自注意力机制self-attention
目录
简介:
输入和输出方式:
Sequence Labeling:
self-attention运作方式:
一:怎么从vector得到b1
二:利用矩阵的方法怎么得到
Multi-head Self-attention:
positional encoding:位置编码
Self-attention的应用:
Self-attention 与 CNN的差别和相同点:
Self-attention 与 RNN的差别和相同点:
简介:
Sophisticated Input之前的输入一个向量输出一个数值,如果输入很复杂,比如输入的是一个句子,每个文字是一个向量表示的,那么每一次输入的都是未知长度的向量组。(用一个很长的向量表示每一个中文的汉字,n个维度向量可以表示2的n次方个汉字),一段音频可以看成一组向量。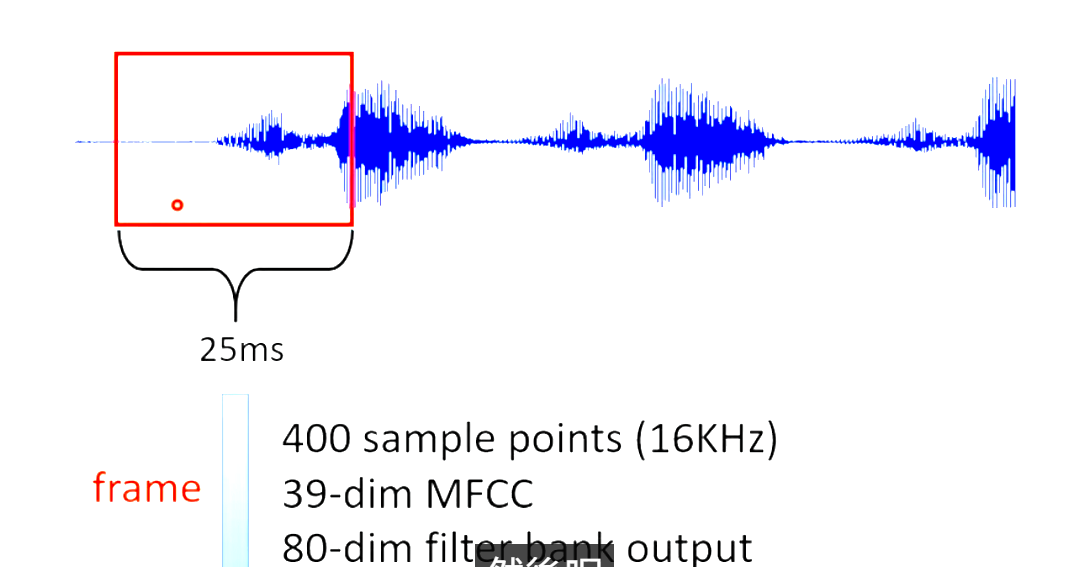
输入和输出方式:
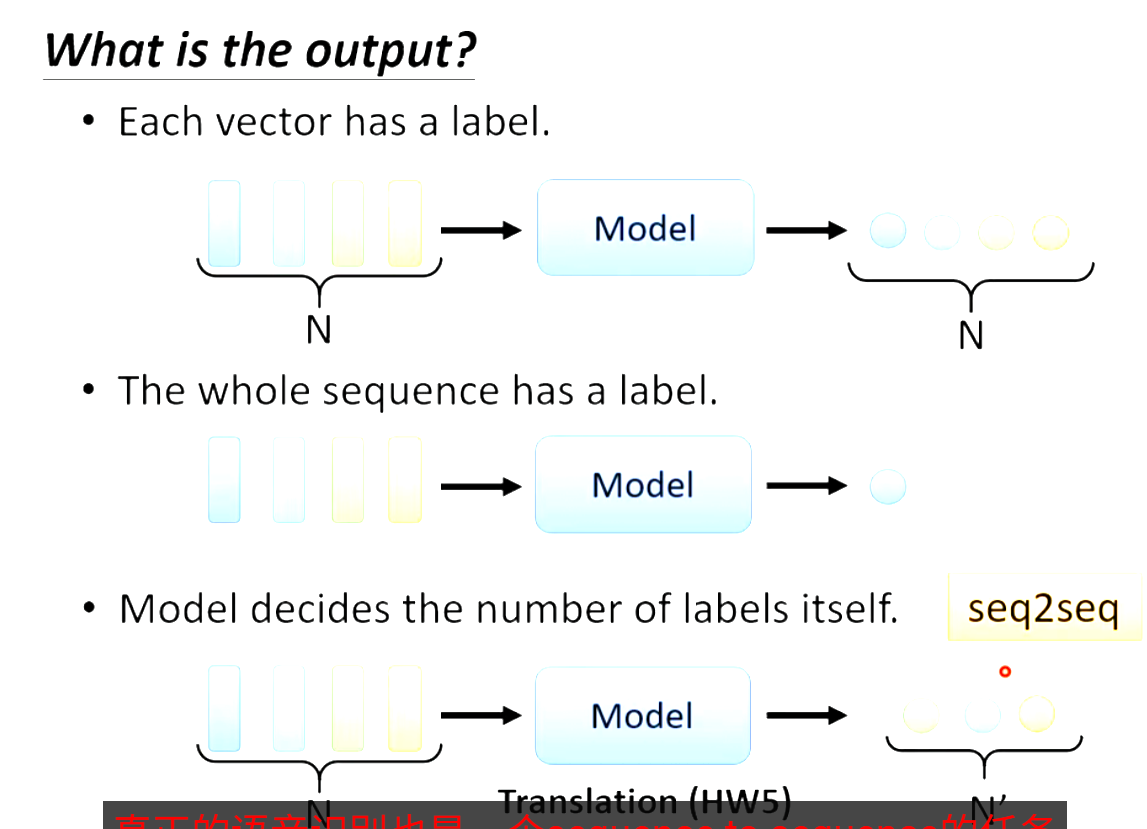
Sequence Labeling:
词性标注:I saw a saw。我看到一把锯子。saw做了动词也做了名词。如果只是单个的词语考虑,会分辨不出来,这里要考虑一整个句子,self-attention就是考虑整个句子,然后把输入向量转变为输出向量,并且输入几个就会输出几个。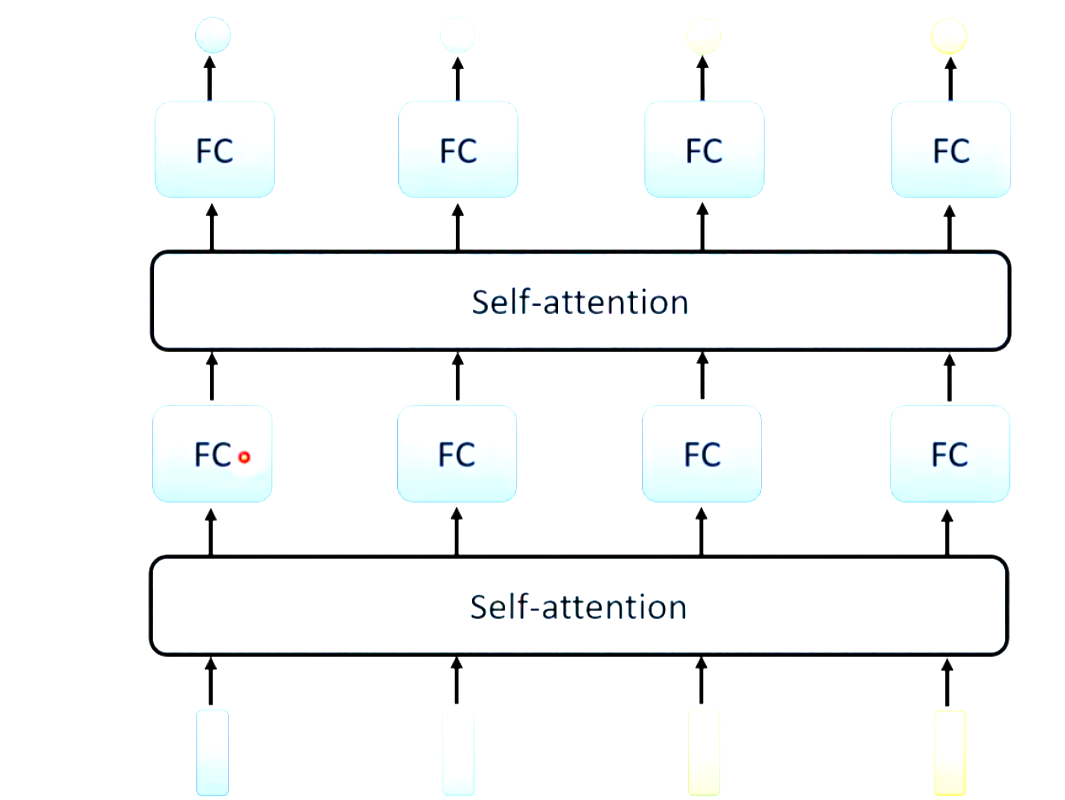
