【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述
Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通过累积历史梯度的平方信息,动态调整每个参数的学习率,使得频繁更新的参数学习率较小,稀疏更新的参数学习率较大。这种自适应特性使其在训练深度神经网络时表现优异,尤其在自然语言处理和推荐系统中广泛应用。
二.Adagrad的优缺点
Adagrad的主要优势在于自适应学习率,尤其适合稀疏数据或非平稳目标的优化问题。其缺点在于累积的梯度平方会持续增长,导致后期学习率过小,可能过早停止训练。后续改进算法如RMSProp和Adam通过引入衰减机制解决了这一问题。尽管如此,Adagrad仍为自适应优化算法的发展奠定了基础。
三.算法原理与特性
3.1 基本核心思想
自适应梯度算法(Adaptive Gradient Algorithm)通过累积历史梯度信息实现参数级学习率调整。其主要创新点在于:
$$g_{t,i} = \sum_{\tau=1}^t \nabla_\theta J(\theta_{\tau,i})^2$$
$$\theta_{t+1,i} = \theta_{t,i} - \frac{\eta}{\sqrt{g_{t,i} + \epsilon}} \nabla_\theta J(\theta_{t,i})$$
其中$$i$$表示参数索引,$$\eta$$为全局学习率, $$\epsilon$$为数值稳定常数(通常取 1e-8)
3.2 算法的特性
- 参数级自适应:每个参数独立动态调整学习率,而不是固定学习率
- 梯度敏感度:更新率较大的动态调整为较小的学习率,更新率较小的动态调整为较大的学习率
- 累积记忆:通过历史梯度的平方和持续积累增长
3.3 更新规则
Adagrad的更新公式基于参数的历史梯度信息,具体表现为对学习率的分母项进行累积。对于每个参数θᵢ,其更新规则如下:
# Adagrad更新公式
grad_squared += gradient ** 2
adjusted_lr = learning_rate / (sqrt(grad_squared) + epsilon)
theta -= adjusted_lr * gradient
其中,grad_squared是梯度平方的累积,epsilon是为数值稳定性添加的常数,防止出现梯度为0导致分母变成无限大的情况,通常采用1e-8。Adagrad的累积特性使其对初始学习率的选择相对鲁棒,但长期训练可能导致学习率过小。
四、代码实现
4.1 测试函数设置
使用非凸函数: f(x) = x**2 / 20.0 + y**2
4.2 收敛速度可视化
import numpy as np
from collections import OrderedDict
import matplotlib.pyplot as pltclass AdaGrad:"""AdaGrad"""def __init__(self, lr=1.5):self.lr = lrself.h = Nonedef update(self, params, grads):if self.h is None:self.h = {}for key, val in params.items():self.h[key] = np.zeros_like(val)for key in params.keys():self.h[key] += grads[key] * grads[key]params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)optimizers= AdaGrad()init_pos = (-7.0, 2.0)
params = {}
params['x'], params['y'] = init_pos[0], init_pos[1]
grads = {}
grads['x'], grads['y'] = 0, 0x_history = []
y_history = []def f(x, y):return x**2 / 20.0 + y**2def df(x, y):return x / 10.0, 2.0*yfor i in range(30):x_history.append(params['x'])y_history.append(params['y'])grads['x'], grads['y'] = df(params['x'], params['y'])optimizers.update(params, grads)x = np.arange(-10, 10, 0.01)
y = np.arange(-5, 5, 0.01)X, Y = np.meshgrid(x, y)
Z = f(X, Y)# for simple contour line
mask = Z > 7
Z[mask] = 0idx = 1# plot
plt.subplot(2, 2, idx)
idx += 1
plt.plot(x_history, y_history, 'o-', color="red")
plt.contour(X, Y, Z)
plt.ylim(-10, 10)
plt.xlim(-10, 10)
plt.plot(0, 0, '+')
# colorbar()
# spring()
plt.title("AdaGrad")
plt.xlabel("x")
plt.ylabel("y")plt.show()
收敛效果如下:
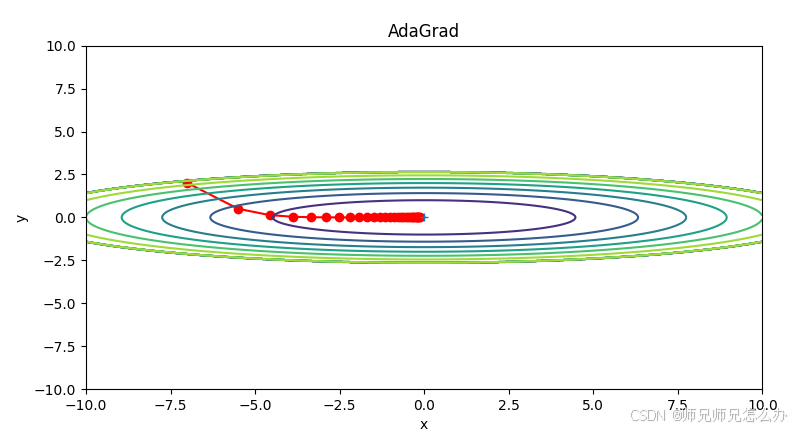
五、Adagrad算法优缺点分析
5.1 优势特征
- 稀疏梯度优化:适合NLP等稀疏数据场景
- 自动学习率调整:减少超参调优成本
- 早期快速收敛:梯度累积未饱和时效率高
5.2 局限与改进
- 学习率单调衰减:后期更新停滞
- 内存消耗:需存储历史梯度平方和
- 梯度突变敏感:可能错过最优解
5.3 常用场景以及建议
- 推荐场景:自然语言处理、推荐系统
- 参数设置:
- 初始学习率:0.01-0.1
- 批量大小:128-512
- 配合技术:梯度裁剪+权重衰减
六. 各优化器对比
| 优化器 | 收敛速度 | 震荡幅度 | 超参敏感性 | 内存消耗 |
|---|---|---|---|---|
| SGD | 慢 | 大 | 高 | 低 |
| Momentum | 中等 | 中等 | 中等 | 低 |
| Adagrad | 快(初期) | 小 | 低 | 中 |
