Learning a Discriminative Prior for Blind Image Deblurring论文阅读
Learning a Discriminative Prior for Blind Image Deblurring
- 1. 论文的研究目标与实际问题意义
- 1.1 研究目标
- 1.2 实际意义
- 2. 创新方法、模型与公式解析
- 2.1 核心思路
- 2.2 方法框架
- 2.2.1 判别性先验学习
- 网络架构设计
- 损失函数
- 2.2.2 MAP优化框架
- 目标函数
- 优化算法
- 2.2.3 非均匀模糊扩展
- 2.3 优势对比
- 2.4 关键公式总结
- 3. 实验设计与结果验证
- 3.1 实验设置
- 3.2 关键结果
- 3.3 消融实验
- 4. 未来研究方向与挑战
- 4.1 技术挑战
- 4.2 潜在方向
- 5. 论文不足与局限性
- 5.1 方法局限
- 5.2 验证缺口
- 6. 可借鉴的创新点与学习建议
- 6.1 核心创新
- 6.2 学习建议
- 公式附录(论文关键公式)
1. 论文的研究目标与实际问题意义
1.1 研究目标
论文旨在解决盲图像去模糊(Blind Image Deblurring)问题,即在未知模糊核(Blur Kernel)的情况下,从模糊图像中恢复清晰图像。具体目标是通过数据驱动的判别性先验(Discriminative Prior)提升去模糊效果,使其适用于自然图像、文本、人脸、低光照等多种场景。
1.2 实际意义
盲图像去模糊是计算机视觉和图像处理中的经典难题。模糊可能由相机抖动、物体运动或光照不足引起,直接影响图像质量与后续应用(如自动驾驶、医学成像、安防监控)。现有方法依赖手工设计的先验,但泛化能力有限。本方法通过学习通用先验,提升复杂场景下的鲁棒性,对产业应用具有重要价值。
2. 创新方法、模型与公式解析
2.1 核心思路
论文提出了一种数据驱动的判别性先验(Data-Driven Discriminative Prior),其核心思想是通过深度CNN训练一个二元分类器,使其能够区分清晰图像与模糊图像,并将分类器的输出作为正则化项嵌入最大后验(MAP)框架中。这一思路基于以下观察:
“A good image prior should favor clear images over blurred ones.”
传统手工先验(如L0梯度、暗通道)依赖特定统计假设,而CNN先验通过数据驱动自动学习更通用的判别性特征,适用于自然图像、文本、人脸和低光照等多种场景。
2.2 方法框架
2.2.1 判别性先验学习
网络架构设计
-
全局平均池化(Global Average Pooling):
传统CNN分类器使用全连接层,限制了输入图像尺寸的灵活性。论文采用全局平均池化层替代全连接层,允许网络处理任意尺寸的输入图像。具体结构如图2所示:
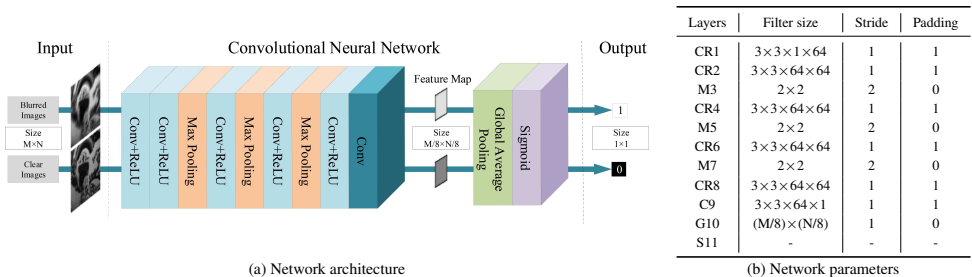
网络由9层卷积层(CR表示卷积+ReLU)和1层全局平均池化(G)组成,最终通过Sigmoid函数输出模糊概率。 -
多尺度训练策略:
为了增强分类器对不同输入尺寸的鲁棒性,训练时随机将输入图像下采样至原尺寸的[0.25, 1]倍。这一策略显著提升了分类器在粗到细(Coarse-to-Fine)MAP框架中的表现(见图10a)。
损失函数
使用二元交叉熵损失(Binary Cross Entropy Loss)训练分类器:
L ( θ ) = − 1 N ∑ i = 1 N y ^ i log ( y i ) + ( 1 − y ^ i ) log ( 1 − y i ) (3) L(\theta)=-\frac{1}{N}\sum_{i=1}^{N}\hat{y}_{i}\log\left(y_{i}\right)+\left(1-\hat{y}_{i}\right)\log\left(1-y_{i}\right) \quad \text{(3)} L(θ)=−N1i=1∑Ny^ilog(yi)+(1−y^i)log(1−yi)(3)
其中, y ^ = 1 \hat{y}=1 y^=1表示模糊图像, y ^ = 0 \hat{y}=0 y^=0表示清晰图像, y i = f ( x i ; θ ) y_i=f(x_i;\theta) yi=f(xi;θ)为分类器输出。
2.2.2 MAP优化框架
目标函数
将CNN先验与L0梯度先验结合,构建MAP优化问题:
min I , k ∥ I ⊗ k − B ∥ 2 2 + γ ∥ k ∥ 2 2 + μ ∥ ∇ I ∥ 0 + λ f ( I ) (4) \min_{I,k}\|I\otimes k-B\|_{2}^{2}+\gamma\|k\|_{2}^{2}+\mu\|\nabla I\|_{0}+\lambda f(I) \quad \text{(4)} I,kmin∥I⊗k−B∥22+γ∥k∥22+μ∥∇I∥0+λf(I)(4)
- 重构项: ∥ I ⊗ k − B ∥ 2 2 \|I\otimes k-B\|_2^2 ∥I⊗k−B∥22确保模糊核 k k k与清晰图像 I I I的卷积逼近观测模糊图像 B B B。
- 核正则化: γ ∥ k ∥ 2 2 \gamma\|k\|_2^2 γ∥k∥22</