self-attention运作方式:
一:怎么从vector得到b1
输入一排a向量输出一排b,a和b的数量相等,而且每个b都要考虑全部的a,生成b1时要考虑a1与全部其他的a向量,计算关联程度记作attention score(关联分数),方式如下。
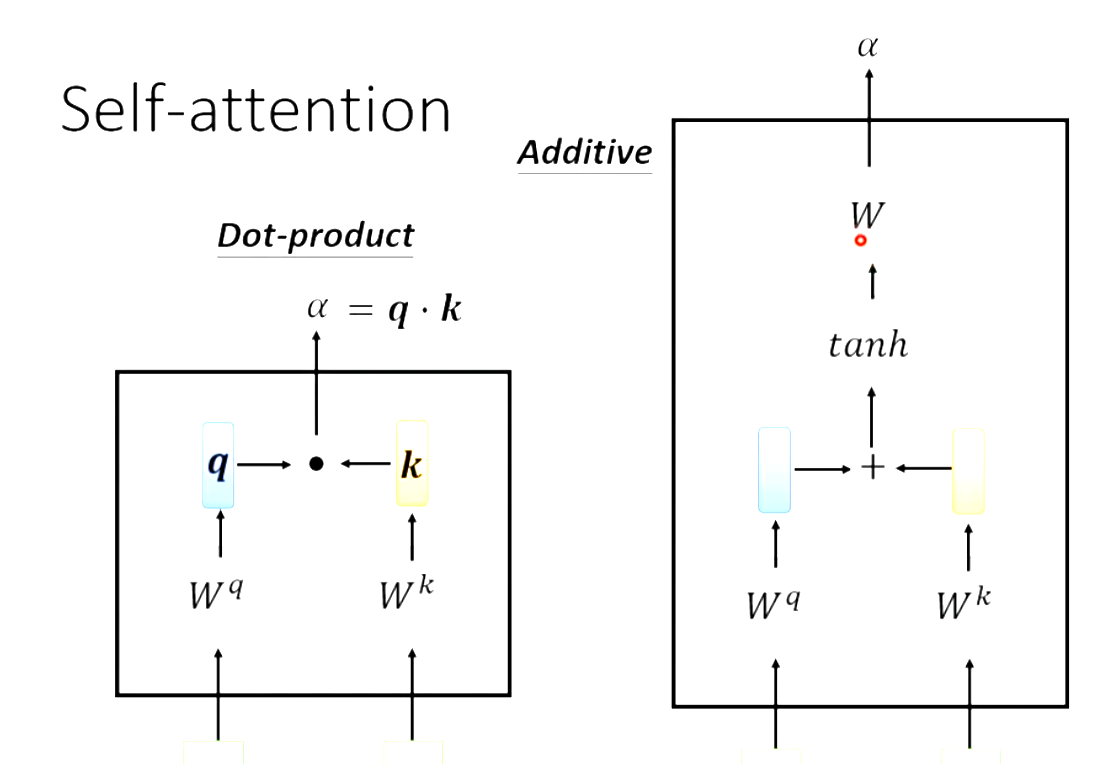
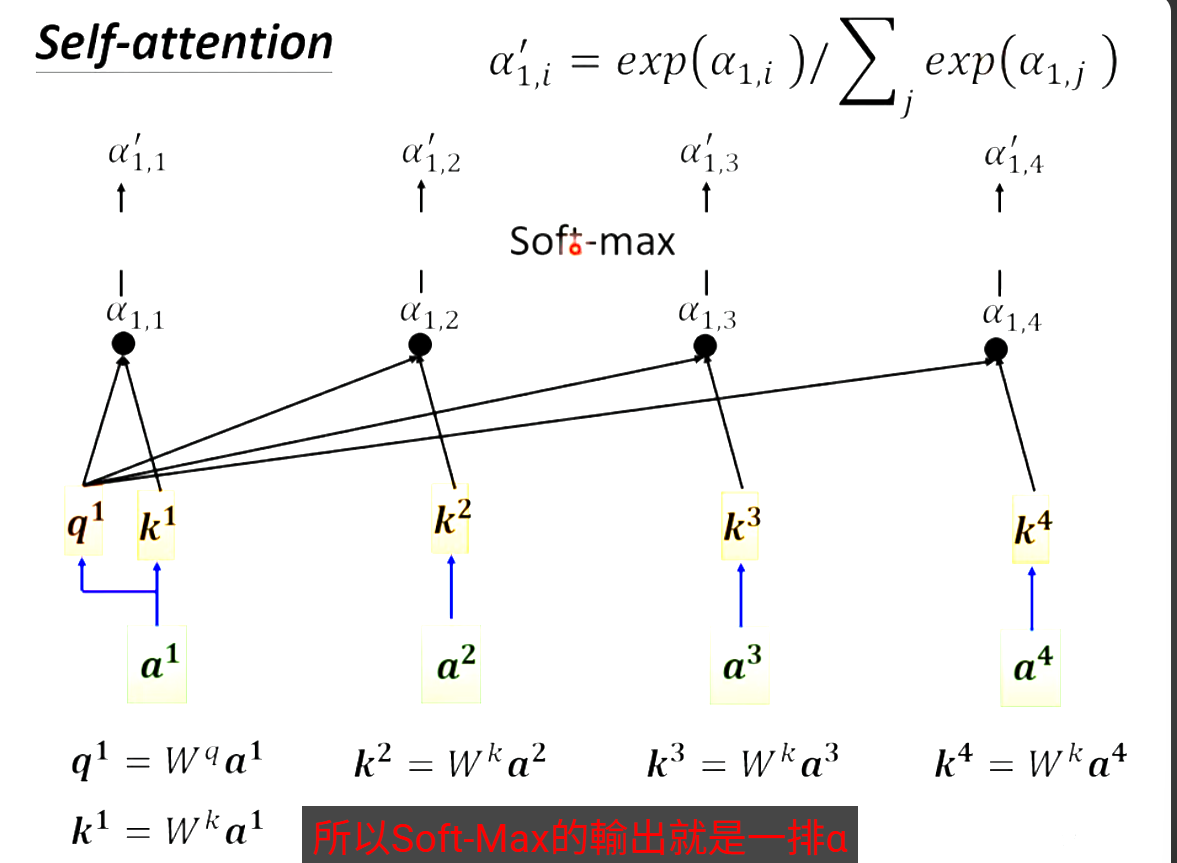
现在已经计算出来了每个向量与a1的关联性。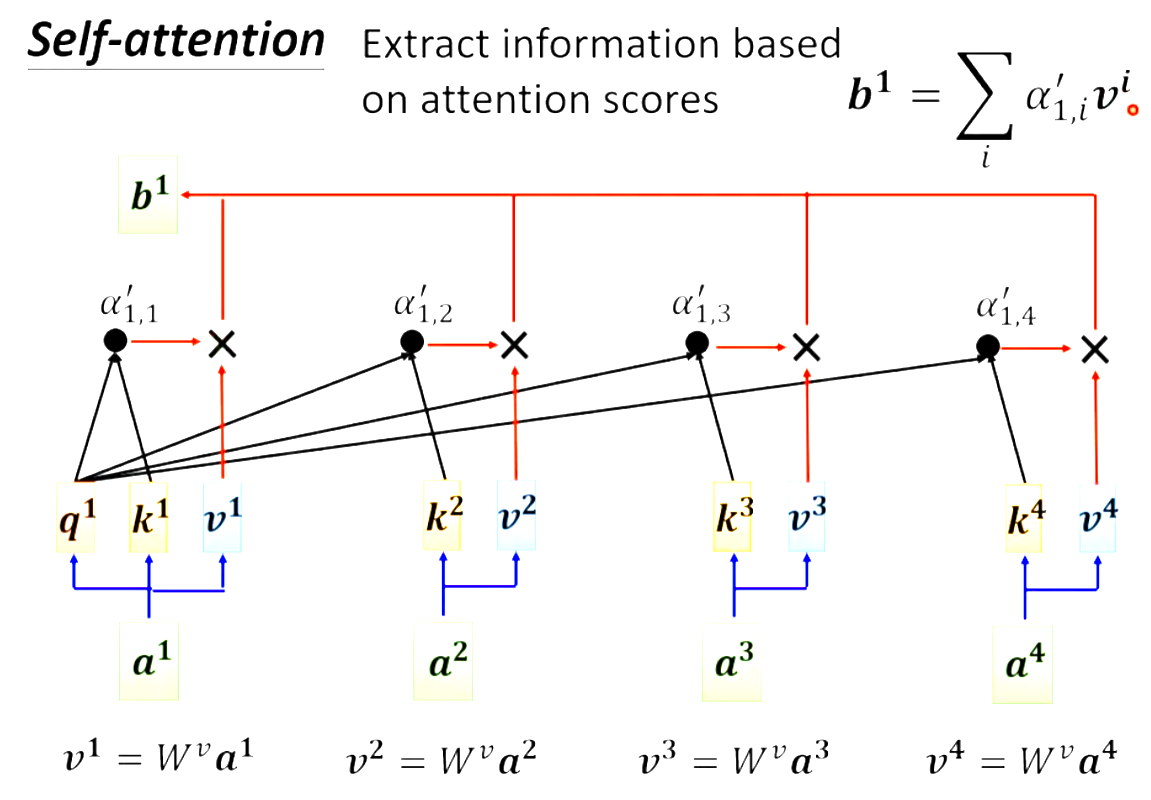
二:利用矩阵的方法怎么得到
a1....a4每一个a都要得到qkv,每一个a都乘一个Wq得到q![]()
