLICIT;/*** @author Administrator*/
@AiService(wiringMode = EXPLICIT, chatModel="openAiChatModel",chatMemory="chatMemory",contentRetriever="contentRetriever")
public interface CustomerServiceAgent {// 用来回答问题的方案String answer(String question);}再次执行 输出

符合预期了
Tool
定义一个Tool:
package com.example.tool;import dev.langchain4j.agent.tool.Tool;import java.time.LocalDateTime;public class DateTool {@Tool("获取当前日期")public static String dateUtil(){System.out.println("获取当前日期");return LocalDateTime.now().toString();}} @Beanpublic DateTool dateTool(){return new DateTool();}@AiService(wiringMode = EXPLICIT, chatModel="openAiChatModel",chatMemory="chatMemory",contentRetriever="contentRetriever",tools = {"dateTool"})
public interface CustomerServiceAgent {//其他代码
}
再运行:

符合预期,这样涉及当前日期的一些任务也可以比较精确的进行回答
到这,一个智能客服系统算是初具雏形了,这中间也涉及到了langchain4j中最为关键的几个核心组件,大家可以基于以上流程在自己公司内部也搭建这么一套系统,当然,可能需要针对实际情况做各种优化。
【zwpflc】
各位看官 有任何问题可以加我 请备注csdn