| RMSProp | 稳定 | 较小 | 中等 | 中 |
| Adam | 最快 | 最小 | 低 | 高 |
七、全部优化器的对比代码
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cmdef test_function(x, y):return x ** 2 / 20.0 + y ** 2def compare_optimizers():# 初始化参数init_params = np.array([3.0, 4.0])epochs = 200optimizers = {'SGD': SGD(lr=0.1),'Momentum': Momentum(lr=0.1, momentum=0.9),'Adagrad': Adagrad(lr=0.1),'RMSProp': RMSProp(lr=0.001, decay=0.9),'Adam': Adam(lr=0.1, beta1=0.9, beta2=0.999)}# 训练过程plt.figure(figsize=(14,10))ax = plt.axes(projection='3d')X = np.linspace(-4, 4, 100)Y = np.linspace(-4, 4, 100)X, Y = np.meshgrid(X, Y)Z = test_function(X, Y)ax.plot_surface(X, Y, Z, cmap=cm.coolwarm, alpha=0.6)for name, opt in optimizers.items():params = init_params.copy()trajectory = []for _ in range(epochs):grad = compute_gradient(params)params = opt.update(params, grad)trajectory.append(params.copy())trajectory = np.array(trajectory)ax.plot3D(trajectory[:,0], trajectory[:,1], test_function(trajectory[:,0], trajectory[:,1]), label=name, linewidth=2)ax.legend()ax.set_xlabel('x')ax.set_ylabel('y')ax.set_zlabel('z')plt.show()def compute_gradient(params):x, y = paramsdx = x / 10.0dy = 2.0*yreturn np.array([dx, dy])# 各优化器实现类
class SGD:def __init__(self, lr=0.01):self.lr = lrdef update(self, params, grads):return params - self.lr * gradsclass Momentum:def __init__(self, lr=0.01, momentum=0.9):self.lr = lrself.momentum = momentumself.v = Nonedef update(self, params, grads):if self.v is None:self.v = np.zeros_like(params)self.v = self.momentum*self.v + self.lr*gradsreturn params - self.vclass Adagrad:def __init__(self, lr=0.01, eps=1e-8):self.lr = lrself.eps = epsself.cache = Nonedef update(self, params, grads):if self.cache is None:self.cache = np.zeros_like(params)self.cache += grads**2return params - self.lr / (np.sqrt(self.cache) + self.eps) * gradsclass RMSProp:def __init__(self, lr=0.001, decay=0.9, eps=1e-8):self.lr = lrself.decay = decayself.eps = epsself.cache = Nonedef update(self, params, grads):if self.cache is None:self.cache = np.zeros_like(params)self.cache = self.decay*self.cache + (1-self.decay)*grads**2return params - self.lr / (np.sqrt(self.cache) + self.eps) * gradsclass Adam:def __init__(self, lr=0.001, beta1=0.9, beta2=0.999, eps=1e-8):self.lr = lrself.beta1 = beta1self.beta2 = beta2self.eps = epsself.m = Noneself.v = Noneself.t = 0def update(self, params, grads):if self.m is None:self.m = np.zeros_like(params)self.v = np.zeros_like(params)self.t += 1self.m = self.beta1*self.m + (1-self.beta1)*gradsself.v = self.beta2*self.v + (1-self.beta2)*grads**2m_hat = self.m / (1 - self.beta1**self.t)v_hat = self.v / (1 - self.beta2**self.t)return params - self.lr * m_hat / (np.sqrt(v_hat) + self.eps)if __name__ == "__main__":compare_optimizers()
效果图如下:

观察图示可以得出以下结论:
- Adagrad初期收敛速度明显快于SGD
- 中后期被Adam、RMSProp超越
- 在平坦区域表现出更稳定的更新方向
- 对于陡峭方向能自动减小步长