那么可以直接把a1a2a3a4看成一个矩阵乘Wq,直接得到q1q2q3q4。
kv同理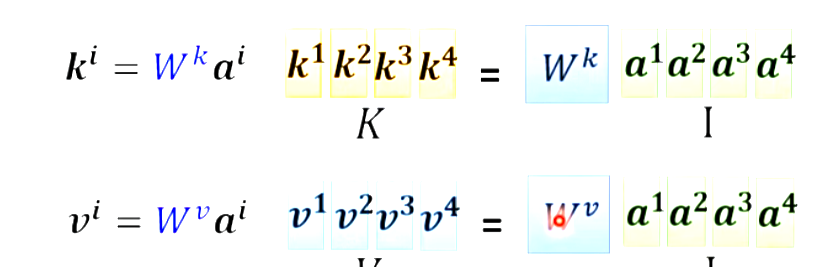 。
。
那么计算q1的α11,α12,α13,α14可以看成k1234×q1的矩阵。
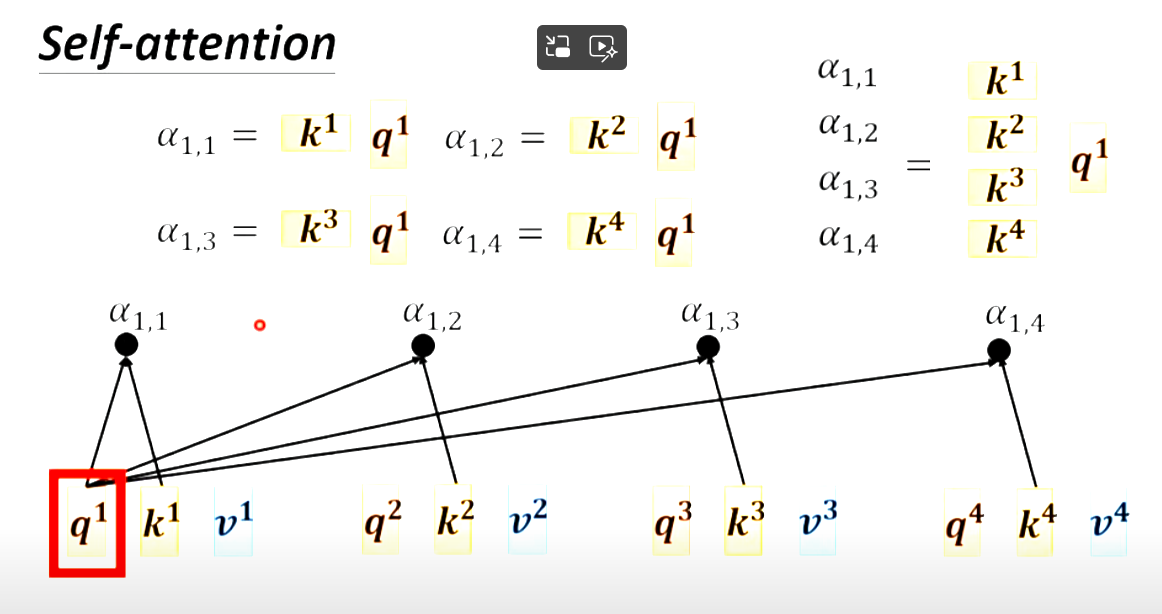
计算q2q3q4的时候同理。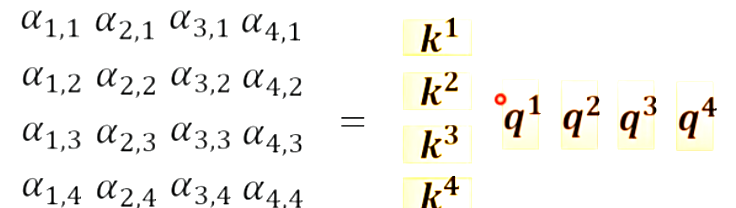
即A=K转制×Q,A进行softmax得到A`
那么b1即等于: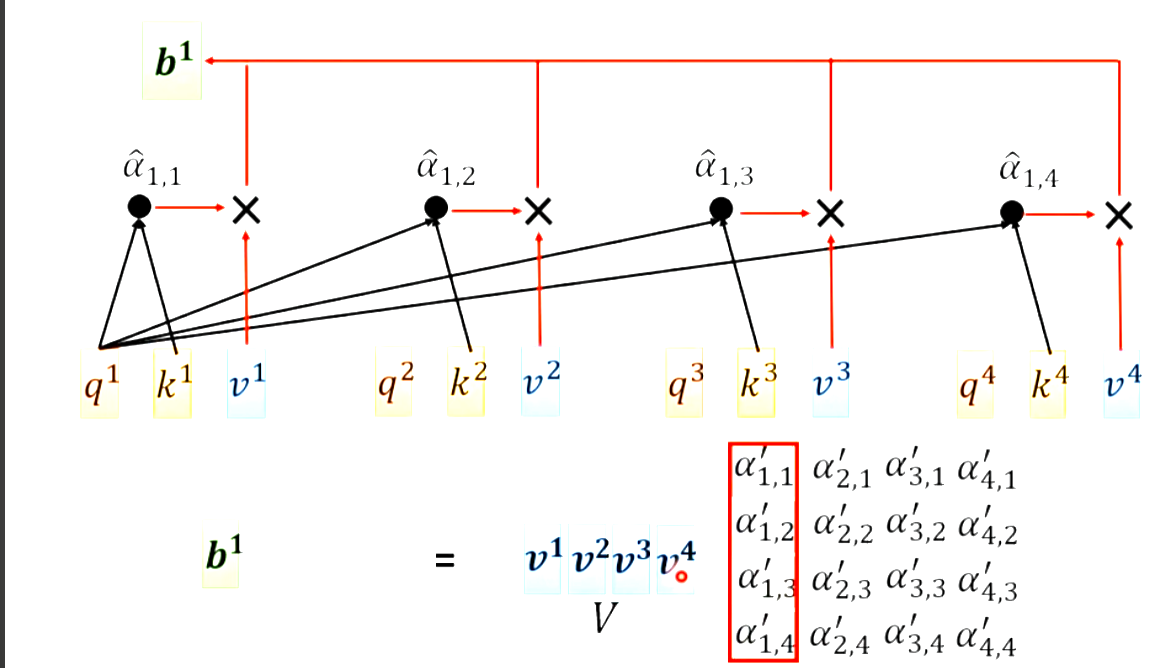
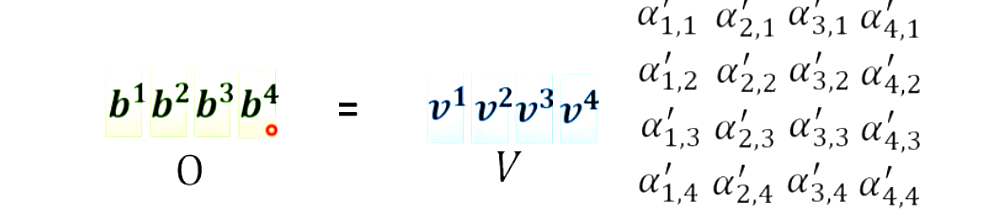
I为input乘上Wq、Wk、Wv得到Q、K、V,K的转制乘Q得到A,A进行softmax得到A`(Attention Matrix)。V乘A`得到了O,O即为self-attention的输出。
只有Wq、Wk、Wv是未知的,需要根据训练资料找出来。
Multi-head Self-attention:
相关这个事有很多种形式很多种定义,不能只有一个q,应该有多个q'来描述“相关”。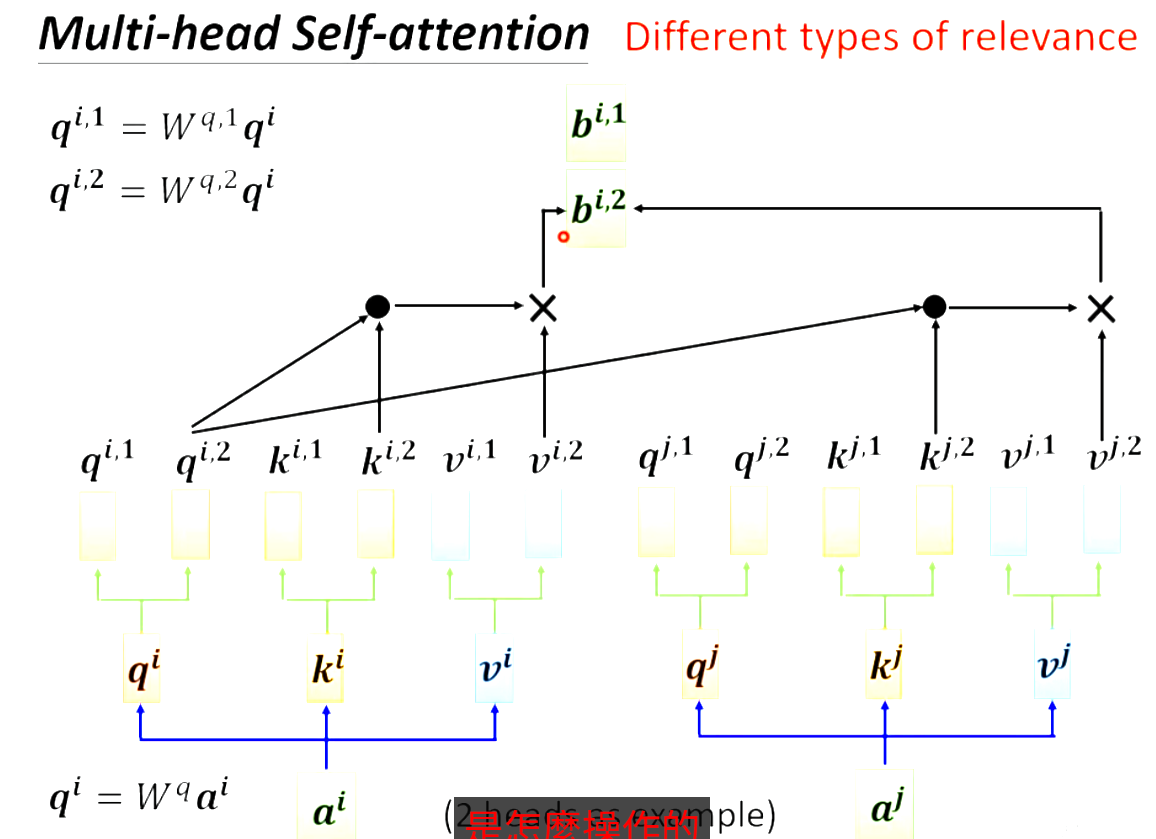
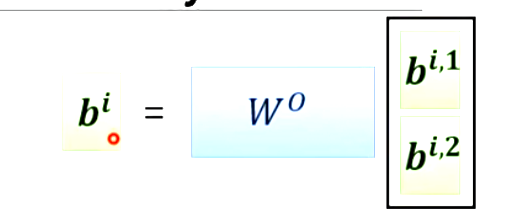
positional encoding:位置编码
self-attention少了一个很重要的信息,即位置的信息,如果是输入一段原始数据是句子的向量,那么每个向量的位置表示输入的句子中每个词语的位置,这个位置信息很重要。
positional encoding为每个位置设定一个vector,记作ei,加到ai上面,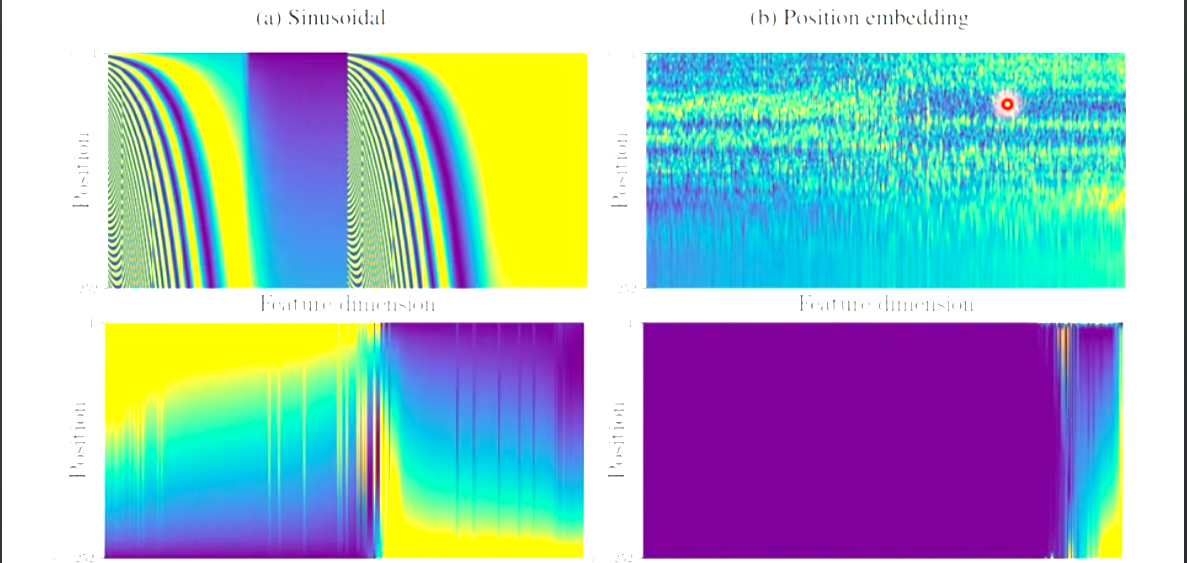
Self-attention的应用:
NLP、Transformer、BERT、语音识别、影像... ...

语音识别上,语音的Attention Matrix会非常大,可以用到Truncated Self-attention,他的作用是在做语音识别的时候,不要看一整句话,只看一个小部分即可。这个部分的大小由人设定
影像上,长宽和RGB,可以把同一个长宽处的RGB看成一个向量。那么这个5×10的图片可以看成5×10个三维的向量。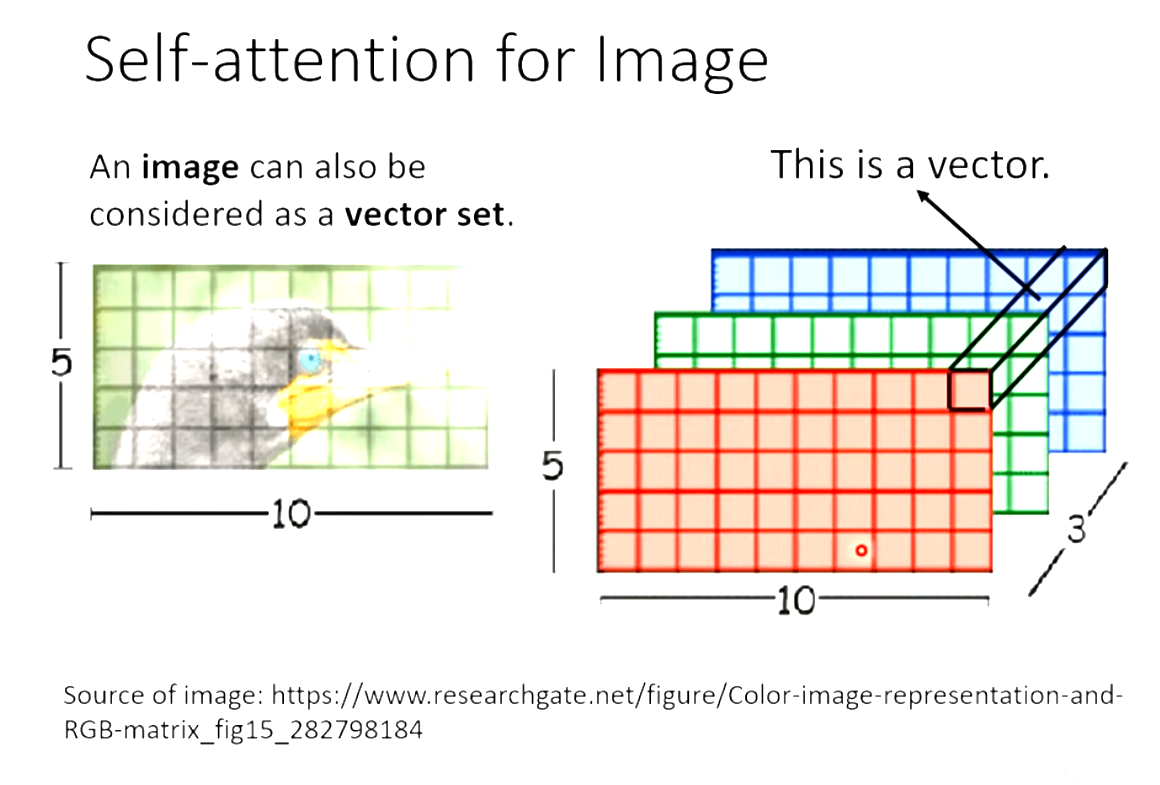
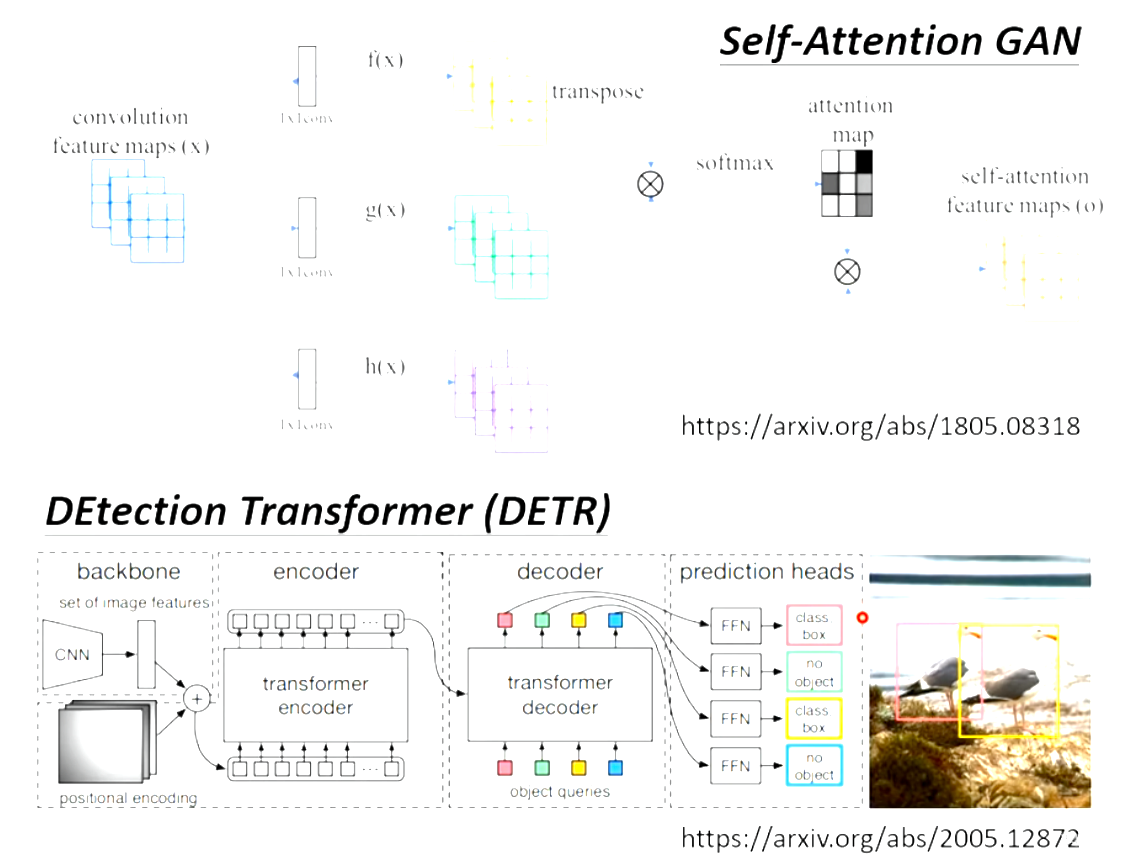
Self-attention 与 CNN的差别和相同点:
CNN是简化版的Self-attention,CNN只考虑receptive file里面的信息,而在做Self-attention的时候,考虑整张图片的信息。

随着资料量越来越多,Self-attention的结果越来越好,在资料量足够大的时候,Self-attention可以超过CNN。但是资料量少的时候,CNN是好于Self-attention的,原因是:Self-attention弹性大,需要更多的资料训练,训练资料少的时候会overfitting,CNN弹性小,资料少的时候就可以训练好。
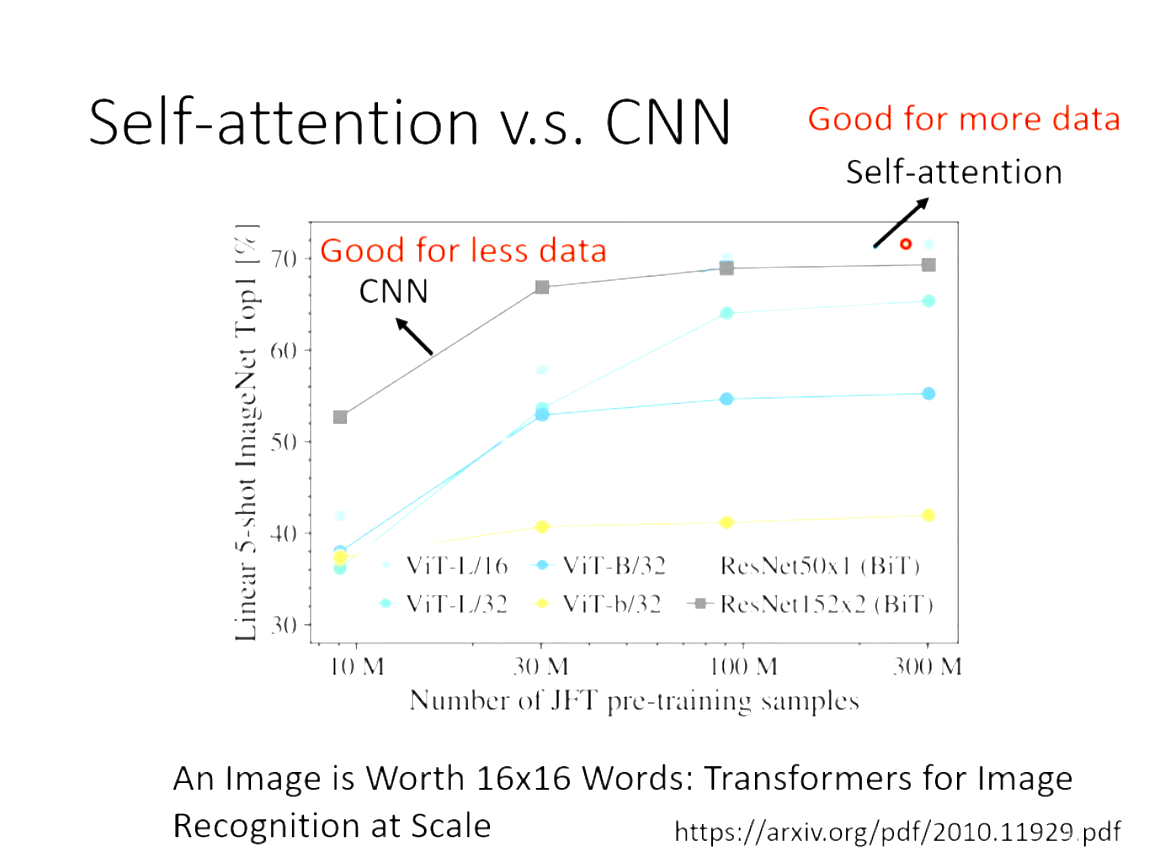
Self-attention 与 RNN的差别和相同点:
RNN:recurrent neural network循环神经网络,输入一个序列。
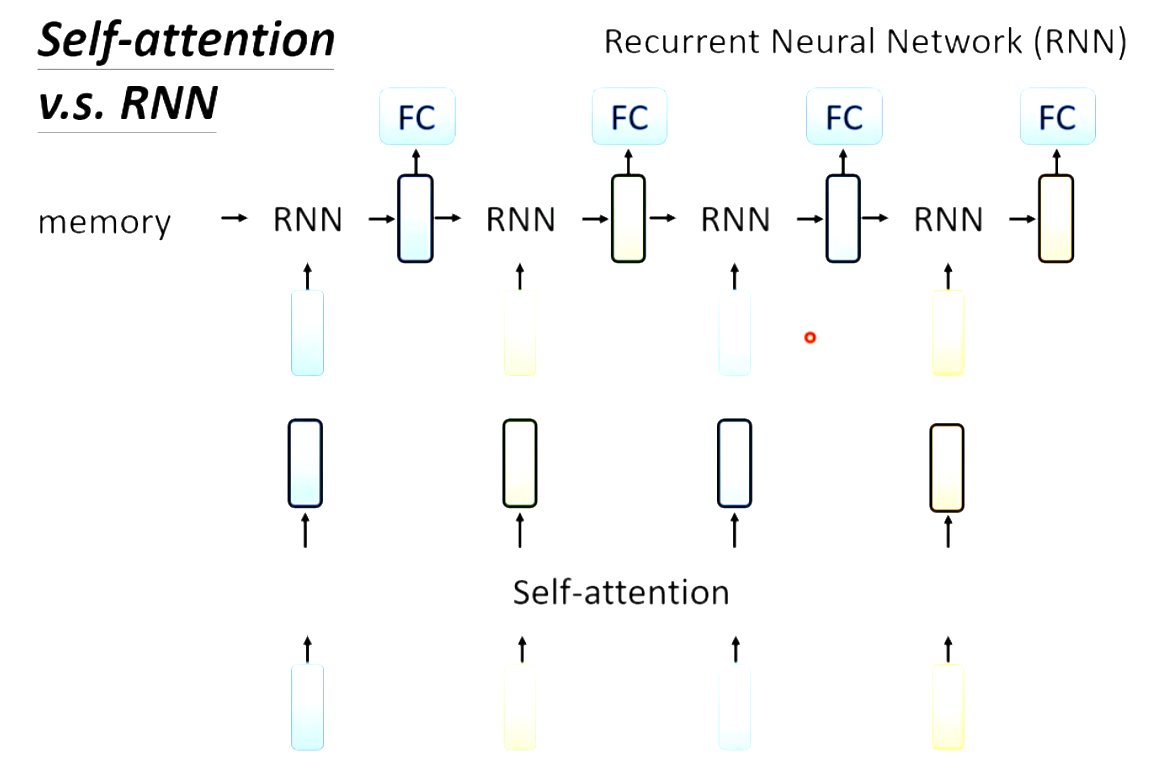
RNN不能平行处理,Self-attention可以平行处理,效率更高。